
FCN學習:Semantic Segmentation(摘自知乎)
源文章地址:https://zhuanlan.zhihu.com/p/22976342?utm_source=tuicool&utm_medium=referral
FCN學習:Semantic Segmentation
![]()
計算機視覺及深度學習
366 人讚了該文章
感謝
@鄭途 @麥田守望者對標籤影象生成的研究和討論,這幾天研究了一下,補充如下。
-----------------------------------------------------分割線------------------------------------------------------------
謝謝
的評論,這一篇確實有很多點沒有分析完,當時想著後來加上去,但是由於工作的關係,也就不了了之了。最近終於忙完了一個專案,有時間更新一下文章了!
----------------------------------------------------- 分割線------------------------------------------------------------
本來這一篇是想寫Faster-RCNN的,但是Faster-RCNN中使用了RPN(Region Proposal Network)替代Selective Search等產生候選區域的方法。RPN是一種全卷積網路,所以為了透徹理解這個網路,首先學習一下FCN(fully convolutional networks)
全卷積網路首現於這篇文章。這篇文章是將CNN結構應用到影象語義分割領域並取得突出結果的開山之作,因而拿到了CVPR 2015年的best paper honorable mention.
影象語義分割,簡而言之就是對一張圖片上的所有畫素點進行分類
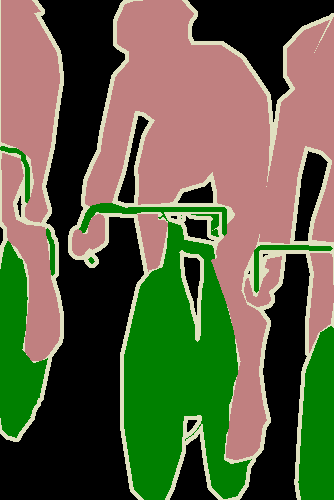
如上圖就是一個語義分割的例子,不同的顏色代表不同的類別
下面簡單介紹一下論文,重點介紹文中的那幾個結構:
