
機器學習該如何入門
什麼是機器學習
首先我們看下圖瞭解一下機器學習在AI(Artificial Intelligence 人工智慧)領域的地位。在圖中,我們可以看到,機器學習是人工智慧的一個子領域。而現在火的不要不要的 深度學習 其實是機器學習的一個子分支。
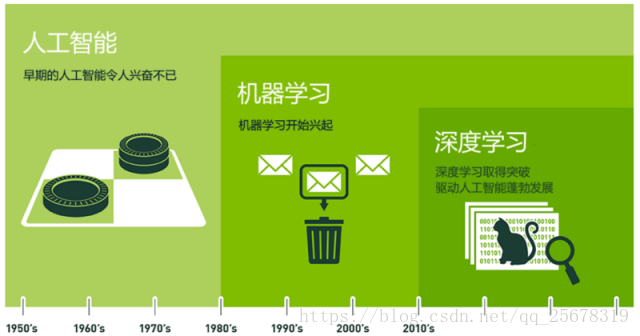
機器學習在人工智慧中的地位
大神的解釋
機器學習研究的是計算機怎樣模擬人類的學習行為,以獲取新的知識或技能,並重新組織已有的知識結構使之不斷改善自身。簡單一點說,就是計算機從資料中學習出規律和模式,以應用在新資料上做預測的任務。
我的解釋
傳統的機器學習主要做的事情就是利用統計學的基本觀點,利用要學習的問題的歷史樣本資料的分佈對總體樣本分佈進行估計。分析資料大致特性建立數學分佈模型,並利用最優化的知識對模型的引數進行調優學習,使得最終的學習模型能夠對已知樣本進行很好的模擬與估計。最終利用學習好的模型對未知標籤的樣本進行預測和估計的過程。
機器學習的基本問題
對於機器學習中的基本問題,我們將從以下幾個角度進行講解:機器學習的特點;機器學習的物件;機器學習的分類;機器學習的要素;模型的評估與選擇。
機器學習的特點
機器學習主要特點如下:
機器學習以資料為研究物件,是資料驅動的科學;
機器學習的目的是對資料進行預測與分析;
機器學習以模型方法為中心,利用統計學習的方法構建模型並且利用模型對未知資料進行預測和分析;
統計學習是概率論、統計學、資訊理論、計算理論、最優化理論以及電腦科學等多領域的交叉學科,並且逐漸形成自己獨自的理論體系和方法論。
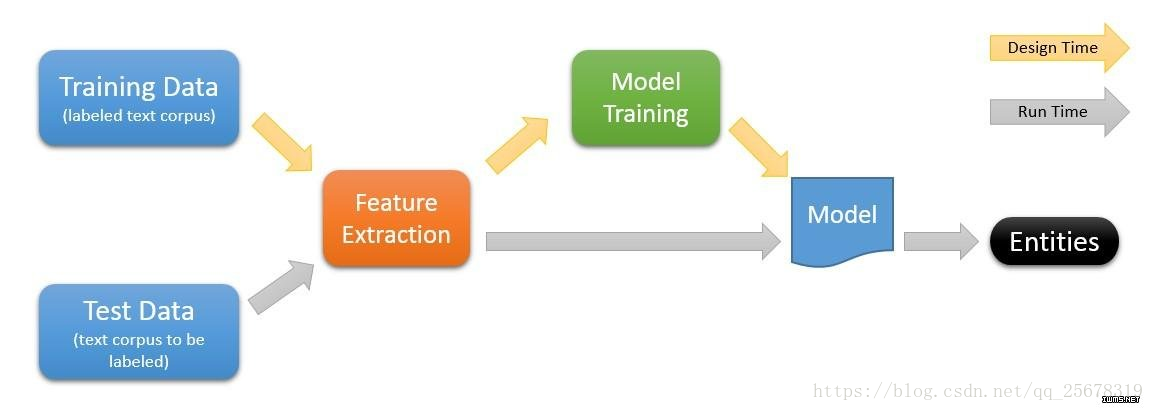
機器學習的一般訓練過程
機器學習的物件
機器學習研究的物件是多維向量空間的資料。它從各種不同型別的資料(數字,文字,影象,音訊,視訊)出發,提取資料的特徵,抽象出資料的模型,發現數據中的知識,又回到資料的分析與預測中去。
