
【自然語言處理】淺談語料庫
文章目錄
【自然語言處理】淺談語料庫
前言
本篇博文重在瞭解語料庫以及獲取相關語料庫的資源介紹。
一、淺談語料庫
1、語料和語料庫
語料通常指在統計自然語言處理中實際上不可能觀測到大規模的語言例項。所以人們簡單地用文字作為替代,並把文字中的上下文關係作為現實世界中語言的上下文關係的替代品。
語料庫一詞在語言學上意指大量的文字,通常經過整理,具有既定格式與標記。其具備三個顯著的特點:
⊚ 語料庫中存放的是在語言的實際使用中真實出現過的語言材料。
⊚ 語料庫以電子計算機為載體承載語言知識的基礎資源,但並不等於語言知識。
⊚ 真實語料需要經過加工(分析和處理),才能成為有用的資源。
2、語料庫語言學
語料庫語言學的研究範疇:主要研究機器可讀自然語言文字的採集、儲存、檢索、統計、語法標註、句法語義分析,以及具有上述功能的語料庫在語言教學、語言定量分析、詞彙研究、詞語搭配研究、詞典編制、語法研究、語言文化研究、法律語言研究、作品風格分析、自然語言理解、機器翻譯等方面的應用。
3、 建議語料庫的意義
語料庫是為一個或者多個應用目標而專門收集的,有一定結構的、有代表的、可被計算機程式檢索的、具有一定規模的語料集合。本質上講,語料庫實際上是通過對自然語言運用的隨機抽樣,以一定大小的語言樣本來代表某一研究中所確定的語言運用的總體。
ok!!! 到了這裡對於語料庫,語料是個什麼鬼也大體有了瞭解。接下來就更深入的瞭解關於語料庫的知識吧!!!
二、語料庫深入瞭解
1、語料庫劃分與種類
馮志偉教授語料庫劃分比較有影響力且在學術上認可度比較高:
⊚ 按語料選取的時間劃分,可分為歷時語料庫(diachronic corpus)和共時語料庫(syn-chronic corpus)。
⊚ 按語料的加工深度劃分,可分為標註語料庫(annotated corpus)和非標註語料庫(non- annotated corpus)。
⊚ 按語料庫的結構劃分,可分為平衡結構語料庫(balance structure corpus)和自然隨機結構的語料庫(random structure corpus)。
⊚ 按語料庫的用途劃分,可分為通用語料庫(general corpus)和專用語料庫(specialized corpus)。
⊚ 按語料庫的表達形式劃分,可分為口語語料庫(spoken corpus)和文字語料庫(textcorpus)。
⊚ 按語料庫中語料的語種劃分,可分為單語種語料庫(monolingual corpora)和多語種語料庫(multilingual corpora)。多語種語料庫又可以再分為比較語料庫(comparable corpora)和平行語料庫(parallel corpora)。比較語料庫的目的側重於特定語言現象的對比,而平行語料庫的目的側重於獲取對應的翻譯例項。
⊚ 按語料庫的動態更新程度劃分,可分為參考語料庫(reference corpus)和監控語料庫(monitor corpus)。參考語料庫原則上不做動態更新,而監控語料庫則需要不斷地進行動態更新。
2、語料庫構建原則
語料庫應該具有代表性、結構性、平衡性、規模性、元資料,各個原則具體介紹如下:
⊚ 代表性:在應用領域中,不是根據量而劃分是否是語料庫,而是在一定的抽樣框架範圍內採集而來的,並且能在特定的抽樣框架內做到代表性和普遍性。
⊚ 結構性:有目的地收集語料的集合,必須以電子形式存在,計算機可讀的語料集合結構性體現在語料庫中語料記錄的程式碼、元資料項、資料型別、資料寬度、取值範圍、完整性約束。
⊚平衡性:主要體現在平緩因子——學科、年代、文體、地域、登載語料的媒體、使用者的年齡、性別、文化背景、閱歷、預料用途(私信/廣告等),根據實際情況選擇其中一個或者幾個重要的指標作為平衡因子,最常見的平衡因子有學科、年代、文體、地域等。
⊚ 規模性:大規模的語料對語言研究特別是對自然語言研究處理很有用,但是隨著語料庫的增大,垃圾語料越來越多,語料達到一定規模以後,語料庫功能不能隨之增長,語料庫規模應根據實際情況而定。
⊚ 元資料:元資料對於研究語料庫有著重要的意義,我們可以通過元資料瞭解語料的時間、地域、作者、文字資訊等;構建不同的子語料庫;對不同的子語料對比;記錄語料知識版權、加工資訊、管理資訊等。
注意:漢語詞與詞之間沒有空隙,不便於計算機處理,一般需要進行切詞和詞性標註。
3、語料標註的優缺點
⊚ 優點:研究方便。可重用、功能多樣、分析清晰。
⊚ 缺點:語料不客觀(手工標註準確率高而一致性差,自動或者半自動標註一致性高而準確率差)、標註不一致、準確率低。
三、自然語言處理工具包:NLTK
1、 瞭解NLTK
NLTK(Natural language Toolkit):自然語言工具包,Python 程式語言實現的統計自然語言處理工具。它是由賓夕法尼亞大學計算機和資訊科學的史蒂芬·伯德和愛德華·洛珀編寫的。NLTK 支援NLP 研究和教學相關的領域,其收集的大量公開資料集、模型上提供了全面易用的介面,涵蓋了分詞、詞性標註(Part-of-Speech tag,POS-tag)、命名實體識別(NamedEntity Recognition,NER)、句法分析(Syntactic Parse) 等各項NLP 領域的功能。廣泛應用在經驗語言學、認知科學、人工智慧、資訊檢索和機器學習。
2、 獲取NLTK

執行exe 檔案,會自動匹配到Python 安裝路徑,如果沒有找到路徑則說明NLTK 版本不正確,去官網選擇正確版本號下載.
獲取NLTK連結:https://pypi.org/project/nltk/3.2.1/#files
說明:NLTK 核心包主要包括如下:
⊚ NLTK-Data:分析和處理語言的語料庫。
⊚ NumPy:科學計算庫。
⊚ Matplotlib:資料視覺化2D 繪相簿。
⊚ NetworkX:儲存和操作由節點和邊組成的網路結構函式庫。
3、 Standford NLP 簡介
Stanford NLP:由斯坦福大學的NLP 小組開源的Java 實現的NLP 工具包,同樣對NLP領域的各個問題提供瞭解決辦法。斯坦福大學的NLP 小組是世界知名的研究小組,能將NLTK 和Stanford NLP 兩個工具包結合起來使用,對於自然語言開發者再好不過了。2004 年Steve Bird 在NLTK 中加上了對Stanford NLP 工具包的支援,通過呼叫外部的jar 檔案來使用Stanford NLP 工具包的功能,這樣一來就變得更為方便好用。NLTK 提供的Stanford NLP 中的以下幾個功能。
⊚ 中英文分詞:StanfordTokenizer。
⊚ 中英文詞性標註:StanfordPOSTagger。
⊚ 中英文命名實體識別:StanfordNERTagger。
⊚ 中英文句法分析:StanfordParser。
⊚ 中英文依存句法分析:StanfordDependencyParser。
4、Standford NLP必要工具包說明
⊚ 分詞依賴:stanford-segmenter.jar、slf4j-api.jar、data 資料夾相關子檔案。
⊚ 命名實體識別依賴:classifiers、stanford-ner.jar。
⊚ 詞性標註依賴:models、stanford-postagger.jar。
⊚ 句法分析依賴:stanford-parser.jar、stanford-parser-3.6.0-models.jar、classifiers。
⊚ 依存語法分析依賴:stanford-parser.jar、stanford-parser-3.6.0-models.jar、classifiers。壓縮包下載和原始碼分析
⊚ 分詞壓縮包StanfordSegmenter 和StanfordTokenizer:下載stanford-segmenter-2015-12-09.zip(https://pan. baidu.com/s/1kVc20ib),解壓獲取目錄中的stanford-segmenter-3.6.0.jar複製為stanford-segmenter.jar 和slf4j-api.jar。
⊚ 詞性標註壓縮包:下載stanford-postagger-full-2015-12-09.zip (https://pan.baidu.com/s/1hrVMSE4),解壓獲取stanford-postagger.jar。
⊚ 命名實體識別壓縮包:下載stanford-ner-2015-12-09.zip (https://pan.baidu.com/s/
1skOJb5r),解壓獲取stanford-ner.jar 和classifiers 檔案。
⊚ 句法分析、句法依存分析:下載stanford-parser-full-2015-12-09.zip(http://pan.baidu.com/s/1nv6Q2bZ),解壓獲取stanford-parser.jar 和stanford-parser-3.6.0-models.jar
四、獲取語料庫
1、國內外著名語料庫
⊚ 點通多語言語音語料庫:
⊚ 賓州大學語料庫: https://www.ldc.upenn.edu/
⊚ Wikipedia XML 語料庫:http://www-connex.lip6.fr/~denoyer/wikipediaXML/
⊚ 中英雙語知識本體詞網:http://bow.ling.sinica.edu.tw/ 結合詞網、知識本體與領域標記的詞彙知識庫。
2、英文語料庫
⊚ 古滕堡語料庫:http://www.gutenberg.org/
⊚ 語料庫線上: http://www.aihanyu.org/cncorpus/index.aspx#P0
3、中文語料庫
1. 搜狗實驗室新聞| 網際網路資料: http://www.sogou.com/labs/
2. 北京大學語言研究中心:http://ccl.pku.edu.cn/term.asp
3. 計算機語言研究所:
4. 資料堂: http://www.datatang.com/
5. 中央研究院平衡語料庫(https://www.sinica.edu.tw/SinicaCorpus):專門針對語言分析而設計的,每個文句都依詞斷開並標示詞類。語料的蒐集也儘量做到現代漢語分配在不同的主題和語式上,是現代漢語無窮多的語句中一個代表性的樣本。現有語料庫主要針對語言分析而設計,由中央研究院資訊所、語言所詞庫小組完成,內含有簡介、使用說明,現行的語料庫是4.0 版本。
6. LIVAC 漢語共時語料庫:http://www.livac.org/index.php?lang=tc
7. 蘭開斯特大學漢語平衡語料庫: http://www.lancaster.ac.uk/fass/projects/corpus/
8. 蘭開斯特——洛杉磯漢語口語語料庫 :http://www.lancaster.ac.uk/fass/projects/corpus/
9. 語料庫語言學線上:https://www.corpus4u.org/
10.北京森林工作室漢語句義結構標註語料庫:http://www.isclab.org.cn/csa/bfs-ctc.htm
11.國家語委現代漢語語料庫(http://corpus.zhonghuayuwen.org/index.aspx)
現代漢語通用平衡語料庫現在重新開放網路查詢了。重開後的線上檢索速度更快,功能更強,同時提供檢索結果下載。現代漢語語料庫線上提供免費檢索的語料約2000 萬字,為分詞和詞性標註語料。
12.古代漢語語料庫(http://corpus.zhonghuayuwen.org/):網站現在增加了一億字的古代
漢語生語料,研究古代漢語的也可以去查詢和下載。網站同時還提供了分詞、詞性標
注軟體,詞頻統計、字頻統計軟體。基於國家語委語料庫的字頻詞頻統計結果和釋出
的詞表等進行建庫,以供學習研究語言文字的同學和老師使用。
13.《人民日報》標註語料庫(https://blog.csdn.net/eaglet/article/details/1778995):《人民日報》標註語料庫中一半的語料(1998 年上半年)共1300 萬字,已經通過《人民日報》新聞資訊中心公開並提供許可使用權。其中一個月的語料(1998 年1 月)近200 萬字在網際網路上公佈,可自由下載。
14. 古漢語語料庫(https://www.sinica.edu.tw/ch):古漢語語料庫包含以下五個語料庫—— 上古漢語、中古漢語(含大藏經)、近代漢語、出土文獻、其他。部分資料取自史語所漢籍全文資料庫,故兩者間內容略有重疊。此語料庫之出土文獻語料庫,全部取自史語所漢簡小組所製作的資料庫。
15. 近代漢語標記語料庫(https://www.sinica.edu.tw/Early_Mandarin):為應對漢語史研究需
求而建構的語料庫。目前語料庫所蒐集的語料已涵蓋上古漢語(先秦至西漢)、中古漢語(東漢魏晉南北朝)、近代漢語(唐五代以後)大部分的重要語料,並陸續開放使用;在標記語料庫方面,上古漢語及近代漢語都已有部分語料完成標註的工作,並視結果逐步提供上線檢索。
16. 樹圖資料庫(http://treebank.sinica.edu.tw/)
17.搜文解字(http://words.sinica.edu.tw/):包含「搜詞尋字」、「文學之美」、「遊戲解惑」、「古文字的世界」四個單元,可由部件、部首、字、音、詞互查,並可查詢在四書、老、莊、唐詩中的出處,以及直接連結到出處並閱讀原文。
18.文國尋寶記(https://www.sinica.edu.tw/wen):在搜文解字的基礎之上,以華語文學習者
為物件,進一步將字、詞、音的檢索功能與國編、華康、南一等三種版本的國小國語課本結合。與唐詩三百首、宋詞三百首、紅樓夢、水滸傳等文學典籍結合,提供網路上國語文學習的素材。
19. 漢籍電子文獻(https://www.sinica.edu.tw/ch):包含整部25 史整部阮刻13經、超過2000 萬字的臺灣史料、1000 萬字的大正藏及其他典籍。
20. 中國傳媒大學文字語料庫檢索系統(http://ling.cuc.edu.cn/RawPub/)
21. 線上分詞標註系統(http://ling.cuc.edu.cn/cucseg/)
22. 新詞語研究資源庫(http://ling.cuc.edu.cn/newword/)
23. 哈工大資訊檢索研究室對外共享語料庫資源 :http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm
該語料庫為漢英雙語語料庫,10 萬對齊雙語句對,文字書件格式,同義詞詞林擴充套件版,77343 條詞語,秉承《同義詞詞林》的編撰風格。同時採用五級編碼體系,多文件自動文摘語料庫,40 個主題,文字書件格式,同一主題下是同一事件的不同報道。漢語依存樹庫,不帶關係5 萬句,帶關係1 萬句;LTML 化,分詞、詞性、句法部分人工標註,可以圖形化檢視,問答系統問題集,6264 句;已標註問題型別,LTML 化,分詞、詞性、句法、詞義、淺層語義等程式處理得到,單文件自動文摘語料庫共211 篇。
24. 清華大學漢語均衡語料庫THACorpus。
25. 中國科學院計算技術研究所,跨語言語料庫目前的雙語句對資料庫中有約180000 對已對齊的中英文句子。本資料庫支援簡單的中英文查詢服務。查詢結果包括句對編號、中文句子、英文句子、句對來源等。
4、獲取網路資源
A: 如下所示獲取的是傷寒雜病論(線上獲取)
程式碼如下所示
"""
author:jjk
datetime:2018/11/4
coding:utf-8
project name:Pycharm_workstation
Program function: 網路資料獲取
"""
from __future__ import division
import nltk,re,pprint
from urllib.request import urlopen # 匯入請求連結
import time
start_time = time.time()
url = r'http://www.gutenberg.org/files/24272/24272-0.txt'# 請求連結
raw = urlopen(url).read()# 開啟,讀取
raw = raw.decode('utf-8')# 設定編碼
print(len(raw))# 輸出字元長度
print(raw[2000:2500])
stop_time = time.time()
time_sum = stop_time-start_time
print("一共耗用時間:",time_sum)
結果

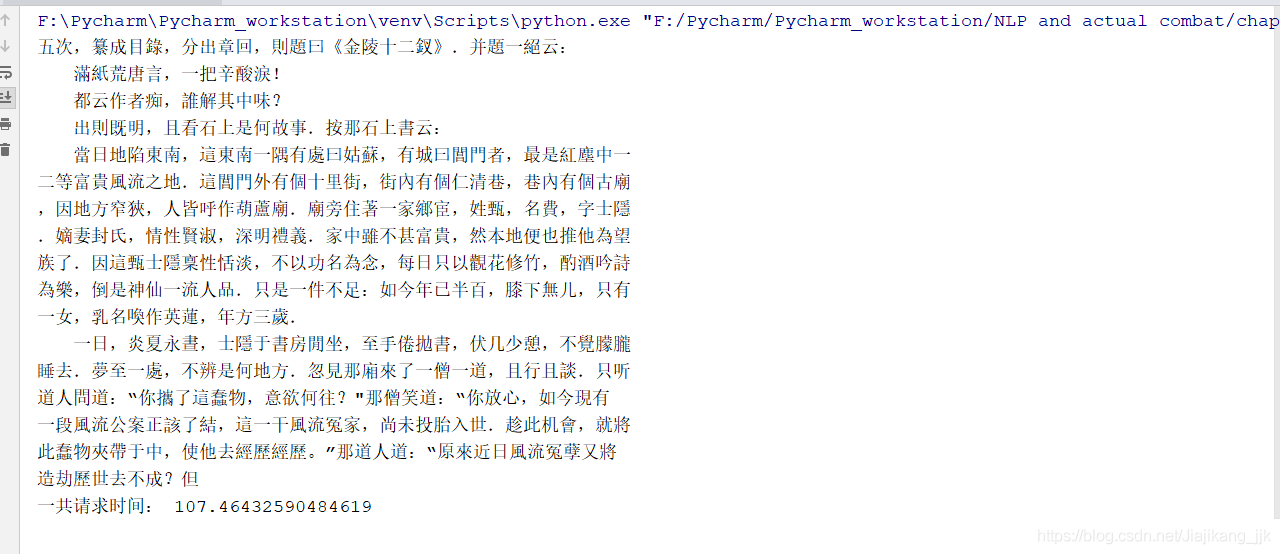
B:線上獲取處理HTML文字(紅樓夢)
程式碼如下所示:
"""
author:jjk
datetime:2018/11/4
coding:utf-8
project name:Pycharm_workstation
Program function: 獲取處理紅樓夢
"""
import re,nltk
from urllib.request import urlopen
import time
start_time = time.time()# 開始時間
url = 'http://www.gutenberg.org/cache/epub/24264/pg24264-images.html'# 請求連結
html = urlopen(url).read()# 開啟,讀取
html = html.decode('utf-8')
print(html[5000:5500])# 獲取5000-5500之間的文字
stop_time = time.time()# 最後時間
time_sum = stop_time-start_time# 一共耗時
print("一共請求時間:",time_sum)
結果
5、NLTK 獲取語料庫
A:古藤保語料庫
"""
author:jjk
datetime:2018/11/4
coding:utf-8
project name:Pycharm_workstation
Program function: 獲取古藤保語料庫
"""
from nltk import data
data.path.append(r"F:\Anaconda\Anaconda_install\nltk_data") # 這裡的路徑需要換成自己資料檔案下載的路徑
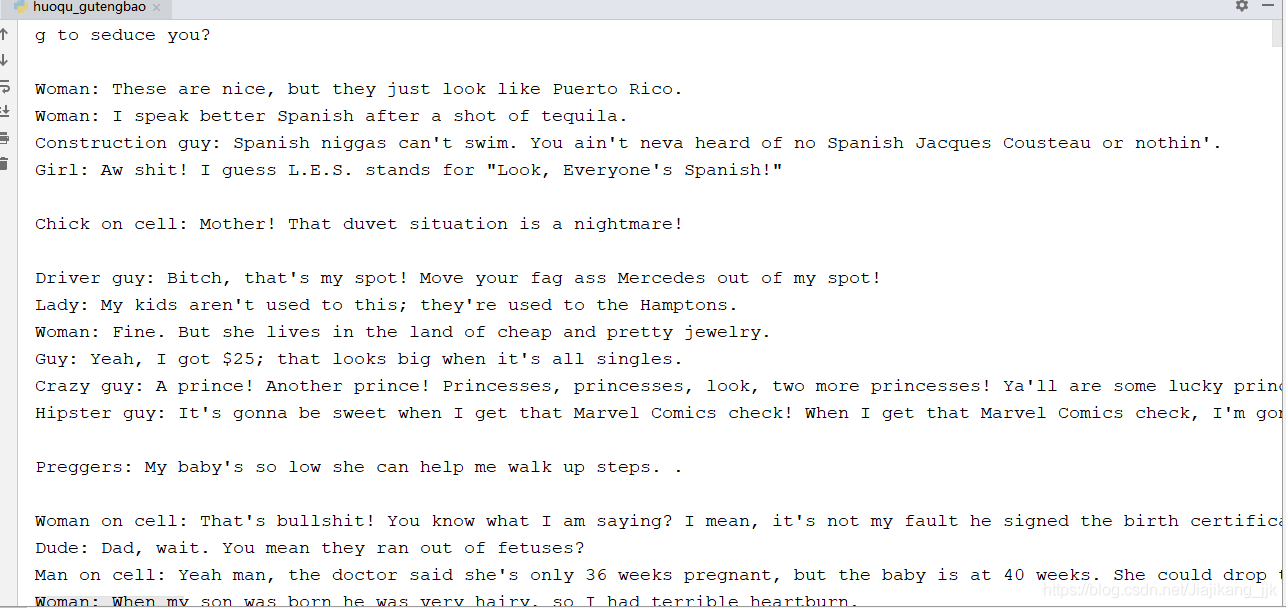
from nltk.corpus import gutenberg
print(gutenberg.fileids())
from nltk.corpus import webtext# 導包
#for fileid in webtext.fileids():# 遍歷
# print(fileid,webtext.raw(fileid))
部分結果截圖

B:網路和聊天文字
"""
author:jjk
datetime:2018/11/4
coding:utf-8
project name:Pycharm_workstation
Program function: 獲取古藤保語料庫
"""
from nltk import data
data.path.append(r"F:\Anaconda\Anaconda_install\nltk_data") # 這裡的路徑需要換成自己資料檔案下載的路徑
from nltk.corpus import gutenberg
# print(gutenberg.fileids())
from nltk.corpus import webtext# 導包
for fileid in webtext.fileids():# 遍歷
print(fileid,webtext.raw(fileid))
部分結果截圖
C:布朗語料庫
比較文體中情態動詞的用法
"""
author:jjk
datetime:2018/11/4
coding:utf-8
project name:Pycharm_workstation
Program function: 布朗語料庫
"""
# 檢視語料資訊
from nltk import data
data.path.append(r"F:\Anaconda\Anaconda_install\nltk_data")
import nltk
from nltk.corpus import brown
#brown.categories()
new_texts = brown.words(categories='news')
fdist = nltk.FreqDist([w.lower() for w in new_texts])
modals = ['can','could','may','might','must','will']
for m in modals:
print(m + ':',fdist[m])
結果

D:路透社語料庫
程式碼
"""
author:jjk
datetime:2018/11/5
coding:utf-8
project name:Pycharm_workstation
Program function: 路透社語料庫
"""
from nltk import data# 導包資料
data.path.append(r"F:\Anaconda\Anaconda_install\nltk_data")# 路徑
from nltk.corpus import reuters
print(reuters.fileids()[:50]) #前50個測試文件
print(reuters.categories()[:100])# 檢視前100個類別
print(reuters.categories('training/9865'))# 檢視某個編號的語料下的類別尺寸
print(reuters.categories(['training/9865','training/9880']))# 檢視某幾個聯合編號語料下的類別尺寸
print(reuters.fileids('barley'))# 檢視哪些編號的檔案屬於指定的類別
結果(部分截圖)

E:就職演說語料庫
程式碼
"""
author:jjk
datetime:2018/11/5
coding:utf-8
project name:Pycharm_workstation
Program function:就職演說語料庫
"""
from nltk import data
data.path.append(r"F:\Anaconda\Anaconda_install\nltk_data")
# 檢視語料資訊
from nltk.corpus import inaugural
print(len(inaugural.fileids()))# 長度
print(inaugural.fileids())# 56個txt
print([fileid[:4] for fileid in inaugural.fileids()])# 檢視就職演說的年份
結果

好吧,,,到了這裡語料庫相關的知識就說到這裡吧。小夥伴們看到這裡還望給博主多多給一些意見和建議。