
RabbitMQ面試專題
如果對您有幫助 ,請多多支援.多少都是您的心意與支援,一分也是愛,再次感謝!!!
支付寶讚賞: 記得點選下面的餘額寶,紅包可能要大些。注意:餘額寶紅包有效期三天(72小時) 在有效期內
記得點選下面的餘額寶,紅包可能要大些。注意:餘額寶紅包有效期三天(72小時) 在有效期內
餘額寶紅包使用完或過期才能有機會領取下個餘額寶紅包,感謝大家的支援!您的支援,我會繼續分享更多的文章,歡迎關注!
【基礎類】
問題一:RabbitMQ 中的 broker 是指什麼?cluster 又是指什麼?
答:broker 是指一個或多個 erlang node 的邏輯分組,且 node 上執行著 RabbitMQ 應用程式。cluster 是在 broker 的基礎之上,增加了 node 之間共享元資料的約束。
問題二:什麼是元資料?元資料分為哪些型別?包括哪些內容?與 cluster 相關的元資料有哪些?元資料是如何儲存的?元資料在 cluster 中是如何分佈的?
答:在非 cluster 模式下,元資料主要分為 Queue 元資料(queue 名字和屬性等)、Exchange 元資料(exchange 名字、型別和屬性等)、Binding 元資料(存放路由關係的查詢表)、Vhost 元資料(vhost 範圍內針對前三者的名字空間約束和安全屬性設定)。在 cluster 模式下,還包括 cluster 中 node 位置資訊和 node 關係資訊。元資料按照 erlang node 的型別確定是僅保存於 RAM 中,還是同時儲存在 RAM 和 disk 上。元資料在 cluster 中是全 node 分佈的。
下圖所示為 queue 的元資料在單 node 和 cluster 兩種模式下的分佈圖。

問題三:RAM node 和 disk node 的區別?
答:RAM node 僅將 fabric(即 queue、exchange 和 binding等 RabbitMQ基礎構件)相關元資料儲存到記憶體中,但 disk node 會在記憶體和磁碟中均進行儲存。RAM node 上唯一會儲存到磁碟上的元資料是 cluster 中使用的 disk node 的地址。要求在 RabbitMQ cluster 中至少存在一個 disk node 。
問題四:RabbitMQ 上的一個 queue 中存放的 message 是否有數量限制?
答:可以認為是無限制,因為限制取決於機器的記憶體,但是訊息過多會導致處理效率的下降。
問題五:RabbitMQ 概念裡的 channel、exchange 和 queue 這些東東是邏輯概念,還是對應著程序實體?這些東東分別起什麼作用?
答:queue 具有自己的 erlang 程序;exchange 內部實現為儲存 binding 關係的查詢表;channel 是實際進行路由工作的實體,即負責按照 routing_key 將 message 投遞給 queue 。由 AMQP 協議描述可知,channel 是真實 TCP 連線之上的虛擬連線,所有 AMQP 命令都是通過 channel 傳送的,且每一個 channel 有唯一的 ID。一個 channel 只能被單獨一個作業系統執行緒使用,故投遞到特定 channel 上的 message 是有順序的。但一個作業系統執行緒上允許使用多個 channel 。channel 號為 0 的 channel 用於處理所有對於當前 connection 全域性有效的幀,而 1-65535 號 channel 用於處理和特定 channel 相關的幀。AMQP 協議給出的 channel 複用模型如下

其中每一個 channel 執行在一個獨立的執行緒上,多執行緒共享同一個 socket。
問題六:vhost 是什麼?起什麼作用?
答:vhost 可以理解為虛擬 broker ,即 mini-RabbitMQ server。其內部均含有獨立的 queue、exchange 和 binding 等,但最最重要的是,其擁有獨立的許可權系統,可以做到 vhost 範圍的使用者控制。當然,從 RabbitMQ 的全域性角度,vhost 可以作為不同許可權隔離的手段(一個典型的例子就是不同的應用可以跑在不同的 vhost 中)。
【cluster 相關】
問題七:在單 node 系統和多 node 構成的 cluster 系統中宣告 queue、exchange ,以及進行 binding 會有什麼不同?
