
Spring原始碼系列 — BeanDefinition
一.前言
回顧
在Spring原始碼系列第二篇中介紹了Environment元件,後續又介紹Spring中Resource的抽象,但是對於上下文的啟動過程詳解並未繼續。經過一個星期的準備,梳理了Spring中的BeanDefinition以及它的解析和註冊過程。本文著重介紹其特點及用途並延續前面上下文啟動過程的步驟繼續分析原始碼。
目錄
本文主要從以下幾個方面介紹BeanDefinition
什麼是BeanDefinition
BeanDefinition解析註冊過程及元件概覽
從路徑到資源載入
資源解析形成BeanDefinition
BeanDefinition註冊
二.什麼是BeanDefinition
個人對Spring喜愛不止是其設計上鬼斧神工,也不僅是其生態的完整性,還有一部分原因是其原始碼的命名。筆者日常開發時偶爾感覺很無奈,由於每個人都有自己的風格,工作中的專案程式碼命名可謂五花八門,著實讓人看著糟心。
或許因為英語水平的限制,無法表達出像Spring那樣生動的描述,從命名上就能給人醍醐灌頂般的感覺!
BeanDefinition,顧名思義即Spring中Bean的定義。XML語言配置描述的Bean配置,對於Java面嚮物件語言而言,需要將其配置轉化為JAVA語言能夠描述的內容,即面向物件。在Spring中抽象出BeanDefinition型別的物件用於描述XML中配置的Bean。BeanDefinition是Bean的元資料資訊,其中囊括了一個Bean物件的所有資訊:
- Bean的型別
- Bean的屬性值
- Bean的構造引數值
- Bean的屬性訪問
- 等等...
在Javadocs中是這樣描述BeanDefinition物件:
A BeanDefinition describes a bean instance, which has property values, constructor argument values, and further information supplied by concrete implementations.
對Spring中BeanDefinition的抽象形成如下UML圖:
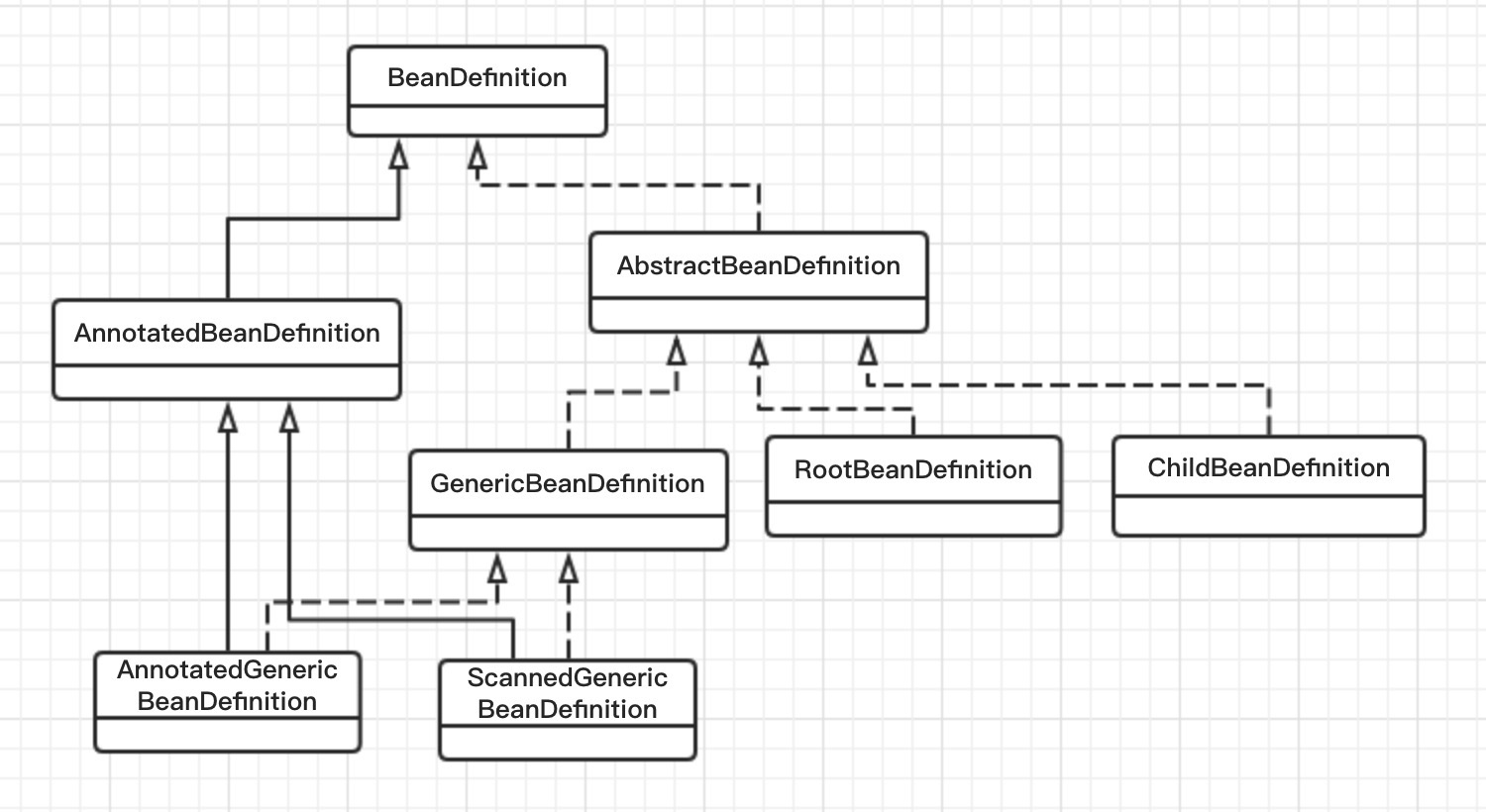
BeaDefinition是最上層的介面,定義了Bean定義配置的基本屬性行為:
- 定義作用域常量
- 定義Bean的角色常量
- 設定獲取Bean的父Bean的名稱
- 設定獲取Bean的Class型別
- 設定獲取Bean的作用域
- 設定獲取Bean是否懶惰初始化
- 設定獲取Bean的依賴
- 設定獲取Bean是否為自動裝配候選者
- 設定獲取Bean的工廠方法名稱
- 設定獲取Bean的構造引數和屬性值
- 等等....