一.論文解讀
1.Introduction
CNN這幾年一直在驅動著影象識別領域的進步。無論是整張圖片的分類(ILSVRC),還是物體檢測,關鍵點檢測都在CNN的幫助下得到了非常大的發展。但是影象語義分割不同於以上任務,這是個空間密集型的預測任務,換言之,這需要預測一幅影象中所有畫素點的類別
以往的用於語義分割的CNN,每個畫素點用包圍其的物件或區域類別進行標註,但是這種方法不管是在速度上還是精度上都有很大的缺陷。
本文提出了全卷積網路(FCN)的概念,針對語義分割訓練一個端到端,點對點的網路,達到了state-of-the-art。這是第一次訓練端到端的FCN,用於畫素級的預測;也是第一次用監督預訓練的方法訓練FCN。
2.Fully Convolutional networks & Architecture
下面我們重點看一下FCN所用到的三種技術:
1.卷積化(convolutionalization)
分類所使用的網路通常會在最後連線全連線層,它會將原來二維的矩陣(圖片)壓縮成一維的,從而丟失了空間資訊,最後訓練輸出一個標量,這就是我們的分類標籤。
而影象語義分割的輸出則需要是個分割圖,且不論尺寸大小,但是至少是二維的。所以,我們丟棄全連線層,換上卷積層,而這就是所謂的卷積化了。
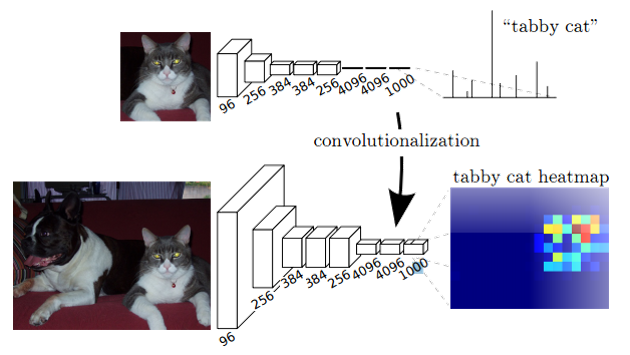
這幅圖顯示了卷積化的過程,圖中顯示的是AlexNet的結構,簡單來說卷積化就是將其最後三層全連線層全部替換成卷積層
2.上取樣(Upsampling)
上取樣也就是對應於上圖中最後生成heatmap的過程。
在一般的CNN結構中,如AlexNet,VGGNet均是使用池化層來縮小輸出圖片的size,例如VGG16,五次池化後圖片被縮小了32倍;而在ResNet中,某些卷積層也參與到縮小圖片size的過程。我們需要得到的是一個與原影象size相同的分割圖,因此我們需要對最後一層進行上取樣,在caffe中也被稱為反捲積(Deconvolution),可能叫做轉置卷積(conv_transpose)更為恰當一點。
為理解轉置卷積,我們先來看一下Caffe中的卷積操作是怎麼進行的
在caffe中計算卷積分為兩個步驟:
1)使用im2col操作將圖片轉換為矩陣
2)呼叫GEMM計算實際的結果
簡單來說就是以下的矩陣相乘操作:
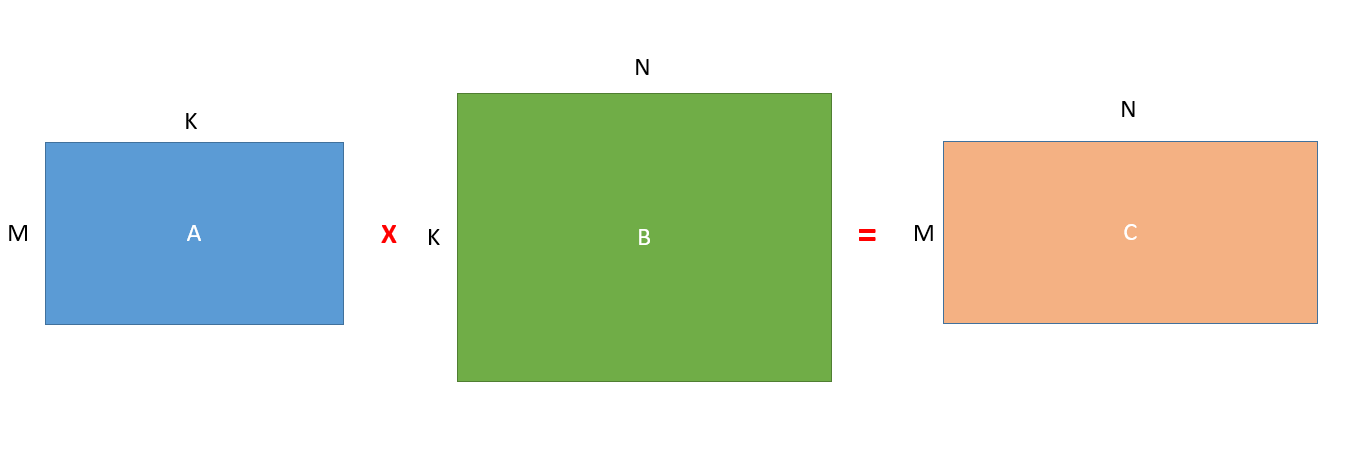
下面使用一下
大神在知乎上解釋Caffe計算卷積的圖來解釋一下上面的操作:
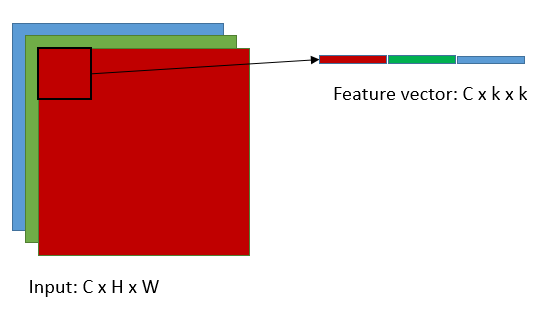
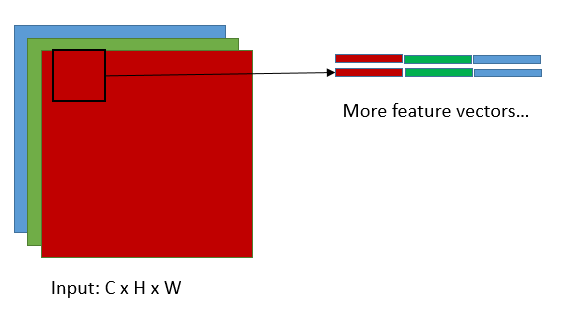
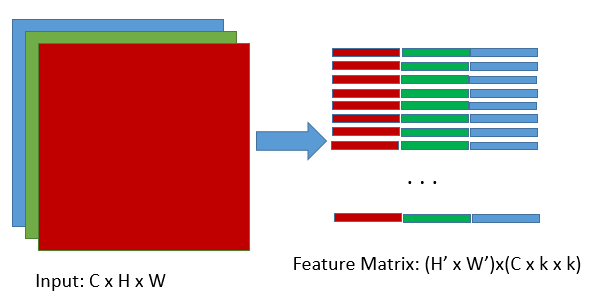
這是將輸入轉換為feature matrix的過程(im2col),這裡的feature matrix對應於上圖中的矩陣B的轉置,k即是卷積核的尺寸,C為輸入的維度,矩陣B中的K=C x k x k,當然N就等於H' x W'了,H',W'對應於輸出的高和寬,顯然H'=(H-k+2*pad)/stride+1,W'=(W-k+2*pad)/stride+1,這組公式想必大家很熟悉了,就不加以解釋了,接下來我們看看A矩陣,
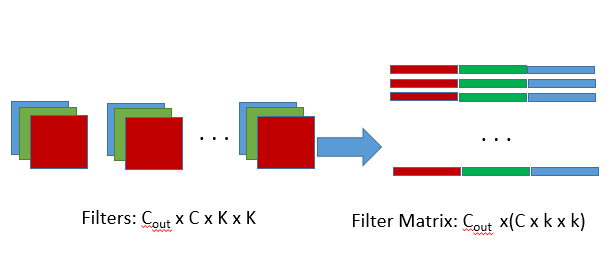
A矩陣對應於filter matrix,Cout是輸出的維度,亦即卷積核的個數,K= C x k x k.
所以在caffe中,先呼叫im2col將filters和input轉換為對應filter matrix(A)和feature matrix(B'),然後再用filter matrix乘以feature matrix的轉置,就得到了C矩陣,亦即輸出矩陣,再將C矩陣通過col2im轉換為對應的feature map,這就是caffe中完整的卷積的前向傳播過程。
那麼當反向傳播時又會如何呢?首先我們已經有從更深層的網路中得到的.
根據矩陣微分公式,可推得
,
Caffe中的卷積操作簡單來說就是這樣,那轉置卷積呢?