機器學習的分類
對於機器學習的分類,絕大多數人只簡單的分為有監督學習和無監督學習這兩類。嚴格意義上來講應該分為四大類:有監督學習、無監督學習、半監督學習、強化學習。下面對這四種學習做一下簡要的介紹:
有監督學習
有監督學習是指進行訓練的資料包含兩部分資訊:特徵向量 + 類別標籤。也就是說,他們在訓練的時候每一個數據向量所屬的類別是事先知道的。在設計學習演算法的時候,學習調整引數的過程會根據類標進行調整,類似於學習的過程中被監督了一樣,而不是漫無目標地去學習,故此得名。
無監督學習
相對於有監督而言,無監督方法的訓練資料沒有類標,只有特徵向量。甚至很多時候我們都不知道總共的類別有多少個。因此,無監督學習就不叫做分類,而往往叫做聚類。就是採用一定的演算法,把特徵性質相近的樣本聚在一起成為一類。
半監督學習
半監督學習是一種結合有監督學習和無監督學習的一種學習方式。它是近年來研究的熱點,原因是在真正的模型建立的過程中,往往有類標的資料很少,而絕大多數的資料樣本是沒有確定類標的。這時候,我們無法直接應用有監督的學習方法進行模型的訓練,因為有監督學習演算法在有類標資料很少的情況下學習的效果往往很差。但是,我們也不能直接利用無監督學習的方式進行學習,因為這樣,我們就沒有充分的利用那些已給出的類標的有用資訊。
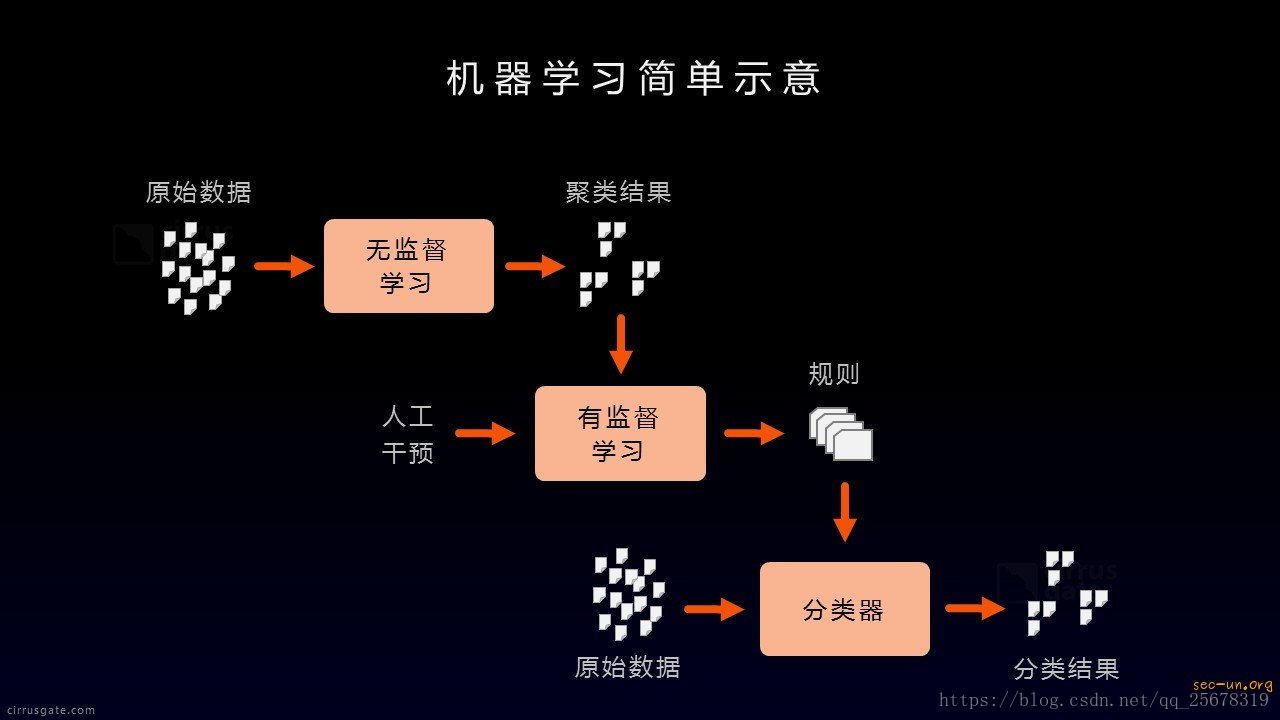
典型半監督訓練過程
強化學習
所謂強化學習就是智慧系統從環境到行為對映的學習,以使獎勵訊號(強化訊號)函式值最大,強化學習不同於連線主義學習中的監督學習,主要表現在教師訊號上,強化學習中由環境提供的強化訊號是對產生動作的好壞作一種評價(通常為標量訊號),而不是告訴強化學習系統RLS(reinforcement learning system)如何去產生正確的動作。由於外部環境提供的資訊很少,RLS必須靠自身的經歷進行學習。通過這種方式,RLS在行動-評價的環境中獲得知識,改進行動方案以適應環境。
機器學習的要素
