
Solr--02.Solr中Core詳解
阿新 • • 發佈:2018-11-27
一、Core概述
1、Core概述
在Solr中、每一個Core、代表一個索引庫、裡面包含索引資料及其配置資訊、
Solr中可以擁有多個Core、也就是同進管理多個索契庫、就像mysql中可以有多個數據庫一樣。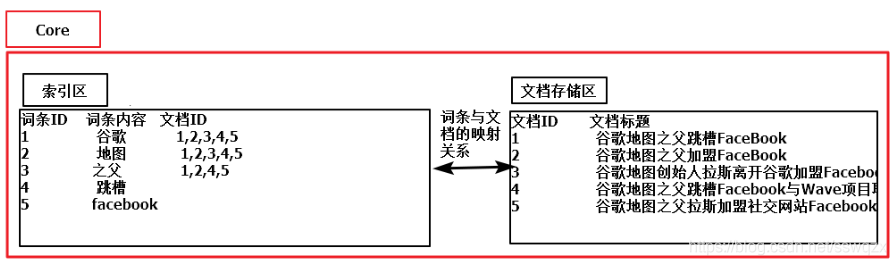
2、Core目錄結構
Core中有二個重要目錄:conf和data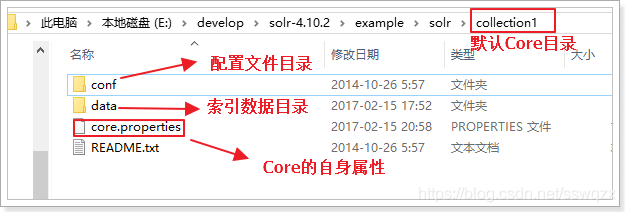
conf目錄中有兩個非常重要的配置檔案:schema.xml和solrconfig.xml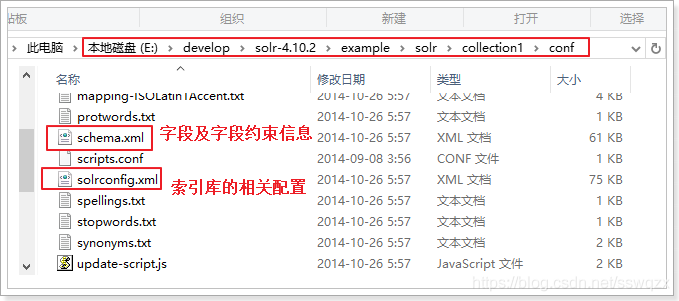
二、Core的配置檔案
1、core.properties
Core的屬性檔案,記錄當前core的名稱、索引位置、配置檔名稱等資訊,也可以不寫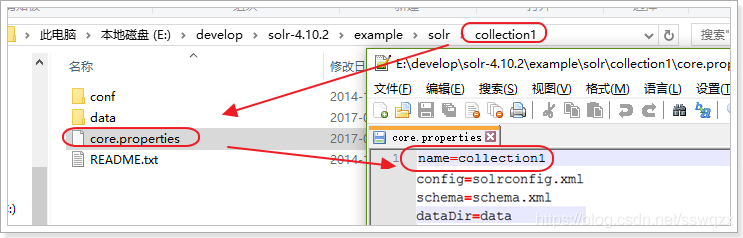
一般要求Core名稱跟Core的資料夾名稱一致!這裡都是Collection1,可以手動修改這個屬性,把Core的名字改成我們喜歡的。
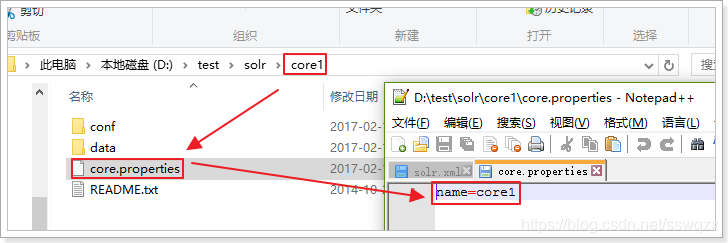
此時重啟Tomcat,可以看到core的名字已經改變!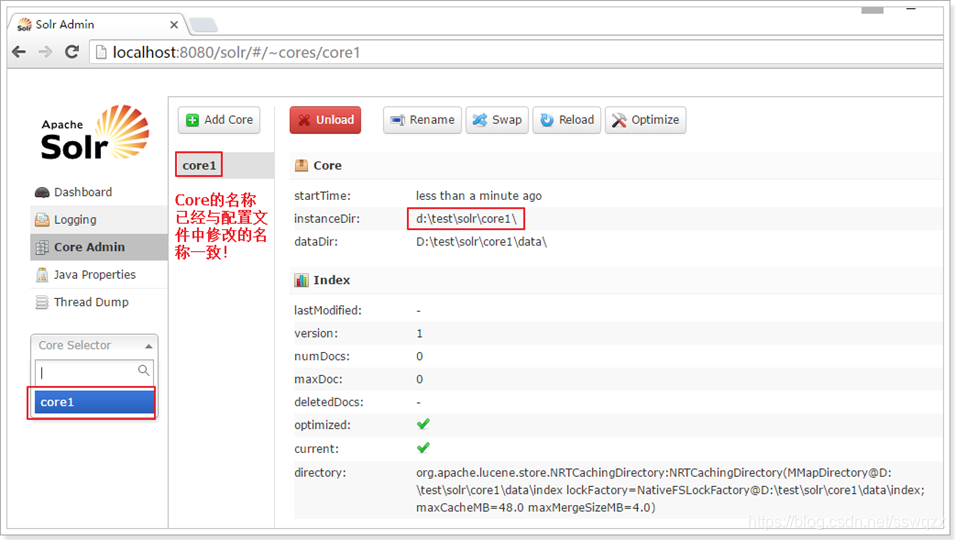
1.1、新增多個Core
1)在solr目錄下複製collection並重新命名為collection2,作為新的core目錄、如下圖
2)在collection2下建立conf目錄和data目錄,並且建立檔案core.properties,新增屬性:name=collection2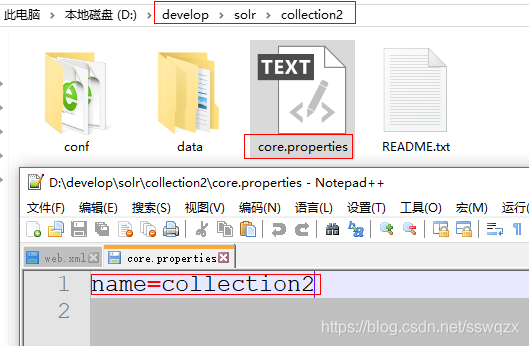
3)、重啟Tomcat,訪問管理頁面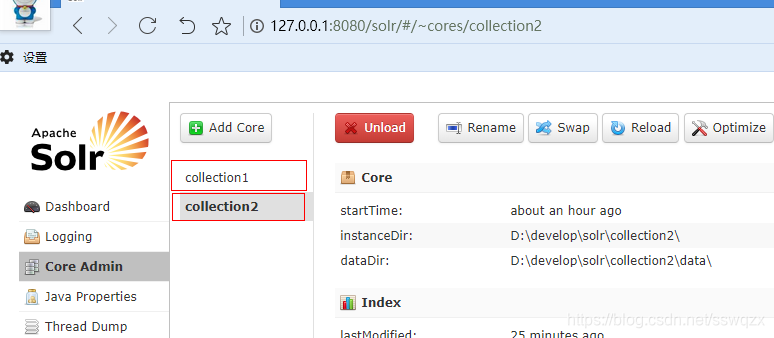
2、schema.xml
Schema.xml配置詳解:Solr中會提前對文件中的欄位進行定義, 並且在schema.xml中對這些欄位的屬性進行約束,例如:欄位資料型別、欄位是否索引、是否儲存、是否分詞等
2.1、<field>標籤
<field>標籤: 通過Field欄位 定義欄位的屬性資訊:
語法:
屬性及含義:
name:欄位名稱
type:欄位型別,指向的是本檔案中的<fieldType>標籤
indexed:是否建立索引
stored:是否被儲存
multiValued:是否可以有多個值,如果欄位可以有多個值,設定為true,false為單個值。
多個值:對應JSON的陣列格式。 對應java的List格式。
注意:
在本檔案中,有兩個欄位是Solr自帶的欄位,絕對不要刪除:_version節點、_root節點和id節點。

擴充套件:
•omitNorms:是否忽略掉Norm,可以節省記憶體空間,只有全文字field和need an index-time boost的field需要norm。
預設就是true,即忽略標準因子。如果一個域要使用得分激勵因子,必須要手動的設定omitNorm= false,否則會報錯。
•termVectors:當設定true,會儲存 term vector。當使用MoreLikeThis,用來作為相似詞的field應該儲存起來。
•termPositions:儲存 term vector中的地址資訊,會消耗儲存開銷。
•termOffsets:儲存 term vector 的偏移量,會消耗儲存開銷。2.2、<FieldType>標籤
過FieldType指定資料型別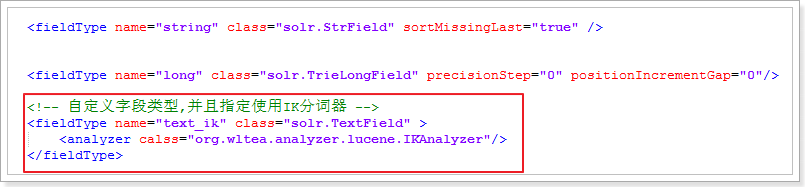
語法:
name:欄位型別的名稱,可以自定義,<field>標籤的type屬性可以引用該欄位,來指定資料型別
class:欄位型別在Solr中的類。StrField可索引不可分詞。TextField欄位可索引,可以分詞,所以需要指定分詞器
<analyzer>:這個子標籤用來指定分詞器
擴充套件:
precisionStep:
用於數值範圍搜尋,進行分詞 通過設定precisionStep的值可以提高檢索速度,8是solr的推薦值。
設定一個PrecisionStep (預設4),對數值型別每次右移(n-1)* PrecisionStep 位。
每次移位後,從左邊開始每7位存入一個byte,組成一個byte[],
並且在陣列第0位插入一個特殊byte,標識這次的偏移量。
每個byte[]可以轉成一個lexicographic sortable string。
lexicographic sortable string 的字元按字典序排列後,和偏移量,
數值的大小順序是一致的。這個是NumericRangeQuery 範圍查詢的關鍵。
positionIncrementGap:
一個doc中的屬性有多個值時候,設定每個屬性之間的增量值和multiValued屬性配合使用(避免錯誤匹配)。
其作用就是在對Multivalue Field進行處理的時候,給兩個field中相隔的詞人為的插入一段固定的distance
然後在使用Lucene/Solr做Phrase query的時候,如果沒有指定Slop(對slop的介紹,可以參
考:http://blog.csdn.net/rick_123/article/details/6708527),會預設Slop為0,即查詢的短語之間應該緊緊挨著,
這樣對很多情況下都得不到使用者想要的結果。解決的辦法就是使用phrase query,同時設定一個適當的Slop值,
然後為了不讓lucene的搜尋跨越多個Field Value,
設定一個遠大於slop的positionIncrementGap,就可以達到目標。
sortMissingLast:設定成true沒有該field的資料排在有該field的資料之後,而不管請求時的排序規則, 預設是true。
sortMissingFirst:跟sortMissingLast相反。預設是false。
analyzer:欄位型別指定的分詞器。
type:當前分詞器用於分詞的操作。index 代表生成索引時使用的分詞器。query 代表在查詢時使用的分詞器。
tokenizer:分詞器使用具體的分詞器類。
2.3、<uniqueKey>標籤
唯一主鍵
Lucene中本來是沒有主鍵的。刪除和修改都需要根據詞條進行匹配。
而Solr卻可以設定一個欄位為唯一主鍵,這樣增刪改操作都可以根據主鍵來進行!
2.4、<dynamicField>標籤
動態欄位
2.5、引入IK分詞器
(1)、引入依賴、 在schemal.xml中自定義fieldType,引入IK分詞器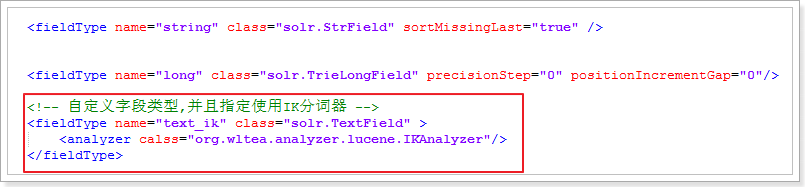
(2)、讓欄位使用我們的自定義資料型別,引入IK分詞器
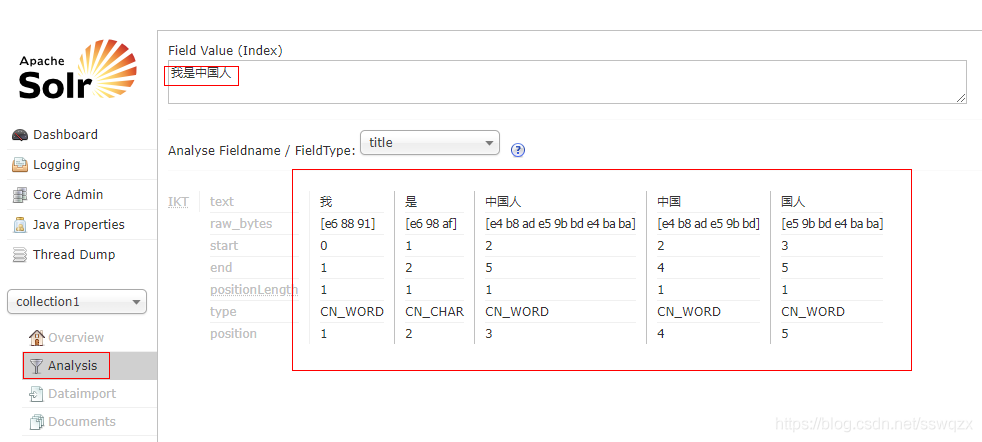
2.6、schema.xml簡化
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<!-- ========================1 不能刪除欄位=========================== -->
<!-- If you remove this field, you must _also_ disable the update log in solrconfig.xml
or Solr won't start. _version_ and update log are required for SolrCloud
-->
<field name="_version_" type="long" indexed="true" stored="true"/>
<!-- points to the root document of a block of nested documents. Required for nested
document support, may be removed otherwise
-->
<field name="_root_" type="string" indexed="true" stored="false"/>
<!-- Only remove the "id" field if you have a very good reason to. While not strictly
required, it is highly recommended. A <uniqueKey> is present in almost all Solr
installations. See the <uniqueKey> declaration below where <uniqueKey> is set to "id".
-->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<uniqueKey>id</uniqueKey>
<!-- ===================不能刪除欄位============================ -->
<!-- =========================2 索引庫業務欄位============================ -->
<field name="title" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="content" type="text_ik" indexed="true" stored="true"/>
<field name="text" type="text_ik" indexed="true" stored="false" multiValued="false"/>
<field name="price" type="float" indexed="true" stored="true"/>
<!-- ====================索引庫業務欄位============================= -->
<!-- =======================3 索引庫業務擴充套件欄位============================= -->
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<copyField source="title" dest="text"/>
<copyField source="content" dest="text"/>
<!-- =====================索引庫業務擴充套件欄位=========================== -->
<!-- ======================4 欄位型別定義============================== -->
<!-- IK分詞器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- ==========================欄位型別定義======================== -->
</schema>
3、solrconfig.xml
solrconfig.xml:這個配置檔案主要配置跟索引庫和請求處理相關的配置。solr服務的優化主要通過這個配置檔案進行:3.1、索引庫的相關配置
<lib/>標籤:
•用途:配置外掛依賴的jar包
•注意事項:
o如果引入多個jar包,要注意包和包的依賴關係,被依賴的包配置在前面
o這裡的jar包目錄如果是相對路徑,那麼是相對於core所在目錄、如下圖
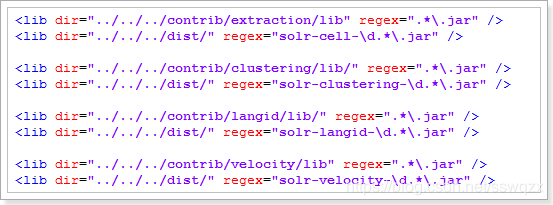
我們發現這些配置是在找兩個資料夾下的jar包:contrib和dist。這兩個資料夾其實在Solr的安裝目錄中有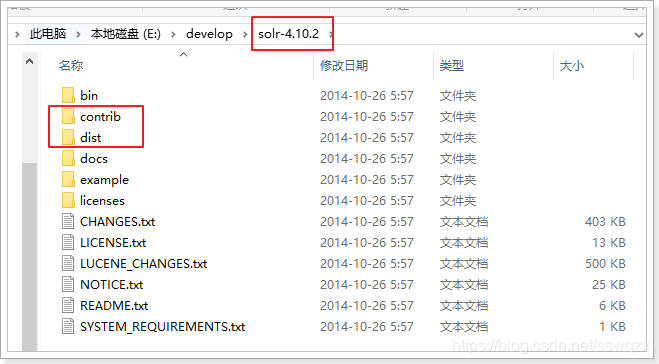
而<lib dir=””>標籤中的dir是相對目錄,預設相對於core目錄。
我們的core在D:\\test\\solr\\core1位置,我們把這兩個資料夾複製到solr下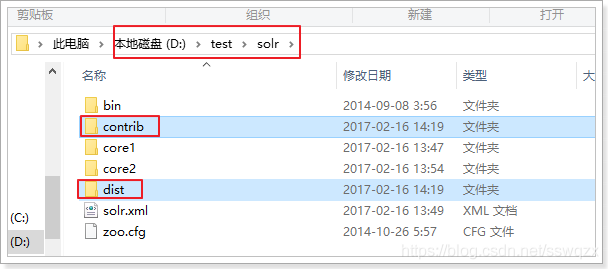
然後修改相對路徑,只留下一個 ../ 即可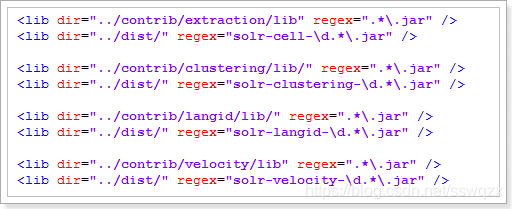
3.2、請求處理相關的配置
<requestHandler/> 標籤:
•用途:配置Solr處理各種請求(搜尋/select、更新索引/update、等)的各種引數
•主要引數:
o name:請求型別,例如:select、query、get、update
o class:處理請求的類
o initParams:可選。引用<initParams>標籤中的配置
o <lst name="defaults">:定義各種預設的配置,比如預設的parser、預設返回條數
例子:負責搜尋請求的Handler
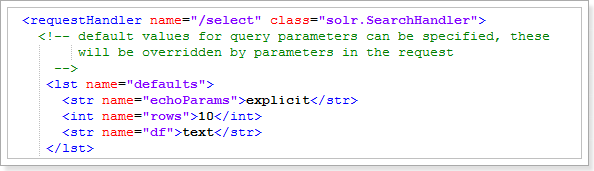
這裡有一個預設選項:rows=10 ,就是設定預設查10條資料
<str name=”df”> text</str> 這個是設定預設搜尋的欄位為:text,我們可以設定為title,因為我們沒有text欄位
<initParams/>標籤:
•用途:為一些requestHandlers定義通用的配置,以便在一個地方修改後,所有地方都生效
•主要引數:
o path:指明該配置應用於哪些請求路徑,多個 的話用逗號分開,可以用萬用字元(*表示一層子路徑,**表示無限層)
o name:如果不指定path,可以指定一個name,然後在<requestHander>配置中可以引用這個name。
例子: (配置一個預設的df)
<initParams path="/update/**,/query,/select,/tvrh,/elevate,/spell,/browse">
<lst name="defaults">
<str name="df">_text_</str>
</lst>
</initParams>
<updateHandler/>標籤:
• 用途:定義一些更新索引相關的引數,比如定義commit的時機
• 主要引數:
o autoCommit:定義自動commit的觸發條件。如果沒配置這個引數,則每次都必須手動commit
maxDocs
maxTime(毫秒)
openSearcher:autoCommit結束後,是否開啟一個新的searcher讓更改生效。預設為false
o autoSoftCommit:定義自動softCommit的觸發條件。相關引數同autoCommit
o listener:配置事件監聽器
event:監聽哪個事件,比如:event="postCommit", event="postOptimize"
class:處理的類,可以是自己的實現類。如果是RunExecutableListener,可以配置下面的引數:
exe:可執行檔案,包括Solr Home的相對路徑和檔名
dir:工作目錄,預設是“.”
wait: 呼叫者是否等待可執行檔案執行結束,預設是true
args:傳遞給可執行檔案的引數
env:其他所需要的環境變數
o updateLog:配置log的儲存路徑、等
dir:儲存路徑
numRecordsToKeep:一個log儲存的記錄數,預設為100
maxNumLogsToKeep:log的數量,預設為10
numversionBuckets:追蹤max version的bucket數量(?),預設為65535
配置這些引數要考慮到搜尋的準確度和效能的平衡。
注:commit和softCommit:
• commit:正式提交、對索引的修改會被儲存到永久儲存中(比如磁碟),會比較耗時
• softCommit:軟提交,對索引的修改會被立即應用到工作中的索引中,即立即生效,但沒有儲存進磁碟
<query/>標籤:
• 用途:配置Solr如何處理和返回搜尋的相關引數
• 主要引數:
o filterCache:當搜尋帶有“fq”引數時,使用這個配置,它儲存未經過排序的所有文件
class:實現類,有三種:solr.search.LRUCache, solr.search.FastLRUCache, solr.search.LFUCache
size:最大儲存的記錄數量
initialSize:初始數量
autowarmCount:新Index Searcher啟動的時候從舊的Index Searcher快取拷貝過來的資料量
o queryResultCache:儲存最終的搜尋結果(排序後的、有範圍的文件id)
class:實現類,有三種:solr.search.LRUCache, solr.search.FastLRUCache, solr.search.LFUCache
size:最大儲存的記錄數量
initialSize:初始數量
autowarmCount:新Index Searcher啟動的時候從舊的Index Searcher快取拷貝過來的資料量
maxRamMB:最大分配的容量(兆)
o documentCache:快取Lucene Document物件(就是每個文件的fields)
class:實現類,有三種:solr.search.LRUCache, solr.search.FastLRUCache, solr.search.LFUCache
size:最大儲存的記錄數量
initialSize:初始數量
autowarmCount:因為Lucene的內部文件 id 是臨時的,所以這個快取不應該被auto-warm,這個值應該為“0”
o cache:配置自定義的快取,通過SolrIndexSearcher類的getCache()方法和name引數呼叫這個快取
name:被呼叫時的標識
其他引數同上
o maxBooleanClauses:BooleanQuery的最大子句數量
o enableLazyFieldLoading:沒有知道被請求的field是否懶載入,true/false
o useFilterForSortedQuery:如果不是按照score排序,是否從filterCache中獲取資料
o queryResultWindowsize:配合queryResultCache使用,快取一個超集。如果搜尋請求第10到19條記錄,
而這個引數是50,那麼會快取0到49條記錄
o queryResultMaxDocsCached:queryResultCache快取的最大文件數量
o useColdSearcher:但一個新searcher正在warm-up的時候,新請求是使用舊是searcher(true)還是等待新的search(false)
o maxWarmingSearchers:定義同時在warm-up的searcher的最大數量
o listener:監聽一些事件並指定處理的類,比如在solr啟動時載入一些資料到快取中,相關引數:
event:被監聽的事件,比如:firstSearcher是第一個searcher啟動、
也就是solr啟動的事件,newSearcher是當已經有searcher在執行的時候有新searcher啟動的事件
class:處理類
name:="queries"就是需要處理的是query
lst, name:針對哪些搜尋條件需要處理
擴充套件:
快取的清空策略一共有三種:
LRU(Least Recently Used):最近最少使用
LFU(Leats Frequently Uesd):最不經常使用
FIFO(First in First Out):先進先出
<requestDispatcher/>標籤:
•用途:控制Solr HTTP RequestDispatche r響應請求的方式,比如:是否處理/select url、
是否支援對流的處理、上傳檔案的大小、如何處理帶有cache頭的HTTP請求、等等
•主要引數:
o handleSelect:true/false,如果是false,則由requestHandler來處理/select請求。
因為現在的requestHandler中/select是標配,所以這裡應該填false
o requestParsers:
enableRemoteStreaming:是否接受流格式的內容,預設為ture
multipartUploadLimitInKB:multi-part POST請求,上傳檔案的大小上限(K)
formdataUploadLimitInKB:HTTP POST的form data大小上限(K)
addHttpRequestToContext:原始的HttpServletRequest物件是否應該被包含在
SolrQueryRequest的httpRequest中……一般自定義的外掛使用這個引數……
o httpCaching:如何處理帶有cache control頭的HTTP請求
nerver304:如果設為true(開發階段),則就算所請求的內容沒被修改,也不會返回304,並且下面兩個引數會失效
lastModFrom:最後修改時間的計算方式,openTime:Searcher啟動的時刻;dirLastMod:索引更新的時刻
etagSeed:HTTP返回的ETag頭內容
cacheControl:HTTP返回的Cache-Control頭內容
<updateProcessor/>和<updateProcessorChain/>標籤:
• 用途:配置處理update請求的處理器、處理器鏈。如果不配置的話,Solr會使用預設的三個處理器:
o LogUpdateProcessorFactory:追蹤和記錄日誌
o DistributedUpdateProcessorFactory:分流update請求到不同的node,
比如SolrCloud的情況下把請求分配給一個shard的leader,然後把更新應用到所有replica中
o RunUpdateProcessorFactory:呼叫Solr的內部API執行update操作
• 如果需要自定義update處理器:
o updateProcessor:
class:負責處理的類
name:名字,給updateProcessorChain引用是使用
o updateProcessorChain:
name:自己的名字標記
processor:指定updateProcessor的name,多個的話用逗號“,”分開