其實轉置卷積相對於卷積在神經網路結構的正向和反向傳播中做相反的運算。
所以所謂的轉置卷積其實就是正向時左乘,而反向時左乘
,即
的運算。
雖然轉置卷積層和卷積層一樣,也是可以train引數的,但是實際實驗過程中,作者發現,讓轉置卷積層可學習,並沒有帶來performance的提升,所以實驗中的轉置卷積層的lr全部被置零了
注意:在程式碼中可以看出,為了得到和原影象size一模一樣的分割圖,FCN中還使用了crop_layer來配合deconvolution層
3.跳躍結構(Skip Architecture)
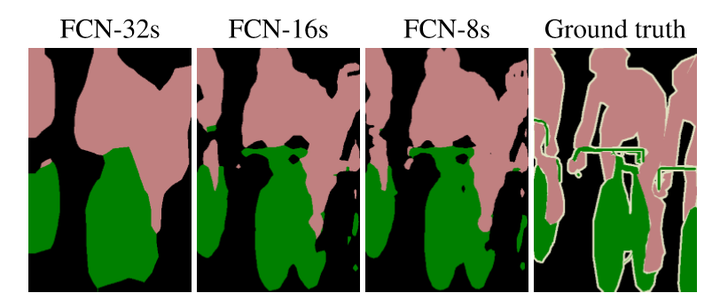
其實直接使用前兩種結構就已經可以得到結果了,但是直接將全卷積後的結果上取樣後得到的結果通常是很粗糙的。所以這一結構主要是用來優化最終結果的,思路就是將不同池化層的結果進行上取樣,然後結合這些結果來優化輸出,具體結構如下:
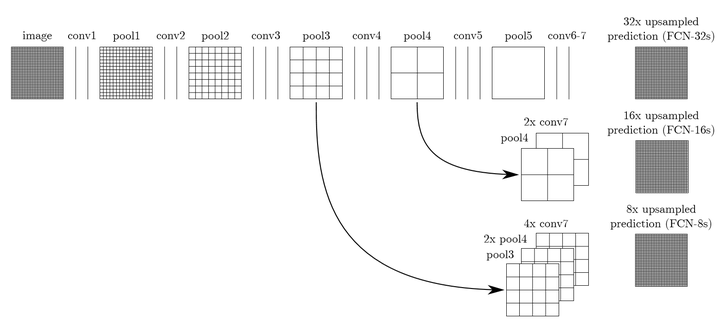
而不同的結構產生的結果對比如下:
二.實踐與程式碼分析
作者在github上開源了程式碼:Fully Convolutional Networks
git clone https://github.com/shelhamer/fcn.berkeleyvision.org.git
我們首先將專案克隆到本地
專案檔案結構很清晰,如果想train自己的model,只需要修改一些檔案路徑設定即可,這裡我們應用已經train好的model來測試一下自己的圖片:
我們下載voc-fcn32s,voc-fcn16s以及voc-fcn8s的caffemodel(根據提供好的caffemodel-url),fcn-16s和fcn32s都是缺少deploy.prototxt的,我們根據train.prototxt稍加修改即可。
-------------------------------------------------標籤影象生成--------------------------------------------------------
從VOCdevkit處下載VOC2012的訓練/驗證集,解壓之後,在SegmentationClass資料夾下可以看到標籤影象。
在PIL中,影象有很多種模式,如'L'模式,’P'模式,還有常見的'RGB'模式,模式'L'為灰色影象,它的每個畫素用8個bit表示,0表示黑,255表示白,其他數字表示不同的灰度。模式“P”為8位彩色影象,它的每個畫素用8個bit表示,其對應的彩色值是按照調色盤索引值查詢出來的。標籤影象的模式正是'P'模式,因此測試時要生成對應標籤影象的圖片的話,構建一個調色盤即可。

按照上圖,對應修改調色盤和infer.py,就可以測試我們自己的圖片了
import numpy as np
from PIL import Image
import caffe
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('data/pascal/VOCdevkit/VOC2012/JPEGImages/2007_000129.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0)
arr=out.astype(np.uint8)
im=Image.fromarray(arr)
palette=[]
for i in range(256):
palette.extend((i,i,i))
palette[:3*21]=np.array([[0, 0, 0],
[128, 0, 0],
[0, 128, 0],
[128, 128, 0],
[0, 0, 128],
[128, 0, 128],
[0, 128, 128],
[128, 128, 128],
[64, 0, 0],
[192, 0, 0],
[64, 128, 0],
[192, 128, 0],
[64, 0, 128],
[192, 0, 128],
[64, 128, 128],
[192, 128, 128],
[0, 64, 0],
[128, 64, 0],
[0, 192, 0],
[128, 192, 0],
[0, 64, 128]], dtype='uint8').flatten()
im.putpalette(palette)
im.show()
im.save('test.png')
如上述,對程式碼的主要修改是增加了一個調色盤,將L模式的影象轉變為P模式,得到類似標籤影象的圖片。
接下來,只需要修改script中的圖片路徑和model的路徑,就可以測試自己的圖片了:

---------------------------------------------------原測試結果---------------------------------------------------------

-----------------------------------------------------P模式測試結果--------------------------------------------------
這是我跑出來的最終結果,可以看出skip architecture對最終的結果確實有優化作用。
這裡沒有對最終結果上色,按照VOC的顏色設定之後,就可以得到和論文中一模一樣的結果了
下面是測試其他一些圖片的結果:


--------------------------------------------以下為對FCN中關鍵程式碼的分析-------------------------------------
這裡我們著重分析在VOC資料集上的程式碼,其他幾個資料集上的程式碼類似。
首先我們下載VOC2012資料集(根據data/pascal/README.md檔案下載),從中可以看到影象(JPEGImages)和ground truth(SegmentationClass).
看過了資料集之後,我們去voc-fcn32s下看一下train.prototxt,你會發現它的輸入層是作者自定義的python layer,也就是voc_layers.py裡面定義的,所以,我們來看一下voc_layers.py裡面的內容:
class VOCSegDataLayer(caffe.Layer):
"""
Load (input image, label image) pairs from PASCAL VOC
one-at-a-time while reshaping the net to preserve dimensions.
Use this to feed data to a fully convolutional network.
"""
def setup(self, bottom, top):
"""
Setup data layer according to parameters:
- voc_dir: path to PASCAL VOC year dir
- split: train / val / test
- mean: tuple of mean values to subtract
- randomize: load in random order (default: True)
- seed: seed for randomization (default: None / current time)
for PASCAL VOC semantic segmentation.
example
params = dict(voc_dir="/path/to/PASCAL/VOC2011",
mean=(104.00698793, 116.66876762, 122.67891434),
split="val")
"""
# config
params = eval(self.param_str)
self.voc_dir = params['voc_dir']
self.split = params['split']
self.mean = np.array(params['mean'])
self.random = params.get('randomize', True)
self.seed = params.get('seed', None)
# two tops: data and label
if len(top) != 2:
raise Exception("Need to define two tops: data and label.")
# data layers have no bottoms
if len(bottom) != 0:
raise Exception("Do not define a bottom.")
# load indices for images and labels
split_f = '{}/ImageSets/Segmentation/{}.txt'.format(self.voc_dir,
self.split)
self.indices = open(split_f, 'r').read().splitlines()
self.idx = 0
# make eval deterministic
if 'train' not in self.split:
self.random = False
# randomization: seed and pick
if self.random:
random.seed(self.seed)
self.idx = random.randint(0, len(self.indices)-1)
def reshape(self, bottom, top):
# load image + label image pair
self.data = self.load_image(self.indices[self.idx])
self.label = self.load_label(self.indices[self.idx])
# reshape tops to fit (leading 1 is for batch dimension)
top[0].reshape(1, *self.data.shape)
top[1].reshape(1, *self.label.shape)
def forward(self, bottom, top):
# assign output
top[0].data[...] = self.data
top[1].data[...] = self.label
# pick next input
if self.random:
self.idx = random.randint(0, len(self.indices)-1)
else:
self.idx += 1
if self.idx == len(self.indices):
self.idx = 0
def backward(self, top, propagate_down, bottom):
pass
def load_image(self, idx):
"""
Load input image and preprocess for Caffe:
- cast to float
- switch channels RGB -> BGR
- subtract mean
- transpose to channel x height x width order
"""
im = Image.open('{}/JPEGImages/{}.jpg'.format(self.voc_dir, idx))
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= self.mean
in_ = in_.transpose((2,0,1))
return in_
def load_label(self, idx):
"""
Load label image as 1 x height x width integer array of label indices.