AbstractBeanDefinition是BeaDefinition的基本實現,實現BeaDefinition的大多數行為。
RootBeanDefinition是合併的BeanDefinition,BeaDefinition之間存在依賴關係,有屬性繼承。Spring Bean工廠會將存在依賴關係的BeanDefinition合併成RootBeanDefinition。主要用於描述因依賴形成的合併Bean。
ChildBeanDefinition表示有繼承父Bean的Bean定義,ChildBeanDefinition代表了繼承關係中的子Bean定義。
GenericBeanDefinition是一站式的標準BeaDefinition,既可以靈活設定BeanDefinition屬性,又可以動態設定父Bean。
雖然以上的RootBeanDefinition/ChildBeanDefinition都可以在配置解析階段用於當做單個BeaDefinition註冊,但是在Spring 2.5中加入GenericBeanDefinition,更偏愛使用GenericBeanDefinition用作註冊。原始碼實現中也的確如此,解析階段
BeanDefition能夠描述如XML描述的Bean配置,Spring在啟動過程中的一個非常重要環節就是將XML描述的Bean配置轉為BeanDefinition的描述。接下來就循序漸進看這一過程的實現。
三.BeanDefinition解析註冊過程及元件概覽
1.解析註冊過程概覽
BeanDefinition解析註冊過程是個非常複雜而漫長的過程。如果是XML配置需要載入XML資源、解析XML文件、形成BeanDefition物件、再註冊BeanDefition,其中涉及到諸多Spring提供的元件。為了能夠清晰的展示和順利描述這些細節,先看下元件處理過程圖:
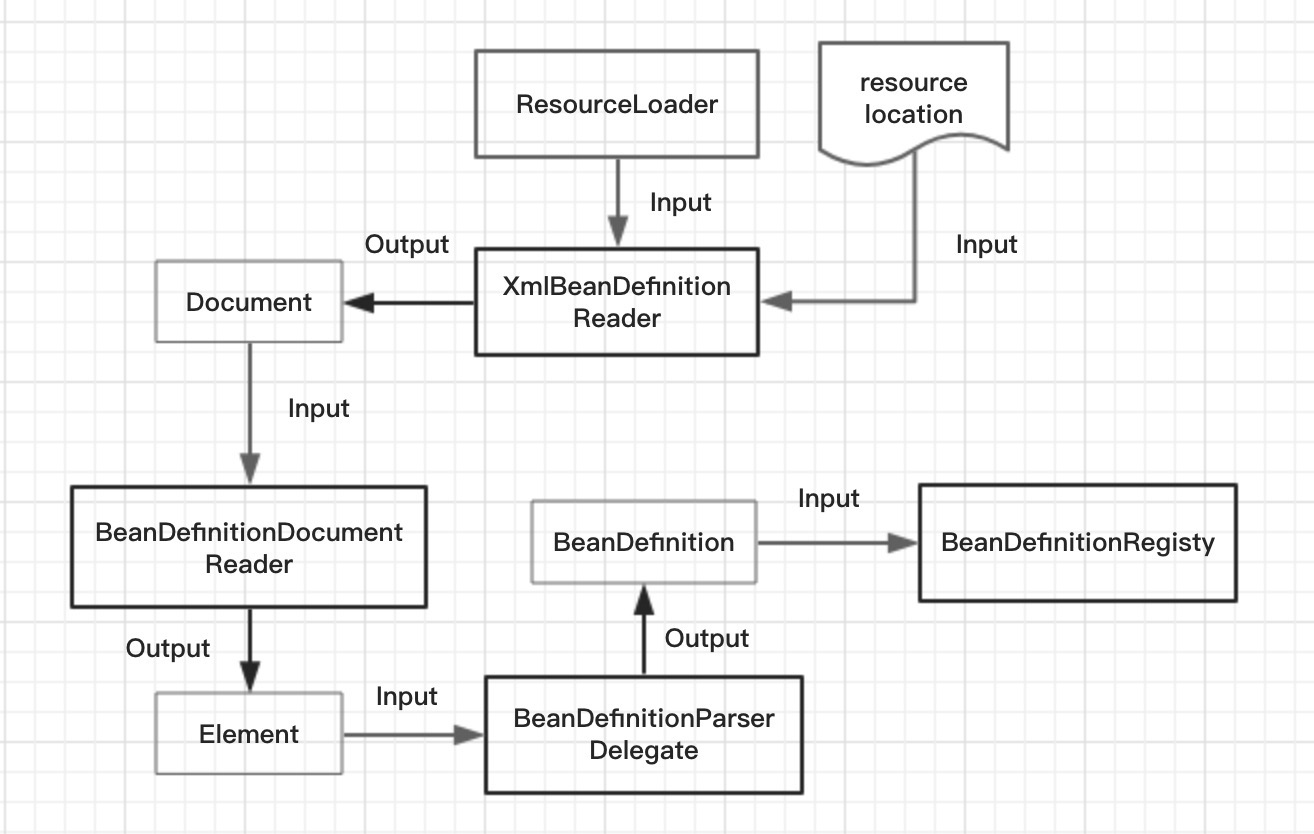
- 當使用XML配置Bean定義時,Spring ApplicationContext通過委託XmlBeanDefinitionReader載入路徑資源,並使用Java XML技術產生Document物件。XmlBeanDefinitionReader組合前篇文章中介紹的ResourceLoader,通過其載入路徑資源產生Resource物件。
- 同時XmlBeanDefinitionReader組合BeanDefinitionDocumentReader,委託其解析Dom,產生Element。每個Element元素即是Bean定義配置。
- BeanDefinitionDocumentReader中組合BeanDefinitionParserDelegate,將產生Bean定義配置的元資料輸入給Delegate,通過其解析Bean定義配置產生BeanDefinition物件。
- 最後將BeanDefinition輸入Bean定義註冊器,交由其註冊為上下文中的BeanDefinition。
2.元件概覽
BeanDefinitionReader
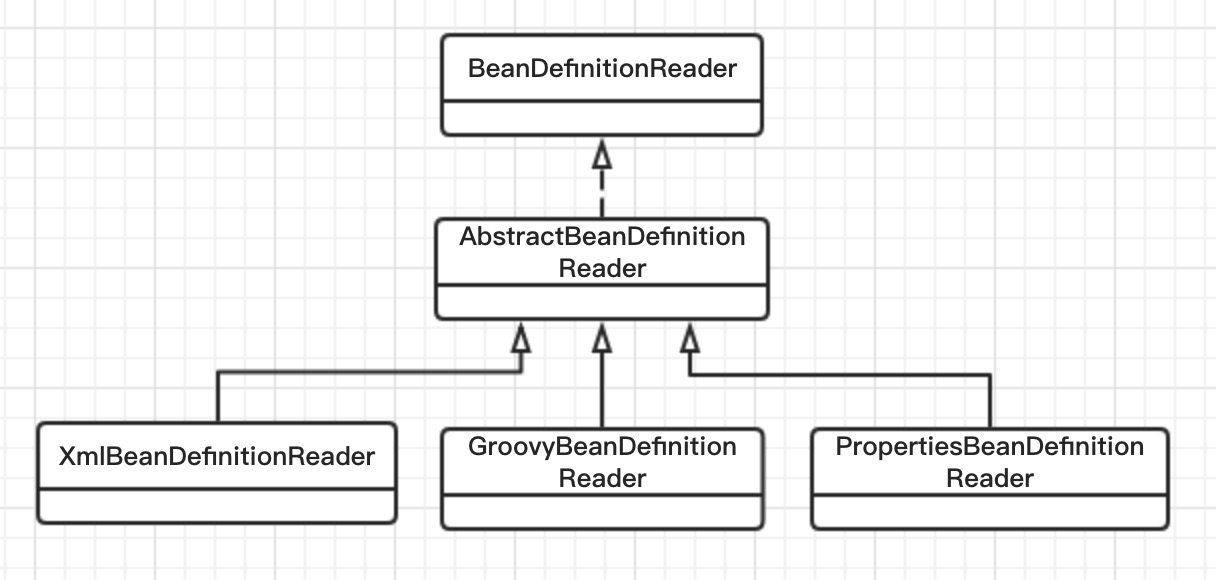
BeanDefinitionReader是Spring上下文中至關重要的元件。上下文通過組合BeanDefinitionReader從而具有解析Bean配置並進行讀Bean定義的能力。
BeanDefinitionReader定義了一套讀從路徑或資源載入Bean定義行為:
- int loadBeanDefinitions(Resource resource)
- int loadBeanDefinitions(Resource... resources)
同時BeanDefinitionReader提供獲取BeanDefinitionRegitry和ResourceLoader介面:
- BeanDefinitionRegistry getRegistry()
- ResourceLoader getResourceLoader()
其中根據讀的資源不同,分為多種實現:
- 當Bean配置使用XML時,上下文將使用XmlBeanDefinitionReader載入解析Bean定義。
- 當Bean配置使用Groovy指令碼時,上下文使用GroovyBeanDefinitionReader解析指令碼,生成BeanDefinition。
其中最常用的XmlBeanDefinitionReader載入資源使用ResourceLoader,解析XML使用下述BeanDefinitionDocumentReader。
Note:
BeanDefinitionReader這裡設計使用了無處不在傳神模式:策略。
根據不同的資源讀,分別封裝相應的演算法實現。
Tips:
ApplicationContext比BeanFactory具有更強的能力正是其組合了像BeanDefinitionReader這樣的元件,擴充套件了載入解析資源,生成BeanDefinition。
BeanDefinitionDocumentReader
XmlBeanDefinitionReader具有解析XML檔案的能力,但是實際的解析邏輯由被抽象成另一個物件實現,即BeanDefinitionDocumentReader。實際的XML解析由BeanDefinitionDocumentReader負責,BeanDefinitionDocumentReader的實現負責解析XML DOM樹,生成一個一個的Element元素。
BeanDefinitionDocumentReader只有一個預設實現DefaultBeanDefinitionDocumentReader。其中持有了解析XML的上下文,主要儲存一些解析上下文的配置。同時硬編碼了一些Spring XML Bean的標籤。
Note:
從XmlBeanDefinitionReader和BeanDefinitionDocumentReader的設計也可以看出,Spring的一些精妙之處。
其首先遵循了介面隔離原則,因為XML的解析可能會變化(比如擴充套件一些自定義的標籤等),所以將讀Document文件的邏輯隔離成BeanDefinitionDocumentReader。但是對於XML的載入卻是XML標準,屬於公共的邏輯由XmlBeanDefinitionReader完成。聚合公共,隔離變化。
其二遵循單一職責原則,載入DOM和解析DOM可以拆分。
BeanDefinitionDocumentReader除了以上功能外,還提供了註冊BeanDefinition的能力。當然是通過BeanDefinitionRegistry完成,後續介紹。
- void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
BeanDefinitionParserDelegate
以上BeanDefinitionDocumentReader負責解析DOM樹,對於解析結果Element元素即是單個具體的Bean定義配置。在Spring中對於單個Bean定義配置的解析委託BeanDefinitionParserDelegate實現。
BeanDefinitionParserDelegate提供了兩項能力:
- 解析能力:解析預設的XML名稱空間(即Bean空間)的配置
- 委託能力:委託其他的解析器解析相應名稱空間的配置,可以自由擴充套件自己實現的BeanDefinitionParser
javadocs中是這樣描述該類:
Stateful delegate class used to parse XML bean definitions.
Intended for use by both the main parser and any extension {@link BeanDefinitionParser BeanDefinitionParsers} or {@link BeanDefinitionDecorator BeanDefinitionDecorators}.
BeanDefinitionParserDelegate硬編碼了很多Bean配置的標籤常量用於匹配解析。同時還維持解析狀態,如:解析至哪個節點哪個屬性等。
Note:
對設計模式比較熟悉,應該能立即聯想到委託模式!BeanDefinitionParserDelegate為其他的解析器代理。整個應用的XML Bean配置解析對於上層元件呼叫者,只會感知BeanDefinitionParserDelegate存在,下層的各色的解析器可以自由演進、擴充套件,上層無需做任何改動(解耦)
BeanDefinitionRegistry
BeanDefinitionRegistry又是一個能讓人覺醒的命名,即Bean定義註冊器。先來看下它的介面定義:
- void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
- void removeBeanDefinition(String beanName)
- BeanDefinition getBeanDefinition(String beanName)
- boolean containsBeanDefinition(String beanName)
- 等等......
註冊/移除/獲取/是否包含Bean定義,一個非常標準的註冊器。BeanDefinitionRegistry是將從配置中解析出的Bean定義註冊為上下文合法的BeanDefinition。
該介面通常與Bean定義讀取配合使用,後者用於讀Bean定義,前者將讀出的Bean定義註冊。
而該介面大多數被BeanFactory實現,因為只有BeanFactory才會持有所有的BeanDefinition然後例項化為Bean例項。
下圖展示BeanDefinitionRegistry實現關係
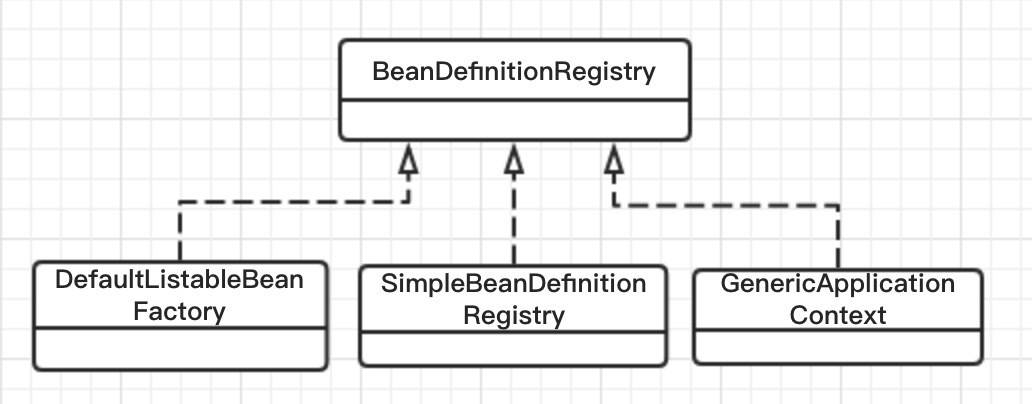
其中DefaultListableBeanFactory是其最通用的實現。該實現就是一個BeanFactory,讓BeanFactory有註冊Bean定義的能力。關於DefaultListableBeanFactory的很多實現細節,後面會詳述。
SimpleBeanDefinitionRegistry只是純粹的持有Bean定義和註冊Bean定義,而不是BeanFactory,主要是用於測試。
四.從路徑到資源載入
上篇文章Resource抽象中提及何時何地觸發載入解析資源時,提到本篇文章中詳述。同時本節也承接第二篇Envoriment元件繼續跟蹤上下文啟動流程。
1.上下文的重新整理
Override
public void refresh() throws BeansException, IllegalStateException {
// 使用監視器同步上下文啟動和關閉
synchronized (this.startupShutdownMonitor) {
// 為上下文重新整理做準備
// Prepare this context for refreshing.
prepareRefresh();
// 獲取上下文中的Bean工廠:載入資源、解析資源、解析Bean定義、註冊Bean定義
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}上下文重新整理是整個Spring框架的中的核心流程,所有子上下文實現的啟動都會呼叫refresh完成上下文的啟動,即模板方法,Spring將上下文的啟動過程抽象成一個固定的模板流程。Spring的啟動流程的絕大部分邏輯都有該refresh完成,邏輯過程非常複雜且漫長。refresh中也的邏輯流程中也提現了Bean的生命週期。由於過程非常長,系列原始碼中也是會將其拆解成一個個單一的部分詳解,最後再將其串聯起來。
Note:
這裡使用了另一個獨領風騷的設計模式,模板方法模式。refresh是模板方法方法,其中預留抽象方法和擴充套件點給子上下文實現擴充套件。模板方法模式的主要應用核心要領在於多變的業務邏輯能被抽象成固定的模板流程,只要滿足其要領,均可使用該模式實現出精彩的程式碼。
本節介紹refresh重新整理步驟中的核心步驟之一:建立BeanFactory,承接前篇的Environment:
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, ApplicationContext parent)
throws BeansException {
super(parent);
// 如果Environment未初始化,其中初始化Environment
setConfigLocations(configLocations);
// 呼叫上下文重新整理,進入Spring啟動的核心
if (refresh) {
refresh();
}
}refresh由AbstractApplicationContext實現,該上下文是上下文的基礎實現。開始重新整理上下文之前需要:進行同步,防止重新整理時進行上下文關閉操作,正確同步後才正式重新整理:
- 為重新整理做準備工作
- 建立上下文內部的BeanFactory
protected void prepareRefresh() {
// 獲取當前時間戳,記錄上下文啟動時間
this.startupDate = System.currentTimeMillis();
// 標識上下文為非關閉,原子變數
this.closed.set(false);
// 表示上下文為活躍狀態
this.active.set(true);
if (logger.isInfoEnabled()) {
logger.info("Refreshing " + this);
}
// 初始化上下文環境中的佔位屬性源,主要用於給子上下文實現的擴充套件點
// 前篇環境元件的文章中介紹到上下文環境屬性初始化,預設只有JVM系統屬性源和作業系統環境變數屬性源
// 在一些特殊環境的上下文中仍需要初始化其他的屬性源,如web環境中需要初始化的屬性源
// Initialize any placeholder property sources in the context environment
initPropertySources();
// 驗證環境中設定的必要的屬性
// Validate that all properties marked as required are resolvable
// see ConfigurablePropertyResolver#setRequiredProperties
getEnvironment().validateRequiredProperties();
// 初始化一個過早上下文事件容器,用於儲存一些在廣播器可用之前收集的上下文事件
// Allow for the collection of early ApplicationEvents,
// to be published once the multicaster is available...
this.earlyApplicationEvents = new LinkedHashSet<ApplicationEvent>();
}至此,上下文初始化的準備工作就完成,正式開始初始化上下文內部的Bean工廠:
獲取BeanFactory,重新整理上下文內部的BeanFactory
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();obtainFreshBeanFactory實現如下:
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
// 重新整理BeanFactory
refreshBeanFactory();
// 獲取BeanFactory
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}Spring上下文都是通過持有BeanFactory例項,從而具有IOC的能力。BeanFactory負責持有註冊Bean定義、例項化BeanFactory、依賴注入等等功能。
refreshBeanFactory中主要完成以下邏輯:
- 從String路徑載入資源,產生Resource物件
- 解析Resource,產生Document物件
- 解析DOM樹,解析Bean定義,產生BeanDefinition
- 註冊BeanDefinition
接下來逐步學習該過程。
refreshBeanFactory是AbstractApplicationContext中定義的抽象行為。AbstractApplicationContext並沒限制規定需要使用的BeanFactory的具體,更沒有實現預設行為,只是定義需要重新整理BeanFactory。對於具體使用哪種BeanFactory和具體的重新整理都交由子上下文擴充套件實現,非常標準的模板方法設計。
重新整理BeanFactory的行為由AbstractApplicationContext的子上下文AbstractRefreshableApplicationContext實現。javadocs是這樣描述它的:
Base class for {@link org.springframework.context.ApplicationContext} implementations which are supposed to support multiple calls to {@link #refresh()}, creating a new internal bean factory instance every time. Typically (but not necessarily), such a context will be driven by a set of config locations to load bean definitions from.
該上下文主要是每次呼叫重新整理時,都建立上下文內部的BeanFactory。
public abstract class AbstractRefreshableApplicationContext extends AbstractApplicationContext {
// 是否允許Bean定義覆蓋標誌
private Boolean allowBeanDefinitionOverriding;
// 是否允許迴圈引用標誌
private Boolean allowCircularReferences;
// 上下文內部持有的BeanFactory例項,預設使用DefaultListableBeanFactory
/** Bean factory for this context */
private DefaultListableBeanFactory beanFactory;
// beanFactory的同步器
/** Synchronization monitor for the internal BeanFactory */
private final Object beanFactoryMonitor = new Object();
}該上下文中持有具體的BeanFactory例項,用於註冊Bean定義、例項化Bean。這裡是一個很大的擴充套件,可以實現定製的BeanFactory,注入ApplicationContext中:
//子上下文實現可以覆蓋該建立BeanFactory的行為,建立定製化的BeanFacotry
protected DefaultListableBeanFactory createBeanFactory() {
return new DefaultListableBeanFactory(getInternalParentBeanFactory());
}AbstractRefreshableApplicationContext中除了建立BeanFactory例項,還定義了載入Bean定義進入BeanFactory的抽象行為:
// 載入Bean定義進入BeanFactory
void loadBeanDefinitions(DefaultListableBeanFactory beanFactory)該行為由子上下問實現,因為載入策略不一樣。
Note:
從這裡可以看出,這裡的設計又是那個傳說的策略模式
繼續深入其refreshBeanFactory的實現:
@Override
protected final void refreshBeanFactory() throws BeansException {
// 如果當前上下文有BeanFactory,則銷燬其所有的Bean例項,然後關閉BeanFactory
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
// 建立新的BeanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
// 實現了序列化介面,設定序列化Id
beanFactory.setSerializationId(getId());
// 自定義BeanFactory的屬性,又是BeanFactory的擴充套件點,用於給子上下文擴充套件
customizeBeanFactory(beanFactory);
// 呼叫載入Bean定義入BeanFactory
loadBeanDefinitions(beanFactory);
// 同步修改上下文的BeanFactory例項
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}從以上的邏輯可以看出,refreshBeanFactory中主要完成兩項邏輯:
- 銷燬當前上下文的BeanFactory和例項
- 建立上下文的新BeanFactory
其中customizeBeanFactory既是一處框架擴張點,又是BeanFactory的基本屬性初始化。預設實現中初始化了BeanFactory是否允許Bean定義覆蓋和是否允許迴圈引用。
不過該refreshBeanFactory的核心邏輯是觸發了loadBeanDefinitions行為。該loadBeanDefinitions是一項策略行為,需要根據不同的上下文以不同的方式載入Bean定義。這裡只分析ClassPathXmlApplicationContext的場景。
ClassPathXmlApplicationContext繼承了AbstractXmlApplicationContext,該上下文實現了loadBeanDefinitions,因為只有AbstractXmlApplicationContext才能確定是從Xml中載入Bean定義,所以由其實現loadBeanDefinitions的策略是非常合理的。
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 建立一個XmlBeanDefinitionReader用於讀Xml
// XmlBeanDefinitionReader中組合BeanFactory
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 配置BeanDefinitionReader,設定其環境
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
// 配置BeanDefinitionReader的資源載入器
beanDefinitionReader.setResourceLoader(this);
// 配置BeanDefinitionReader的Xml實體解析器
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
// 又是一個擴充套件點,供自上下文擴充套件定製BeanDefinitionReader的行為
initBeanDefinitionReader(beanDefinitionReader);
// 載入Bean定義
loadBeanDefinitions(beanDefinitionReader);
}再進一步深入loadBeanDefinitions之前,先看下XmlBeanDefinitionReader的內部結構:
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
...省略
// 預設的BeanDefinitionDocumentReader型別
private Class<?> documentReaderClass = DefaultBeanDefinitionDocumentReader.class;
// 解析XML出異常時能夠報告問題
private ProblemReporter problemReporter = new FailFastProblemReporter();
private ReaderEventListener eventListener = new EmptyReaderEventListener();
private SourceExtractor sourceExtractor = new NullSourceExtractor();
// 名稱空間解析器,主要處理不同名稱空間的XML配置解析
private NamespaceHandlerResolver namespaceHandlerResolver;
// 文件載入器,將Resource抽象載入解析出Document物件,生成記憶體DOM樹。主要是XML技術
private DocumentLoader documentLoader = new DefaultDocumentLoader();
// 也是XML技術,實體解析器
private EntityResolver entityResolver;
// 也是XML技術,SAX解析XML出錯時的處理器
private ErrorHandler errorHandler = new SimpleSaxErrorHandler(logger);
// 也是XML技術,用於XML驗證
private final XmlValidationModeDetector validationModeDetector = new XmlValidationModeDetector();
// 使用ThreadLocal和Set保證單個資源只會單個執行緒被解析一次
private final ThreadLocal<Set<EncodedResource>> resourcesCurrentlyBeingLoaded =
new NamedThreadLocal<Set<EncodedResource>>("XML bean definition resources currently being loaded");
}XmlBeanDefinitionReader是BeanDefinitionReader中關於在XML方面定義Bean配置的讀取的最終實現,所以從以上的成員域持有也可以看出其主要是在XML的處理上。
其中需要重點關注的是NamespaceHandlerResolver。它是Spring實現多名稱空間解析的關鍵。關於Spring多名稱空間解析,後續再介紹Spring Aop文章中再詳細介紹。
XmlBeanDefinitionReader主要關注的是Xml的處理,關於Bean定義的讀取更多相關,比如:資源路徑解析載入、環境等是在其非類,也就是通用的AbstractBeanDefinitionReader中定義。
public abstract class AbstractBeanDefinitionReader implements EnvironmentCapable, BeanDefinitionReader {
// Bean定義註冊器
private final BeanDefinitionRegistry registry;
// 資源載入
private ResourceLoader resourceLoader;
// 載入Bean Class的類載入器
private ClassLoader beanClassLoader;
// 環境元件
private Environment environment;
// Bean名稱生成器
private BeanNameGenerator beanNameGenerator = new DefaultBeanNameGenerator();
}AbstractBeanDefinitionReader中持有的成員域都是和Bean定義解析相關的共性物件。與實際的Bean配置格式無關。
在熟悉BeanDefinitionReader後,再來重點看loadBeanDefinitions實現:
// 從location代表的資原始檔載入Bean定義
@Override
public int loadBeanDefinitions(String location) throws BeanDefinitionStoreException {
return loadBeanDefinitions(location, null);
}
public int loadBeanDefinitions(String location, Set<Resource> actualResources) throws BeanDefinitionStoreException {
// 獲取資源載入器
ResourceLoader resourceLoader = getResourceLoader();
// 校驗資源載入器不能為空
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
}
// 如果是模式解析,則轉為ResourcePatternResolver型別解析路徑模式,並載入為Resource
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
// 使用模式解析器解析資源路徑並載入配置為Resource抽象。這部分內容在上篇文章Resource抽象中已深入介紹
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
// 從多個Resource抽象中載入Bean定義
int loadCount = loadBeanDefinitions(resources);
if (actualResources != null) {
for (Resource resource : resources) {
actualResources.add(resource);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
}
// 返回載入的Bean定義個數
return loadCount;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
// 如果不是模式路徑,則使用ResourceLoader載入單個資源
else {
// Can only load single resources by absolute URL.
