
FAST AI Deep Learning Note
FastAI github:https://github.com/fastai/fastai/tree/master/courses
Video:https://www.bilibili.com/video/av18904696
Lesson1
11:15
conda env update
42:40
Image Classification可用於圍棋AI中,給定一個棋盤的佈局(影象),判斷該佈局是否能贏
43:30
在反欺詐任務中,將使用者滑鼠移動的軌跡畫出來,對該影象進行分類
59:15
一個線上展示影象卷積效果的網站:http://setosa.io/ev/image-kernels/
73:00
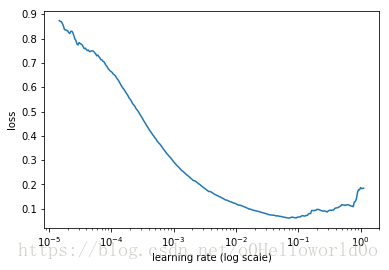
選擇learning rate的論文:
首先從一個很小的learning rate開始,每處理一個batch data時,增加learning rate,記錄每一個learning rate梯度下降後的loss(視訊中似乎沒說是普通梯度下降還是別的優化演算法),畫出一個loss隨learning rate變化的影象(圖中的log scale表示橫座標是不均勻的)
斜率越大表示loss下降得越快,如learning rate=1e-3時,斜率最大,loss下降得越快
但我們想要學習率儘可能大一些,於是選擇learning rate=1e-2,此時斜率仍然足夠大
如果選擇learning rate=0.1就不行,因為此時loss已經不再減小了
77:25
兩種增加learning rate的方式:線性增加和指數級增加
82:15
忘記函式的引數是什麼的時候,Shift+Tab按1次
Shift+Tab按2次,檢視文件
Shift+Tab按3次,文件展示在底部
83:30
使用?檢視文件,使用??檢視原始碼
84:45
按H,顯示Jupyter Notebook的快捷鍵
Lesson 8
視訊連結:https://www.bilibili.com/video/av18904696/?p=8
使用cv2比PIL更快,並且在多執行緒下更安全
90:21
使用dict建立DataFrame時,不保證列的順序,再指定columns就可以保證列的順序
91:50
在Image Classification中,通常目標物體很大,且位於影象中心位置,可以做RandomCrop
而在Object Detection中,存在很多小物體,並且小物體可能位於影象邊緣,因此不做任何Crop操作,直接將矩形影象squish成正方形
直覺上squish操作使影象中的物體變形了,但“still work pretty well”
95:00
next( dataloader_obj ),報錯’DataLoader’ object is not an iterator.
改成next( iter( dataloader_obj ) )
101:40
In [130]的程式碼,畫出多幅影象,很有用
115:40
對於bounding box regression,使用label = (row1, col1, row2, col2),即bounding box的左上角和右下角在影象矩陣中的行號和列號,直接使用畫素值,而沒有進行歸一化
116:30
fastai中,使用tfm_y=TfmType.COORD來實現bounding box的data augmentation
118:40
對於bounding box regression,使用nn.L1loss()
Lesson 9,連結:https://www.bilibili.com/video/av18904696/?p=9
09:20
影象增強時,最多旋轉30°,bounding box隨之旋轉,變成斜的矩形,取外接矩形即可
缺點是外接矩形所包含的範圍變大了,不再精確表示物體的邊界位置,視訊中解決的辦法是使用小一點的旋轉角度,如最多旋轉3°,並且以0.5的概率旋轉
13:10
In [82]受到的啟發:可以對Dataset使用陣列下標,直接獲取某個樣本,如dataset[0]
17:50
在Single object detection的方案中,網路輸出層節點數為4+len( cat ),為線性層,將座標預測值經sigmoid變換到(0, 1),然後乘以224
18:15
Jeremy建議把BatchNorm放在Relu之後,然後再BatchNorm再接上Dropout
但是他又承認有時又會把BatchNorm放在Relu之前
ps:所以別總是糾結這個問題,隨便選一種方案就行了
21:10
Loss的一部分是bounding box迴歸的L1loss,另一部分是分類的cross entropy loss,它們的取值其實是不在一個數量級的
在實際執行中觀察它們的取值,發現將cross entropy乘以20之後二者的值才相當
22:03
有一個矛盾的地方,ResNet在AvgPool層中對空間維度上求了平均值,其實已經丟失了能夠準確預測bounding box的資訊(意思是AvgPool適合做分類任務,而不適合做檢測),然而後面又加了全連線層預測bounding box,這樣不就是先把資訊丟失了,然後再“創造”資訊嗎?
34:30
視訊中展示的這一頁PPT
YOLO:Single object detection方案中,網路輸出層節點數為4+C,只能檢測1個物體,現在我想檢測16個物體該怎麼辦?令網路輸出層節點數為16×(4+C)
SSD:放棄使用全連線層,卷積層得到的feature map維度為7×7×512,那麼可以使用一個卷積層將該feature map變化為4×4×(4+C),同樣可以檢測16個物體(此處將通道數變為4+C)
37:40
假設我們最終得到了一個2×2×(4+C)的feature map,將原始影象劃分為2×2的網格
以影象上左上角的格子為例,為什麼這個格子要負責檢測落在其中的物體?
原因是,最後feature map空間維度上“左上角”的activation,對應的receptive field正好就是影象上左上角的格子
46:10
本來使用卷積就可以直接得到4×4×(4+C)的feature map,但是Jeremy認為還是分開進行卷積好一些,因此定義OutputConv,分別得到4×4×4和4×4×C的feature map,然後將它們拼接起來,得到最終的4×4×(4+C)的feature map
47:25
將最終的4×4×(4+C)的Tensor Flatten為16×(4+C),是為了方便計算loss
54:55
影象被劃分為4×4的網格,每一個格子,在不同的paper中被稱為anchor box,prior box,default box
56:55
檢視影象的真實標記中的每一個bounding box,將每一個bounding box分配到某一個格子,分配的依據是Jacard Index(也稱為IOU)最大
具體來說,假設真實標記有3個bounding box,座標形成一個3×4的Tensor,再假設影象劃分為4×4的網格,共16個格子,座標形成一個16×4的Tensor,於是可以算出每個bounding box與每個格子的IOU,得到一個3×16的Tensor
map_to_ground_truth函式是幹嘛的?
68:20
使用binary cross entropy,而不是softmax,為什麼?沒聽懂
76:00
建立更多的anchor box,可以指定許多不同形狀的anchor box
原先的版本,在每一個位置只有一個正方形的anchor box,現在我們可以在同一位置指定更多形狀的anchor box
76:20
另一種建立更多的anchor box的方法
原先的版本,在每一個位置只有一個正方形的anchor box,現在我們可以將兩個anchor box合併起來,構成一個新的anchor box,甚至可以將所有anchor box合併起來,構成一個最大的anchor box
91:20
現在anchor box有4×4的,有2×2的,有4×4的,那麼我們就可以構建3個OutputConv,分別生成4×4×(4+C),2×2×(4+C),1×1×(4+C)的feature map
Lesson14,視訊連結:https://www.bilibili.com/video/av18904696/?p=14
99:50
nn.ConvTranspose2d輸出的Tensor為batch_size×1×128×128,而我們想要batch_size×128×128的Tensor,使用Lambda層去掉1的維度