
Spring原始碼系列 — 註解原理
前言
前文中主要介紹了Spring中處理BeanDefinition的擴充套件點,其中著重介紹BeanDefinitionParser方式的擴充套件。本篇文章承接該內容,詳解Spring中如何利用BeanDefinitionParser的特性實現註解配置的解析。本文主要從以下幾個方面介紹Spring中的註解配置解析原理:
- @Component系註解配置的作用原理
- @Autowired註解配置的作用原理
無論註解配置還是XML配置,只是外在配置形式的變化,但是Spring的核心仍然是相同的:
@Component系註解配置的作用原理
在介紹@Component原理前,先總結下@Component系的註解:
- @Service
- @Repository
- @Configuration
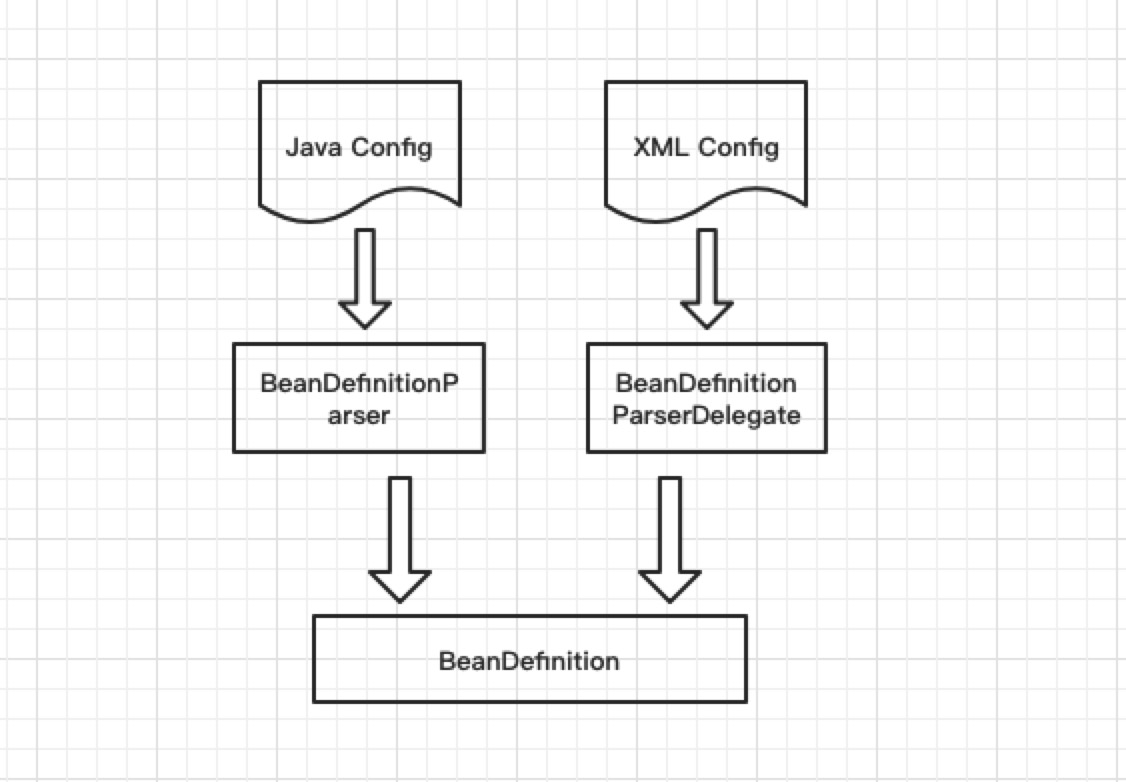
以上這些都均屬於@Component系註解,均被Component修飾。其實Spring應用者需要明白無論是XML配置,還是以上的這些註解配置,它們只是配置形式上的變化,但是內在表述這種配置的BeanDefinition模型仍然是統一的。形式上的變化,只會導致適配該形式的解析會發生變化。下文將從原始碼的角度先分析Component系註解配置的解析。
涉及到Bean配置的解析自然不能脫離前文中講述到的BeanDefinitionParser(如果還沒有閱讀過前文的讀者,這裡送一個傳送門Spring原始碼系列 — BeanDefinition擴充套件點
同時大家也應該知道觸發@Component註解生效,需要配置XML:<component-scan/>。
從前文的ContextNameSpaceHandler中可以看到component-scan該配置由ComponentScanBeanDefinitionParser負責解析。該BeanDefinitionPaser是開始處理@Component的入口,負責將被@Component系註解修飾的配置解析為BeanDefinition。
同樣ComponentScanBeanDefinitionParser實現了parse方法:
// element為XML配置元素,parserContext解析上下文 @Override public BeanDefinition parse(Element element, ParserContext parserContext) { // 獲取該元素的base-package的屬性 // spring應用者,應該不陌生<context:component-scan base-package="..."/>這樣的配置 // 獲取被@Componet系註解配置的類所在的包路徑 String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE); // 利用環境元件解析路徑,處理其中的佔位。關於這部分內容在前文中已經介紹 basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage); // 因為base-package可以配置多個,所以這裡根據分隔符進行分割處理,形成包路徑陣列。預設分割符為:",; \t\n" String[] basePackages = StringUtils.tokenizeToStringArray(basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS); // Actually scan for bean definitions and register them. // 建立Bean定義的掃描器元件 ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element); // 掃描basePackages下被@Componet系註解修飾的Bean,形成BeanDefinition Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages); // 註冊公共的元件 registerComponents(parserContext.getReaderContext(), beanDefinitions, element); return null; }
以上的邏輯已經非常清晰明瞭,對於使用環境元件處理basePackages中的佔位部分,如果讀者不瞭解,這裡有傳送門Spring原始碼系列 — Envoriment元件。 繼續學習configureScanner中如果建立Scanner。主要分為兩部分:
- 建立Scanner
- 配置Scanner
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {
// 解析componet-scan中配置的use-default-filters屬性
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
useDefaultFilters = Boolean.valueOf(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
// 建立Bean定義Scanner
// Delegate bean definition registration to scanner class.
