
自然語言處理中傳統詞向量表示VS深度學習語言模型(三):word2vec詞向量
在前面的部落格中,我們已經梳理過語言表示和語言模型,之所以將這兩部分內容進行梳理,主要是因為分散式的詞向量語言表示方式和使用神經網路語言模型來得到詞向量這兩部分,構成了後來的word2vec的發展,可以說是word2vec的基礎。
1.什麼是詞向量
詞向量,簡單的說,就是使用固定維度的向量來表示一個詞,分為One-Hot Representation和Distributed Representation兩種,詳細解釋在前面已經講過,這裡不再贅述。在實際應用中,基於one-hot的向量雖然在傳統的機器學習演算法中取得了不錯的成績,但Distributed 的向量可以說更加具有魯棒性,因為其考慮了語義的資訊,更具合理性。借鑑大神的
接下來所要講的word2vec就是Distributed Representation詞向量的一種形式。
2. word2vec
詞向量的訓練方式在前面已經說過,就是通過訓練神經網路語言模型(NNLM)來獲得,而word2vec是為一群用來產生詞向量的相關模型。word2vec 是 Google 於 2013 年開源推出的一個用於獲取 word vector 的工具包,它簡單、高效。NNLM一般是一個三層的神經網路結構(這裡,很多人將word2vec稱為deep learning,其實從網路結構上來看,遠沒有達到deep learning的層次):輸入層、隱藏層和輸出層(softmax層)。
word2vec是如何定義資料的輸入和輸出呢?主要分為兩種:CBOW模型(Continuous Bag-of-Words Model)和Skip-Gram模型(Continuous Skip-Gram Model)。在Tomas Mikolov的論文中,CBOW和Skip-Gram的結構其實也非常簡單,都只包含三層結構:輸入層(INPUT)、投影層(PROJECTION)(或者說是隱藏層是一個意思)和輸出層(OUTPUT)。CBOW是在已知上下文w(t-2)、w(t-1)、w(t+1)和w(t+2)的情況下來預測中心詞w(t),其結構如下左圖;Skip-Gram是在已知中心詞w(t)的情況下來預測上下文
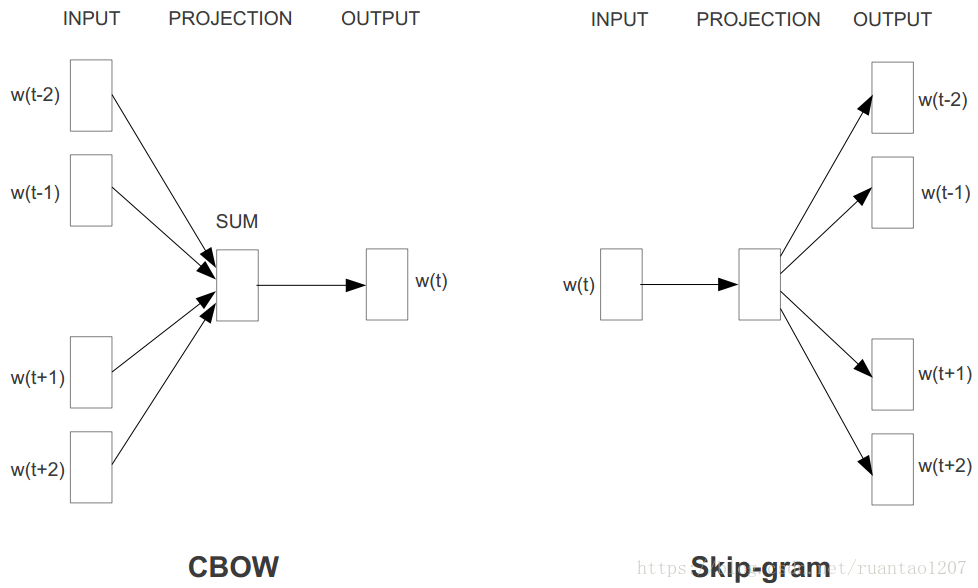
仔細一想,是不是覺得CBOW模型其實特別類似於n-gram,只不過n-gram是隻使用歷史資訊來預測當前詞,而CBOW使用了當前詞的左右資訊來同時預測。而Skip-gram只不過是將CBOW模型反過來預測罷了。
2.1 模型定義
我們設定一個大小為 t 的視窗,在語料庫裡隨機抽取一個詞 w(t),這個核心詞的前 c 個和後 c 個單詞構成該詞的上下文,即
context(w(t)) = (w(t-c),...,w(t-1),w(t+1),...,w(t+c))
CBOW模型:最大化P(w(t)|context(w(t))),用context去預測詞w;
Skip-Gram模型:最大化P(context(w(t))|w(t)),用詞w去預測context。
但是在word2vec的第一篇論文【1】中,其實並沒有給出具體模型的構建,而是在第二篇論文【2】中提到了Skip-Gram模型公式,即優化目標。
給定一個訓練的序列w1,w2,...,wT,具體是最大化均值對數似然概率(Average Log Probability):
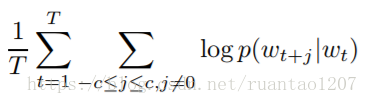
而兩個詞之間的 skip-gram 概率 p(wt+j|wt) 可以這樣定義,就是在最後使用了一個Softmax:
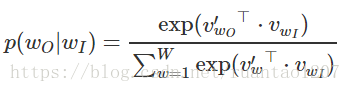
分子是把 輸入詞w 對應的詞向量和 輸出context(w) 裡的某個詞對應的詞向量做內積,分母是把 輸入詞w 對應的詞向量和詞彙表中的所有詞向量做內積。最後得到的結果要經過一個 Softmax,得到真正的概率。
由上述公式可知,在分母中,需要對輸入詞w和詞彙表中的所有詞的詞向量做內積運算,時間複雜度過高,開銷太大,因此效率低下。例如,詞彙表的大小為|V|,一般包含(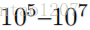
特別鳴謝: