
Google思想二(MapReduce)
MapReduce 的思想源於 PageRank(網頁排名) 問題。
PageRank(網頁排名)
現在有四個網頁,它們之間的存在如下引用關係:
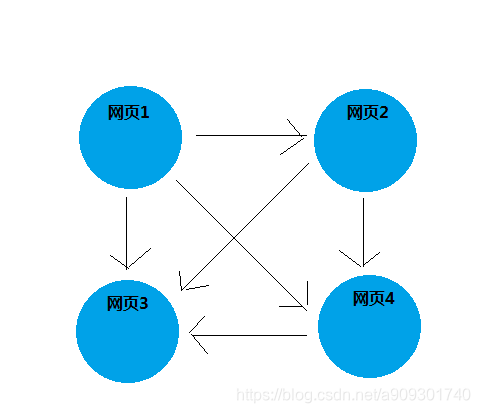
網頁 1 有 3 個引用,分別指向網頁 2,網頁 3,網頁 4。
網頁 2 有 2 個引用,分別指向網頁 3,網頁 4。
網頁 4 有 1 個引用,分別指向網頁 3。
網頁 3 沒有引用。
Google 採用向量矩陣的方式來表示上面網頁之間的引用關係:
| 網頁1 | 網頁2 | 網頁3 | 網頁4 | |
|---|---|---|---|---|
| 網頁1 | 0 | 1 | 1 | 1 |
| 網頁2 | 0 | 0 | 1 | 1 |
| 網頁3 | 0 | 0 | 0 | 0 |
| 網頁4 | 0 | 0 | 1 | 0 |
網頁 1 與網頁 2,3,4 都有引用關係,所以把對應的那一行上對應位置記為 1,沒有引用關係的網頁記為 0,以此類推。
最終我們可以得到一個 4 * 4 的矩陣,我們都知道矩陣在數學上是可以計算的,最終計算出網頁 3 的權重最大,所以我們就把網頁 3 排在頁面的最前面。
但是,實際操作上會出現一些的問題:
實際上的網頁的數量很大,以 1 億為例,就會產生一個 1 億 * 1 億的矩陣,雖然從數學的角度來說是可以計算的,但是實際情況是到目前為止任何一臺計算機都沒有辦法在短時間內獨立計算出結果。
所以,Google 提出了一個 MapReduce 計算模型。
MapReduce
MapReduce 基本思想:先拆分,再合併。
拿上面的例子來說,就是把一個大矩陣拆分成多個小矩陣,每臺機器負責計算其中的一個小矩陣的結果,計算完畢後再把結果合併。
再看一個累加求和的例子:
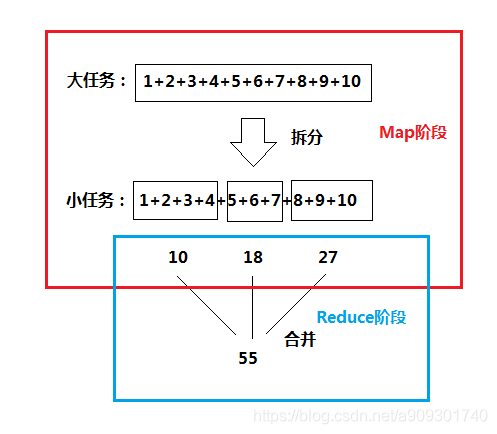
MapReduce 其實分為兩個階段:紅色部分為 Map 階段,藍色部分為 Reduce 階段。
MapReduce 程式設計模型
-
一個 MapReduce 任務 = map + reduce
也就是說一個完整的 MapReduce 程式由三個 Java 類組成。
-
Map 的輸出是 Reduce 的輸入。
10,18,27 是 Map 的輸出,同時是 Reduce 的輸入。
-
所有的輸入輸出都是 <key, value> 形式的。
-
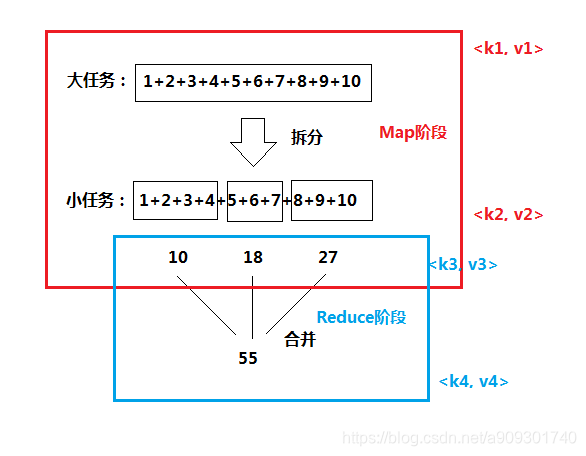
在整個 MapReduce 過程有 4 個 <key, value> 對。
<k1, v1> Map 的輸入,<k2, v2> Map 的輸出
<k3, v3> Reduce 的輸入,<k4, v4> Reduce 的輸出
-
k2 = k3,v3 是一個集合,該集合中的每個元素就是 v2。
-
所有的輸入輸出的資料型別必須是 Hadoop 自己的資料型別,不能是 Java 的資料型別。
ava 資料型別 Hadoop 資料型別 Integer IntWritable Long LongWritable String Text null NullWritable 原因:Hadoop 所有的資料型別都實現了 Hadoop 的序列化。
Java 類只要實現了 Serializable 介面,就實現了 Java 序列化,對應的物件就可以在 InputStream 和 OutputStream 上進行傳輸。
Java 類只要實現了 Writable 介面,就實現了 Hadoop 序列化,對應的物件就可以作為 Map 和 Reduce 程式的輸入和輸出。
-
MapReduce 處理的都是 HDFS 上的資料(或 HBase)。