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);
// 配置預設的BeanDefinitionDefaults,該物件持有預設的Bean定義屬性
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
// 配置自動注入候選者模式
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
// 配置資源模式
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));
}
try {
// 配置BeanName生成器
parseBeanNameGenerator(element, scanner);
}
catch (Exception ex) {
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
try {
// 配置作用域
parseScope(element, scanner);
}
catch (Exception ex) {
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
// 配置型別過濾器
parseTypeFilters(element, scanner, parserContext);
return scanner;
}關於以上配置Scanner由幾個地方需要重點關注:
- 預設的過濾器
- 配置預設的BeanDefinitionDefaults
- 配置BeanName生成器
- 配置型別過濾器
BeanDefinitionDefaults是持有BeanDefinition屬性的預設配置,其中有是否惰性初始化、自動裝配模式、初始化/銷燬方法等。這些Bean定義屬性將會作為預設值配置到將要被解析的BeanDefinition中。
BeanName生成器將會為沒有配置Bean名字的BeanDefinition生成Bean名字。
型別過濾器非常重要,使用base-packages配置了包路徑,這些路徑下的類需要被過濾。如使用@Component註解修飾的類將會被過濾,然後解析為BeanDefinition,其他的類將不會被處理。
其中有變數useDefaultFilters標誌是否使用預設的過濾器,我們繼續看下createScanner的實現:
protected ClassPathBeanDefinitionScanner createScanner(XmlReaderContext readerContext, boolean useDefaultFilters) {
// 直接new創鍵Scanner
return new ClassPathBeanDefinitionScanner(readerContext.getRegistry(), useDefaultFilters,
readerContext.getEnvironment(), readerContext.getResourceLoader());
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
// 賦值BeanDefinitionRegistry
this.registry = registry;
// 判斷是否使用預設的過濾器
if (useDefaultFilters) {
// 註冊預設的過濾器
registerDefaultFilters();
}
// 設定環境元件
setEnvironment(environment);
// 設定資源載入器
setResourceLoader(resourceLoader);
}以上需要注意的是resourceLoader,前文在介紹BeanDefinition解析時,提到XmlReaderContext是用於持有Spring解析XML配置時的各種元件資訊,其中包括資源載入器。這裡將資源載入器傳給Scanner,Scanner通過組合ResourceLoader從而具有了載入資源的能力。
同時需要注意useDefaultFilters,它用於控制是否註冊預設的型別過濾器,繼續看下預設的過濾器是什麼:
protected void registerDefaultFilters() {
// includeFilters中新增關於Component註解的過濾器
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
// 新增ManagedBean註解的過濾器
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.debug("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
// 新增Named註解的過濾器
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.debug("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}從以上預設的過濾器可以看出,被@Component、@ManagedBean、@Named註解修飾的類都將被註冊為Bean。
建立和配置Scanner的邏輯雖然不復雜,當時呼叫鏈路還是有點繞彎。這裡整理下:
Scanner主要完成兩項邏輯:
- 負責掃描目標包路徑下的註解配置,並將其解析為BeanDefinition;
- 將解析出的BeanDefinition註冊到BeanFactory中;
其中為了實現包路徑下的Bean配置的擴充套件性、動態配置解析,Scanner中通過組合兩種型別過濾器:
- 需要解析的過濾器
- 排除解析的過濾器
該兩種過濾器可以在
// 包含的過濾器
private final List<TypeFilter> includeFilters = new LinkedList<TypeFilter>();
// 排除的過濾器
private final List<TypeFilter> excludeFilters = new LinkedList<TypeFilter>();在瞭解Scanner的建立和配置後,再來看其如何載入資源,檢測並解析BeanDefinition和註冊。
其中doScan中完成以上的三步邏輯:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
// 建立將被解析的BeanDefinition容器
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<BeanDefinitionHolder>();
// 迴圈遍歷掃描多個包路徑
for (String basePackage : basePackages) {
// 在basePackage下尋找BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 迴圈遍歷已尋找到的BeanDefinition
for (BeanDefinition candidate : candidates) {
// 解析該candidate的作用域
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 生成BeanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 如果是AbstractBeanDefinition,則後置處理BeanDefinition
// 主要將BeanDefinitionDefaults的屬性覆蓋到BeanDefiniton中
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 處理該BeanDefinition的一些公共的註解資訊
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 檢查該Bean定義是否已經存在,或者與已存在的Bean定義是否相容
if (checkCandidate(beanName, candidate)) {
// 註冊Bean定義至BeanFactory中
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}首先看前兩步驟,載入資源然後檢測解析Bean定義,這個過程是由findCandidateComponents完成:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// 建立Bean定義容器
Set<BeanDefinition> candidates = new LinkedHashSet<BeanDefinition>();
try {
// 基於給定的包路徑組裝成檢索的路徑:
// 1. 將包路徑分隔符替換成檔案系統分隔符
// 2. 加上資源解析模式字首"classpath*:"
// 3. 加上資源模式字尾"**/*.class",用於表示路徑層次和要檢測的檔案型別為.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 使用resourceloader獲取給定的檢索路徑上的所有匹配的資源
// 關於這部分邏輯在介紹BeanDefinition一文中已經詳細介紹,這裡不再贅述
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 遍歷每個資源
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
// 如果資源是可讀
if (resource.isReadable()) {
try {
// 這裡使用工廠模式獲取該資源的元資料閱讀器(MetadataReader)
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
// 根據MetadataReader判斷是否為匹配的候選者Component
if (isCandidateComponent(metadataReader)) {
// 如果是,則構造ScannedGenericBeanDefinition型別的Bean定義
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
// 設定Bean定義的resourc和source屬性
sbd.setResource(resource);
sbd.setSource(resource);
// 決策該class是否為滿足條件的候選者
// 1. 需要滿足是非抽象類;2. 需要滿足是頂級的無依賴類(即非巢狀的內部類)
if (isCandidateComponent(sbd)) {
// 如果是候選者,則加入bean定義容器中
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
// 資源不可讀,則忽略跳過該資源
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}在細說這段邏輯之前,先來了解一些基礎的元件:MetadataReader、MetadataReaderFactory、ClassMetadata、AnnotationMetadata、ScannedGenericBeanDefinition、TypeFilter。
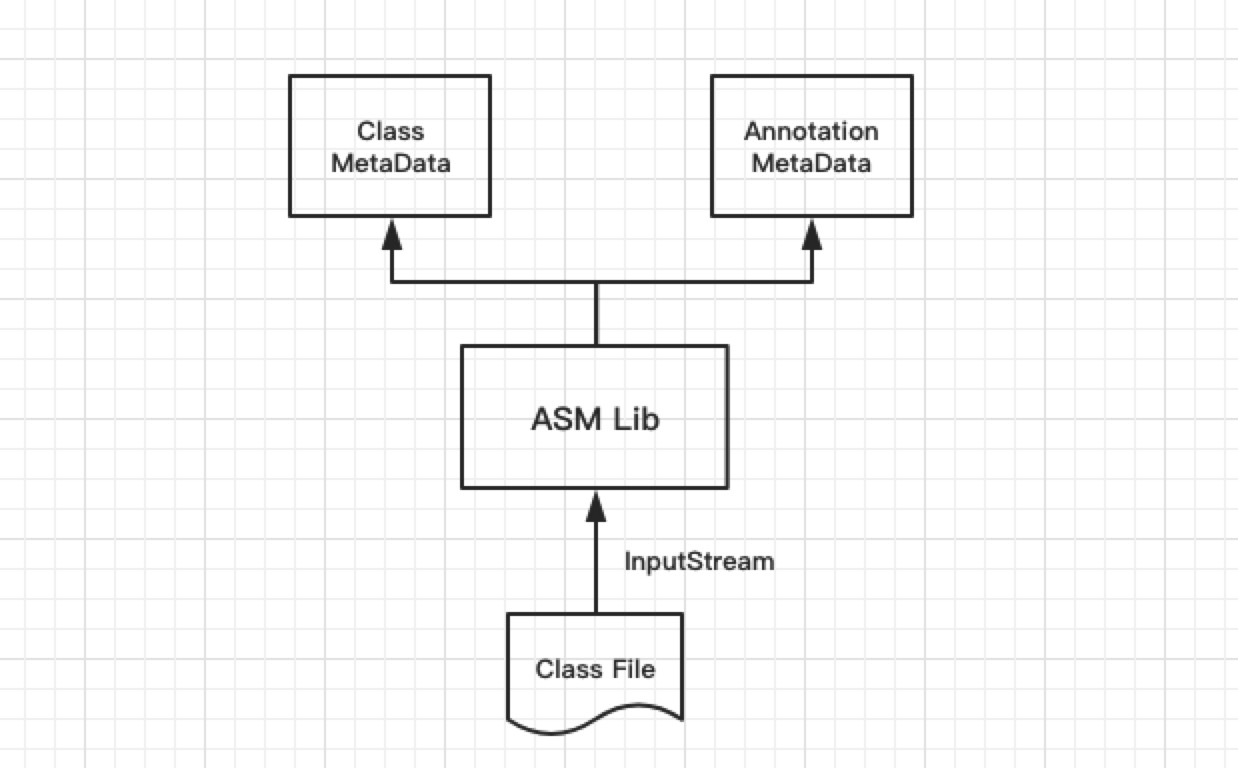
MetadataReader是Spring封裝用於訪問class檔案的門面工具,通過它可以獲取到class的元資訊。主要是通過ASM庫的ClassReader實現。從介面定義上分析:
public interface MetadataReader {
// 獲取class類的元資訊
ClassMetadata getClassMetadata();
// 獲取該類被修飾的註解的元資訊
AnnotationMetadata getAnnotationMetadata();
}MetadataReaderFactory也是Spring封裝用於建立指定類的MetadataReader門面。即這裡使用了工廠模式。通過其介面抽象可以可以體會到其工廠的設計理念:
public interface MetadataReaderFactory {
// 根據類名獲取指定的MetadataReader
MetadataReader getMetadataReader(String className) throws IOException;
// 根據指定的resource獲取對應的MetadataReader
MetadataReader getMetadataReader(Resource resource) throws IOException;
}ClassMetadata是該類的元資訊的抽象,其中提供大量的介面用於描述該類的特徵。如:
// 獲取該類類名
String getClassName();
// 是否為介面
boolean isInterface();
boolean isAnnotation();
boolean isAbstract();
// 是否為實現類
boolean isConcrete();
// 是否是final
boolean isFinal();
boolean isIndependent();
boolean hasEnclosingClass();
String getEnclosingClassName();AnnotationMetadata是修飾該類的註解資訊的抽象,它用於描述修飾該類註解的元資訊。包含了修飾的註解所有資訊,包括註解本身的屬性。
// 獲取所有的註解型別
Set<String> getAnnotationTypes();
// 根據名稱獲取註解屬性
Map<String, Object> getAnnotationAttributes(String annotationName);Spring通過提供這套元件,可以非常便捷的訪問類資訊。它底層的原理是依賴ASM位元組碼庫實現。下圖描述了大致原理:
Tips:
Spring中封裝的MetadataReader和MetadataReaderFactory,筆者認為本身定位也是作為工具使用,所以日常應用中開發中,完全可以使用其提供的能力。當然是Spring應用才是最好這樣使用。
Note:
從以上的介紹中,不可忽略的是這裡訪問class資訊,並未涉及到類載入器系統將該類載入至JVM中形成class物件。這個需要重點關注:該類尚未被載入。只是被ASM載入了而已!
