
面試專題(框架)
Spring
Spring有哪些特點?
使用Spring有什麼好處?
1 應用解耦
2 依賴注入
3 AOP
4 事務管理
5 MVC
6 整合開發
Spring應用程式看起來像什麼?
一些介面及其實現
一些POJO類
一些xml配置檔案
Spring核心容器模組是什麼?
Spring core/IOC/BeanFactory
核心容器(Spring Core)
核心容器提供Spring框架的基本功能。Spring以bean的方式組織和管理Java應用中的各個元件及其關係。Spring使用BeanFactory來產生和管理Bean,它是工廠模式的實現。BeanFactory使用控制反轉(IoC)模式將應用的配置和依賴性規範與實際的應用程式程式碼分開。
為了降低Java開發的複雜性, Spring採取了哪幾種策略
POJO/IOC/AOP/Template
基於POJO的輕量性和最小侵入性程式設計
通過依賴注入和麵向介面實現鬆耦合
基於切面和慣例進行宣告式程式設計
通過切面和模板減少樣板式程式碼
談談Spring框架幾個主要部分組成
Spring core/beans/context/aop/jdbc/tx/web mvc/orm
說一下Spring中支援的bean作用域
Singleton/prototype/request/session
singleton:單例模式,在整個Spring IoC容器中,使用singleton定義的Bean將只有一個例項。
prototype:原型模式,每次通過容器的getBean方法獲取prototype定義的Bean時,都將產生一個新的Bean例項。
request:對於每次HTTP請求,使用request定義的Bean都將產生一個新例項,即每次HTTP請求將會產生不同的Bean例項。只有在Web應用中使用Spring時該作用域才有效。
session:對於每次HTTP Session,使用session定義的Bean都將產生一個新例項。同樣只有在Web應用中使用Spring時該作用域才有效。
Spring框架中單例beans是執行緒安全的嗎?為什麼?
不是執行緒安全(預設singleton)
當多個執行緒併發執行該請求對應的業務邏輯(成員方法),如果該處理邏輯中有對單例狀態的修改(單例的成員屬性),則必須考慮執行緒同步問題。
解釋Spring框架中bean的生命週期
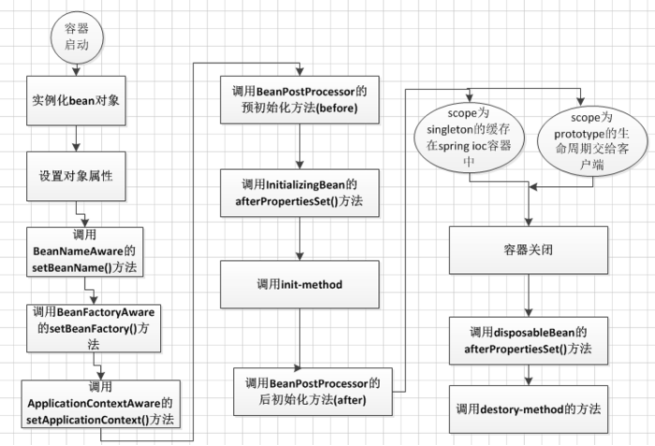
哪些是最重要的bean生命週期方法?能重寫它們嗎?
Setup/teardown
Xml中對應Init-method/destory-method
@PostConstruct @PreDestory
bean標籤有兩個重要的屬性(init-method 和 destroy-method),可以通過這兩個屬性定義自己的初始化方法和析構方法。Spring也有相應的註解:@PostConstruct 和 @PreDestroy。
Spring容器例項化Bean有多少種方法?分別是什麼?
使用類構造器
使用靜態工廠方法
Xml配置檔案factory-method
如何減少Spring XML的配置數量
使用Java配置檔案,使xml中的bean轉為Javaconfig檔案方式
註解的方式
什麼是bean自動裝配?並解釋自動裝配的各種模式?
Spring容器可以自動配置相互協作beans之間的關聯關係。這意味著Spring可以自動配置一個bean和其他協作bean之間的關係,通過檢查BeanFactory 的內容裡沒有使用和< property>元素。
一個類就是一個Bean,Spring框架是一個Bean容器,替我們管理這些Bean,Spring就是來組織各個角色之間的關係,然後對這些角色進行調動。
自動裝配:
- default(beans這個標籤的default-autowired屬性)
- 通過byName自動裝配
- 通過byType自動裝配
- 通過建構函式自動裝配
- no不使用自動裝配
自動裝配有哪些好處和壞處?
自動裝配的優點如下:
- 自動裝配能顯著減少裝配的數量,因此在配置數量相當多時採用自動裝配,可以減少工作量。
- 自動裝配可以使配置與Java程式碼同步更新。例如:如果需要給一個Java類增加一個依賴,那麼該依賴將自動實現而不需要修改配置。因此強烈在開發過程中採用自動裝配,而在系統趨於穩定的時候改為顯式裝配的方式。
雖然自動裝配具有上面這些優點,但不是說什麼時候都可以使用它,因為它還有如下一些缺點:
- 儘管自動裝配比顯式裝配更神奇,但是,Spring會盡量避免在裝配不明確時進行猜測,因為裝配不明確可能出現難以預料的結果,而Spring所管理的物件之間的關聯關係也不再能清晰地進行文件化。
- 對於那些根據Spring配置檔案生成文件的工具來說,自動裝配將會使這些工具無法生成依賴資訊。
是不是所有型別都能自動裝配?如果不是請舉例
不是。原生型別/字串型別不可以自動裝配
什麼是迴圈依賴?
迴圈依賴就是N個類中迴圈巢狀引用,如果在日常開發中我們用new 物件的方式發生這種迴圈依賴的話程式會在執行時一直迴圈呼叫,直至記憶體溢位報錯。
public class PersonA {
private PersonB personB;
public PersonA(PersonB personB) {
this.personB = personB;
}
}
public class PersonB {
private PersonC personC;
public PersonB(PersonC personC) {
this.personC = personC;
}
}
public class PersonC {
private PersonA personA;
public PersonC(PersonA personA) {
this.personA = personA;
}
}
Spring如何解決迴圈依賴?
DefaultSingletonBeanRegistry.getSingleton原始碼中有3個cache:
- singletonFactories : 單例物件工廠的cache
- earlySingletonObjects :提前暴光的單例物件的Cache
- singletonObjects:單例物件的cache
getSingleton()的整個過程,Spring首先從一級快取singletonObjects中獲取。如果獲取不到,並且物件正在建立中,就再從二級快取earlySingletonObjects中獲取。如果還是獲取不到且允許singletonFactories通過getObject()獲取,就從三級快取singletonFactory.getObject()(三級快取)獲取。
解析:
PersonA的setter依賴了PersonB的例項物件,同時PersonB的setter依賴了PersonA的例項物件”這種迴圈依賴的情況。
PersonA首先完成了初始化的第一步,並且將自己提前曝光到singletonFactories中,此時進行初始化的第二步,發現自己依賴物件PersonB,此時就嘗試去get(PersonB),發現PersonB還沒有被create,所以執行create流程,PersonB在初始化第一步的時候發現自己依賴了物件PersonA,於是嘗試get(PersonA),嘗試一級快取singletonObjects(肯定沒有,因為A還沒初始化完全),嘗試二級快取earlySingletonObjects(也沒有),嘗試三級快取singletonFactories,由於PersonA通過ObjectFactory將自己提前曝光了,所以PersonB能夠通過ObjectFactory.getObject拿到PersonA物件(雖然PersonA還沒有初始化完全),PersonB拿到PersonA物件後順利完成了初始化階段1、2、3,完全初始化之後將自己放入到一級快取singletonObjects中。此時返回PersonA中,PersonA此時能拿到PersonB的物件順利完成自己的初始化階段2、3,最終A也完成了初始化,進去了一級快取singletonObjects中。而且,由於PersonB拿到了PersonA的物件引用,所以PersonB現在中的PersonA物件完成了初始化。
SpringMVC的工作流程和原理是什麼?
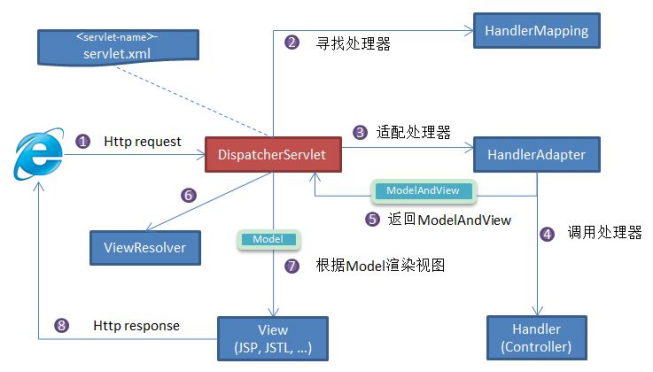
SpringMVC與Struts2的主要區別?
區別1:
Struts2 的核心是基於一個Filter即StrutsPreparedAndExcuteFilter
SpringMvc的核心是基於一個Servlet即DispatcherServlet(前端控制器)
區別2:
Struts2是基於類開發的,傳遞的引數是通過類的屬性傳遞(屬性驅動和模型驅動),所以只能設計成多例prototype
SpringMvc是基於類中的方法開發的,也就是一個url對應一個方法,傳遞引數是傳到方法的形參上面,所以既可以是單例模式也可以是多例模式singiton
區別3:
Struts2採用的是值棧儲存請求以及響應資料,OGNL存取資料
SpringMvc採用request來解析請求內容,然後由其內部的getParameter給方法中形參賦值,再把後臺處理過的資料通過ModelAndView物件儲存,Model儲存資料,View儲存返回的頁面,再把物件通過request傳輸到頁面去。
SpringMVC的控制器是不是單例模式,如果是有什麼問題,怎麼解決
是。單例如果有非靜態成員變數儲存狀態會有執行緒安全問題。
解決辦法1:不要有成員變數,都是方法。
解決辦法2:@Scope(“prototype”)
Spring註解的基本概念和原理
註解(Annotation),也叫元資料。一種程式碼級別的說明。
Spring註解分為:
1.類級別的註解:如@Component、@Repository、@Controller、@Service以及JavaEE6的@ManagedBean和@Named註解,都是新增在類上面的類級別註解。
Spring容器根據註解的過濾規則掃描讀取註解Bean定義類,並將其註冊到Spring IoC容器中。
2.類內部的註解:如@Autowire、@Value、@Resource以及EJB和WebService相關的註解等,都是新增在類內部的欄位或者方法上的類內部註解。
SpringIoC容器通過Bean後置註解處理器解析Bean內部的註解。
舉例說明什麼是Spring基於Java的配置?
Spring3.0之前都是基於XML配置的,Spring3.0開始可以幾乎不使用XML而使用純粹的java程式碼來配置Spring應用。
@Configuration
@EnableTransactionManagement
public class AppConfig implements TransactionManagementConfigurer {
@Bean
public DruidDataSource dataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/sqoop");
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUsername("root");
dataSource.setPassword("abcd_123");
return dataSource;
}
@Bean
public JdbcTemplate jdbcTemplate(DruidDataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
public PlatformTransactionManager txManager() {
return new DataSourceTransactionManager(dataSource());
}
@Override
public PlatformTransactionManager annotationDrivenTransactionManager() {
return txManager();
}
}
什麼是基於註解的容器配置?
