
【人工智慧】NCC S1 5.6Tops高算力神經網路計算卡
阿新 • • 發佈:2018-11-26
基於AI專用的APiM架構,無需外部快取的模組化深度神經網路學習加速器,用於高效能邊緣計算領域,可作為基於視覺的深度學習運算和AI演算法加速。外形小巧,極低功耗,擁有著強勁算力,配套完整易用的模型訓練工具、網路訓練模型例項,搭配專業硬體平臺,可快速應用於人工智慧行業中。

5.6Tops強勁算力 NCC S1基於AI嵌入式神經網路處理器(NPU),擁有28000個並行神經計算核,支援晶片上並行與原位計算,峰值運算能力高達5.6Tops,是市面上其他方案的數十倍。其強勁的算力,能進行復雜的高密度計算,適用於高效能邊緣計算領域。

AI處理架構APiM 採用AI專用的MPE矩陣引擎和APiM(AI processing in Memory,儲存中的AI處理)架構,以革命性的方式處理AI,一次升級網路預載入,無需指令、匯流排,無需外部DDR快取,大量資料可直接輸入/輸出矽片,從而大大提高了AI的處理速度,降低處理能耗。

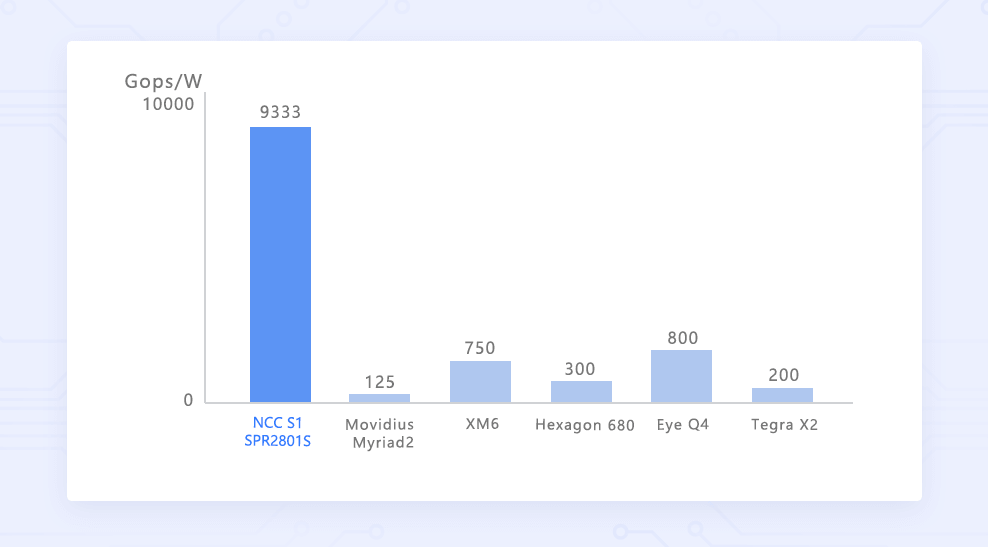
9.3 Tops/W超高效能 NCC S1神經網路計算卡的核心採用28nm工藝製程,在2.8 Tops算力時功率僅300mW,效率能耗比高達為9.3 Tops/W,在擁有超強的算力同時保持了極低的能耗,讓其應用在終端裝置的邊緣計算領域中極具優勢。
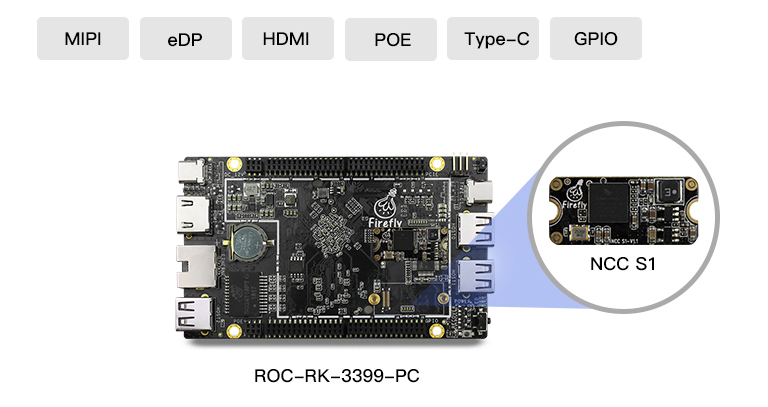
高效能硬體平臺 NCC S1神經網路計算卡可搭配ROC-RK3399-PC開源主機板,配置高效能RK3399六核處理器,擁有豐富的硬體介面,可快速整合邊緣計算的硬體平臺,搭建產品原型,加速AI產品的專案程序。
配套模型訓練工具 提供基於PyTorch完整易用的模型訓練工具PLAI(People Learn AI), 可在Windows 10與Ubuntu 16.04系統上開發,更簡單快捷地新增自定義網路模型,大大降低了使用AI的技術門檻,讓更多人能更容易開啟AI的大門。

提供網路訓練模型 支援GNet1,GNet18和GNetfc三種網路訓練模型例項,後續會持續增加網路例項,輕鬆在裝置上測試大量深度學習應用。

進入Firefly官網,可瞭解NCC S1神經網路計算卡更多內容。