同時可以通過以下的例子更深入的瞭解其特性和API:
String className = AnnotatedTargetClass.class.getName();
MetadataReaderFactory metadataReaderFactory = new SimpleMetadataReaderFactory();
MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);
ClassMetadata classMetadata = metadataReader.getClassMetadata();
System.out.println("isConcrete:" + classMetadata.isConcrete());
System.out.println("isAbstract:" + classMetadata.isAbstract());
System.out.println("isFinal:" + classMetadata.isFinal());
System.out.println("isIndependent:" + classMetadata.isIndependent());
System.out.println("isInterface:" + classMetadata.isInterface());
System.out.println("isAnnotation:" + classMetadata.isAnnotation());
AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata();
System.out.println("all annotations type:" + String.join(",",
annotationMetadata.getAnnotationTypes()));
Map<String, Object> annotationAttrs = annotationMetadata
.getAnnotationAttributes(XmlRootElement.class.getName());
Set<Map.Entry<String, Object>> entries = annotationAttrs.entrySet();
for (Map.Entry<String, Object> entry : entries) {
System.out.println("attribute name:" + entry.getKey() + ", attribute name:" + entry.getValue());
}在介紹完訪問類的元資訊後,繼續看下ScannedGenericBeanDefinition和TypeFilter。
首先ScannedGenericBeanDefinition是一種BeanDefinition型別,它是擴充套件GenericBeanDefinition實現,同時基於ASM增加了對AnnotatedBeanDefinition註解暴露介面的支援,即實現了AnnotatedBeanDefinition介面。提供獲取AnnotationMetadata和MethodMetadata的資訊。通過註解形式配置的Bean定義需要轉化為該型別的BeanDefinition。因為它可以提供獲取註解資訊。
TypeFilter是型別過濾器,通過抽象介面:
boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory)
throws IOException;匹配過濾指定的metadataReader。metadataReader本身代表class的訪問器,通過TypeFilter篩選出需要的metadataReader,然後將其轉化為BeanDefinition。
在瞭解一些基礎元件後,便可以深入分析Spring如何篩選出被@Componet系註解修飾的類。
上述程式碼在遍歷每個Resource中,利用isCandidateComponent(metadataReader)篩選指定的metadataReader:
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
// 首先根據排除過濾器進行匹配,然後排除掉metadataReader
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return false;
}
}
// 然後根據包含過濾器篩選出滿足的metadataReader
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return isConditionMatch(metadataReader);
}
}
return false;
}前文在介紹excludeFilters和includeFilters正是被這裡使用。在預設情況下(componet-scan中未做任何filter的配置時),只有includeFilters中包含@Component的AnnotationTypeFilter,這個由前文中介紹的registerDefaultFilters將其註冊。
由於篇幅原因,這裡不在詳述match方法的實現。但是原理就是:
- 首先匹配自身類的metadataReader,即將metadataReader中的註解與AnnotationTypeFilter中的註解進行比較,如果metadataReader中的註解包含了AnnotationTypeFilter的,則認為是匹配;
- 否則再獲取metadataReader的父類的metadataReader,再如上的方式比較;
可以看下其比較方式:
// 獲取所有的註解元資訊
AnnotationMetadata metadata = metadataReader.getAnnotationMetadata();
// 如果註解中包含AnnotationTypeFilter指定的註解
return metadata.hasAnnotation(this.annotationType.getName()) ||
(this.considerMetaAnnotations && metadata.hasMetaAnnotation(this.annotationType.getName()));通過以上的方式可以成功的找到@Component系註解的所有metadataReader,然後利用其構造ScannedGenericBeanDefinition。然後再看下如何篩選BeanDefinition的isCandidateComponent:
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
// 獲取BeanDefintion中的註解元資訊
AnnotationMetadata metadata = beanDefinition.getMetadata();
// 抉擇該類是否為實現和無依賴類,或者該類是抽象類但是有Lookup註解修飾的方法
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}到這裡,關於資源的載入、@Component系註解配置檢測、解析為BeanDefition的過程基本完成,這裡再總結下:
- 迴圈遍歷所有的包路徑
- 將每個包路徑組轉成滿足解析器的搜尋路徑格式
- 根據搜尋路徑載入所有資源
- 遍歷所有資源,將資源轉化成MetadataReader
- 根據MetadataReader和TypeFilter進行匹配,篩選出符合的MetadataReader
- 根據MetadataReader建立ScannedGenericBeanDefinition
再繼續生成BeanName的邏輯:
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
// 如果是註解型BeanDefinition
if (definition instanceof AnnotatedBeanDefinition) {
// 從註解配置中解析BeanName
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
// 如果註解中指定了BeanName,則返回註解中配置的BeanName
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
// 如果註解中沒有配置,則根據Bean的ShortClassName(即簡單的class名字,非全限定名)生成
// 生成時,className的首字母小寫
// Fallback: generate a unique default bean name.