簡單地說,機器學習的三要素就是:模型、策略和演算法。
模型 其實就是機器學習訓練的過程中所要學習的條件概率分佈或者決策函式。
策略 就是使用一種什麼樣的評價度量模型訓練過程中的學習好壞的方法,同時根據這個方法去實施的調整模型的引數,以期望訓練的模型將來對未知的資料具有最好的預測準確度。
演算法 演算法是指模型的具體計算方法。它基於訓練資料集,根據學習策略,從假設空間中選擇最優模型,最後考慮用什麼樣的計算方法去求解這個最優模型。
入門方法與學習路徑

機器學習的入門過程
對於上圖,之所以最左邊寫了『數學基礎』 『經典演算法學習』 『程式設計技術』 三個並行的部分,是因為機器學習是一個將數學、演算法理論和工程實踐緊密結合的領域,需要紮實的理論基礎幫助引導資料分析與模型調優,同時也需要精湛的工程開發能力去高效化地訓練和部署模型和服務。
經典演算法學習
絕大多數平常的應用中,經典的機器學習演算法就能夠解決其中絕大多數的問題。因此,對機器學習經典演算法的學習和掌握是相當有必要的。
接下來我們會分門別類的介紹一下:
分類演算法: 邏輯迴歸(LR),樸素貝葉斯(Naive Bayes),支援向量機(SVM),隨機森林(Random Forest),AdaBoost,GDBT,KNN,決策樹……
迴歸演算法: 線性迴歸(Linear Regression),多項式迴歸(Polynomial Regression),逐步迴歸(Stepwise Regression),嶺迴歸(Ridge Regression),套索迴歸(Lasso Regression)
聚類演算法: K均值(K-Means),譜聚類、DBSCAN聚類、模糊聚類、GMM聚類、層次聚
降維演算法: PCA(主成分分析)、SVD(奇異值分解)
推薦演算法: 協同過濾演算法
