
g2o學習——g2o整體框架
寫在前面
進來對g2o優化庫進行了學習,雖然才模仿著寫了兩個例程,但是對於整個g2o的理解和使用方面還是多了不少的感觸,特此寫下部落格,對這些天的學習進行記錄。
g2o的整體結構
說到整體的結構,不得不用一張比較概括的圖來說明:
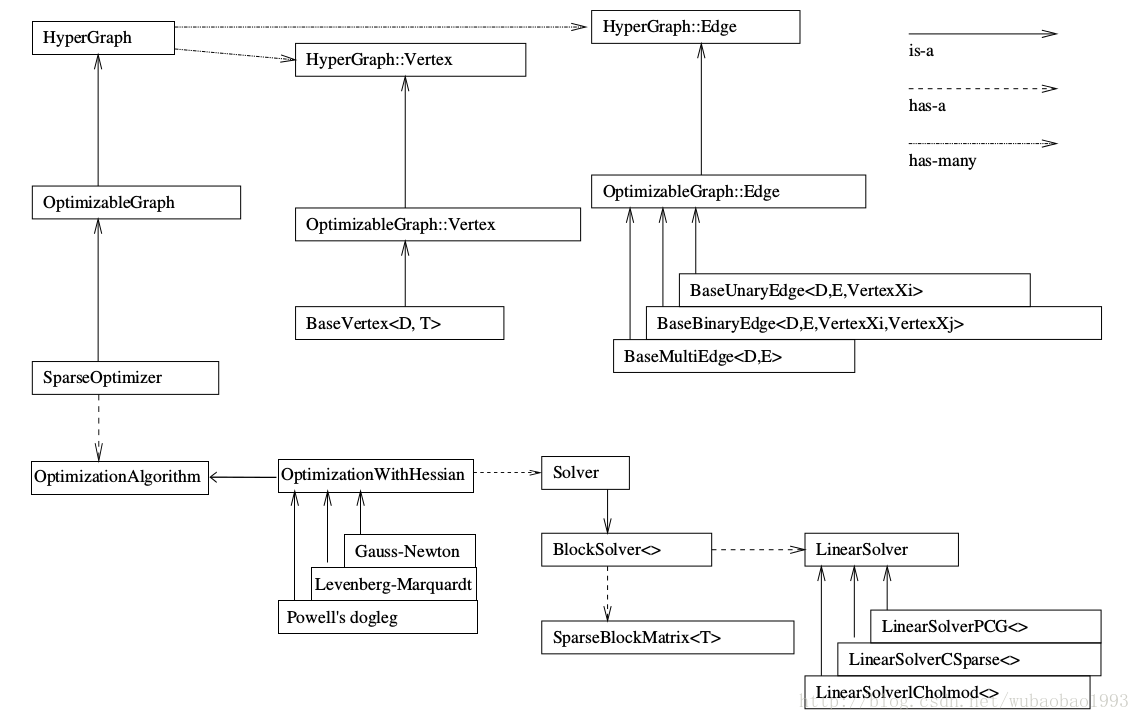
這張圖最好跟著畫一下,這樣能更好的理解和掌握,例如我第一次看的時候根本沒有注意說箭頭的型別等等的細節。
那麼從圖中我們其實比較容易的就看出來整個庫裡面較為重要的類之間的繼承以及包含關係,也可以看出整個框架裡面最重要的東西就是SparseOptimizer這個類(或者說例項)。
頂點(Vertex)和邊(Edge)
順著圖往上看,可以看到我們所使用的優化器最終是一個超圖(hyperGrahp),而這個超圖包含了許多頂點(Vertex)和邊(Edge)。這兩個型別是我們在看程式和寫程式中比較關注的東西了,g2o不像Ceres,內部很多東西其實作者都已經寫好了(此刻一鞠躬),很適合我們這些新興的懶惰青年,但是同時,我們也失去了一個比較完整的瞭解內部關係的機會,不過這個東西我們可以通過看內部的實現補回來(但是程式設計實踐是沒有機會了),順便看看大牛寫的程式碼~
那麼扯回來,在圖優化中,頂點代表了要被優化的變數,而邊則是連線被優化變數的橋樑,因此,也就造成了說我們在程式中見得較多的就是這兩種型別的初始化和賦值。
在整個優化過程中,頂點的值會越來越趨近於最有值,優化完畢後則可以將頂點的優化值作為最優值進行使用;邊則是連線頂點的型別,在SLAM問題中,一般是邊連線要被優化的空間點(Point)和機器人的位姿(Pose),當然,邊還可以連線一個頂點(類似與引數估計,邊的數量由量測的數量決定),也可以連線多個頂點(超圖,這裡筆者還沒有遇到過,就不妄言了),邊在圖優化中的一個很大的作用就是計算誤差(視覺SLAM中計算的就是空間點的對映誤差),同時計算該誤差對於被優化變數的jacobian矩陣,也是比較重要的存在。
自定義頂點(Vertex)和邊(Edge)
我們在用g2o的時候,不會一帆風順的就能適合自身機器人的實際情況,總會遇到自己獨特的頂點型別和邊型別,此時我們需要對頂點和邊進行重寫,那麼重寫也比較簡單,這裡簡單進行記錄。
在整體框架圖中,可以看到不管是頂點還是邊,都可以說是繼承自baseXXX這個類的,因此我們在自定義的時候,也可以仿照著繼承這兩個類,當然也可以繼承自g2o中較為“成熟”的類,不管怎樣,都要重寫下述的函式。
自定義頂點
virtual bool read(std::istream& is); virtual bool write(std::ostream& os) const; virtual void oplusImpl(const number_t* update); virtual void setToOriginImpl();
其中read,write函式可以不進行覆寫,僅僅宣告一下就可以,setToOriginImpl設定被優化變數的原始值,oplusImpl比較重要,我們根據增量方程計算出增量之後,就是通過這個函式對估計值進行調整的,因此這個函式的內容一定要寫對,否則會造成一直優化卻得不到好的優化結果的現象。
自定義邊
virtual bool read(std::istream& is);
virtual bool write(std::ostream& os) const;
virtual void computeError();
virtual void linearizeOplus();read和write函式同上,computeError函式是使用當前頂點的值計算的測量值與真實的測量值之間的誤差,linearizeOplus函式是在當前頂點的值下,該誤差對優化變數的偏導數,即jacobian。
自定義的總結
不管是自定義邊還是頂點,除了自己加入的一些變數,還都要對一些g2o框架要呼叫的函式進行覆寫,這些函式使用者可以宣告為實函式(即不加virtual),但是筆者還是建議宣告為虛擬函式。
優化演算法(Algorithm,BlockSolver,linearSolver)
順著整體結構圖往下看,可以看到這部分其實算是整個g2o裡面比較隱晦的部分,設計到優化的演算法,塊求解器,線性求解器等等部分,在程式中,這部分通常位於g2o演算法的開頭配置部分,一般情況下我們可以隨著一個例程進行配置即可,這裡對這部分進行了稍微淺顯的理解,特意寫在這裡(下面的東西純屬個人理解了,如有不妥還請大神指出:)。
linearSolver,線性求解器
我們知道在求解增量方程HdeltaX=-b的時候,通常情況下想到線性求解,很簡單嘛,deltaX=-H.inv*b,的確,當H的維度較小的時候,上述問題變得簡單,只需要矩陣的求逆就能解決問題,但是當H的維度較大時,問題變得複雜,此時我們就需要一些特殊的方法對矩陣進行求逆,g2o中主要有圖中所示的三種方法,PCG,CSparse和Cholmod方法。
注意,這裡說再多,線性求解器僅僅只是完成了一個求解的功能,可以說是整個優化中比較靠後的計算部分了。
BlockSolver,塊求解器(引數塊求解器?)
塊求解器是包含線性求解器的存在,之所以是包含,是因為塊求解器會構建好線性求解器所需要的矩陣塊(也就是H和b),之後給線性求解器讓它進行運算,邊的jacobian也就是在這個時候發揮了自己的光和熱。
這裡再記錄下一個比較容易混淆的問題,也就是在初始化塊求解器的時候的引數問題。
大部分的例程在初始化塊求解器的時候都會使用如下的程式程式碼:
std::unique_ptr<g2o::BlockSolver_6_3::LinearSolverType> linearSolver = g2o::make_unique<g2o::LinearSolverCholmod<g2o::BlockSolver_6_3::PoseMatrixType>>();其中的BlockSolver_6_3有兩個引數,分別是6和3,在定義的時候可以看到這是一個模板的重新命名(模板類的重新命名只能用using)
template<int p, int l>
using BlockSolverPL = BlockSolver< BlockSolverTraits<p, l> >;其中p代表pose的維度,l表示landmark的維度,且這裡都表示的是增量的維度(這裡筆者也不是很確定,但是從後續的程式中可以看出是增量的維度而並非是狀態變數的維度)。
因此(後面的話以SLAM情況為例),對於僅僅優化位姿的應用而言,這裡l的值是沒有太大影響的,因為H矩陣中並沒有Hll的塊,因此這裡的維度也就沒有用武之地了。
Algorithm,優化演算法
這裡就不多講了,從圖中可以看到主要有三種方法:GN,LM,PSD,不同的方法主要表現在最終的H矩陣構造不同。
總結
1. 對g2o優化庫的整體框架有了更好的瞭解
2. 對圖中的頂點和邊有了更加深刻的認識
3. 理解了g2o初始化部分的程式與意圖
以上觀點僅僅代表個人學習觀點,如有不對還請各位大神指正!這裡不勝感激!