// 資源載入器載入配置為Resource抽象,上篇文章已深入介紹
Resource resource = resourceLoader.getResource(location);
// 根據Resource抽象載入Bean定義
int loadCount = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
}
// 返回載入的Bean定義個數
return loadCount;
}
}對於以上的原始碼邏輯有兩點需要注意:
- Spring根據路徑載入資源是什麼時候開始,從哪裡切入的
- BeanDefinitionReader載入Bean定義介面的多型所提供的能力
上篇文章留下的疑問:Spring根據路徑載入資源是什麼時候開始,從哪裡切入的,這裡基本上也已經解決。Spring在使用構造上下文內部的BeanFactory時,將使用XmlBeanDefinitionReader載入BeanDefinition進入BeanFactory,這時涉及到資源路徑解析為Resource抽象。
總結下,什麼時候觸發資源路徑解析載入為Resource抽象:只有當需要載入Bean定義的時候。由誰觸發:實際處理Bean配置檔案的閱讀器BeanDefinitionReader負責。
關於解析資源路徑且載入為Resource的詳細內容上篇文章Resource抽象已經詳細說明,這裡不再贅述。
接下來再看第二個問題:BeanDefinitionReader載入Bean定義介面的多型所提供的能力
// 從resource載入Bean定義
int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;
// 從多個resource載入Bean定義
int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException;
// 從resource的路徑載入Bean定義
int loadBeanDefinitions(String location) throws BeanDefinitionStoreException;
// 從多個resource路徑載入Bean定義
int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException;BeanDefinitionReader中對於載入Bean定義具有多種形態,極大程度的提升了其載入Bean定義的能力。但是無從resource路徑載入Bean定義,還是利用ResourceLoader將路徑解析並載入為resource,從而轉化為從resource載入Bean定義。
既然知道從路徑載入Bean定義的原理,那繼續看載入Bean定義的細節。實際的載入Bean定義loadBeanDefinitions(Resource resource)或者loadBeanDefinition(Resource... resources)完成。但是後者也是內部迴圈呼叫前者試下,反正就是多型!這裡直接分析前者實現
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 將Resource包裝成EncodedResource再載入,EncodedResource是具有編碼能力能力的InputStreamResource
return loadBeanDefinitions(new EncodedResource(resource));
}因為涉及到Resource的讀取,必然會有Encode問題。不然會產生亂碼,所以這裡將描述資源的Resource轉為具有編碼的可輸入的資源。
Note:
這裡使用了裝飾器模式,EncodedResource通過包裝InputStreamSource的實現Resource並加上Encode增強了Resource的能力。從這裡也可以看出Spring介面抽象的隔離的非常徹底。Resource/EncodeResource都是InputStreamSource的實現,但是職責並不相同。
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
// 非空檢驗和記錄日誌
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource);
}
// 使用前文介紹XmlBeanDefinitionReader中resourcesCurrentlyBeingLoaded防重
// 如果當前檔案未被正在解析,則加入本地執行緒快取,防止後續重複解析
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
// 將EncodedResource轉為java中w3c實現的XML技術中的InputSource
try {
// 獲取資源對應的輸入流,這是Resource的基本能力,實現了InputStream介面,具有獲取資源對應的輸入流的能力
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
// InputSource是JAVA XML技術中的規範api,代表XML輸入源
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 做實際的載入Bean定義的邏輯
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
// 解析完畢時,移除已經解析過的檔案
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}該方法的重要邏輯在doLoadBeanDefinitions中實現,它主要負責載入Bean定義
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 根據InputSource載入XML的標準介面的文件物件Document,即將XML載入記憶體,形成DOM樹
Document doc = doLoadDocument(inputSource, resource);
// 解析DOM樹上的各個節點,每個節點即是Bean定義
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}關於建立Document的過程這裡不再詳述,主要關注Bean定義的解析過程。直接分析registerBeanDefinitions的邏輯:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// 此時的document實際上是包含Bean定義的DOM樹,Spring中對於該Dom的解析,抽象出BeanDefinitionDocumentReader介面
// 這裡建立其實現,採用預設實現DefaultBeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// 獲取Bean定義註冊器中當前BeanDefinition的個數
int countBefore = getRegistry().getBeanDefinitionCount();
// 註冊Bean定義
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 獲取此次註冊的Bean定義個數
return getRegistry().getBeanDefinitionCount() - countBefore;
}這裡需要關注兩點:
- BeanDefinitionDocumentReader
- XmlReaderContext
關於BeanDefinitionDocumentReader介面的抽象和其具體定義,在之前小節的元件概覽中已經介紹,這裡不再贅述。這裡注意其建立過程的技巧:
// XmlBeanDefinitionReader中持有的BeanDefinitionDocumentReader實現的型別
private Class<?> documentReaderClass = DefaultBeanDefinitionDocumentReader.class;
// 根據持有的型別建立BeanDefinitionDocumentReader的實現例項
protected BeanDefinitionDocumentReader createBeanDefinitionDocumentReader() {
return BeanDefinitionDocumentReader.class.cast(BeanUtils.instantiateClass(this.documentReaderClass));
}在這裡,XmlBeanDefinitionReader也提供了Set介面,可以寫入自定義的BeanDefinitionDocumentReader的實現用於擴充套件。BeanDefinitionDocumentReader本身就是解析Bean定義配置的XML的SPI。
Note:
一般典型的SPI的擴充套件方式都是採用Java提供的SPI機制,但是這裡的技巧也不失為一種方式,主要是面向Spring IOC。
對於createReaderContext實現。該方法主要是為了建立解析XML的上下文,持有一些全域性的配置和元件。
以下是XmlReaderContext的成員域細節
// 解析XML,解析Bean定義是一個非常複雜而漫長的邏輯過程
// 需要有全域性的物件能夠hold這個過程的元件資訊。抽象出XmlReaderContext
public class XmlReaderContext extends ReaderContext {
// hold XmlBeanDefinitionReader後續會使用其持有的Bean定義註冊器
// 後續需要使用Environment
private final XmlBeanDefinitionReader reader;
// hold namespaceHandlerResolver,後續再解析import資源時需要
private final NamespaceHandlerResolver namespaceHandlerResolver;
}public XmlReaderContext createReaderContext(Resource resource) {
// 只是new 建立一個XmlReaderContext,hold當前解析XML對應的resource, XmlBeanDefinitionReader
// NamespaceHandlerResolver等關於XML解析的元件
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, getNamespaceHandlerResolver());
}在建立了BeanDefinitionDocumentReader和XmlReaderContext後,繼後再根據Document註冊Bean定義。首先需要逐個逐個解析DOM中的Node,然後逐個解析為Bean定義配置。解析Dom形成NodeD額過程由BeanDefinitionDocumentReader負責。所以其中的核心邏輯是 documentReader.registerBeanDefinitions(doc, createReaderContext(resource)):
registerBeanDefinitions(Document doc, XmlReaderContext readerContext)該介面由預設的DefaultBeanDefinitionDocumentReader實現,在XmlBeanDefinitionReader中建立的也是該預設實現的例項,前文已經介紹。DefaultBeanDefinitionDocumentReader中的實現:
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
// 賦值readerContext
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
// 解析DOM樹根節點root
Element root = doc.getDocumentElement();
// 根據根節點解析註冊Bean定義
doRegisterBeanDefinitions(root);
}解析DOM數的根元素,然後根據根元素解析並並註冊Bean定義:
protected void doRegisterBeanDefinitions(Element root) {
// Any nested <beans> elements will cause recursion in this method. In
// order to propagate and preserve <beans> default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