return buildDefaultBeanName(definition, registry);
}然後再繼續看處理公共註解的邏輯AnnotationConfigUtils.processCommonDefinitionAnnotations
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {
// 處理公共註解
processCommonDefinitionAnnotations(abd, abd.getMetadata());
}
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {
// 處理惰性初始化註解,將BeanDefinition設定成Lazy
if (metadata.isAnnotated(Lazy.class.getName())) {
abd.setLazyInit(attributesFor(metadata, Lazy.class).getBoolean("value"));
}
else if (abd.getMetadata() != metadata && abd.getMetadata().isAnnotated(Lazy.class.getName())) {
abd.setLazyInit(attributesFor(abd.getMetadata(), Lazy.class).getBoolean("value"));
}
// 處理Primary註解,將BeanDefinition設定為首選的主要候選者
if (metadata.isAnnotated(Primary.class.getName())) {
abd.setPrimary(true);
}
// 解析DependsOn註解
if (metadata.isAnnotated(DependsOn.class.getName())) {
abd.setDependsOn(attributesFor(metadata, DependsOn.class).getStringArray("value"));
}
// 處理Role和Description註解
if (abd instanceof AbstractBeanDefinition) {
AbstractBeanDefinition absBd = (AbstractBeanDefinition) abd;
if (metadata.isAnnotated(Role.class.getName())) {
absBd.setRole(attributesFor(metadata, Role.class).getNumber("value").intValue());
}
if (metadata.isAnnotated(Description.class.getName())) {
absBd.setDescription(attributesFor(metadata, Description.class).getString("value"));
}
}
}以上公共的註解處理邏輯中關於惰性初始化的尤其需要注意。
對BeanDefinition解析完成後,接下來就是將其註冊到BeanFactory中。但是在註冊之前需要進行檢查該BeanDefinition是否已經存在,防止重複註冊。註冊BeanDefinition的邏輯相信大家應該不陌生了,就是使用BeanDefinition註冊器將BeanDefinition註冊至BeanFactory。
完成了BeanDefinition的註冊,關於@Component系註解的大部分工作就已經完成了。但是還剩下最後的註冊公共的元件步驟,這些公共元件主要用處理特定的註解:
- 註冊處理@Configuration註解的處理器ConfigurationClassPostProcessor,其中有包含處理@Import,@ Configuration,@Bean等邏輯;
- 註冊處理@Autowired和Value註解的處理器AutowiredAnnotationBeanPostProcessor,其中主要處理Bean的註解式自動裝配邏輯;
- 註冊處理@Required註解的處理器RequiredAnnotationBeanPostProcessor;
- 註冊處理@PreDestroy,@PostConstruct,@Resource(JSR-250的註解)這些java自身的註解處理器CommonAnnotationBeanPostProcessor
protected void registerComponents(
XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) {
// 定義複合元件定義物件
Object source = readerContext.extractSource(element);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);
// 將掃描出的BeanDefinition新增到符合元件定義中
for (BeanDefinitionHolder beanDefHolder : beanDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));
}
// 從xml中獲取是否註冊公共註解處理器的配置屬性
// Register annotation config processors, if necessary.
boolean annotationConfig = true;
if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) {
annotationConfig = Boolean.valueOf(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));
}
// 根據配置判斷是否註冊一些公共的處理註解配置處理器
if (annotationConfig) {
// 註冊公共的註解處理器
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source);
// 將公共的註解處理器加入符合元件定義中
for (BeanDefinitionHolder processorDefinition : processorDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));
}
}
// 發起元件註冊事件
readerContext.fireComponentRegistered(compositeDef);
}以上主要是獲取配置,判斷是否註冊公共的註解配置處理器,其中註冊的邏輯由AnnotationConfigUtils.registerAnnotationConfigProcessors工具方法實現。
其中關於ConfigurationClassPostProcessor的註解處理器還是非常重要,但是由於篇幅原因這裡不再詳述。後續可能會不上一篇單獨介紹他。
到這裡,關於@Component系註解的作用原理就已經介紹完成,後續就是Bean的例項化的邏輯,關於該內容請參考之前的文章,這裡不再贅述。
接下來就開始介紹以上註解處理器中的另一個至關重要的角色:AutowiredAnnotationBeanPostProcessor
@Autowired註解配置的作用原理
關於@Autowired的作用相信讀者應該都知道:即註解式自動裝配。類似XML配置一樣,配置物件之間的依賴關係,使用也是非常簡單。但是關於該註解的內部實現原理,很多使用者都知之甚少,本節將對其原理進行深入介紹。
先分析@Autowired註解完成的工作,以及這些工作應該在Spring的哪些階段中完成相應的邏輯。
@Autowired作用在方法或者成員域上,將依賴的Bean注入。比如A依賴B,A類中有B類性的成員,在B成員域上加上@Autowired,Spring將會管理這種依賴,將B的例項注入A的例項中(前提A和B都需要被註冊為Bean)。這個工作需要完成兩件事:
- 解析@Autowired配置
- 尋找依賴的Bean,將依賴的Bean注入
其中解析@Autowired配置屬於解析BeanDefinition階段,尋找依賴的Bean,將依賴的Bean注入屬於在裝配階段。Spring中在解析@Autowired配置,雖然是解析BeanDefinition,但是是在例項化階段之後解析,並非在解析BeanDefinition階段。
關於以上兩部分邏輯由Spring中的AutowiredAnnotationBeanPostProcessor處理器負責,在上節中已經介紹在處理
首先看下其javadocs的部分描述:
{@link org.springframework.beans.factory.config.BeanPostProcessor} implementation
that autowires annotated fields, setter methods and arbitrary config methods.
Such members to be injected are detected through a Java 5 annotation: by default,
Spring's {@link Autowired @Autowired} and {@link Value @Value} annotations. Also supports JSR-330's {@link javax.inject.Inject @Inject} annotation, if available, as a direct alternative to Spring's own {@code @Autowired}.