XML解耦了配置和原始碼,而註解則精簡了配置。spring框架基於註解的容器配置:
@Qualifier
@Autowired
@Resource
@PostContuct
@PreDestory
@Autowired @Resource @Inject 的區別
@Resource
1、@Resource是JSR250規範的實現,需要匯入javax.annotation實現注入。
2、@Resource是根據名稱進行自動裝配的,一般會指定一個name屬性
3、@Resource可以作用在變數、setter方法上。
@Autowired
1、@Autowired是spring自帶的,@Inject是JSR330規範實現的,@Resource是JSR250規範實現的,需要匯入不同的包
2、@Autowired、@Inject用法基本一樣,不同的是@Autowired有一個request屬性
3、@Autowired、@Inject是預設按照型別匹配的,@Resource是按照名稱匹配的
4、@Autowired如果需要按照名稱匹配需要和@Qualifier一起使用,@Inject和@Name一起使用
什麼是AOP,有什麼作用,能應用在什麼場景?
面向切面程式設計。
AOP主要作用
將日誌記錄,效能統計,安全控制,事務處理,異常處理等程式碼從業務邏輯程式碼中劃分出來,通過對這些行為的分離,我們希望可以將它們獨立到非指導業務邏輯的方法中,進而改變這些行為的時候不影響業務邏輯的程式碼。
總之,面向切面的目標與面向物件的目標沒有不同。一是減少重複,二是專注業務。
AOP應用場景
日誌記錄,效能統計,安全控制,事務處理,異常處理等問題及擴充套件
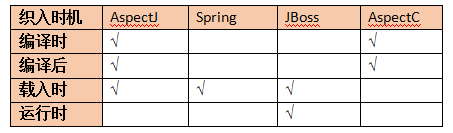
什麼是織入,織入的時機是什麼
把切面(aspect)連線到其它的應用程式型別或者物件上,並建立一個被通知(advised)的物件,這樣的行為叫做織入。
織入操作可以發生在如下幾個階段。
- 編譯時:在對原始碼進行編譯時,特殊的編譯器允許我們通過某種方式指定程式中的各個方面進行Weave的規則,並根據這些規則生成編譯完成的應用程式;
- 編譯後:根據Weave規則對已經完成編譯的程式模組進行Weave操作;
- 載入時:在載入程式模組的時候進行Weave操作;
- 執行時:在程式執行時,根據情況織入程式中的物件和方面。
編譯期織入是指在Java編譯期,將切面織入到Java類中;而類載入期織入則指通過特殊的類載入器,在類位元組碼載入到JVM時,織入切面;執行期織入則是採用CGLib工具或JDK動態代理進行切面的織入
什麼是切入點,關注點,連線點
連線點(JoinPoint) spring允許你是通知(Advice)的地方,基本每個方法的前、後、環繞或丟擲異常時都可以是連線點,spring只支援方法連線點。其他如AspectJ還可以讓你在構造器或屬性注入時都行。
切入點(Pointcut) 一個類裡,有N個方法就有N個連線點,但是你並不想在所有方法上都使用通知,只想讓其中幾個方法執行前、後或者丟擲異常完成其他功能(如日誌,效能分析),那麼就用切入點來篩選到那幾個你想要的方法。
public class BusinessLogic {
public void doSomething() {
// 驗證安全性;Securtity關注點
// 執行前記錄日誌;Logging關注點
doit();
// 儲存邏輯運算後的資料;Persistence關注點
// 執行結束記錄日誌;Logging關注點
}
} Business Logic屬於核心關注點,它會呼叫到Security,Logging,Persistence等橫切關注點。
Spring提供了幾種AOP支援?