// 每次開始解析根元素之前(更貼切的說,是Beans標籤的元素),
// 將當前的BeanDefinitionParserDelegate作為父委託解析器,建立新的子委託解析器
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 判斷當前根元素是否為預設名稱空間
if (this.delegate.isDefaultNamespace(root)) {
// 獲取根元素屬性:profile
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
// profile可以配置多個,使用";"分割,這裡按照此規則解析profile屬性
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// 之前文章已經介紹Environment的能力,這裡不再贅述
// 前文也介紹了XmlReaderContext持有解析過程的元件,從其可以獲取上下文的Environment元件
// 使用Environment元件抉擇該profile是否為activeProfile,進一步決定該Bean定義配置是否需要解析
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
// 如果該profile不滿足,則不解析,直接返回
return;
}
}
}
// 解析Bean定義前,處理Xml之前的邏輯
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
// 解析Bean定義後,處理Xml之前的邏輯
postProcessXml(root);
// 還原現場,這是遞迴的基本原則
this.delegate = parent;
}該實現中有幾點需要關注:
- 建立父子Bean定義解析委託器的原因
- spring profile的實現
- 名稱空間解析
- 解析Bean定義的hook
逐個擊破,來看這些問題。關於第一個問題,相信Spring註釋說的也夠清楚了。XML配置中,Bean定義的配置都是在Bean名稱空間和Beans根元素下的,如:
<?xml version="1.0" encoding="UTF-8"?>
<beans default-lazy-init="true"
default-autowire="byName"
default-init-method="printHelloWorld"
default-destroy-method="printHelloWorld"
default-merge="false"
default-autowire-candidates=""
profile="default"
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
...bean定義配置省略
<beans>
...bean定義配置省略
</beans>
</beans>從以上可以看出bean定義配置都是嵌入在根元素Beans下,同時Beans元素仍支援屬性配置,用於做全域性配置。但是Beans下還可以巢狀Beans,這裡有點遞迴(巢狀)的表現。所以需要設定父子BeanDefinitionParserDelegate,用於分別持有Beans的屬性。同時BeanDefinitionParserDelegate是有狀態的解析器,它需要維持正在解析的位置在哪裡,上一層解析位置在哪裡等等狀態資訊,也需要父子BeanDefinitionParserDelegate維持各自的Beans解析。
在之前Environment元件的文章中已經介紹過Spring Profile的能力是Enviroment賦予的。其中之介紹Environment中的profile細節,但是Environment抉擇Bean定義是否滿足當前active profile的切入點並未詳細說明。現在時機已到,從以上可以看出Environment是如何抉擇Bean定義是否屬於active profile的實現。需要兩點:
- Environment當前的active profile是什麼
- Bean定義配置的profile是多少
需要注意的是,如果Bean定義未配置profile,那麼久認為是該Bean定義配置是全域性生效的。
再者就是名稱空間解析,在Spring中不同名稱空間的配置是不一樣的,這決定其解析方式不一樣,且配置的作用也不一樣決定其有相應的處理邏輯。在這裡有名稱空間解析處理相應配置是否屬於預設的名稱空間:
public boolean isDefaultNamespace(String namespaceUri) {
// 不為空且等於http://www.springframework.org/schema/beans,則認為是預設名稱空間
// 可以看出Spring中預設名稱空間是Beans名稱空間
return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
}
public boolean isDefaultNamespace(Node node) {
// 獲取Node所屬的名稱空間,這是XML技術,再判斷是否為預設名稱空間
return isDefaultNamespace(getNamespaceURI(node));
}關於第四點解析Bean定義的hook,Spring不愧是高擴充套件框架:擴充套件無處不在。這裡留下解析前和解析後的擴充套件鉤子,應用可以繼承DefaultBeanDefinitionDocumentReader實現新的Reader並覆蓋鉤子,然後注入XmlBeanDefinitionReader中。
Note:
在寫業務程式碼時,也要有這種思想,在易發生變化的地方可以預留hook,實現擴充套件,由其是模板方法模式中預留hook是必要的!
最後的重點就在於parseBeanDefinitions(root, this.delegate),它是用於觸發Bean定義委託器解析Bean定義的關鍵:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 判斷是否為預設名稱空間,如果是則使用預設方式解析
// 如果不是使用自定義方式解析
if (delegate.isDefaultNamespace(root)) {
// 獲取根元素下所有子節點
NodeList nl = root.getChildNodes();
// 迴圈遍歷解析每個子節點
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 判斷子節點是否為預設名稱空間
// 如果是beans,使用預設方式解析
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
// 不是Beans名稱空間,使用自定義方式解析元素
else {
delegate.parseCustomElement(ele);
}
}
}
}
// 不是Beans名稱空間,使用自定義方式解析元素
else {
delegate.parseCustomElement(root);
}
}對於Spring配置瞭解的讀者,肯定知道Spring的XML配置可以通過引入其他的名稱空間,可以在Beans元素下定義其他名稱空間的配置。如:引入Context名稱空間,可以佔位解析器配置:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!-- context名稱空間下的佔位解析配置,上面引入了Context名稱空間 -->
<context:property-placeholder></context:property-placeholder>
</beans>以上的程式碼邏輯就是處理這種case。
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 解析import標籤
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
// 解析alias標籤
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
// 解析Bean標籤,這是解析Bean定義
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
// 解析巢狀的Beans標籤
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}從以上可以看出,預設的Bean空間解析,只有import/bean/beans/alias四種標籤,且DOM的部分解析都是在BeanfinitionDocumentReader中完成。我們這裡重點關注bean標籤的解析,關於其他三種,考慮到篇幅原因這裡不做詳細介紹。
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 委託Bean定義解析器解析Bean,產生BeanDefinitionHolder物件
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// hold不為空
if (bdHolder != null) {
// 抉擇是否需要修飾BeanDefinition
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 註冊BeanDefinition進入BeanFactory
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
// 報告註冊錯誤
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
// 傳送註冊事件
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}處理Bean定義的主要邏輯就是兩點:
- 使用委託器解析BeanDefinition
- 註冊解析結果BeanDefinition至BeanFactory
到這裡,關於Spring載入資源和XML Bean配置的DOM解析就已經結束。這一節講述的內容比較複雜漫長,這裡做下總結:
- AbstractRefreshableApplicationContext中定義了loadBeanDefinitions介面,為什麼在該上下文中定義?因為它是可以重新整理上下文內部的BeanFactory,在重新整理的過程中需要載入Bean定義進入BeanFactory,所以在這裡定義。由誰實現?由頂層接近應用的上下文(分類)實現,它們按照不同Bean定義的配置方式實現其不同的載入方式,如XML配置Bean定義,則由AbstractXmlApplicationContext實現;如Java Config配置,則由AnnotationConfigWebApplicationContext實現解析,等等。
- 需要BeanDefinitionReader,它是什麼?它是Bean定義讀取器,這個元件應該需要哪些邏輯?能夠載入資源,解析配置的BeanDefinition。
- XmlBeanDefinitionReader的能力,如果通過ResourceLoader解析路徑模式,載入資源為Resource抽象?如果解析Resource抽象為XML標準的DOM樹,又是如和解析DOM樹。
Spring上下文可以看成是kernal,通過組合XmlBeanDefinitionReader而具有處理XML配置的能力,通過將XmlBeanDefinitionReader和BeanDefinitionRegistry組合,可以達到註冊BeanDefinition的能力。
五.資源解析形成BeanDefinition
這節中主要承接上文中委託器是如何解析Bean定義配置,如何構造產生BeanDefinition的。這部分邏輯主要在BeanDefinitionDelegate中完成。
BeanDefinitionDelegate委託器不僅用於解析預設的Bean定義配置,還整合BeanDefinitionParser用於擴擴充套件Spring配置的解析,如:AOP名稱空間、Context命名孔家的解析,等等,甚至是自定義的名稱空間。javadocs是這樣描述這個類的:
Stateful delegate class used to parse XML bean definitions Intended for use by both the main parser and any extension {@link BeanDefinitionParser BeanDefinitionParsers} or {@link BeanDefinitionDecorator BeanDefinitionDecorators}.
