
word2vec的詞向量&&神經網路的embedding層的關係
自己之前學習了一波word2vec的詞向量&&神經網路的embedding,關於這2者的原理和實踐,可以參看我之前的部落格:
這篇文章的主題是分析word2vec的詞向量&&神經網路的embedding層的關係,以及在實際中,如何同時應用它們。
第一章主要介紹二者之間的關係,第二章給出一個利用NN的embedding層來學習句子的詞嵌入的例子,第三章給出一個如何結合二者的例子:即用word2vec學到的詞嵌入作為NN的embedding層的初始權重。
一、word2vec的詞向量&&神經網路的embedding層
1.1 word embedding
word embedding我在這裡就不多做介紹了。具體可以參看我上面的連結。
1.2 Keras embedding layer
關於神經網路的embedding layer,我這裡再多說幾句,翻譯自參考文獻【1】。我以Keras嵌入層為例:
Keras提供了一個嵌入層,可用於處理文字資料的神經網路。它要求輸入資料進行整數編碼,以便每個單詞都由唯一的整數表示。該資料準備步驟可以使用提供有Keras的Tokenizer API來執行。
嵌入層使用隨機權重初始化,並將學習資料集中所有詞的嵌入。
它是一個靈活的層,可以以各種方式使用,如:
- 它可以單獨使用來學習一個字嵌入,以後可以在另一個模型中使用。
- 它可以用作深度學習模型的一部分,其中嵌入與模型本身一起被學習。
- 它可以用於載入訓練好的詞嵌入模型,一種遷移學習。
嵌入層被定義為網路的第一個隱藏層。它必須指定3個引數:
1.input_dim:這是文字資料中詞彙的大小。例如,如果你的資料是整數編碼為0-10之間的值,則詞表的大小將為11個字。
2.output_dim:這是嵌入單詞的向量空間的大小。它為每個單詞定義了該層的輸出向量的大小。例如,它可以是32或100甚至更大。根據你的問題來定。
3.input_length:這是輸入序列的長度,正如你為Keras模型的任何輸入層定義的那樣。例如,如果你的所有輸入句子裡最多包含1000個單詞,則為1000。
例如,下面我們定義一個詞彙量為200的嵌入層(例如,從0到199(包括整數)的整數編碼單詞),將詞嵌入到32維的向量空間中,以及每次輸入50個單詞的輸入句子。
e = Embedding(200, 32, input_length=50)嵌入層的輸出是一個三維向量(x,y,z)。x代表有多少個句子(樣本),y代表這個句子的長度(即有多少個詞,句子的詞長度需要人為統一)這裡指50;z代表嵌入後的設定向量維度,這裡指32。
如果希望連線密集(dense)層直接到嵌入層,必須首先將y和z壓縮到一行,形成一個(x,yz)的2D矩陣。
1.3 二者之間的關係
不論是word2vec還是NN的embedding layer,我們都可以學到詞的稠密的嵌入表示。只不過二者學習的方式不一樣。
word2vec是無監督的學習方式,利用上下文環境來學習詞的嵌入表示,因此可以學到相關詞;而神經網路的嵌入層權重的更新是基於標籤的資訊進行學習,為了達到較高的監督學習的效果,它本身也可能會學到相關詞。
我在1.2中標紅那裡說到,NN的embedding layer可用於載入訓練好的詞嵌入模型,這句話通俗來解釋就是:先用word2vec學到詞向量,然後作為NN的embedding layer的初始權重,而不是用隨機的初始化權重。這也是業界常用的一個手段。我在第3章會給出這麼一個例子。
二、利用NN的embedding層學習句子的詞嵌入的例子
現在,我們來看看我們如何在實踐中使用嵌入層。翻譯自參考文獻1。
我們定義一個小問題,我們有10個句子,每個句子都有一個關於學生作品的評論。這是一個簡單的情緒分析問題,每個文字分類為正“1”或負“0”。
首先,我們將定義文件及其類標籤。
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]由於神經網路無法認識str型別的輸入,接下來我們對每個句子進行整數編碼,作為輸入,嵌入層將具有整數序列。
Keras提供one_hot()函式,它建立每個單詞的雜湊值作為有效的整數編碼。我們估計有20個詞彙大小,這遠遠大於減少雜湊函式碰撞概率所需的大小。如果你的詞彙很多的話,我建議你使用這個函式。
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)
'''
[[6, 19], [7, 5], [19, 5], [14, 5], [10], [17], [4, 5], [1, 7], [4, 5], [4, 11, 19, 17]]
'''句子具有不同的長度,且Keras需要輸入具有相同的長度。因為最大的句子的單詞個數為4,我們將所有輸入句子的長度設為4。再次,我們可以使用內建的Keras函式(在這種情況下為pad_sequences()來執行此操作)。
# pad documents to a max length of 4 words
max_length = 4
padded_docs=pad_sequences(encoded_docs,maxlen=max_length, padding='post')
print(padded_docs)
'''
[[ 6 19 0 0]
[ 7 5 0 0]
[19 5 0 0]
[14 5 0 0]
[10 0 0 0]
[17 0 0 0]
[ 4 5 0 0]
[ 1 7 0 0]
[ 4 5 0 0]
[ 4 11 19 17]]
'''
'''
我們可以看到短的句子給補零了。
'''我們現在可以將我們的嵌入層定義為神經網路模型的一部分。該嵌入具有50詞彙及輸入長度為4,我們將選擇8尺寸的嵌入空間。
該模型是一個簡單的二分類模型。重要的是,嵌入層的輸出將是4個向量,每個向量8個維度,每個單詞一個。我們將其平坦化為一個32維度的向量,以傳遞到Dense輸出層。
# define the model
model = Sequential()
model.add(Embedding(vocab_size, 8, input_length=max_length))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
'''
______________________________________________________________
Layer (type) Output Shape Param #
