
快速上手多機多卡的分散式tensorflow
快速上手多機多卡的分散式tensorflow
終於又有時間和成果拿出來和大家分享,實在不容易,之前由於臨時更換任務加上入職事情多斷更了很久,現在主要在做一些KG和KGQA方面的工作。今天要和大家分享的是最近在工作中實現的分散式tensorflow。(BTW打個廣告~NLP和DL討論歡迎加群~二維碼在末尾~)
理論在這裡就不詳細介紹了,說說對一些概念自己的理解吧:
(1)task->server->cluster:
這裡其實應該也是分散式計算的一些基本概念,在分散式tensorflow中,採用的主從模式,即master-slave模式。有一個總控伺服器來負責傳遞資料和排程,若干從節點伺服器負責計算。在這裡,我們所說的每一個伺服器也就對應一個server。在tensorflow中,總控伺服器其實叫做引數伺服器(Parameter Server),在實際操作中負責引數的更新,但是並不負責圖的計算。那麼負責計算的是什麼呢?在這裡就是工作節點(工作伺服器)。在每個工作伺服器上,tensorflow都會儲存整張計算圖並且獨立的進行計算。不過值得注意的是,儘管叫server級別,但是不一定一個節點就只能是一個伺服器,他僅僅對應伺服器上的一個埠,使用某個伺服器的一部分資源(或者所有資源),同時若干個工作節點也可以放在一個資源足夠的伺服器上,在後面的程式碼中你會看到我就是這麼做的。注意到之前說的引數伺服器和工作伺服器都是server級別的,在這個級別下,每個伺服器可以有若干個task,每個task對應一個具體的計算操作。在這個級別之上,若干個工作節點可以構成一個計算叢集,而若干個引數伺服器可以構成一個引數伺服器叢集。
(2)gRPC:
這裡主要放一些乾貨,介紹一些谷歌自己開發的通訊協議gRPC,這也是分散式tensorflow用來做多機程序間通訊的協議。額外想提以下的其實是一些tradeoff,由於現在只是跑通了demo而沒有在大的模型上做實驗,有一個需要驗證的問題就是:在沒有足夠多臺伺服器的情況下,到底是使用兩臺伺服器,將引數更新和圖計算分開,降低整個伺服器的壓力,還是應該單機多卡,減少任務之間的通訊開銷,這個問題需要在後面的工作中驗證,也希望有經驗的同學給出意見。
gRPC是一個高效能、開源和通用的RPC框架,面向移動和HTTP/2設計。目前提供C、Java和Go語言版本,分別是grpc、grpc-java、grpc-go。gRPC基於HTTP/2標準設計,帶來諸如雙向流、流控、頭部壓縮、單TCP連線上的多複用請求等特性。這些特性使得其在移動裝置上表現更好,更省電和節省空間佔用。gRPC由google開發,是一款語言中立、平臺中立、開源的遠端過程呼叫系統。在gRPC裡客戶端應用可以像呼叫本地物件一樣直接呼叫另一臺不同機器上服務端應用的方法,使得你能夠更容易地建立分散式應用和服務。與許多RPC系統類似,gRPC也是基於以下理念:定義一個服務,指定其能夠被遠端呼叫的方法(包括引數和返回型別)。在服務端實現這個介面,並執行一個gRPC伺服器來處理客戶端呼叫。在客戶端擁有一個存根能夠像服務端一樣的方法。
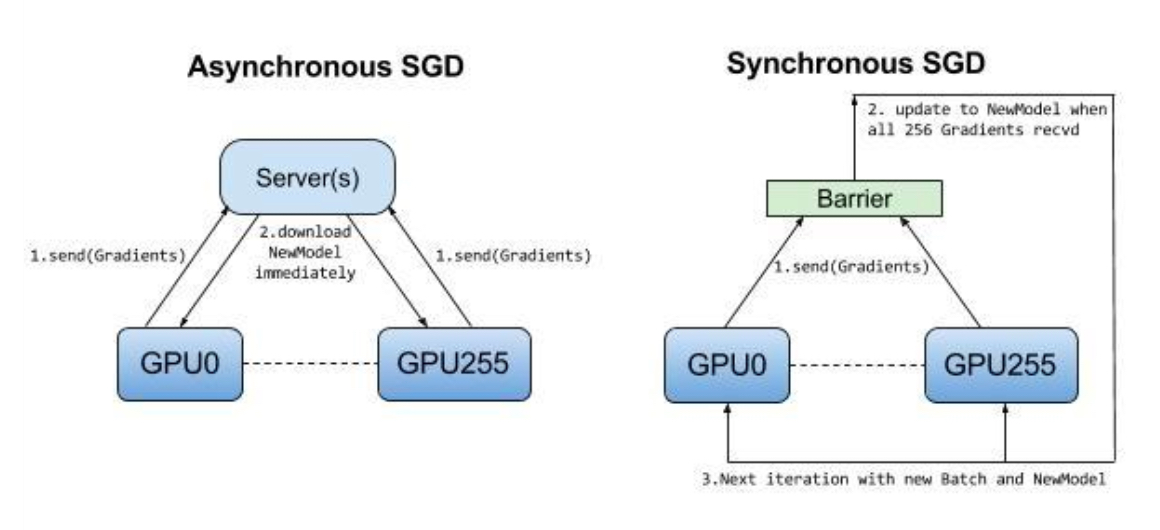
(3)同步更新和非同步更新
在下面的demo裡面其實沒有明確的實現同步或非同步更新,因為這個例子實在太小,即使實現了也沒有太大區別。在非同步更新中,沒有任何裝置等待來自任何其他裝置的模型更新。這些裝置可以獨立執行並與對等裝置共享結果,或者通過一個或多個引數伺服器進行通訊。在同步更新中,每個工作節點需要等待其他工作節點的結果然後一起傳送到引數伺服器進行更新。在這裡的tradeoff就是同步更新可能會拖慢整個訓練的速度因為要等待最慢的一個節點,非同步更新很快,但是很有可能剛剛學到的正確梯度又被接著來的錯誤梯度抵消。下面的圖簡要描述了這兩種更新模式的區別。
好了,理論說完了,現在要展現我和其他博主不一樣的地方了:直接上能跑的程式碼!對於程式碼的解釋直接見註釋部分。注意:執行程式碼需要在每一個節點分別執行一次,並不是一勞永逸的哦(雖然我最開始也是這麼覺得的)執行的命令如下:(demo修改自https://github.com/TracyMcgrady6/Distribute_MNIST,特別感謝)