答:當你在單 node 上宣告 queue 時,只要該 node 上相關元資料進行了變更,你就會得到 Queue.Declare-ok 迴應;而在 cluster 上宣告 queue ,則要求 cluster 上的全部 node 都要進行元資料成功更新,才會得到 Queue.Declare-ok 迴應。另外,若 node 型別為 RAM node 則變更的資料僅儲存在記憶體中,若型別為 disk node 則還要變更儲存在磁碟上的資料。
問題八:客戶端連線到 cluster 中的任意 node 上是否都能正常工作?
答:是的。客戶端感覺不到有何不同。
問題九:若 cluster 中擁有某個 queue 的 owner node 失效了,且該 queue 被宣告具有 durable 屬性,是否能夠成功從其他 node 上重新宣告該 queue ?
答:不能,在這種情況下,將得到 404 NOT_FOUND 錯誤。只能等 queue 所屬的 node 恢復後才能使用該 queue 。但若該 queue 本身不具有 durable 屬性,則可在其他 node 上重新宣告。
問題十:cluster 中 node 的失效會對 consumer 產生什麼影響?若是在 cluster 中建立了 mirrored queue ,這時 node 失效會對 consumer 產生什麼影響?
答:若是 consumer 所連線的那個 node 失效(無論該 node 是否為 consumer 所訂閱 queue 的 owner node),則 consumer 會在發現 TCP 連線斷開時,按標準行為執行重連邏輯,並根據“Assume Nothing”原則重建相應的 fabric 即可。若是失效的 node 為 consumer 訂閱 queue 的owner node,則 consumer 只能通過 Consumer Cancellation Notification 機制來檢測與該 queue 訂閱關係的終止,否則會出現傻等卻沒有任何訊息來到的問題。
問題十一:能夠在地理上分開的不同資料中心使用 RabbitMQ cluster 麼?
答:不能。第一,你無法控制所建立的 queue 實際分佈在 cluster 裡的哪個 node 上(一般使用 HAProxy + cluster 模型時都是這樣),這可能會導致各種跨地域訪問時的常見問題;第二,Erlang 的 OTP 通訊框架對延遲的容忍度有限,這可能會觸發各種超時,導致業務疲於處理;第三,在廣域網上的連線失效問題將導致經典的“腦裂”問題,而 RabbitMQ 目前無法處理(該問題主要是說 Mnesia)。
【綜合問題】
問題十二:為什麼 heavy RPC 的使用場景下不建議採用 disk node ?
答:heavy RPC 是指在業務邏輯中高頻呼叫 RabbitMQ 提供的 RPC 機制,導致不斷建立、銷燬 reply queue ,進而造成 disk node 的效能問題(因為會針對元資料不斷寫盤)。所以在使用 RPC 機制時需要考慮自身的業務場景。
問題十三:向不存在的 exchange 發 publish 訊息會發生什麼?向不存在的 queue 執行 consume 動作會發生什麼?
答:都會收到 Channel.Close 信令告之不存在(內含原因 404 NOT_FOUND)。
問題十四:routing_key 和 binding_key 的最大長度是多少?
答:255 位元組。
問題十五:RabbitMQ 允許傳送的 message 最大可達多大?
答:根據 AMQP 協議規定,訊息體的大小由 64-bit 的值來指定,所以你就可以知道到底能發多大的資料了。
問題十六:什麼情況下 producer 不主動建立 queue 是安全的?
答:1.message 是允許丟失的;2.實現了針對未處理訊息的 republish 功能(例如採用 Publisher Confirm 機制)。
問題十七:“dead letter”queue 的用途?
答:當訊息被 RabbitMQ server 投遞到 consumer 後,但 consumer 卻通過 Basic.Reject 進行了拒絕時(同時設定 requeue=false),那麼該訊息會被放入“dead letter”queue 中。該 queue 可用於排查 message 被 reject 或 undeliver 的原因。
問題十八:為什麼說保證 message 被可靠持久化的條件是 queue 和 exchange 具有 durable 屬性,同時 message 具有 persistent 屬性才行?