===========================================================
embedding_1 (Embedding) (None, 4, 8) 400
______________________________________________________________
flatten_1 (Flatten) (None, 32) 0
______________________________________________________________
dense_1 (Dense) (None, 1) 33
===========================================================
Total params: 433
Trainable params: 433
Non-trainable params: 0
'''embedding_1 (Embedding) 的shape為 (None, 4, 8),None代表的是樣本個數,即不確定的值。對於一個句子來說,可以看出,embedding層將(1, 4)的一個輸入sample(最長為4個單詞的句子,其中每個單詞表示為一個int數字),嵌入為一個(1, 4, 8)的向量,即將每個單詞embed為一個8維的向量,而整個embedding層的引數就由神經網路學習得到,資料經過embedding層之後就方便地轉換為了可以由CNN或者RNN進一步處理的格式(本例中,只是直接接了個Dense層)。
最後,我們可以訓練和評估該分類模型。
# fit the model
model.fit(padded_docs, labels, epochs=50, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))
'''
Accuracy: 100.00
'''完整的程式碼清單如下:這個例子就展示了我們如何輸入一些句子來用神經網路進行分類。
from keras.preprocessing.text import one_hot
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.embeddings import Embedding
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
# integer encode the documents
vocab_size = 20
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
# define the model
model = Sequential()
model.add(Embedding(vocab_size, 8, input_length=max_length))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
# fit the model
model.fit(padded_docs, labels, epochs=50, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))對於上面的程式碼,我們進一步分析以下embedding layer輸出的結果:
from keras.models import Model
weight = model.get_weights()
# 'embedding_1'是嵌入層的名字
intermediate_layer_model = Model(inputs=model.input,
outputs=model.get_layer('embedding_1').output)
intermediate_output = intermediate_layer_model.predict(padded_docs)
'''
intermediate_output的shape即為(10,4,8),10代表句子個數,4代表句子的長度,8代表嵌入的維度。與之前我們描述得一致。
'''embeddding後的結果其實是一個索引的結果表。關於這一點,在《利用神經網路的embedding層處理類別特徵》中我詳細地探討過,有興趣的讀者可以去看看。
三、結合word2vec的詞向量和神經網路的embedding層
在這裡,我們應用一個已經訓練好的詞嵌入的資料集GloVe詞向量作為神經網路的embedding層的輸入。GloVe 是 "Global Vectors for Word Representation"的縮寫,一種基於共現矩陣分解的詞向量。本文所使用的GloVe詞向量是在2014年的英文維基百科上訓練的,有400k個不同的詞,每個詞用(50,100,150,200)維向量表示。點此下載 (友情提示,詞向量檔案大小約為822M)。本文的示例來自Keras專案中的示例:pretrained_word_embeddings.py
下載和解壓縮後,你將看到一些檔案,其中之一是“glove.6B.100d.txt”,其中包含一個100維版本的嵌入。
如果認真看檔案,則會在每行上看到單詞,後跟權重(100個數字)。例如,下面是嵌入的ASCII文字檔案的第一行,顯示“the”的嵌入。
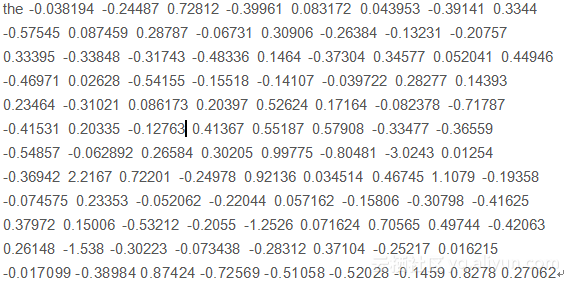
我們仍然用第二章的例子作為我們的訓練集。與第二章同樣的操作:區別我們用Tokenizer()來數字化句子裡的單詞。
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
# prepare tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
vocab_size = len(t.word_index) + 1
# integer encode the documents
encoded_docs = t.texts_to_sequences(docs)
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
'''
[[6, 2], [3, 1], [7, 4], [8, 1], [9], [10], [5, 4], [11, 3], [5, 1], [12, 13, 2, 14]]