方式一:經典的基於代理的AOP
方式二:@AspectJ註解的切面
方式三:純POJO切面
AOP常用的實現方式有兩種,一種是採用宣告的方式來實現(基於XML),一種是採用註解的方式來實現(基於AspectJ)。
舉例說明什麼是事物以及其特點
事務是為了保證對同一資料表操作的一致性。
- A是原子性(atomic):事務中包含的各項操作必須全部成功執行或者全部不執行。任何一項操作失敗,將導致整個事務失敗,其他已經執行的任務所作的資料操作都將被撤銷,只有所有的操作全部成功,整個事務才算是成功完成。
- C是一致性(consistent):保證了當事務結束後,系統狀態是一致的。那麼什麼是一致的系統狀態?例如,如果銀行始終遵循著"銀行賬號必須保持正態平衡"的原則,那麼銀行系統的狀態就是一致的。上面的轉賬例子中,在取錢的過程中,賬戶會出現負態平衡,在事務結束之後,系統又回到一致的狀態。這樣,系統的狀態對於客戶來說,始終是一致的。
- I是隔離性(isolated):使得併發執行的事務,彼此無法看到對方的中間狀態。保證了併發執行的事務順序執行,而不會導致系統狀態不一致。
- D是永續性(durable):保證了事務完成後所作的改動都會被持久化,即使是發生災難性的失敗。可恢復性資源儲存了一份事務日誌,如果資源發生故障,可以通過日誌來將資料重建起來
Java EE事務型別有哪些?應用場景是什麼?Spring是如何實現的?
一般J2EE伺服器支援三種類型的事務管理。即:JDBC事務,JTA事務,容器管理事務。
JDBC事物介面:PlatformTransactionManager、AbstractPlatformTransactionManager、DataSourceTransactionManager
JTA具有三個主要的介面:UserTransaction、JTATransactionManager、Transaction介面
容器級事務主要是由容器提供的事務管理,如:WebLogic/Websphere
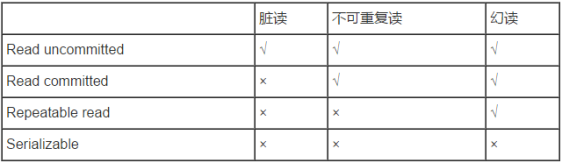
Spring有幾個事物隔離級別,分別詳述
事務隔離級別(5種)
DEFAULT 這是一個PlatfromTransactionManager預設的隔離級別,使用資料庫預設的事務隔離級別。
未提交讀(read uncommited) :髒讀,不可重複讀,虛讀都有可能發生。
已提交讀 (read commited):避免髒讀。但是不可重複讀和虛讀有可能發生。
可重複讀 (repeatable read) :避免髒讀和不可重複讀.但是虛讀有可能發生。
序列化的 (serializable) :避免以上所有讀問題。
Mysql 預設:可重複讀
Oracle 預設:讀已提交
read uncommited:是最低的事務隔離級別,它允許另外一個事務可以看到這個事務未提交的資料。
read commited:保證一個事物提交後才能被另外一個事務讀取。另外一個事務不能讀取該事物未提交的資料。
repeatable read:這種事務隔離級別可以防止髒讀,不可重複讀。但是可能會出現幻象讀。它除了保證一個事務不能被另外一個事務讀取未提交的資料之外還避免了以下情況產生(不可重複讀)。
serializable:這是花費最高代價但最可靠的事務隔離級別。事務被處理為順序執行。除了防止髒讀,不可重複讀之外,還避免了幻象讀(避免三種)。
描述下SpringJDBC的架構
Spring JDBC提供了一套JDBC抽象框架,用於簡化JDBC開發。
Spring主要提供JDBC模板方式、關係資料庫物件化方式、SimpleJdbc方式、事務管理來簡化JDBC程式設計。
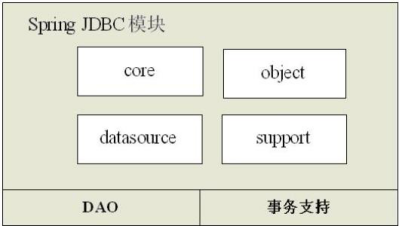
support包:提供將JDBC異常轉換為DAO非檢查異常轉換類、一些工具類如JdbcUtils等。
datasource包:提供簡化訪問JDBC 資料來源(javax.sql.DataSource實現)工具類,並提供了一些DataSource簡單實現類從而能使從這些DataSource獲取的連線能自動得到Spring管理事務支援。
core包:提供JDBC模板類實現及可變部分的回撥介面,還提供SimpleJdbcInsert等簡單輔助類。
object包:提供關係資料庫的物件表示形式,如MappingSqlQuery、SqlUpdate、SqlCall
描述下Spring事務處理類及其作用
