
Google思想一(GFS - Google File System)
思考1:Google 搜尋引擎每天要從世界各地抓取數以億計的網頁,資料都儲存在哪裡呢?
GFS:使用大量廉價的去掉硬碟的 PC 機構成叢集,將資料都儲存在伺服器的記憶體中,採用分散式的檔案系統進行儲存。
思考2:記憶體中的資料掉電會丟失,怎麼保證可靠呢?
在世界各地進行部署,部分地區還配有發電廠。
當然,不是所有的公司都像 Google 一樣技術牛X,有錢,資料都存記憶體裡面。我們的資料主要還是儲存在硬碟中的,但是思路還是採用分散式的思想。
什麼是分散式檔案系統?
思考3:為什麼要用分散式檔案系統?分散式檔案系統解決了什麼問題?
分散式檔案系統解決了資料的儲存問題。
在沒有使用分散式的檔案系統時,資料儲存可能遇到的問題有:
-
硬碟不夠大,容納不了我們要儲存的資料。
解決:多幾個硬碟。
-
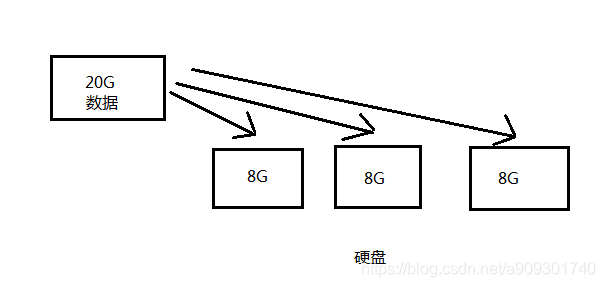
要儲存的資料非常大,一下把資料全部存入硬碟,中途斷電了,部分資料不就丟失了嗎,怎麼辦?
解決:將資料分塊,按資料塊的大小進行儲存。
ps:Hadoop1.x 的 HDFS 資料塊的預設大小是 64 M,Hadoop2.x 的 HDFS 資料塊的預設大小是128 M。 -
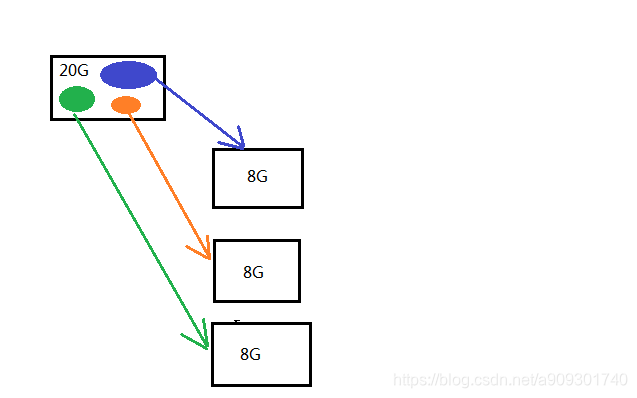
硬碟不夠安全,硬碟一旦損壞,上面的資料就丟失了。
解決:資料冗餘(同一份資料存多份),客戶端上傳到服務端一份資料之後,服務端通過水平復制的方式,複製多份相同的資料塊到不同的硬碟。
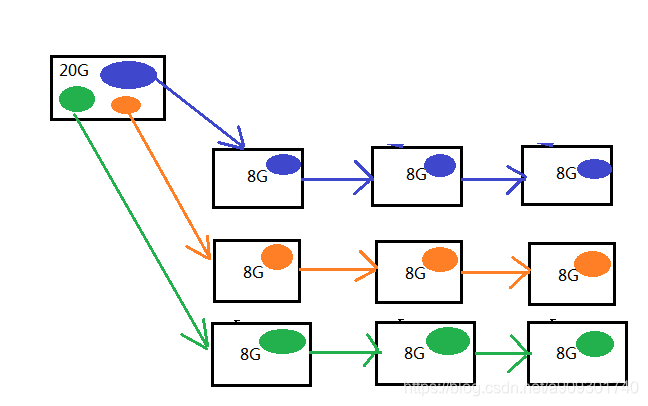
ps:HDFS 資料塊預設的冗餘度是 3,也就是 1 個數據塊在 HDFS 中存 3 份。
什麼是機架感知?
-
冗餘的資料塊具體要水平復制到哪些硬碟上呢?是通過什麼方式來決定資料塊的儲存位置呢?