The leading singleton dimension is required by the loss.
"""
im = Image.open('{}/SegmentationClass/{}.png'.format(self.voc_dir, idx))
label = np.array(im, dtype=np.uint8)
label = label[np.newaxis, ...]
return label
裡面定義了兩個類,我們只看其中一個,該資料層繼承自caffe.Layer,因而必須重寫setup(),reshape(),forward(),backward()函式。
setup()是類啟動時該做的事情,比如層所需資料的初始化。
reshape()就是取資料然後把它規範化為四維的矩陣。每次取資料都會呼叫此函式,load_image()很容易理解,就是轉化為caffe的標準輸入資料,我們重點關注一下load_label()這個方法,我們會發現這裡的label不同於以往的分類標籤,而是一個二維的label,也就是SegmentationClass資料夾中的ground truth圖片(這裡很好奇這樣的圖片是怎麼生成的,我後來測試時發現並不能直接生成這樣的圖片,希望有知道的知友告知一下)
原來的圖片是這樣:
但是我們按照上面的方法把這張圖片load進來之後,label就是一個(1,500,334)的二維資料(嚴格來說是三維),每個位置的數值正是原圖在這個位置的類別,原圖是這樣的:

注:255是邊界資料,在訓練時會被忽略
forward()就是網路的前向執行,這裡就是把取到的資料往前傳遞,因為沒有其他運算。
backward()就是網路的反饋,data層是沒有反饋的,所以這裡就直接pass。
評論中有很多知友問到如何訓練自己的資料,其實分析到這裡就可以發現,大致可以以下三步:
1.為自己的資料製作label;
2.將自己的資料分為train,val和test集;
3.仿照voc_lyaers.py編寫自己的輸入資料層
但其實第一步還是挺困難的~~T_T
接下來我們分析一下論文中的關鍵結構:上取樣和跳躍結構
ok,我們還是先從簡單的結構開始,voc-fcns/train.prototxt
這裡推薦使用Netscope進行網路結構的視覺化
裡面有這幾個地方比較難以理解:
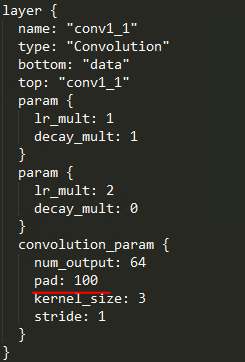
1.為什麼首層卷積層要pad 100畫素?
要解決這個問題,我們先來推算順著結構推算一下:(假設是一般的VGG16結構,第一個卷積層只pad 1)
我們假設輸入圖片的高度是h,根據我們的卷積公式
conv1_1:
conv1_2:
。。。。。。
我們發現,VGG中縮小輸出map只在池化層,所以下面我們忽略卷積層:
pool1:
pool2:
pool3:
。。。。。。
pool5:
很明顯,feature map的尺寸縮小了32倍,接下來是卷積化的fc6層,如下圖
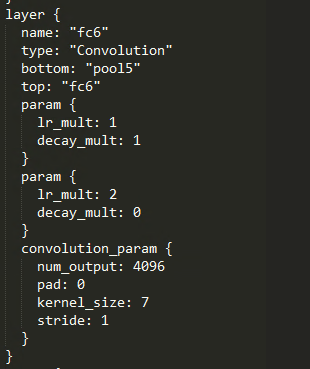
fc6: ,
接下來還有兩個卷積化的全連線層,fc7以及score_fr,但他們都是1*1的卷積核,對輸出的尺寸並不會有影響,所以最終在輸入反捲積之前的尺寸就是!