Spring框架支援事務管理的核心是事務管理器抽象,對於不同的資料訪問框架(如Hibernate)通過實現策略介面PlatformTransactionManager。該介面由3個方法組成:
getTransaction():返回一個已經啟用的事務或建立一個新的事務(根據給定的TransactionDefinition型別引數定義的事務屬性),返回的是TransactionStatus物件代表了當前事務的狀態,該方法丟擲TransactionException(未檢查異常)表示事務由於某種原因失敗。
commit():用於提交TransactionStatus引數代表的事務
rollback():用於回滾TransactionStatus引數代表的事務
程式設計式事務
1、直接使用PlatformTransactionManager實現
2、使用TransactionTemplate模板類,用於支援邏輯事務管理。
宣告式事務
1、AOP代理方式實現
2、@Transactional實現事務管理
<tx:annotation-driven transaction-manager="transactionManager"
Spring提供幾種事物實現?分別是什麼?各有什麼優缺點?
一種程式設計式和三種宣告式
一種程式設計式(基於底層 API txManager.getTransaction方式或基於TransactionTemplate)
三種宣告式:AOP(TransactionProxyFactoryBean),基於AspectJ的宣告式事務<tx:advice>,基於註解方式的宣告式事務(@Transactional)程式設計式事務侵入性比較強,但處理粒度更細。
JdbcTemplate有哪些主要方法
CRUD操作全部包含在JdbcTemplate
ResultSetExtractor/RowMapper/RowCallbackHandler
JdbcTemplate支援哪些回撥類
1、RowMapper是一個精簡版的ResultSetExtractor,RowMapper能夠直接處理一條結果集內容,而ResultSetExtractor需要我們自己去ResultSet中去取結果集的內容,但是ResultSetExtractor擁有更多的控制權,在使用上可以更靈活;
2、與RowCallbackHandler相比,ResultSetExtractor是無狀態的,他不能夠用來處理有狀態的資源。
MyBatis
什麼是MyBatis?簡述MyBatis的體系結構
Mybatis的功能架構分為三層:
- API介面層:提供給外部使用的介面API,開發人員通過這些本地API來操縱資料庫。介面層一接收到呼叫請求就會呼叫資料處理層來完成具體的資料處理。
- 資料處理層:負責具體的SQL查詢、SQL解析、SQL執行和執行結果對映處理等。它主要的目的是根據呼叫的請求完成一次資料庫操作。
- 基礎支撐層:負責最基礎的功能支撐,包括連線管理、事務管理、配置載入和快取處理,這些都是共用的東西,將他們抽取出來作為最基礎的元件。為上層的資料處理層提供最基礎的支撐。
列舉MyBatis的常用API及方法
org.apache.ibatis.session.SqlSession
MyBatis工作的主要頂層API,表示和資料庫互動的會話。完畢必要資料庫增刪改查功能。
org.apache.ibatis.executor.Executor
MyBatis執行器,是MyBatis 排程的核心,負責SQL語句的生成和查詢快取的維護。
org.apache.ibatis.executor.statement.StatementHandler
封裝了JDBC Statement操作。負責對JDBC statement 的操作。如設定引數、將Statement結果集轉換成List集合。
org.apache.ibatis.executor.parameter.ParameterHandler
負責對使用者傳遞的引數轉換成JDBC Statement 所須要的引數。
org.apache.ibatis.executor.resultset.ResultSetHandler
負責將JDBC返回的ResultSet結果集物件轉換成List型別的集合
org.apache.ibatis.type.TypeHandler
負責java資料型別和jdbc資料型別之間的對映和轉換
org.apache.ibatis.mapping.MappedStatement