解決:機架感知。 -
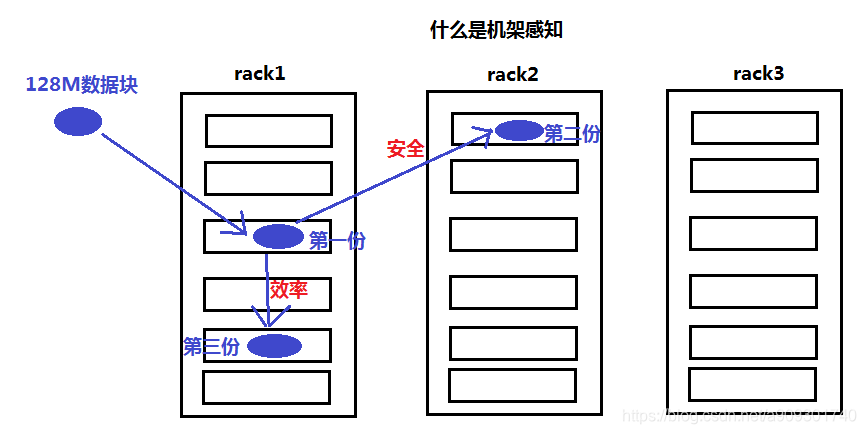
機架感知如何分配後兩份資料塊的儲存位置?
第 2 份資料優先儲存在與第 1 份資料不在同一個機架的另外一個機架的伺服器上。(安全)
第 3 份資料優先儲存在與第 1 份資料在同一個機架的另外一個伺服器上。(效率)
-
為什麼第 2 份資料優先儲存在與第 1 份資料不在同一個機架的另外一個機架的伺服器上?
這是從安全的角度考慮的,萬一 rack1 上的所有伺服器都掛掉了,還有 rack2 作為後援。 -
為什麼第 3 份資料優先儲存在與第 1 份資料在同一個機架的另外一個伺服器上?
這是從效率的角度考慮的,rack1 上所有伺服器都掛掉的該率是比較小的,但是某臺伺服器掛掉的概率還是有的。儲存第一份資料的伺服器掛掉後,還可以立即從所處的機架上的另一臺伺服器上取資料,效率較高。 -
資料塊的水平復制,硬碟的新增和移除這些功能由誰來做呢?
需要有一個管理員來管理,不,兩個管理員。
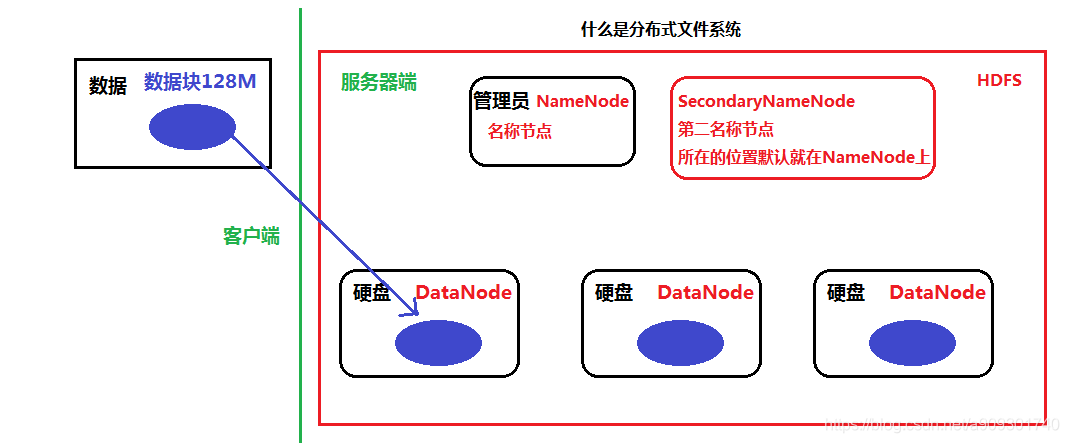
ps:到目前為止,用紅框框住的部分就是我們的 HDFS,其實 HDFS 也就是仿照 GFS 的一個通用的(便宜)分散式檔案系統。 -
資料塊分佈在各個伺服器上,怎麼查詢呢?
解決:使用倒排索引,和資料庫中的索引類似,儲存的是資料塊中的位置資訊(元資訊)。
什麼是倒排索引?
思考4:什麼是正排索引?正排索引哪裡不好?為什麼要使用倒排索引?
-
什麼是正排索引?
以搜尋引擎舉例:每個檔案都對應了一個檔案 ID,檔案內容是一系列的關鍵詞的集合,在這個集合中儲存了每個關鍵詞出現的次數。
假如使用正排索引,那麼在搜尋引擎上搜索 “大資料” 時,搜尋引擎就需要掃描庫中所有的文件,找出所有包含 “大資料” 這個關鍵詞的檔案,根據文件 ID 找關鍵詞,這就是正排索引。
很明顯,使用正排索引的方式難以滿足查詢需求,所以就有了倒排索引。
-
什麼是倒排索引?
倒排索引就是根據關鍵詞找檔案 ID。通過這種方式,就能大大提高搜尋引擎檢索文件的速度。
以上就是 Google 第一篇論文(GFS)中的一些思想。