它具有兩項能力:
- 作為主要的預設Bean定義解析器
- 作為擴充套件的BeanDefinitionParser的委託
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
// 獲取bean的id屬性,這裡且包括以下的獲取方式都是XML技術提供的api
String id = ele.getAttribute(ID_ATTRIBUTE);
// 獲取bean的name屬性,name屬性為bean的別名
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 生成別名,bean的name屬性可以配置多個,使用",;"分割即可
List<String> aliases = new ArrayList<String>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
// 將id作為bean的名字
// 如果bean未配置id,則將別名中的第一個作為bean的id,也就是bean名字
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
// 如果containingBean等於空,則要檢驗bean的名字是否唯一
// bean的名字需要唯一
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 以上邏輯都是為了獲取bean的名字和別名
// 這裡使用bean的元資料(即Element)和bean的名字進一步解析該bean的屬性配置,生成bean對應的BeanDefinition物件
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
// 如果bean定義不為空
if (beanDefinition != null) {
// 人員故意bean名字為空,則需要為其生成一個
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
// 使用bean名字,bean別名,bean定義構造BeanDefinitionHolder
// 該holder主要是為了持有bean名字和bean別名
String[] aliasesArray = StringUtils.toStringArray(aliases);
// 返回holder
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}從以上邏輯中可以看出,處理了兩部分:
- 處理bean的名字和bean的別名
- 使用bean名字和bean的元資訊源Element進一步解析Bean定義
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, BeanDefinition containingBean) {
// 將當前解析的bean入棧,儲存解析狀態,能夠定位到當前處理的bean的位置
this.parseState.push(new BeanEntry(beanName));
// 解析bean的class
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
// 解析bean的parent屬性
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
// 使用bean的類名和parent屬性建立該bean對應的BeanDefintiion
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析bean配置的的屬性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
// 設定bean定義的描述
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
// 解析bean定義的元元素
parseMetaElements(ele, bd);
// 解析Lookup覆蓋方法子元素
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// 解析Replace方法子元素
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
// 解析構造引數值
parseConstructorArgElements(ele, bd);
// 解析成員屬性值
parsePropertyElements(ele, bd);
// 解析Qualifier元素
parseQualifierElements(ele, bd);
// 設定bean定義屬於的資源Resource
bd.setResource(this.readerContext.getResource());
// 設定bean定義的源,即是DOM樹中的哪個節點
bd.setSource(extractSource(ele));
返回bean定義物件
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
// 返回前,需要彈出當前bean定義位置,已經解析完畢
this.parseState.pop();
}
return null;
}讀以上的邏輯,可以看出才是Spring中解析XML Bean配置的核心。前面的那些步驟,都是為這裡鋪墊。
關於Bean定義的解析其實也是十分複雜的,但是可以簡化的瞭解大致的邏輯過程:
- 解析Bean名字,包括別名的解析
- 解析Bean的class型別
- 解析Bean配置的屬性值
- 解析Bean的Lookup覆蓋方法
- 解析Bean的Replace方法
- 解析Bean的構造引數值
- 解析Bean的成員屬性值
- 等等...
其中最為關鍵的是著重部分。這裡只分析這三個部分,關於方法的解析,日常開發並不常用。
1.解析Bean配置的屬性值
Bean本身有很多屬性配置,如:作用域、是否懶惰初始化、裝配方式、初始化方法、銷燬方法、工廠方法等等。parseBeanDefinitionAttributes就是為了解析Bean的這些自身屬性。
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
BeanDefinition containingBean, AbstractBeanDefinition bd) {
// 解析bean單例屬性,這是spring v1.x版本在使用,升級至scope屬性。這裡報告錯誤
if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
}
// 解析bean作用屬性並設定
else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
}
else if (containingBean != null) {
// Take default from containing bean in case of an inner bean definition.
bd.setScope(containingBean.getScope());
}
// 解析bean的抽象屬性
if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
}
// 解析設定bean是否懶惰初始化屬性
String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
if (DEFAULT_VALUE.equals(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit(TRUE_VALUE.equals(lazyInit));
// 解析設定bean的自動裝配方式
String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
bd.setAutowireMode(getAutowireMode(autowire));
// 解析並設定bean的依賴檢查屬性
String dependencyCheck = ele.getAttribute(DEPENDENCY_CHECK_ATTRIBUTE);
bd.setDependencyCheck(getDependencyCheck(dependencyCheck));
if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
}
// 解析並設定bean是否為自動裝配候選者
String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
if ("".equals(autowireCandidate) || DEFAULT_VALUE.equals(autowireCandidate)) {
String candidatePattern = this.defaults.getAutowireCandidates();
if (candidatePattern != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
}
else {
bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
}
// 解析並設定bean的primary屬性
if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
}
// 解析並設定bean的初始化方法
if (ele.hasAttribute(INIT_MET