推導到這裡pad 100的作用已經很明顯了,如果不進行padding操作,對於長或寬不超過192畫素的圖片是沒法處理的,而當我們pad 100畫素之後,再進行以上推導,可以得到:
,這樣就解決了以上問題,但是毋庸置疑,這會引入很多噪聲。
2.反捲積層和Crop層如何產生和原圖尺寸相同的輸出?
卷積和反捲積在解讀部分已經做了詳細介紹,這裡不再贅述,只是再重複一下公式,在卷積運算時,
,
有這樣一組公式;而在上面我們提到,反捲積就是卷積計算的逆過程,所以在做反捲積時,
顯然輸出的高度和寬度應該這樣計算;下面我們繼續上面的推導,
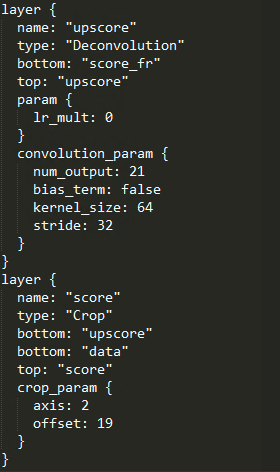
upscore:
反捲積之後,輸出尺寸與原影象不一致,接下來就是Crop層起作用的時候了
我們首先了解一下Caffe中的Crop層
注:以下解讀來自caffe-users中Mohamed Ezz的回答
---------------------------------------------------------------------------------------------------------------------------
為了理解Crop層,我們首先回答一個問題:Caffe是如何知道在哪裡開始裁剪?
很顯然Caffe並不知道,應該是程式設計師為它指定的,right,我們正是通過offset引數來指定。
下面我們舉一個例子:
Caffe中的Blob是4D資料:(N,C,H,W),Corp層有兩個bottom blob,也就是兩個輸入,第一個是要crop的blob,假設為blob A:(20,50,512,512),第二個是參考的blob,假設為blob B:(20, 10, 256, 256),還有一個top blob,亦即輸出,假設blob C:(20,10,256,256)。
很顯然crop的作用就是參考B裁剪A。
在這個例子中,我們只想裁剪後三個維度,而保持第一個維度不變,所以我們需要指定axis=1,表明我們只想裁剪從1開始的所有維度;
接下來我們需要指定offset引數,保證正確crop.有兩種指定方式:
1.為想要crop的每個維度指定特定值,比如在這裡我們可以指定offset=(25,128,128),這樣在實際crop過程中:C = A[: , 25: 25+B.shape[1] , 128: 128+B.shape[2] , 128: 128+B.shape[3] ],換句話說,就是我們只保留A第二維中25-35的部分而放棄了其他的,以及二維圖中的中間部分
2.只指定一個offset值,假設我們offest=25,這樣在上例中我們相當於指定了offset=(25,25,25),也就是為所有要crop的維度指定一個相同的值
---------------------------------------------------------------------------------------------------------------------------
好了,瞭解了這些之後我們再來看一下剛才的Crop層,現在很明白了,我們參考data層將upscore層裁剪成score層,引數axis=2,表明我們只想裁剪後兩個維度,亦即輸出尺寸,offset=19,對應於C = A[: , : , 19: 19+h , 19: 19+h ],這正是從(h+38,w+38)的upscore層中裁剪出中間的(h,h)的影象,這也就產生了和原圖尺寸相同的最終輸出!
可以看出,這中間的每一個設定都是獨具匠心的,讓人不得不生出敬意。
但是隻是用pool5層進行上取樣最後產生的結果是比較粗糙的,所以作者又將不同層級的池化層分別上取樣,然後疊加到一起,這樣產生了更好的結果。當然理解上述之後,大家可以自行分析FCN16s和FCN8s,這裡就不再贅述了!
三.總結
影象語義分割可能是自動駕駛技術下一步發展的一個重要突破點,而且本身也特別有意思!藉此機會也學習了一下Caffe計算卷積和轉置卷積的過程,對語義分割也有了一個初步的瞭解,收穫頗豐!