python distributed.py --job_name=ps --task_index=0 #在引數伺服器上執行,啟動引數伺服器 python distributed.py --job_name=worker --task_index=0 #在工作節點上執行,啟動工作節點0 python distributed.py --job_name=worker --task_index=1 #在工作節點上執行,啟動工作節點1
上程式碼~這個程式碼其實是用來訓練minist的,我用的是兩個RTX2080(有木有很羨慕~),速度有多快呢?大概不到30秒就訓練完了10000步,差點沒來得及給同事看~如果有同學跑下面的程式碼遇到問題可以找我要原始碼~郵箱見上一條~
# encoding:utf-import math
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
import tempfile
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
flags = tf.app.flags
IMAGE_PIXELS = 28
# 定義預設訓練引數和資料路徑
#tf.flags其實就是定義一些命令列引數
flags.DEFINE_string('data_dir', '/tmp/mnist-data', 'Directory for storing mnist data')
flags.DEFINE_integer('hidden_units', 100, 'Number of units in the hidden layer of the NN')
flags.DEFINE_integer('train_steps', 10000, 'Number of training steps to perform')
flags.DEFINE_integer('batch_size', 100, 'Training batch size ')
flags.DEFINE_float('learning_rate', 0.01, 'Learning rate')
# 定義分散式引數
# 引數伺服器parameter server節點
flags.DEFINE_string('ps_hosts', '192.168.6.156:22223', 'Comma-separated list of hostname:port pairs')
# 兩個worker節點
flags.DEFINE_string('worker_hosts', '192.168.6.164:22221,192.168.6.164:22220',
'Comma-separated list of hostname:port pairs')
# 設定job name引數
flags.DEFINE_string('job_name', None, 'job name: worker or ps')
# 設定任務的索引
flags.DEFINE_integer('task_index', None, 'Index of task within the job')
# 選擇非同步並行,同步並行,在本程式中其實沒有用到
flags.DEFINE_integer("issync", None, "是否採用分散式的同步模式,1表示同步模式,0表示非同步模式")
FLAGS = flags.FLAGS
def main(unused_argv):
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
if FLAGS.job_name is None or FLAGS.job_name == '':
raise ValueError('Must specify an explicit job_name !')