[[ 6 2 0 0]
[ 3 1 0 0]
[ 7 4 0 0]
[ 8 1 0 0]
[ 9 0 0 0]
[10 0 0 0]
[ 5 4 0 0]
[11 3 0 0]
[ 5 1 0 0]
[12 13 2 14]]
'''接下來,我們對GloVe詞向量進行處理,形成一個詞典,key為單詞,value為embedding的值:
# load the whole embedding into memory
embeddings_index = dict()
f = open('datasets\glove.6B\glove.6B.100d.txt', 'rb')
for line in f:
values = line.split()
word = values[0]
coefs = asarray(values[1:], dtype='float32')
# 資料集中的word都是bytes型別,必須將bytes型別的word轉為str。轉換程式碼:str(word, encoding='utf-8')
embeddings_index[str(word, encoding='utf-8')] = coefs
f.close()
print('Loaded %s word vectors.' % len(embeddings_index))
'''
Loaded 400000 word vectors.
'''然後,我們把訓練集的單詞從embeddings_index遍歷,作為embedding層輸入的權重的初始化。
# create a weight matrix for words in training docs
embedding_matrix = zeros((vocab_size, 100))
for word, i in t.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector現在我們可以像以前那樣定義我們的模型,訓練和評估。
關鍵區別是嵌入層可是用GloVe字嵌入權重進行遷移。我們選擇了100維版本,因此嵌入層必須用output_dim定義為100。最後,我們不更新此模型中學習的單詞權重,因此我們將將模型的可訓練屬性設定為False。
e= Embedding(vocab_size, 100, weights=[embedding_matrix], input_length=4, trainable=False)完整的工作程式碼如下所示:
from numpy import asarray
from numpy import zeros
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Embedding
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
# prepare tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
vocab_size = len(t.word_index) + 1
# integer encode the documents
encoded_docs = t.texts_to_sequences(docs)
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
# load the whole embedding into memory
embeddings_index = dict()
f = open('datasets\glove.6B\glove.6B.100d.txt', 'rb')
for line in f:
values = line.split()
word = values[0]
coefs = asarray(values[1:], dtype='float32')
# 資料集中的word都是bytes型別,必須將bytes型別的word轉為str。轉換程式碼:str(word, encoding='utf-8')
embeddings_index[str(word, encoding='utf-8')] = coefs
f.close()
print('Loaded %s word vectors.' % len(embeddings_index))
# create a weight matrix for words in training docs
embedding_matrix = zeros((vocab_size, 100))
for word, i in t.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# define model
model = Sequential()
e = Embedding(vocab_size, 100, weights=[embedding_matrix], input_length=4, trainable=False)
model.add(e)
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
# fit the model
model.fit(padded_docs, labels, epochs=50, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))
'''
Accuracy: 100.000000
'''我們進一步分析將模型的可訓練屬性設定為False時,embedding的權重是否發生了改變。
weight = model.get_weights()經過測試,可以發現:
weight[0]是embedding層的權重。與embedding_matrix對比,可以發現,當設定trainable=False時初始時的權值沒有改變。當設定trainable=True時,初始時的權值在訓練時更新了。
參考文獻
【1】How to Use Word Embedding Layers for Deep Learning with Keras
【4】字詞的向量表示法
【5】神經網路中embedding層作用——本質就是word2vec,資料降維,同時可以很方便計算同義詞(各個word之間的距離),底層實現是2-gram(詞頻)+神經網路