答:binding 關係可以表示為 exchange – binding – queue 。從文件中我們知道,若要求投遞的 message 能夠不丟失,要求 message 本身設定 persistent 屬性,要求 exchange 和 queue 都設定 durable 屬性。其實這問題可以這麼想,若 exchange 或 queue 未設定 durable 屬性,則在其 crash 之後就會無法恢復,那麼即使 message 設定了 persistent 屬性,仍然存在 message 雖然能恢復但卻無處容身的問題;同理,若 message 本身未設定 persistent 屬性,則 message 的持久化更無從談起。
問題十九:什麼情況下會出現 blackholed 問題?
答:blackholed 問題是指,向 exchange 投遞了 message ,而由於各種原因導致該 message 丟失,但傳送者卻不知道。可導致 blackholed 的情況:1.向未繫結 queue 的 exchange 傳送 message;2.exchange 以 binding_key key_A綁定了 queue queue_A,但向該 exchange 傳送 message 使用的 routing_key 卻是 key_B。
問題二十:如何防止出現 blackholed 問題?
答:沒有特別好的辦法,只能在具體實踐中通過各種方式保證相關 fabric 的存在。另外,如果在執行 Basic.Publish 時設定 mandatory=true ,則在遇到可能出現 blackholed 情況時,伺服器會通過返回 Basic.Return 告之當前 message 無法被正確投遞(內含原因 312 NO_ROUTE)。
問題二十一:Consumer Cancellation Notification 機制用於什麼場景?
答:用於保證當映象 queue 中 master 掛掉時,連線到 slave 上的 consumer 可以收到自身 consume 被取消的通知,進而可以重新執行 consume 動作從新選出的 master 出獲得訊息。若不採用該機制,連線到 slave 上的 consumer 將不會感知 master 掛掉這個事情,導致後續無法再收到新 master 廣播出來的 message 。另外,因為在映象 queue 模式下,存在將 message 進行 requeue 的可能,所以實現 consumer 的邏輯時需要能夠正確處理出現重複 message 的情況。
問題二十二:Basic.Reject 的用法是什麼?
答:該信令可用於 consumer 對收到的 message 進行 reject 。若在該信令中設定 requeue=true,則當 RabbitMQ server 收到該拒絕信令後,會將該 message 重新發送到下一個處於 consume 狀態的 consumer 處(理論上仍可能將該訊息傳送給當前 consumer)。若設定 requeue=false ,則 RabbitMQ server 在收到拒絕信令後,將直接將該 message 從 queue 中移除。
另外一種移除 queue 中 message 的小技巧是,consumer 回覆 Basic.Ack 但不對獲取到的 message 做任何處理。
而 Basic.Nack 是對 Basic.Reject 的擴充套件,以支援一次拒絕多條 message 的能力。
問題二十三:為什麼不應該對所有的 message 都使用持久化機制?
答:首先,必然導致效能的下降,因為寫磁碟比寫 RAM 慢的多,message 的吞吐量可能有 10 倍的差距。其次,message 的持久化機制用在 RabbitMQ 的內建 cluster 方案時會出現“坑爹”問題。矛盾點在於,若 message 設定了 persistent 屬性,但 queue 未設定 durable 屬性,那麼當該 queue 的 owner node 出現異常後,在未重建該 queue 前,發往該 queue 的 message 將被 blackholed ;若 message 設定了 persistent 屬性,同時 queue 也設定了 durable 屬性,那麼當 queue 的 owner node 異常且無法重啟的情況下,則該 queue 無法在其他 node 上重建,只能等待其 owner node 重啟後,才能恢復該 queue 的使用,而在這段時間內傳送給該 queue 的 message 將被 blackholed 。所以,是否要對 message 進行持久化,需要綜合考慮效能需要,以及可能遇到的問題。若想達到 100,000 條/秒以上的訊息吞吐量(單 RabbitMQ 伺服器),則要麼使用其他的方式來確保 message 的可靠 delivery ,要麼使用非常快速的儲存系統以支援全持久化(例如使用 SSD)。另外一種處理原則是:僅對關鍵訊息作持久化處理(根據業務重要程度),且應該保證關鍵訊息的量不會導致效能瓶頸。
問題二十四:RabbitMQ 中的 cluster、mirrored queue,以及 warrens 機制分別用於解決什麼問題?存在哪些問題?
