
g2o學習
寫在前面
跟著g2o的slam2d_tutorial進行了學習,發現自己對於頂點和邊的理解還是不太夠,覺得有必要把頂點和邊的一些東西再給總結一下,主要參考的就是如下網站:
http://docs.ros.org/fuerte/api/re_vision/html/namespaceg2o.html
這個網站裡面有較為全面的g2o的類以及函式的講解,很方便。
g2o的頂點(Vertex)
首先我們來看一下頂點的繼承關係: 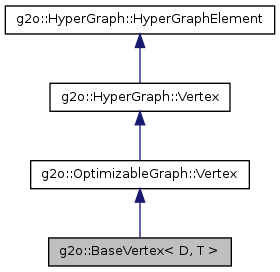
可以看到比較“成熟”的型別就是BaseVertex了,由於我們一般在派生的時候就是繼承自這個類的,下面主要是對這個類進行分析,其中個人認為還是有很多東西要注意的。
g2o::BaseVertex< D, T >
int D, typename T
首先記錄一下定義模板的兩個引數D和T,兩個型別分別是int和typename的型別,D表示的是維度,g2o原始碼裡面是這個註釋的
static const int Dimension = D; ///< dimension of the estimate (minimal) in the manifold space- 1
可以看到這個D並非是頂點(更確切的說是狀態變數)的維度,而是其在流形空間(manifold)的最小表示,這裡一定要區別開;之後是T,原始碼裡面也給出了T的作用
typedef T EstimateType;
EstimateType _estimate; - 1
- 2
可以看到,這裡T就是頂點(狀態變數)的型別。
在頂點的繼承中,這兩個引數是直接面向我們的,所以務必要定義妥當。
_hessian矩陣和_b向量
看到這兩個名字就感覺很激動,畢竟增量方程美名遠揚,而其中很重要的就是H和b兩個引數,這裡的_hessian和_b是增量方程中H和b的一部分,更確切的說是對應於該頂點的部分,下面簡單的說一下這兩個引數的作用。
_hessian矩陣
它的型別是Eigen中的Map型別,也就是這個引數只是一個對映,把一塊記憶體區域對映為Eigen中的資料型別,具體這裡就不贅述了。它的作用也比較簡單,就是拿到邊中算出的jacobian,之後根據公式
相關的程式程式碼這裡貼出來:
block_solver.hpp
for (size_t i = 0; i < _optimizer->indexMapping().size(); ++i) {
OptimizableGraph::Vertex* v = _optimizer->indexMapping()[i];
if (! v->marginalized()){
//assert(poseIdx == v->hessianIndex());
PoseMatrixType* m = _Hpp->block(poseIdx, poseIdx, true);
if (zeroBlocks)
m->setZero();
v->mapHessianMemory(m->data());
++poseIdx;
} else {
LandmarkMatrixType* m = _Hll->block(landmarkIdx, landmarkIdx, true);
if (zeroBlocks)
m->setZero();
v->mapHessianMemory(m->data());
++landmarkIdx;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
base_binary_edge.hpp
if (this->robustKernel() == 0) {
if (fromNotFixed) {
Eigen::Matrix<number_t, VertexXiType::Dimension, D, Eigen::ColMajor> AtO = A.transpose() * omega;
from->b().noalias() += A.transpose() * omega_r;
from->A().noalias() += AtO*A;
if (toNotFixed ) {
if (_hessianRowMajor) // we have to write to the block as transposed
_hessianTransposed.noalias() += B.transpose() * AtO.transpose();
else
_hessian.noalias() += AtO * B;
}
}
if (toNotFixed) {
to->b().noalias() += B.transpose() * omega_r;
to->A().noalias() += B.transpose() * omega * B;
}
} else { // robust (weighted) error according to some kernel
number_t error = this->chi2();
Vector3 rho;
this->robustKernel()->robustify(error, rho);
InformationType weightedOmega = this->robustInformation(rho);
//std::cout << PVAR(rho.transpose()) << std::endl;
//std::cout << PVAR(weightedOmega) << std::endl;
omega_r *= rho[1];
if (fromNotFixed) {
from->b().noalias() += A.transpose() * omega_r;
from->A().noalias() += A.transpose() * weightedOmega * A;
if (toNotFixed ) {
if (_hessianRowMajor) // we have to write to the block as transposed
_hessianTransposed.noalias() += B.transpose() * weightedOmega * A;
else
_hessian.noalias() += A.transpose() * weightedOmega * B;
}
}
if (toNotFixed) {
to->b().noalias() += B.transpose() * omega_r;
to->A().noalias() += B.transpose() * weightedOmega * B;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
_b矩陣
它的型別就是簡單的Eigen::Vector,這裡不是用的對映關係,但是他的作用和上述的類似,只不過最後是通過拷貝把b=JTerrorb=JTerror給整個的b。
相關程式碼如下(上面的base_binary_edge.hpp程式碼有意部分):
base_vertex.h
virtual int copyB(number_t* b_) const {
memcpy(b_, _b.data(), Dimension * sizeof(number_t));
return Dimension;
}- 1
- 2
- 3
- 4
總結
g2o的頂點的繼承還是比較容易的,但是一定要搞清楚D和E表示什麼,不要填寫錯誤(這裡的D對應BlockSolver中的PoseMatrixTpye的維度)。
g2o的邊(Edge)
首先我們也是先給出邊的繼承關係 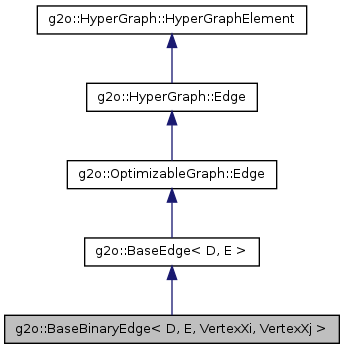
這裡擷取的是二元邊的繼承圖,下面的分析也是以該二元邊為例的。
g2o::BaseBinaryEdge< D, E, VertexXi, VertexXj >
int D, typename E
首先還是介紹這兩個引數,還是從原始碼上來看
static const int Dimension = D;
typedef E Measurement;
typedef Eigen::Matrix<number_t, D, 1, Eigen::ColMajor> ErrorVector;- 1
- 2
- 3
可以看到,D決定了誤差的維度,從對映的角度講,三維情況下就是2維的,二維的情況下是1維的;然後E是measurement的型別,也就是測量值是什麼型別的,這裡E就是什麼型別的(一般都是Eigen::VectorN表示的,N是自然數)。
和前面一樣,這兩個引數是直接面向我們的,一定要定義妥當。
typename VertexXi, typename VertexXj
這兩個引數就是邊連線的兩個頂點的型別,這裡特別注意一下,這兩個必須一定是頂點的型別,也就是繼承自BaseVertex等基礎類的類!不是頂點的資料類!例如必須是VertexSE3Expmap而不是VertexSE3Expmap的資料型別類SE3Quat。原因的話原始碼裡面也很清楚,因為後面會用到一系列頂點的維度等等的屬性,這些屬性是資料型別類裡面沒有的。
_jacobianOplusXi,_jacobianOplusXj和_hessian
這幾個引數是一些內部的引數,_jacobianOplusXi和_jacobianOplusXj也算是在繼承的時候需要面向的引數,不算特別內部,但是這裡還是記錄說明一下。
_jacobianOplusXi,_jacobianOplusXj
這兩個變數本質上是Eigen::Matrix型別的,具體定義在這裡:
typedef typename Eigen::Matrix<number_t, D, Di, D==1?Eigen::RowMajor:Eigen::ColMajor>::AlignedMapType JacobianXiOplusType;
typedef typename Eigen::Matrix<number_t, D, Dj, D==1?Eigen::RowMajor:Eigen::ColMajor>::AlignedMapType JacobianXjOplusType;
JacobianXiOplusType _jacobianOplusXi;
JacobianXjOplusType _jacobianOplusXj;- 1
- 2
- 3
- 4
然後這裡給出一個base_binary_edge類中的jacobian的程式:
base_binary_edge.hpp
template <int D, typename E, typename VertexXiType, typename VertexXjType>
void BaseBinaryEdge<D, E, VertexXiType, VertexXjType>::linearizeOplus()
{
VertexXiType* vi = static_cast<VertexXiType*>(_vertices[0]);
VertexXjType* vj = static_cast<VertexXjType*>(_vertices[1]);
bool iNotFixed = !(vi->fixed());
bool jNotFixed = !(vj->fixed());
if (!iNotFixed && !jNotFixed)
return;
#ifdef G2O_OPENMP
vi->lockQuadraticForm();
vj->lockQuadraticForm();
#endif
const number_t delta = cst(1e-9);
const number_t scalar = 1 / (2*delta);
ErrorVector errorBak;
ErrorVector errorBeforeNumeric = _error;
if (iNotFixed) {
//Xi - estimate the jacobian numerically
number_t add_vi[VertexXiType::Dimension] = {};
// add small step along the unit vector in each dimension
for (int d = 0; d < VertexXiType::Dimension; ++d) {
vi->push();
add_vi[d] = delta;
vi->oplus(add_vi);
computeError();
errorBak = _error;
vi->pop();
vi->push();
add_vi[d] = -delta;
vi->oplus(add_vi);
computeError();
errorBak -= _error;
vi->pop();
add_vi[d] = 0.0;
_jacobianOplusXi.col(d) = scalar * errorBak;
} // end dimension
}
if (jNotFixed) {
//Xj - estimate the jacobian numerically
number_t add_vj[VertexXjType::Dimension] = {};
// add small step along the unit vector in each dimension
for (int d = 0; d < VertexXjType::Dimension; ++d) {
vj->push();
add_vj[d] = delta;
vj->oplus(add_vj);
computeError();
errorBak = _error;
vj->pop();
vj->push();
add_vj[d] = -delta;
vj->oplus(add_vj);
computeError();
errorBak -= _error;
vj->pop();
add_vj[d] = 0.0;
_jacobianOplusXj.col(d) = scalar * errorBak;
}
} // end dimension
_error = errorBeforeNumeric;
#ifdef G2O_OPENMP
vj->unlockQuadraticForm();
vi->unlockQuadraticForm();
#endif
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
由程式可以看出,這裡的求解演算法是從定義出發的一種求解,數學上的推導類似於:
假定有函式f(x⃗) x⃗=(a,b,c)Tf(x→) x→=(a,b,c)T,此時我們要求解該函式的偏導數,自然按照定義就行求解:
對於假定的函式,我們可以進行如下的推導:
J=[f(x⃗+Δa)−f(x⃗)Δa,f(x⃗+Δb)−f(x⃗)Δb,f(x⃗+Δc)−f(x⃗)Δc]J=[f(x→+Δa)−f(x→)Δa,f(x→+Δb)−f(x→)Δb,f(x→+Δc)−f(x→)Δc]
上面的程式碼基本上就是按照這個思路進行的,只不過程式碼取了 ±Δx±Δx進行求取。
這裡,一個問題出現在我的腦海裡,既然這個方法是如此的正確(都按照定義來了哇),為什麼我們還要在繼承的時候把這個方法覆寫呢?想了段時間,我覺得可能是因為該段程式碼比較費時吧,如果我們有幾個乘法就能求出jacobian,那麼勢必不會用這樣的迴圈去做,特別是狀態變數多的時候!當然這裡僅僅是個人的見解, 有大神知道的話還煩請留言說一下。
_hessian矩陣
這裡hessian矩陣的作用和頂點裡面的無二,都是一個Map的對映,旨在成小塊的構建大的H矩陣,這裡千萬不要以為邊構建的是Hpl和HlpHpl和Hlp,主要還是取決於邊連線的頂點的型別,在g2o裡面,Hpl和HlpHpl和Hlp主要是靠頂點的marginalization標誌進行區分的,標誌為false,則將會歸在HppHpp中,標誌為true則會歸在HllHll中,可不是我們認為這是pose就歸在HppHpp,這是point就歸在HllHll中的!下面給出的是整個大H矩陣的塊狀結構。
主要的程式碼這裡也給出來:
block_solver.h
for (SparseOptimizer::EdgeContainer::const_iterator it=_optimizer->activeEdges().begin(); it!=_optimizer->activeEdges().end(); ++it){
OptimizableGraph::Edge* e = *it;
for (size_t viIdx = 0; viIdx < e->vertices().size(); ++viIdx) {
OptimizableGraph::Vertex* v1 = (OptimizableGraph::Vertex*) e->vertex(viIdx);
int ind1 = v1->hessianIndex();
if (ind1 == -1)
continue;
int indexV1Bak = ind1;
for (size_t vjIdx = viIdx + 1; vjIdx < e->vertices().size(); ++vjIdx) {
OptimizableGraph::Vertex* v2 = (OptimizableGraph::Vertex*) e->vertex(vjIdx);
int ind2 = v2->hessianIndex();
if (ind2 == -1)
continue;
ind1 = indexV1Bak;
bool transposedBlock = ind1 > ind2;
if (transposedBlock){ // make sure, we allocate the upper triangle block
std::swap(ind1, ind2);
}
if (! v1->marginalized() && !v2->marginalized()){
PoseMatrixType* m = _Hpp->block(ind1, ind2, true);
if (zeroBlocks)
m->setZero();
e->mapHessianMemory(m->data(), viIdx, vjIdx, transposedBlock);
if (_Hschur) {// assume this is only needed in case we solve with the schur complement
schurMatrixLookup->addBlock(ind1, ind2);
}
} else if (v1->marginalized() && v2->marginalized()){
// RAINER hmm.... should we ever reach this here????
LandmarkMatrixType* m = _Hll->block(ind1-_numPoses, ind2-_numPoses, true);
if (zeroBlocks)
m->setZero();
e->mapHessianMemory(m->data(), viIdx, vjIdx, false);
} else {
if (v1->marginalized()){
PoseLandmarkMatrixType* m = _Hpl->block(v2->hessianIndex(),v1->hessianIndex()-_numPoses, true);
if (zeroBlocks)
m->setZero();
e->mapHessianMemory(m->data(), viIdx, vjIdx, true); // transpose the block before writing to it
} else {
PoseLandmarkMatrixType* m = _Hpl->block(v1->hessianIndex(),v2->hessianIndex()-_numPoses, true);
if (zeroBlocks)
m->setZero();
e->mapHessianMemory(m->data(), viIdx, vjIdx, false); // directly the block
}
}
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
總結
- 在定義自己的邊和頂點的時候,務必要弄明白D和E所代表的含義,在定義邊的時候還要注意後面兩個引數一定是一個頂點的類而不是資料型別;
- 在邊的linearizeOplus函式定義時,如果我們有更簡潔的數學表達,那麼可以轉化為程式語言進行求解,如果沒有,也可以使用父類的求解方法,但是這種方法由於使用了迴圈,甚至中間還求了多次對映誤差,因此較為耗時;
- 千萬不要以為g2o會幫你區分什麼是pose,什麼是point,從而對號入座在HppHpp和HllHll中,這塊必須由使用者設定marginalization告訴g2o什麼頂點歸在那一塊裡面;
- 綜合看來,g2o幫助我們實現了很多內部的演算法,但是在進行構造的時候,也需要遵循一些規則,在我看來這是可以接收的,畢竟一個程式不可能滿足所有的要求,因此在以後g2o的使用中還是應該多看多記,這樣才能更好的使用這個庫。