
Yarn與Mr
yarn應用:
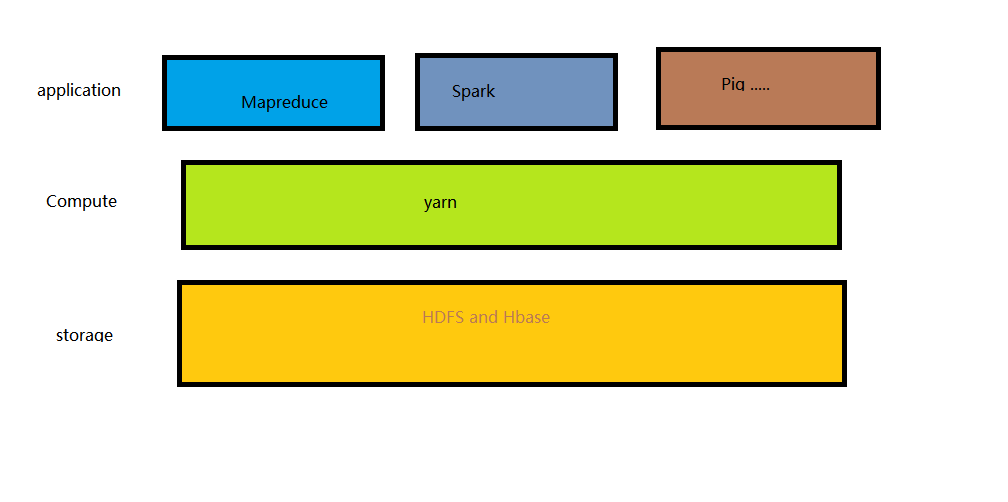
分散式計算框架(Mapreduce、spark等)作為yarn應用執行在叢集計算層(yarn)和儲存層(hdfs和hbase上)。
Yarn的執行機制:
(1) 客戶端練習資源管理器,請求他執行一個application master。
(2) 資源管理器找到一個能夠在容器中啟動application master 的節點管理器。
(3)根據application master 自己來確定的,如果所需資源少或者程式碼給定為一個,那麼就經過簡單的計算將結果反饋給客戶端:如果所需資源大,或者需要節點運算,那麼就向資源管理器申請更多的容器。
(4)進行分散式計算。當程式執行完成時,ApplicationMaster從Resourcemanager登出其容器,執行週期就完成了。

yarn中的排程:
在yarn中有三種排程器可以選擇:FIFO Scheduler,Capacity Scheduler,Fair Scheduler。
FIFO Scheduler 把應用按提交的順序排成一個佇列,這是一個先進先出佇列,在進行資源分配的時候,先給佇列中最頭上的應用進行分配資源,待最頭上的應用需求滿足後再給下一個分配,以此類推. FIFO Scheduler 是最簡單的也是最容易理解的排程器,也不需要任何配置,但它並不適用於共享叢集。大的應用可能會佔用所有叢集資源,這就導致其他應用被阻塞。
而對於Capacity排程器,有一個專門的佇列用來執行小任務,但是為小任務專門設定一個佇列會預先佔用一定的叢集資源,這就導致大任務的執行時間會落後於使用FIFO 排程器時的時間。
在Fair排程器中,我們不需要預先佔用一定的系統資源,Fair排程器回為所有執行的job動態的調整系統資源。如下圖所示:當第一個大job提交時,只有這一個job在執行,此時它獲得了所有叢集資源;當第二個小任務提交後,Fair排程器會分配一般資源給這個小任務,讓這兩個小任務公平的共享叢集資源。需要注意的是,在下圖fair排程器中,從第二個任務提交獲得資源會有一定的延遲,因為它需要等待第一個任務釋放佔用的Container。小任務執行完成後也會釋放自己佔用的資源,大任務又獲得了全部的系統資源。最終的效果就是Fair排程器即得到了高的資源利用率又能保證小任務及時完成。
搶佔當一個job提交到一個繁忙叢集中的空佇列時,job並不會馬上執行,而是阻塞直到正在執行的job釋放系統資源,為了使提交job的執行時間更具預測性(可以設定等待的超時時間),Fair排程器支援搶佔,搶佔就是允許排程器殺掉佔用超過其應占份額資源佇列的containers,這些cintainers資源便可被分配到應該享有這些份額資源的佇列中,需要注意搶佔會降低叢集的執行效率,因為被終止的containers需要被重新執行。
hadoop_yarn記憶體調優
(1) yarn.nodemanager.resource.memory-mb
表示在該節點上yarn可使用的實體記憶體數量,預設是8192(MB),注意,如果你的節點記憶體資源不夠8GB,則需要減小這個值,而yarn不會只能的檢測節點的實體記憶體總量。
(2)yarn.nodemanager.vmem-pmem-ratio
任務每使用1mb實體記憶體,最多可使用虛擬記憶體,預設是2.1
(3)yarn.nodemanager.pmem-check-enabled
是否啟動一個執行緒檢查每個任務正使用的實體記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true。
(4)yarn.nodemanager.vmem-check-enabled
是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true。
(5)yarn.scheduler.minimum-allocation-mb
單個任務可申請的最少實體記憶體量,預設是1024(MB),如果一個任務申請的實體記憶體量少於該值,則該對應的值改為這個數。
(6)yarn.scheduler.maximum-allocation-mb
單個任務可申請的最多實體記憶體量,預設是8192(MB).
(7)小總結:計算節點的記憶體佔用量。
預設情況下,一個同時運行了 namenode,secondarynamenode 和 nodemanager 的主節點,各自使用1000M 記憶體,所以總計使用3000M。
預設情況下,一個從節點運行了如下守護程序:
1個 datanode:預設佔用1000M記憶體.
1個 tasktracker:預設佔用1000M記憶體.
最多2個map任務:2*200M=400M.
最多2個reduce任務:2*200M=400Ma