從docs中可以看出,其是BeanPostProcessor的實現,用於處理在域和setter方法上的@ Autowired註解和@Value註解。同時還支援jsr-330的註解@Inject。
public class AutowiredAnnotationBeanPostProcessor extends InstantiationAwareBeanPostProcessorAdapter
implements MergedBeanDefinitionPostProcessor, PriorityOrdered, BeanFactoryAware {}該類通過同時還實現了MergedBeanDefinitionPostProcessor介面,該介面是對BeanPostProcessor的更進一步抽象,提供對合並BeanDeifnition的回撥處理。其實現該介面,實現對合並BeanDeifnition解析,最終完成對@Autowired和@Value的解析。
通過繼承實現InstantiationAwareBeanPostProcessorAdapter抽象類,以實現InstantiationAwareBeanPostProcessor介面,從而完成對該方法postProcessPropertyValues的實現,在這裡完成對依賴的Bean的尋找和注入裝配工作。InstantiationAwareBeanPostProcessor也是對BeanPostProcessor的更進一步抽象,提供對Bean例項化之前和之後的後置處理回撥,也提供了對裝配階段的後置處理回撥postProcessPropertyValues。
MergedBeanDefinitionPostProcessor在Bean例項化之後,被觸發。InstantiationAwareBeanPostProcessor對裝配階段的後置處理回撥,是在裝配之前觸發,對於詳情可以參考我的另一篇文章Spring原始碼系列 — Bean生命週期。
首先看AutowiredAnnotationBeanPostProcessor的結構
public class AutowiredAnnotationBeanPostProcessor extends InstantiationAwareBeanPostProcessorAdapter
implements MergedBeanDefinitionPostProcessor, PriorityOrdered, BeanFactoryAware {
// 自動注入的註解型別,能夠處理的自動注入註解的型別都存在該集合中
private final Set<Class<? extends Annotation>> autowiredAnnotationTypes =
new LinkedHashSet<Class<? extends Annotation>>(4);
// 硬編碼,註解引數required
private String requiredParameterName = "required";
private boolean requiredParameterValue = true;
// 實現beanFactoryAware介面,准入BeanFactory
private ConfigurableListableBeanFactory beanFactory;
// 自動注入元資訊集合,儲存被自動注入註解修飾的資訊
private final Map<String, InjectionMetadata> injectionMetadataCache =
new ConcurrentHashMap<String, InjectionMetadata>(256);
}其中autowiredAnnotationTypes集合儲存能夠被處理的註解資訊:
public AutowiredAnnotationBeanPostProcessor() {
// 增加對@Autowired註解的支援
this.autowiredAnnotationTypes.add(Autowired.class);
// 增加對@Vaule的註解的支援
this.autowiredAnnotationTypes.add(Value.class);
try {
// 增加對Inject註解的支援
this.autowiredAnnotationTypes.add((Class<? extends Annotation>)
ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));
logger.info("JSR-330 'javax.inject.Inject' annotation found and supported for autowiring");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}然後便是解析@Autowired和@Value配置,將其抽象成InjectionMetadata物件,存入其集合中。InjectionMetadata結構如下:
public class InjectionMetadata {
// 目標型別
private final Class<?> targetClass;
// 被注入元素的集合
private final Collection<InjectedElement> injectedElements;
// 被檢查元素的集合
private volatile Set<InjectedElement> checkedElements;
}該例項中抽象有InjectedElement,它是用來描述單個被注入的資訊,如:
@Autowired
private A a;將被解析成InjectedElement用於描述:
public abstract static class InjectedElement {
// 被註解的成員,Field還是Method
protected final Member member;
// 是否為Field被注入
protected final boolean isField;
// 屬性描述,javabeans中的介面
protected final PropertyDescriptor pd;
}其中有兩個實現被作為AutowiredAnnotationBeanPostProcessor其內部類,AutowiredFieldElement和AutowiredMethodElement。前者代表被注入的域資訊,後者代表被注入的方法資訊。
關於資料結構的示意圖如下:
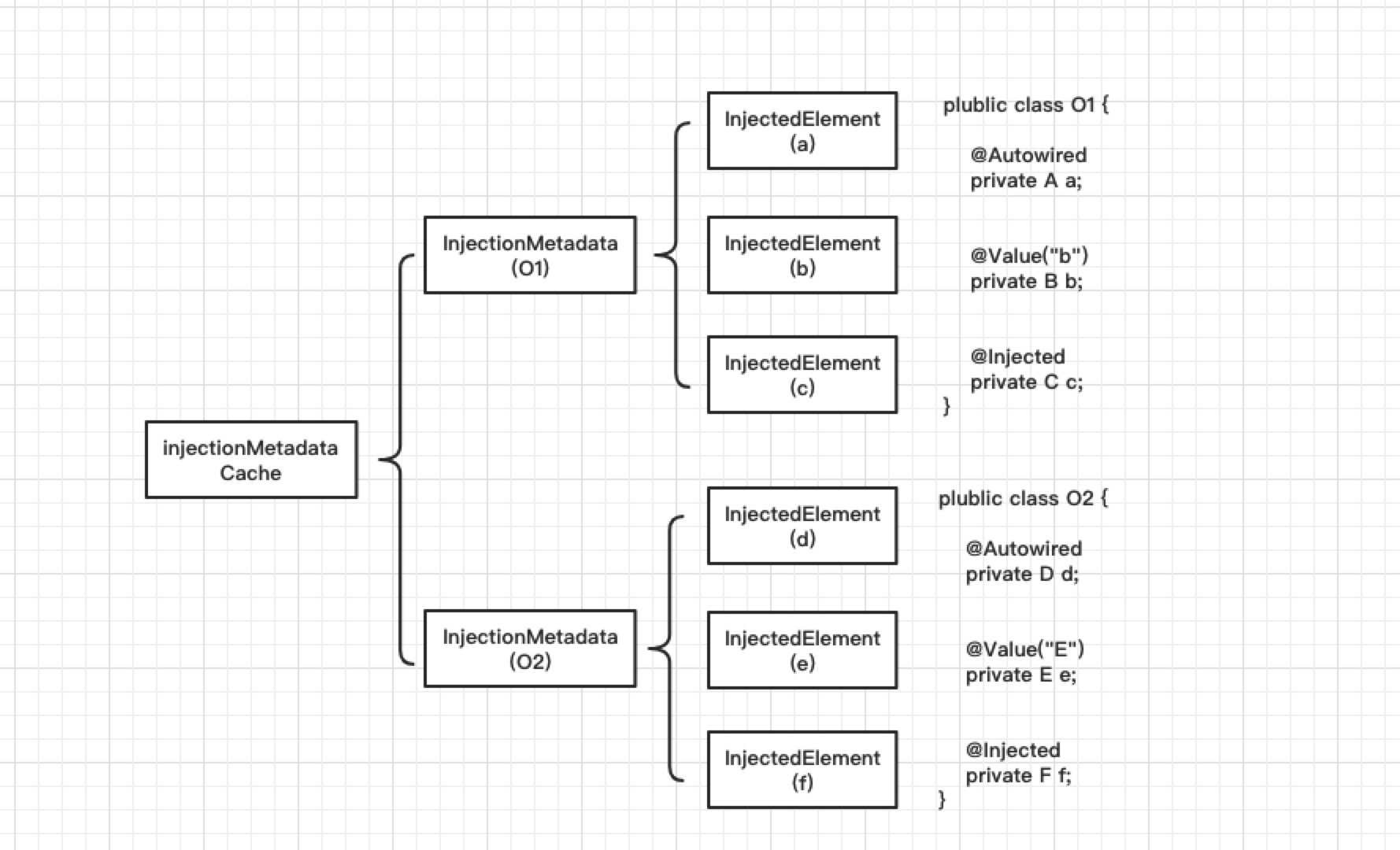
自動注入的註解@Autowired、@Value等最終將會解析成如上的結構,被injectionMetadataCache成員持有。所以AutowiredAnnotationBeanPostProcessor中將會有所有Bean的註解式自動配置元資訊。關於具體實現看以下分析:
// 後置處理合並的BeanDefinition,解析@Autowired和@Value等註解配置
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
// 如果beanType不為空,則查詢解析@Autowired註解配置,將抽象成InjectionMetadata,用其描述注入元資訊
if (beanType != null) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
}這裡的核心邏輯便是findAutowiringMetadata,根據beanType尋找其自動裝配的元配置資訊:
// 因為解析class,查詢解析註解配置資訊是耗效能且這些配置資訊比較固定,所以這裡使用快取,將解析的註解配置資訊快取在
// injectionMetadataCache中
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, PropertyValues pvs) {
// 獲取快取的key,如果存在beanName,則將beanName作為快取key;如果不存在,則將類名作為快取key