MappedStatement維護了一條<select|update|delete|insert>節點的封裝
org.apache.ibatis.mapping.SqlSource
負責依據使用者傳遞的parameterObject,動態地生成SQL語句,將資訊封裝到BoundSql物件中,並返回
org.apache.ibatis.mapping.BoundSql
表示動態生成的SQL語句以及對應的引數資訊
org.apache.ibatis.session.Configuration
MyBatis全部的配置資訊都維持在Configuration物件之中
對於Hibernate和MyBatis的區別與利弊,談談你的看法
1、hibernate真正掌握要比mybatis難,因為hibernate的功能和特性非常多,還不適合多表關聯查詢。
2、hibernate查詢會將所有關聯表的欄位全部查詢出來,會導致效能消耗,當然hibernate也可以自己寫sql指定欄位,但這就破壞了hibernate的簡潔性。mybatis的sql是自己手動編寫的,所以可以指定查詢欄位。
3、hibernate與資料庫管聯只需在xml檔案中配置即可,所有的HQL語句都與具體使用的資料庫無關,移植性很好;mybatis所有的sql都是依賴所用資料庫的,所以移植性差。
4、hibernate是在jdbc上進行一次封裝,mybatis是基於原生的jdbc,執行速度較快。
5、如果有上千萬的表或者單次查詢或提交百萬資料以上不建議使用hibernate。如果統計功能、多表關聯查詢較多較複雜建議使用mybatis。
#{}和${}的區別是什麼?
select * from location where id = ${id} => Select * from location where id = xxx;
Select * from location where id = #{} => Select * from location where id="xxxx";
${}方式無法防止sql注入;
Order by動態引數時,使用${}而不用#{}
模糊查詢的時候使用${}
select * from location where name like '${}%';
Mybatis是如何進行分頁的?分頁外掛的原理是什麼?
RowBounds針對ResultSet結果集執行分頁
<select id="selectById" parameterType="int" resultType="com.dongnao.demo.dao.Location">
select * from location where id = #{id}
</select>外掛分頁
@Intercepts
分頁外掛的基本原理是使用Mybatis提供的外掛介面,實現自定義外掛,在外掛的攔截方法內攔截待執行的sql,然後重寫sql,根據dialect方言,新增對應的物理分頁語句和物理分頁引數。
簡述Mybatis的外掛執行原理,以及如何編寫一個外掛
Mybatis僅可以編寫針對ParameterHandler、ResultSetHandler、StatementHandler、Executor這4種介面的外掛。
Mybatis使用JDK的動態代理,為需要攔截的介面生成代理物件以實現介面方法攔截功能,每當執行這4種介面物件的方法時,就會進入攔截方法,具體就是InvocationHandler的invoke()方法。當然,只會攔截那些你指定需要攔截的方法。
實現Mybatis的Interceptor介面並複寫intercept()方法,然後在給外掛編寫註解,指定要攔截哪一個介面的哪些方法即可。記住,別忘了在配置檔案中配置你編寫的外掛。
Mybatis動態sql是做什麼的?都有哪些動態sql?簡述一下動態sql的執行原理
Mybatis動態sql可以讓我們在Xml對映檔案內,以標籤的形式編寫動態sql,完成邏輯判斷和動態拼接sql的功能。
Mybatis提供了9種動態sql標籤trim|where|set|foreach|if|choose|when|otherwise|bind
原理為,使用OGNL從sql引數物件中計算表示式的值,根據表示式的值動態拼接sql,以此來完成動態sql的功能。
動態SQL,主要用於解決查詢條件不確定的情況:在程式執行期間,根據提交的查詢條件進行查詢。
動態SQL,即通過MyBatis提供的各種標籤對條件作出判斷以實現動態拼接SQL語句。
Mybatis是否支援延遲載入?如果支援,它的實現原理是什麼?