在這裡,我還是希望解釋一下 演算法 這個概念在不同的地方出現的意義給廣大的讀者帶來的疑惑。本文介紹的機器學習演算法和我們程式設計師所說的“資料結構與演算法分析”裡的演算法略有不同。前者更關注結果資料的召回率、精確度、準確性等方面,後者更關注執行過程的時間複雜度、空間複雜度等方面。 當然,實際機器學習問題中,對效率和資源佔用的考量是不可或缺的。
程式設計技術
技術選擇
程式設計技術無非是語言和開發環境了。在此,對初入門學習機器學習的小白童鞋來說,我的個人建議是:Python + PyCharm。如下圖所示是他們的Logo。

Python 與 PyCharm 軟體示意圖
語言和工具選擇好了,對於小白來說,我們當然使用成熟的機器學習庫。那麼對於python機器學習來說,毫無疑問我們選擇的是scikit-learn。
軟體安裝
關於在Windows下安裝python和scikit-learn的方法步驟,請參閱我的CSDN部落格Windows下安裝Scikit-Learn。對於PyChram的下載,請點選PyCharm官網去下載,當然windows下軟體的安裝不用解釋,傻瓜式的點選 下一步 就行了。
實戰操作
建立專案
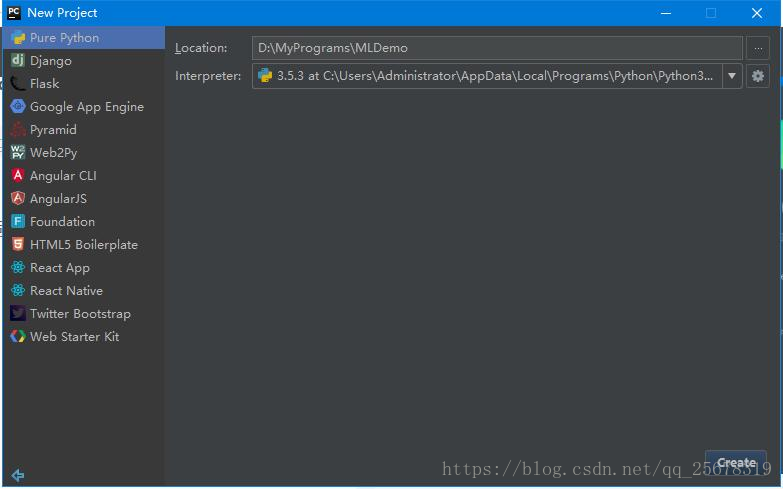
開啟 PyCharm,點選 Create New Project

接下來選擇 Pure Python,並選擇程式目錄同時設定專案名稱為 MLDemo,點選右下角的 Create。
在生成的專案MLDemo 上右擊,依次選擇 New —> Python,命名 MLDemo
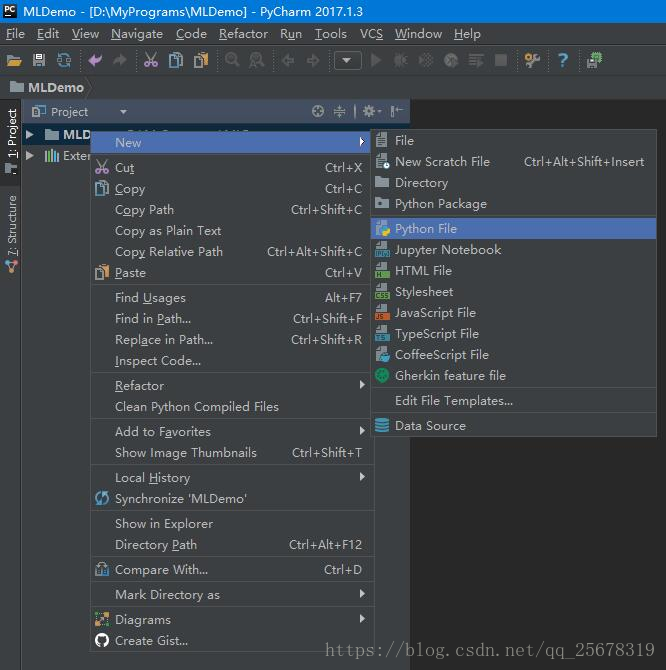
編寫如下程式碼,然後右擊程式碼區,點選 Run MLDemo

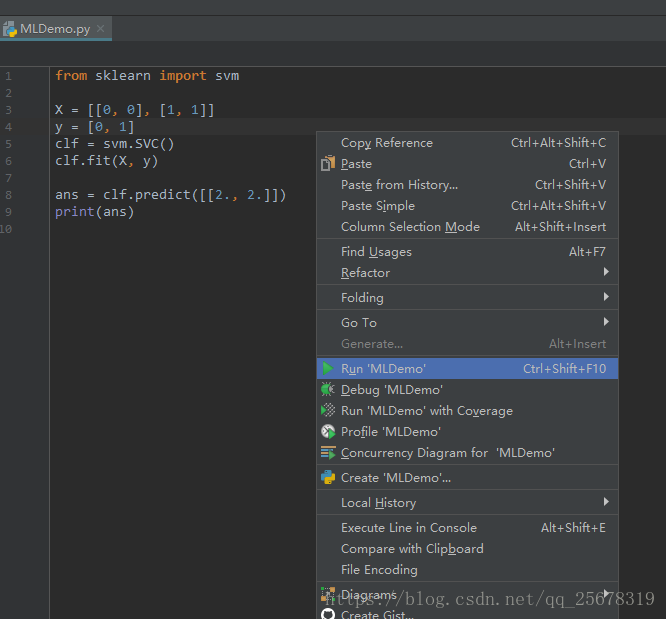
對執行結果進行解釋:

源程式呼叫了sklearn包的svm類,用於後續程式的分類器是訓練:

轉自: https://blog.csdn.net/u013709270/article/details/76058123 機器學習在人工智慧中的地位