else:
print ('job_name : %s' % FLAGS.job_name)
if FLAGS.task_index is None or FLAGS.task_index == '':
raise ValueError('Must specify an explicit task_index!')
else:
print ('task_index : %d' % FLAGS.task_index)
ps_spec = FLAGS.ps_hosts.split(',')
worker_spec = FLAGS.worker_hosts.split(',')
# 建立叢集
num_worker = len(worker_spec)
cluster = tf.train.ClusterSpec({'ps': ps_spec, 'worker': worker_spec})
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == 'ps':
server.join()
is_chief = (FLAGS.task_index == 0)
# worker_device = '/job:worker/task%d/cpu:0' % FLAGS.task_index
#難點其實在這裡,通過worker_device指定在同一臺伺服器上的不同顯示卡作為工作節點
with tf.device(tf.train.replica_device_setter(
worker_device = '/job:worker/task:%d/gpu:%d' %(FLAGS.task_index, FLAGS.task_index),
ps_device = '/job:ps/cpu:0',
cluster=cluster
)):
global_step = tf.Variable(0, name='global_step', trainable=False) # 建立紀錄全域性訓練步數變數
hid_w = tf.Variable(tf.truncated_normal([IMAGE_PIXELS * IMAGE_PIXELS, FLAGS.hidden_units],
stddev=1.0 / IMAGE_PIXELS), name='hid_w')
hid_b = tf.Variable(tf.zeros([FLAGS.hidden_units]), name='hid_b')
sm_w = tf.Variable(tf.truncated_normal([FLAGS.hidden_units, 10],
stddev=1.0 / math.sqrt(FLAGS.hidden_units)), name='sm_w')
sm_b = tf.Variable(tf.zeros([10]), name='sm_b')
x = tf.placeholder(tf.float32, [None, IMAGE_PIXELS * IMAGE_PIXELS])
y_ = tf.placeholder(tf.float32, [None, 10])
hid_lin = tf.nn.xw_plus_b(x, hid_w, hid_b)
hid = tf.nn.relu(hid_lin)
y = tf.nn.softmax(tf.nn.xw_plus_b(hid, sm_w, sm_b))
cross_entropy = -tf.reduce_sum(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
opt = tf.train.AdamOptimizer(FLAGS.learning_rate)
train_step = opt.minimize(cross_entropy, global_step=global_step)
# 生成本地的引數初始化操作init_op
init_op = tf.global_variables_initializer()
train_dir = tempfile.mkdtemp()
sv = tf.train.Supervisor(is_chief=is_chief, logdir=train_dir, init_op=init_op, recovery_wait_secs=1,
global_step=global_step)
if is_chief:
print ('Worker %d: Initailizing session...' % FLAGS.task_index)
else:
print ('Worker %d: Waiting for session to be initaialized...' % FLAGS.task_index)
#sess = sv.prepare_or_wait_for_session(server.target)
#第二個坑在這裡,必須要設定allow_soft_placement為True讓tensorflow可以自動找到最適合的裝置,否則會說不存在gpu的kernel,同時建議執行時只安裝tensorflow_gpu
config = tf.ConfigProto(allow_soft_placement = True)
sess = sv.prepare_or_wait_for_session(server.target, config=config)
print ('Worker %d: Session initialization complete.' % FLAGS.task_index)
time_begin = time.time()
print ('Traing begins @ %f' % time_begin)
local_step = 0
while True:
batch_xs, batch_ys = mnist.train.next_batch(FLAGS.batch_size)
train_feed = {x: batch_xs, y_: batch_ys}
_, step = sess.run([train_step, global_step], feed_dict=train_feed)
local_step += 1
now = time.time()
print ('%f: Worker %d: traing step %d dome (global step:%d)' % (now, FLAGS.task_index, local_step, step))
if step >= FLAGS.train_steps:
break
time_end = time.time()
print ('Training ends @ %f' % time_end)
train_time = time_end - time_begin
print ('Training elapsed time:%f s' % train_time)
val_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
val_xent = sess.run(cross_entropy, feed_dict=val_feed)
print ('After %d training step(s), validation cross entropy = %g' % (FLAGS.train_steps, val_xent))
sess.close()
if __name__ == '__main__':
tf.app.run()