
【自然語言處理】--視覺問答(Visual Question Answering,VQA)從初始到應用
阿新 • • 發佈:2019-02-13
一、前述
視覺問答(Visual Question Answering,VQA),是一種涉及計算機視覺和自然語言處理的學習任務。這一任務的定義如下: A VQA system takes as input an image and a free-form, open-ended, natural-language question about the image and produces a natural-language answer as the output[1]。 翻譯為中文:一個VQA系統以一張圖片和一個關於這張圖片形式自由、開放式的自然語言問題作為輸入,以生成一條自然語言答案作為輸出。簡單來說,VQA就是給定的圖片進行問答。
VQA系統需要將圖片和問題作為輸入,結合這兩部分資訊,產生一條人類語言作為輸出。針對一張特定的圖片,如果想要機器以自然語言來回答關於該圖片的某一個特定問題,我們需要讓機器對圖片的內容、問題的含義和意圖以及相關的常識有一定的理解。VQA涉及到多方面的AI技術(圖1):細粒度識別(這位女士是白種人嗎?)、 物體識別(圖中有幾個香蕉?)、行為識別(這位女士在哭嗎?)和對問題所包含文字的理解(NLP)。綜上所述,VQA是一項涉及了計算機視覺(CV)和自然語言處理(NLP)兩大領域的學習任務。它的主要目標就是讓計算機根據輸入的圖片和問題輸出一個符合自然語言規則且內容合理的答案。
二、具體步驟
2.1 第一步,生成答案
2.2 第二步,處理輸⼊源資料
2.2.1 處理輸⼊源資料:圖⽚
卷積CNN結合VGG-16模型
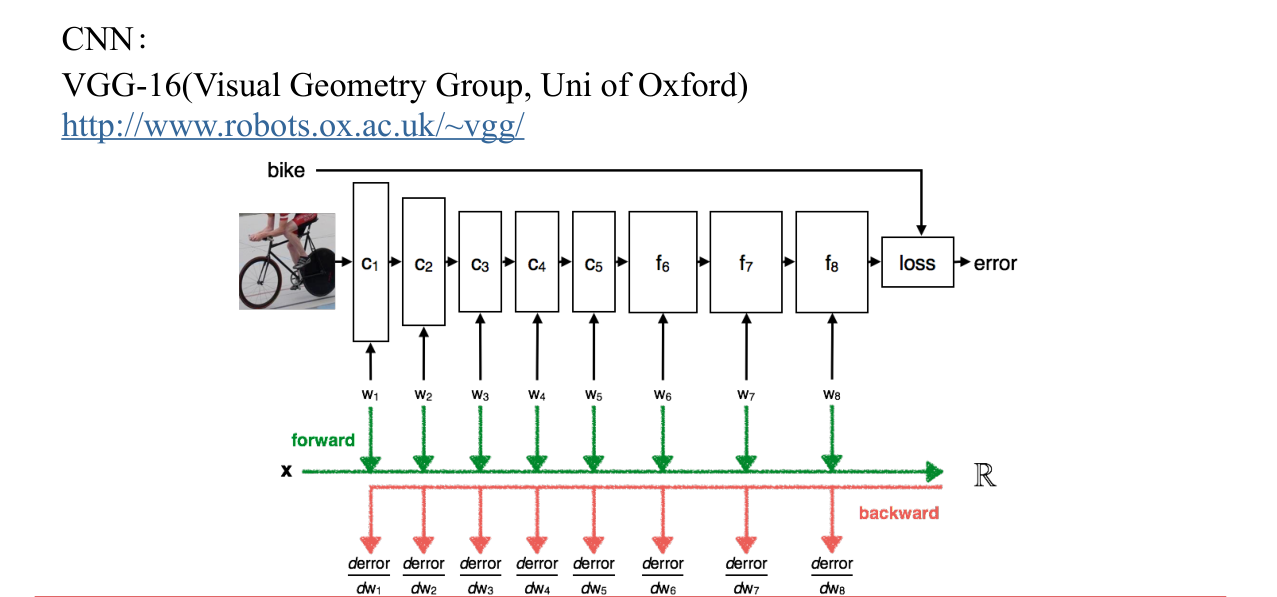
VGG-16的標準構造 (keras)
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='
2.2.2 處理輸⼊源資料:⽂字
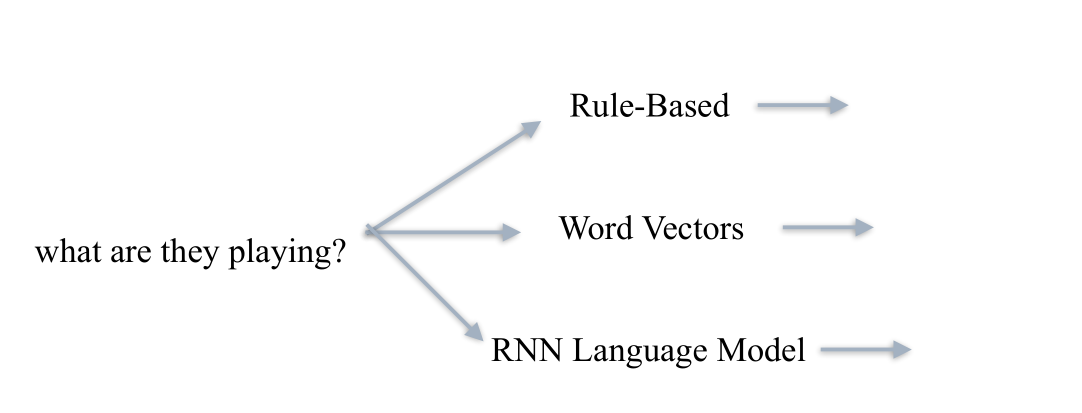
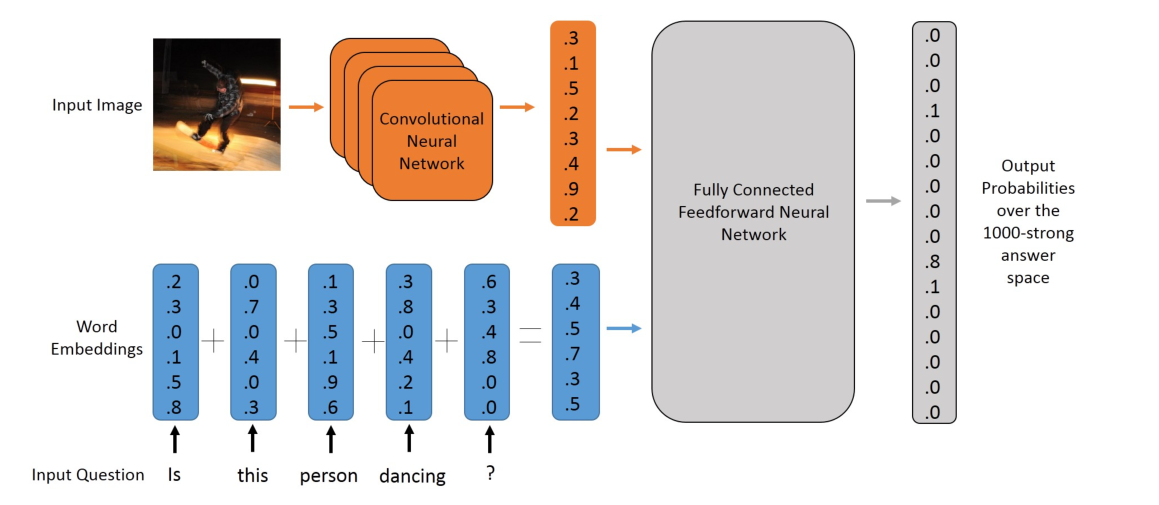
2.3 第三步, 選取VQA模型-MLP
2.3.1 選取VQA模型-MLP
2.3.2 選取VQA模型-LSTM
