
大資料需要學習哪些知識?
學習一項技術最重要的是要理解它能解決什麼問題,那麼學習大資料可以解決什麼問題呢?
一、大資料可以解決什麼問題?
-
場景一:電商網站要把過去一個月或一年賣的好的商品放到首頁推薦給使用者。
問題1:過去一個月或者一年的訂單數量是巨大的,如何儲存?
問題2:假設已經找到儲存的方案了,那麼大量的訂單如何計算? -
場景二:天氣預報需要根據過去一年或者十年的天氣狀況預測明天或者下個周的天氣狀況。
問題1:過去一年或者十年的天氣狀況資訊是巨大的,如何儲存?
問題2:假設已經解決了儲存的問題,那麼近十年的天氣狀況資料要如何計算?
沒錯,大資料可以解決海量資料的儲存和計算這兩個問題。
- 海量資料的儲存是使用分散式儲存(HDFS)
- 海量資料的計算是使用分散式計算(MapReduce)
Hadoop則是集成了分散式儲存和分散式計算這兩種功能的一種大資料的解決方案。
二、Hadoop
-
Hadoop 的 HDFS(Hadoop Distributed File System ,Hadoop分散式檔案系統)解決了資料的分散式儲存。
-
Hadoop 的 MapReduce 計算模型解決了資料的分散式計算。
-
Hadoop也可以看成是資料倉庫的一種實現方式。
資料庫:服務於業務功能,主要用於增刪改查。
資料倉庫:服務於系統分析師,主要用於查詢。 -
Hadoop (資料倉庫)中的資料來自於哪裡呢?
關係型資料庫,日誌,其他資料…
-
那麼我們如何將這麼多不同型別的資料儲存到 Hadoop 的 HDFS 中呢?
通過ETL(Extract-抽取,Transfer-轉換,Load-載入)的方式,就像我們在一些招聘網站上看到的一樣:

-
ETL還只是一個概念,那麼具體要用什麼技術進行資料的採集,清洗呢?
需要用到資料採集引擎,如下兩種:
Sqoop:主要用來採集關係型資料庫。
Flume:主要用來採集日誌。 -
採集到的資料儲存到Hadoop的哪一部分呢?
- 可以是上面提到的HDFS
- 也可以是HBase(基於Hadoop的一個No-SQL資料庫)
- 當然也可以是Hive(一個數據分析引擎,另外一個比較常見的資料分析引擎是Pig)
-
那麼如何處理這些海量的資料呢?
- 使用 Hadoop 中的 MapReduce 程式。
- 使用另一個類似Hadoop的大資料處理框架Spark。
-
當然處理後的資料仍然是儲存在HDFS,HBase,Hive中。
-
這麼多的元件,如何協調它們的執行呢?
使用 ZooKeeper、HUE。 -
最終將不同型別的資料提供給不同的人使用。
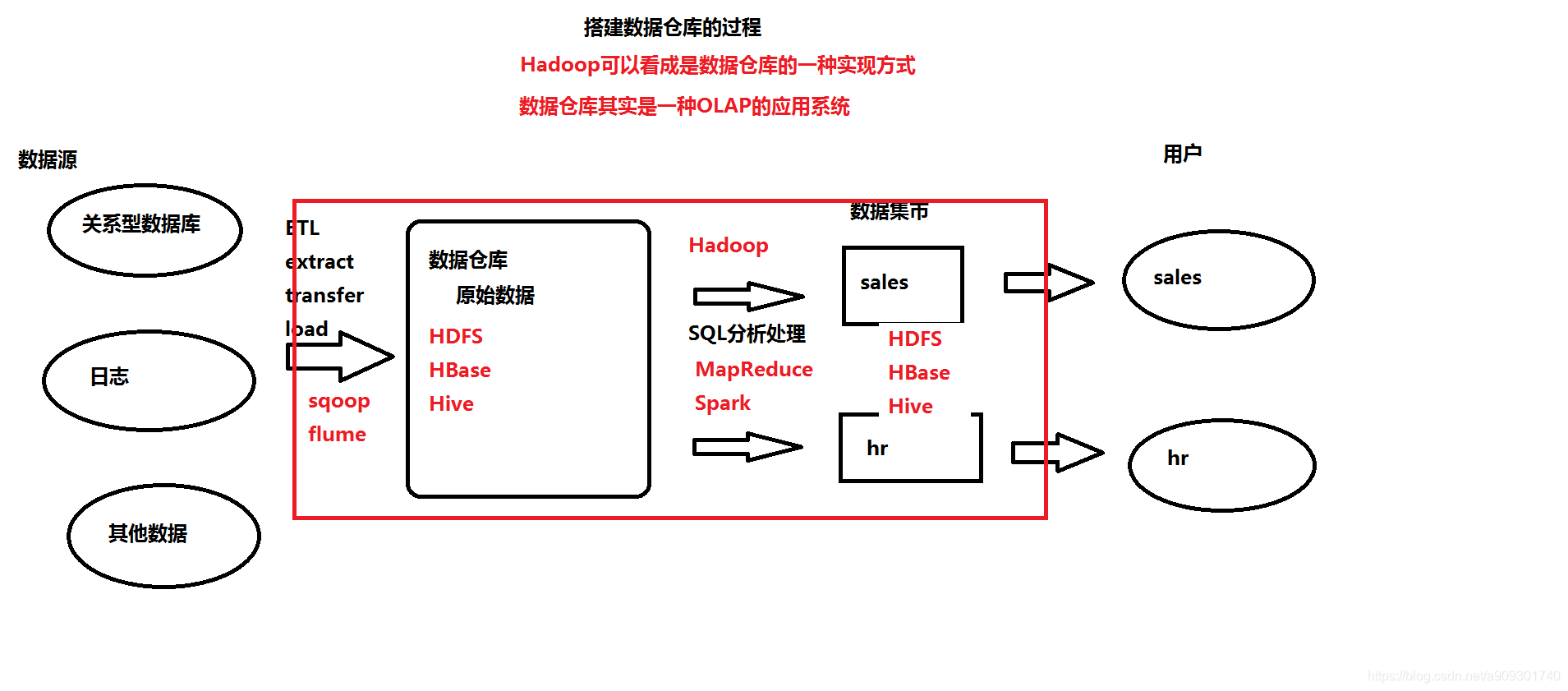
紅框框住的部分就是Hadoop的一些元件(Spark除外)。- HDFS:Hadoop分散式檔案系統
- MapReduce:Java程式,用於分散式計算,並且是執行在 Yarn 平臺。
- Yarn:就像 Tomcat 一樣,也是一個執行程式的容器,不同的是 Yarn 中執行的是 MapReduce 程式,Tomcat 中執行的是 servlet 程式。
- Hbase:一個NoSQL資料庫。
- Sqoop、Flume:資料採集引擎。
- Hive、Pig:資料分析引擎。
- ZooKeeper、HUE:是協調管理工具,管理圖中不同元件之間的排程。
三、Storm
實時計算框架,用來處理流式資料。
- NoSQL資料庫:Redis
- Apache Storm
四、Spark
類似 Hadoop 的一個基於記憶體的大資料處理框架。
- Sclala程式語言(基於Java)
- Spark Core:核心(最重要的內容) ----> 相當於 Hadoop 的MapReduce
- Spark SQL:相當於 Hadoop 的 Hive、Pig 是資料分析引擎,支援SQL
- Spark Streaming:相當於 Storm,也是一個實時計算框架,用來處理流式資料。