
“希希敬敬對”團隊作業-敏捷衝刺-3
阿新 • • 發佈:2018-11-26
“希希敬敬對”百度貼吧小爬蟲任務計劃:
今天的團隊討論照片:

龍江騰(隊長) 201810775001
完成任務“對貼吧前10頁進行爬取任務”,明天將完成“爬取發帖主題人的主題回覆資料”程式碼review。
楊希 201810812008
完成“對貼吧前10頁進行爬取任務”程式碼review,明天將完成程式碼,實現“爬取發帖主題人的主題回覆資料”功能。
何敬上 201810812004
完成任務“對貼吧前10頁進行爬取任務”,明天將完成“爬取發帖主題人的主題回覆資料”程式碼review。
遇到的問題:
最開始不能對需要爬取到的html程式碼塊準確定位,後來改進正則表示式成功爬取到需要的資料,並完整爬取到10頁內所有需要的資料。
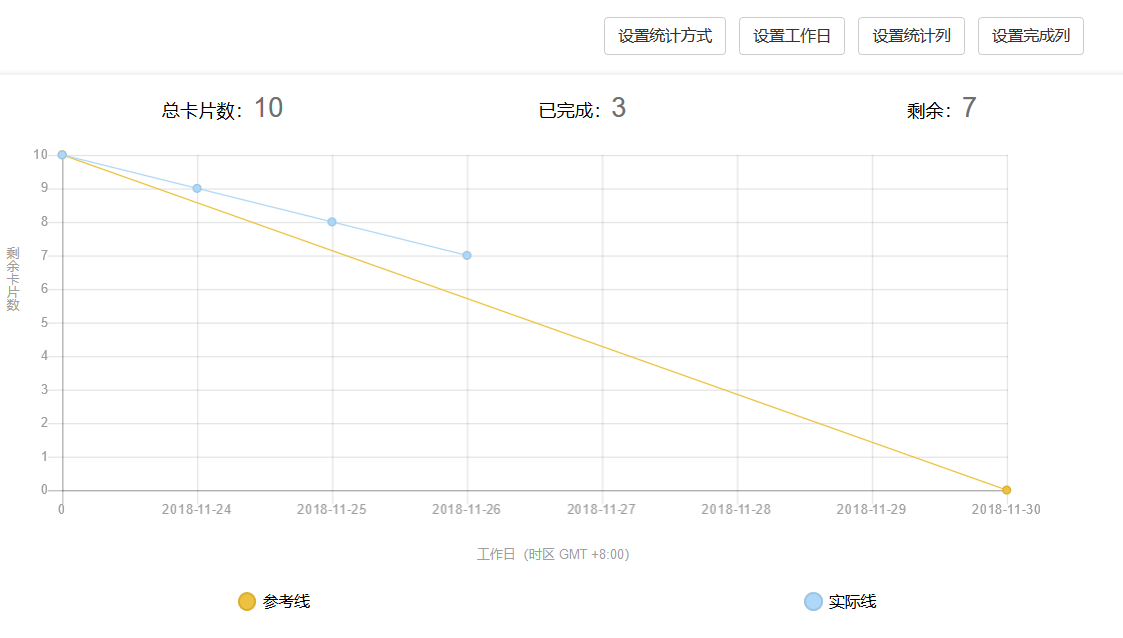
燃盡圖:
程式程式碼:
# 找到資料對應的網頁,分析網頁結構找到資料所在的標籤位置
#模擬HTTP請求,向伺服器傳送這個請求,獲取到伺服器返回給我們的HTML
import re
from urllib import request
class BDTBCrawler():
url = "http://tieba.baidu.com/f?kw=%E4%B8%9C%E5%8D%8E%E7%90%86%E5%B7%A5%E5%A4%A7%E5%AD%A6&ie=utf-8"
Name_num_list = []
def __init__(self, url):
BDTBCrawler.url = url
#匹配到包含了主題作者和帖子回覆數關鍵字的標籤
root_pattern = '<span class="threadlist_rep_num center_text"([\s\S]*?)data-field='
#模擬HTTP請求,向伺服器傳送請求,獲取到伺服器返回給我們的HTML
def __fetch_content(self):
r = request.urlopen(BDTBCrawler.url)
htmls = r.read()
# 將伺服器返回的位元組碼轉換成字串格式
htmls = str(htmls, encoding='utf-8')
return htmls
def __analysis(self, htmls):
#root_html獲取包含了主題作者和帖子回覆數關鍵字的標籤
root_html = re.findall(BDTBCrawler.root_pattern, htmls)
return root_html
def go(self):
#使用for迴圈爬取前10頁
htmls = ''
for i in range(0, 10):
pn = i * 50
#page記錄當前爬取頁面需要在URL上新增的字串
page = '&pn=' + str(pn)
BDTBCrawler.url += page
htmls += self.__fetch_content()
root_html = self.__analysis(htmls)
print(root_html)
crawler = BDTBCrawler(BDTBCrawler.url)
crawler.go()
經執行,獲取某貼吧前10頁html功能已實現。