答:cluster 是為了解決當 cluster 中的任意 node 失效後,producer 和 consumer 均可以通過其他 node 繼續工作,即提高了可用性;另外可以通過增加 node 數量增加 cluster 的訊息吞吐量的目的。cluster 本身不負責 message 的可靠性問題(該問題由 producer 通過各種機制自行解決);cluster 無法解決跨資料中心的問題(即腦裂問題)。另外,在cluster 前使用 HAProxy 可以解決 node 的選擇問題,即業務無需知道 cluster 中多個 node 的 ip 地址。可以利用 HAProxy 進行失效 node 的探測,可以作負載均衡。下圖為 HAProxy + cluster 的模型。

Mirrored queue 是為了解決使用 cluster 時所建立的 queue 的完整資訊僅存在於單一 node 上的問題,從另一個角度增加可用性。若想正確使用該功能,需要保證:1.consumer 需要支援 Consumer Cancellation Notification 機制;2.consumer 必須能夠正確處理重複 message 。
Warrens 是為了解決 cluster 中 message 可能被 blackholed 的問題,即不能接受 producer 不停 republish message 但 RabbitMQ server 無迴應的情況。Warrens 有兩種構成方式,一種模型是兩臺獨立的 RabbitMQ server + HAProxy ,其中兩個 server 的狀態分別為 active 和 hot-standby 。該模型的特點為:兩臺 server 之間無任何資料共享和協議互動,兩臺 server 可以基於不同的 RabbitMQ 版本。如下圖所示

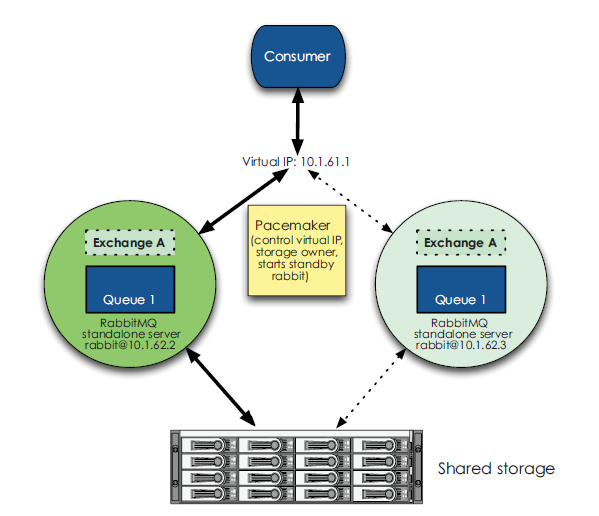
另一種模型為兩臺共享儲存的 RabbitMQ server + keepalived ,其中兩個 server 的狀態分別為 active 和 cold-standby 。該模型的特點為:兩臺 server 基於共享儲存可以做到完全恢復,要求必須基於完全相同的 RabbitMQ 版本。如下圖所示
Warrens 模型存在的問題:對於第一種模型,雖然理論上講不會丟失訊息,但若在該模型上使用持久化機制,就會出現這樣一種情況,即若作為 active 的 server 異常後,持久化在該 server 上的訊息將暫時無法被 consume ,因為此時該 queue 將無法在作為 hot-standby 的 server 上被重建,所以,只能等到異常的 active server 恢復後,才能從其上的 queue 中獲取相應的 message 進行處理。而對於業務來說,需要具有:a.感知 AMQP 連線斷開後重建各種 fabric 的能力;b.感知 active server 恢復的能力;c.切換回 active server 的時機控制,以及切回後,針對 message 先後順序產生的變化進行處理的能力。對於第二種模型,因為是基於共享儲存的模式,所以導致 active server 異常的條件,可能同樣會導致 cold-standby server 異常;另外,在該模型下,要求 active 和 cold-standby 的 server 必須具有相同的 node 名和 UID ,否則將產生訪問許可權問題;最後,由於該模型是冷備方案,故無法保證 cold-standby server 能在你要求的時限內成功啟動。
如果對您有幫助 ,請多多支援.多少都是您的心意與支援,一分也是愛,再次感謝!!!
支付寶讚賞: