
深入ZooKeeper——ZooKeeper的概念和基礎
由於Kafka和Duboo都需要在ZooKeeper的基礎上執行,所以我們先學習ZooKeeper。
ZooKeeper改變了什麼
ZooKeeper的設計更專注於任務協作,並不提供任何鎖的介面或通用儲存資料介面。同時,ZooKeeper沒有給開發人員強加任何特殊的同步原語,使用起來非常靈活。
整個ZooKeeper的伺服器叢集管理著應用協作的關鍵資料。ZooKeeper不適合用作海量資料儲存。對於需要儲存海量的應用資料的情況,我們有很多備選方案,比如說資料庫和分散式檔案系統等。
ZooKeeper中實現了一組核心操作,通過這些可以實現很多常見分散式應用的任務。你知道有多少應用服務採用主節點方式或程序響應跟蹤方式?雖然ZooKeeper並沒有為你實現這些任務,也沒有為應用實現主節點選舉,或者程序存活與否的跟蹤的功能,但是,ZooKeeper提供了實現這些任務的工具,對於實現什麼樣的協同任務,由開發人員自己決定。
分散式定義
分散式系統是同時跨越多個物理主機,獨立執行的多個軟體元件所組成的系統。
我們採用分散式去設計系統有很多原因,分散式系統能夠利用多處理器的運算能力來執行元件,比如並行複製任務。一個系統也許由於戰略原因,需要分佈在不同地點,比如一個應用由多個不同地點的伺服器提供服務。
分散式系統中的程序通訊有兩種選擇:直接通過網路進行資訊交換,或讀寫某些共享儲存。
ZooKeeper使用共享儲存模型來實現應用間的協作和同步原語。
在真實的系統中,我們需要特別注意以下問題:
- 訊息延遲。比如網路擁堵。
- 處理器效能。比如作業系統的排程和超載,這個造成的結果是處理器效能下降,最終導致訊息延遲。
- 時鐘偏移。比如確定某一時間系統中發生了哪些事件,由於處理器時鐘不可靠而帶來的錯誤決策。
關於這些問題的一個重要結果是,在實際情況中,我們很難判斷一個程序是崩潰了還是某些因素導致了延時。沒有收到一個程序傳送的訊息,可能是該程序已經崩潰,或是最新訊息發生了網路延遲,或是其他情況導致程序延遲,或者是程序時鐘發生了偏移。我們無法確定一個被稱為非同步(asynchronous)的系統中的這些區別。
ZooKeeper的精確設計簡化了這些問題的處理,ZooKeeper並不是完全消除這些問題,而是將這些問題在應用服務層面上完全透明化,使得這些問題更容易處理。
主從系統
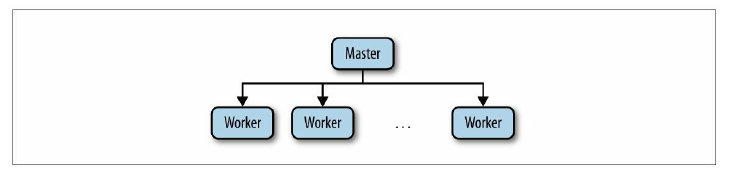
一般在這種架構中,主節點程序負責跟蹤從節點狀態和任務的有效性,並分配任務到從節點。對ZooKeeper來說,這個架構風格具有代表性,闡述了大多數流行的任務,如選舉主節點
要實現主-從模式的系統,我們必須解決以下三個關鍵問題:
- 主節點崩潰
如果主節點發送錯誤並失效,系統將無法分配新的任務或重新分配已失敗的任務。 - 從節點崩潰
如果從節點崩潰,已分配的任務將無法完成。 - 通訊故障
如果主節點和從節點之間無法進行資訊交換,從節點將無法得知新任務分配給它。
主節點失效
主節點失效時,我們需要有一個備份主節點(backup master)。當主要主節點(primary master)崩潰時,備份主節點接管主要主節點的角色,進行故障轉移,然而,這並不是簡單開始處理進入主節點的請求。新的主要主節點需要能夠恢復到舊的主要主節點崩潰時的狀態。對於主節點狀態的可恢復性,我們不能依靠從已經崩潰的主節點來獲取這些資訊,而需要從其他地方獲取,也就是通過ZooKeeper來獲取。
狀態恢復並不是唯一的重要問題。假如主節點有效,備份主節點卻認為主節點已經崩潰。這種錯誤的假設可能發生在以下情況,例如主節點負載很高,導致訊息任意延遲。備份主節點將會接管成為主節點的角色,執行所有必需的程式,最終可能以主節點的角色開始執行,成為第二個主要主節點。。更糟的是,如果一些從節點無法與主要主節點通訊,如由於網路分割槽(network partition)錯誤導致,這些從節點可能會停止與主要主節點的通訊,而與第二個主要主節點建立主-從關係。
我們一般稱之為腦裂(split-brain):系統中兩個或者多個部分開始獨立工作,導致整體行為不一致性。我們需要找出一種方法來處理主節點失效的情況,關鍵是我們需要避免發生腦裂的情況。
從節點失效
客戶端向主節點提交任務,之後主節點將任務派發到有效的從節點中。從節點接收到派發的任務,執行完這些任務後會向主節點報告執行狀態。主節點下一步會將執行結果通知給客戶端。
如果從節點崩潰了,所有已派發給這個從節點且尚未完成的任務需要重新派發。其中首要需求是讓主節點具有檢測從節點的崩潰的能力。主節點必須能夠檢測到從節點的崩潰,並確定哪些從節點是否有效以便派發崩潰節點的任務。一個從節點崩潰時,從節點也許執行了部分任務,也許全部執行完,但沒有報告結果。如果整個運算過程產生了其他作用,我們還有必要執行某些恢復過程來清除之前的狀態。
通訊故障
如果一個從節點與主節點的網路連線斷開,比如網路分割槽(network partition)導致,重新分配一個任務可能會導致兩個從節點執行相同的任務。如果一個任務允許多次執行,我們在進行任務再分配時可以不用驗證第一個從節點是否完成了該任務。如果一個任務不允許,那麼我們的應用需要適應多個從節點執行相同任務的可能性。
對任務加鎖並不能保證一個任務執行多次,比如以下場景中描述的
情況:
1.主節點M1派發任務T1給從節點W1。
2.W1為任務T1獲取鎖,執行任務,然後釋放鎖。
3.M1懷疑W1已經崩潰,所以再次派發任務T1給從節點W2。
4.W2為任務T1獲取鎖,執行任務,然後釋放鎖。
通訊故障導致的另一個重要問題是對鎖等同步原語的影響。
因為節點可能崩潰,而系統也可能網路分割槽(network partition),鎖機制也會阻止任務的繼續執行。因此ZooKeeper也需要實現處理這些情況的機制。
首先,客戶端可以告訴ZooKeeper某些資料的狀態是臨時狀態(ephemeral)。
其次,同時ZooKeeper需要客戶端定時傳送是否存活的。
通知,如果一個客戶端未能及時傳送通知,那麼所有從屬於這個客戶端的臨時狀態的資料將全部被刪除。
任務總結
根據之前描述的這些,我們可以得到以下主-從架構的需求:
- 主節點選舉 :使得主節點可以給從節點分配任務。
- 崩潰檢測:主節點必須具有檢測從節點崩潰或失去連線的能力。
- 組成員關係管理:主節點必須具有知道哪一個從節點可以執行任務的能力。
- 元資料管理:主節點和從節點必須具有通過某種可靠的方式來儲存分配狀態和執行狀態的能力。
分散式協作的難點
在獨立主機上執行的應用與分散式應用發生的故障存在顯著的區別:
如果是獨立主機上執行多個程序,一個程序執行的失敗,其他程序可以通過作業系統獲得這個故障,作業系統提供了健壯的多程序訊息通訊的保障。
在分散式環境中這一切發生了改變。如果一個主機或程序發生故障,其他主機繼續執行,並會接管發生故障的程序,為了能夠處理故障程序,這些仍在執行的程序必須能夠檢測到這個故障,無論是訊息丟失或發生了時間偏移。
不得不指出,完美的解決方案是不存在的。