Mybatis僅支援association關聯物件和collection關聯集合物件的延遲載入,association指的就是一對一,collection指的就是一對多查詢。在Mybatis配置檔案中,可以配置是否啟用延遲載入lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB建立目標物件的代理物件。當呼叫目標方法時,進入攔截器方法,如:呼叫a.getB().getName(),攔截器invoke()方法發現a.getB()是null值,那麼就會單獨傳送事先儲存好的查詢關聯B物件的sql,把B查詢上來,然後呼叫a.setB(b),於是a的物件b屬性就有值了,接著完成a.getB().getName()方法的呼叫。這就是延遲載入的基本原理。
Mybatis的Xml對映檔案中,不同的Xml對映檔案,id是否可以重複?
可以。Mybatis namespace+id
Mybatis都有哪些Executor執行器?它們之間的區別是什麼?
SimpleExecutor執行一次sql,開始建立一個statement,用完關閉statement
ReuseExector 類似資料庫連線池,statement用完後返回,statement可以複用
BatchExecutor主要用於批處理執行
Mybatis是否可以對映Enum列舉類?
可以。Mybatis可以對映列舉類,不單可以對映列舉類,Mybatis可以對映任何物件到表的一列上。
Mybatis能否執行一對一、一對多關聯查詢?都有哪些實現方式,它們之間有什麼區別
能,Mybatis不僅可以執行一對一、一對多的關聯查詢,還可以執行多對一,多對多的關聯查詢。
什麼是MyBatis的介面繫結,有什麼好處
介面對映就是在IBatis中任意定義介面,然後把接口裡邊的方法和SQL語句繫結,我們可以直接呼叫介面方法,比起SqlSession提供的方法我們可以有更加靈活的選擇和設定。
iBatis和MyBatis在細節上的不同有哪些
區別太多,篇幅太長,大家可以自行百度下。
講下MyBatis的快取
MyBatis 提供了查詢快取來快取資料,以提高查詢的效能。MyBatis 的快取分為一級快取和二級快取。
一級快取是 SqlSession 級別的快取
二級快取是 mapper 級別的快取,多個 SqlSession 共享
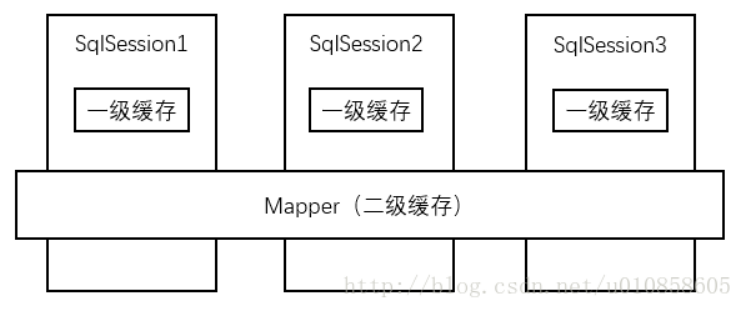
一級快取
一級快取是SqlSession級別的快取,是基於HashMap的本地快取。不同的 SqlSession之間的快取資料區域互不影響。
一級快取的作用域是SqlSession範圍,當同一個SqlSession執行兩次相同的 sql語句時,第一次執行完後會將資料庫中查詢的資料寫到快取,第二次查詢時直接從快取獲取不用去資料庫查詢。當SqlSession執行insert、update、delete 操做並提交到資料庫時,會清空快取,保證快取中的資訊是最新的。
MyBatis預設開啟一級快取。
二級快取
二級快取是mapper級別的快取,同樣是基於HashMap進行儲存,多個SqlSession可以共用二級快取,其作用域是mapper的同一個namespace。不同的SqlSession兩次執行相同的namespace下的sql語句,會執行相同的sql,第二次查詢只會查詢第一次查詢時讀取資料庫後寫到快取的資料,不會再去資料庫查詢。
MyBatis 預設沒有開啟二級快取,開啟只需在配置檔案中寫入如下程式碼:
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>