// Fall back to class name as cache key, for backwards compatibility with custom callers.
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
// 從快取中獲取註解配置元資訊
// Quick check on the concurrent map first, with minimal locking.
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
// 如果沒有快取或者型別不匹配,則重新獲取
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
// 執行緒同步
synchronized (this.injectionMetadataCache) {
// 使用雙重檢查,再次獲取
metadata = this.injectionMetadataCache.get(cacheKey);
// 如果沒有或者型別不匹配,則重新獲取
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
try {
// 構建自動注入的配置資訊
metadata = buildAutowiringMetadata(clazz);
// 將其快取
this.injectionMetadataCache.put(cacheKey, metadata);
}
catch (NoClassDefFoundError err) {
throw new IllegalStateException("Failed to introspect bean class [" + clazz.getName() +
"] for autowiring metadata: could not find class that it depends on", err);
}
}
}
}
return metadata;
}這個查詢邏輯非常簡單,就是從快取中獲取,如果沒有則重新構建自動注入的配置資訊。但是這裡的設計思想卻是非常經典。
Notes:
快取的設計思想在日常應用的開發中被大量使用,一般模式都遵循先從快取獲取,如果快取沒有,則從資料來源獲取,再填充快取。
對於配置資訊的具體解析構建則在buildAutowiringMetadata中實現:
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
// 建立注入配置元素集合
LinkedList<InjectionMetadata.InjectedElement> elements = new LinkedList<InjectionMetadata.InjectedElement>();
// 將當前需要解析的類作為目標類,即將解析
Class<?> targetClass = clazz;
// 迴圈遍歷解析當前類以及所有的父類
do {
// 建立解析類所對應的自動注入配置的集合
final LinkedList<InjectionMetadata.InjectedElement> currElements =
new LinkedList<InjectionMetadata.InjectedElement>();
// 解析自動注入的域配置
ReflectionUtils.doWithLocalFields(targetClass, new ReflectionUtils.FieldCallback() {
@Override
public void doWith(Field field) throws IllegalArgumentException, IllegalAccessException {
AnnotationAttributes ann = findAutowiredAnnotation(field);
if (ann != null) {
if (Modifier.isStatic(field.getModifiers())) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation is not supported on static fields: " + field);
}
return;
}
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field, required));
}
}
});
// 解析自動注入的方法的配置
ReflectionUtils.doWithLocalMethods(targetClass, new ReflectionUtils.MethodCallback() {
@Override
public void doWith(Method method) throws IllegalArgumentException, IllegalAccessException {
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
AnnotationAttributes ann = findAutowiredAnnotation(bridgedMethod);
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
if (Modifier.isStatic(method.getModifiers())) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation is not supported on static methods: " + method);
}
return;
}
if (method.getParameterTypes().length == 0) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation should only be used on methods with parameters: " +
method);
}
}
boolean required = determineRequiredStatus(ann);
PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);
currElements.add(new AutowiredMethodElement(method, required, pd));
}
}
});
// 加入總個集合中
elements.addAll(0, currElements);
// 獲取父類,再次解析父類
targetClass = targetClass.getSuperclass();
}
// 當類為空,或者是Object最頂層類時跳出迴圈
while (targetClass != null && targetClass != Object.class);
// 根據自動注入配置集合,構建自動注入配置物件
return new InjectionMetadata(clazz, elements);
}以上的邏輯也是非常簡單,就利用反射庫提供的API獲取class的所有Field和Method,然後解析其被標註的註解是否匹配自動注入註解型別,如果匹配則將其解析為AutowiredFieldElement和AutowiredMethodElement。
可以看其使用反射API的具體細節:
public static void doWithLocalFields(Class<?> clazz, FieldCallback fc) {
// 獲取class的所有域,迴圈遍歷處理其上註解
for (Field field : getDeclaredFields(clazz)) {
try {
fc.doWith(field);
}
catch (IllegalAccessException ex) {
throw new IllegalStateException("Not allowed to access field '" + field.getName() + "': " + ex);
}
}
}
public static void doWithLocalMethods(Class<?> clazz, MethodCallback mc) {
// 獲取class中所有的方法,迴圈遍歷處理其上註解
Method[] methods = getDeclaredMethods(clazz);
for (Method method : methods) {
try {
mc.doWith(method);
}
catch (IllegalAccessException ex) {
throw new IllegalStateException("Not allowed to access method '" + method.getName() + "': " + ex);
}
}
}當然這裡使用了回撥的方式非常巧妙,使其更具有擴充套件性。再以具體的尋找域上的註解的例項詳解:
private AnnotationAttributes findAutowiredAnnotation(AccessibleObject ao) {
// 該ao上的註解不為空
if (ao.getAnnotations().length > 0) { // autowiring annotations have to be local
// 遍歷自動處理註解型別
for (Class<? extends Annotation> type : this.autowiredAnnotationTypes) {
// 獲取該ao上的自動處理註解(@Autowired, @Value, @Injected)
AnnotationAttributes attributes = AnnotatedElementUtils.getMergedAnnotationAttributes(ao, type);
// 如果註解屬性不為空,則返回
if (attributes != null) {
return attributes;
}
}
}
return null;
}到這裡,讀者應該明白Spring中如何解析自動注入的註解式配置了。接下來便再從裝配的角度分析其原理:
@Override
public PropertyValues postProcessPropertyValues(
PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeanCreationException {
// 尋找自動裝配元配置,這個邏輯前面已經介紹
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
// 進行注入處理
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}以上邏輯非常簡單,根據自動裝入元配置進行注入:
public void inject(Object target, String beanName, PropertyValues pvs) throws Throwable {
// 獲取需要注入的元素InjectedElement的集合
Collection<InjectedElement> elementsToIterate =
(this.checkedElements != null ? this.checkedElements : this.injectedElements);
// 進行迭代注入
if (!elementsToIterate.isEmpty()) {
for (InjectedElement element : elementsToIterate) {
if (logger.isDebugEnabled()) {
logger.debug("Processing injected element of bean '" + beanName + "': " + element);
}
element.inject(target, beanName, pvs);
}
}
}關於使用InjectedElement注入的邏輯由其實現類實現,這裡主要分析下AutowiredFieldElement根據域注入的實現方式:
@Override
protected void inject(Object bean, String beanName, PropertyValues pvs) throws Throwable {
// 是域方式注入,將Member介面強轉成Field型別
Field field = (Field) this.member;
Object value;
// 如果引數有被快取,則從快取中解析
if (this.cached) {
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
// 否則重新解析依賴
else {
// 將field重新包裝成依賴描述
DependencyDescriptor desc = new DependencyDescriptor(field, this.required);
// 設定包含這個依賴的bean的class
desc.setContainingClass(bean.getClass());
Set<String> autowiredBeanNames = new LinkedHashSet<String>(1);
// 獲取轉換器
TypeConverter typeConverter = beanFactory.getTypeConverter();
try {
// 獲取依賴的值,這裡使用了BeanFactory提供方法,這個方法之前的Bean建立中已經介紹,這裡不再贅述
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName, new InjectionPoint(field), ex);
}
// 同步,然後快取value值,並修改快取表示為true
synchronized (this) {
if (!this.cached) {
if (value != null || this.required) {
this.cachedFieldValue = desc;
registerDependentBeans(beanName, autowiredBeanNames);
if (autowiredBeanNames.size() == 1) {
String autowiredBeanName = autowiredBeanNames.iterator().next();
if (beanFactory.containsBean(autowiredBeanName) &&
beanFactory.isTypeMatch(autowiredBeanName, field.getType())) {
this.cachedFieldValue = new ShortcutDependencyDescriptor(
desc, autowiredBeanName, field.getType());
}
}
}
else {
this.cachedFieldValue = null;
}
this.cached = true;
}
}
}
// 使用反射方式將值注入
if (value != null) {
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}其中BeanFactory的resolveDependency解析依賴中使用到了QualifierAnnotationAutowireCandidateResolver解析器,該解析器實現瞭解析Field中的@Value註解獲取值,如果value值不為空則當做依賴返回。關於這些細節由於篇幅原因這裡不再詳述。
總結
本文主要針對Spring中的註解式配置@Component系和@Autowired的作用原理從原始碼實現的角度進行深層次的剖析。對於這兩項基本功能,Spring都是以外掛的形式提供擴充套件的,主要基於Spring上下文核心提供的執行解析BeanDefinitionParser能力和Bean的例項化裝配能力。
其中需要重點掌握的是ComponentScanBeanDefinitionParser和AutowiredAnnotationBeanPostProcessor兩大元件。它們負責完成了本文的提到的註解式配置。