
分散式系統學習筆記
分散式系統
一、什麼是分散式系統?
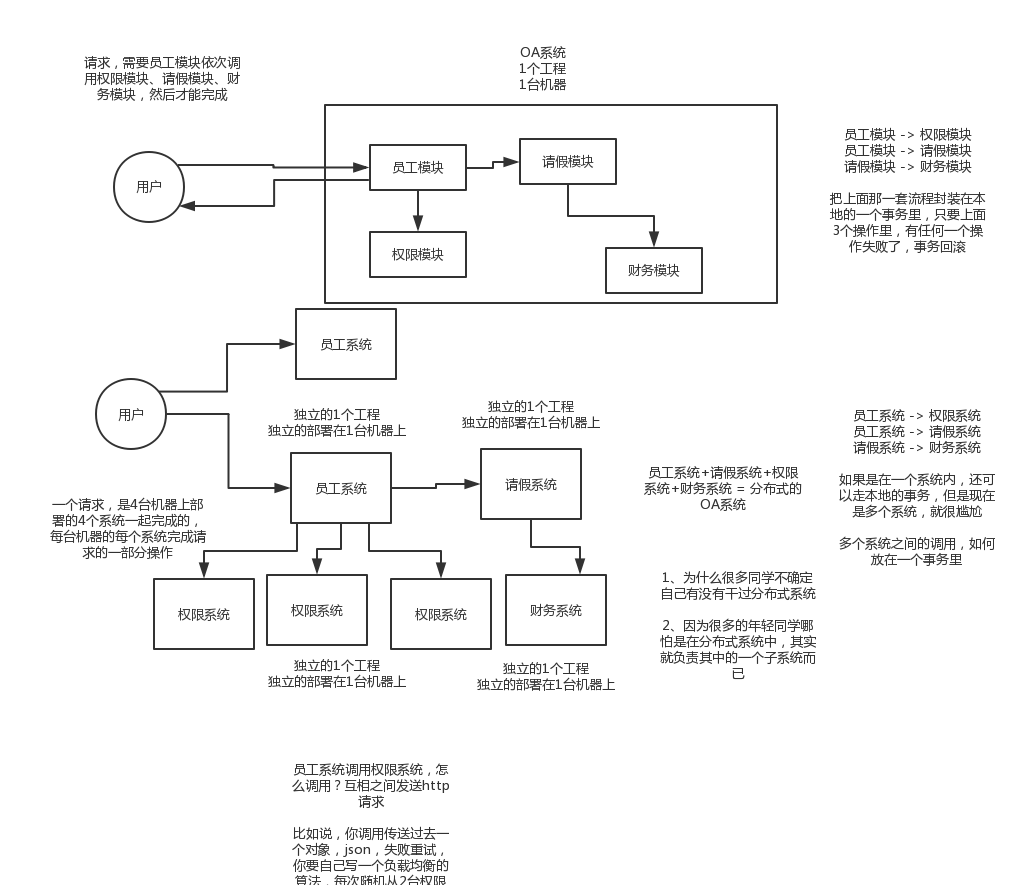
二、為什麼要進行分散式系統的拆分?
1)要是不拆分,一個大系統幾十萬行程式碼,20個人維護一份程式碼,簡直是悲劇啊。程式碼經常改著改著就衝突了,各種程式碼衝突和合並要處理,非常耗費時間;經常我改動了我的程式碼,你呼叫了我,導致你的程式碼也得重新測試,麻煩的要死;然後每次釋出都是幾十萬行程式碼的系統一起釋出,大家得一起提心吊膽準備上線,幾十萬行程式碼的上線,可能每次上線都要做很多的檢查,很多異常問題的處理,簡直是又麻煩又痛苦;而且如果我現在打算把技術升級到最新的spring版本,還不行,因為這可能導致你的程式碼報錯,我不敢隨意亂改技術。
假設一個系統是20萬行程式碼,其中小A在裡面改了1000行程式碼,但是此時釋出的時候是這個20萬行程式碼的大系統一塊兒釋出。就意味著20萬上程式碼在線上就可能出現各種變化,20個人,每個人都要緊張地等在電腦面前,上線之後,檢查日誌,看自己負責的那一塊兒有沒有什麼問題。
小A就檢查了自己負責的1萬行程式碼對應的功能,確保ok就閃人了;結果不巧的是,小A上線的時候不小心修改了線上機器的某個配置,導致另外小B和小C負責的2萬行程式碼對應的一些功能,出錯了
幾十個人負責維護一個幾十萬行程式碼的單塊應用,每次上線,準備幾個禮拜,上線 -> 部署 -> 檢查自己負責的功能
2)拆分了以後,整個世界清爽了,幾十萬行程式碼的系統,拆分成20個服務,平均每個服務就1~2萬行程式碼,每個服務部署到單獨的機器上。20個工程,20個git程式碼倉庫裡,20個碼農,每個人維護自己的那個服務就可以了,是自己獨立的程式碼,跟別人沒關係。再也沒有程式碼衝突了,爽。每次就測試我自己的程式碼就可以了,爽。每次就釋出我自己的一個小服務就可以了,爽。技術上想怎麼升級就怎麼升級,保持介面不變就可以了,爽。
所以簡單來說,一句話總結,如果是那種程式碼量多達幾十萬行的中大型專案,團隊裡有幾十個人,那麼如果不拆分系統,開發效率極其低下,問題很多。但是拆分系統之後,每個人就負責自己的一小部分就好了,可以隨便玩兒隨便弄。分散式系統拆分之後,可以大幅度提升複雜系統大型團隊的開發效率。
三、dubbo
對dubbo熟悉不熟悉:
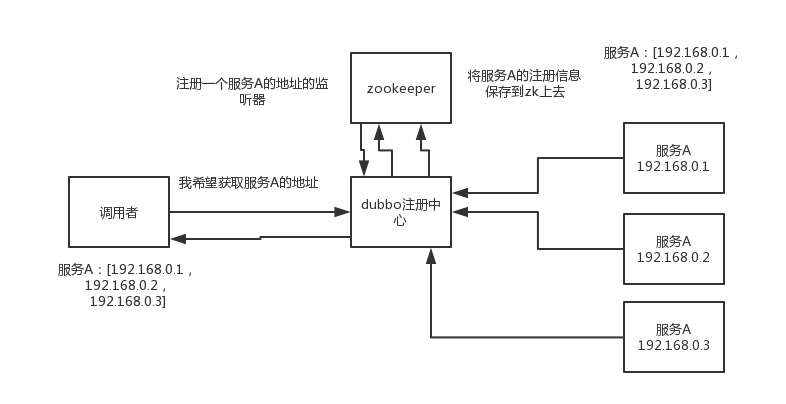
(1)dubbo工作原理:服務註冊,註冊中心,消費者,代理通訊,負載均衡
(2)網路通訊、序列化:dubbo協議,長連線,NIO,hessian序列化協議
(3)負載均衡策略,叢集容錯策略,動態代理策略:dubbo跑起來的時候一些功能是如何運轉的,怎麼做負載均衡?怎麼做叢集容錯?怎麼生成動態代理?
(4)dubbo SPI機制:你瞭解不瞭解dubbo的SPI機制?如何基於SPI機制對dubbo進行擴充套件?
(5)dubbo的服務治理、降級、重試
1. 為什麼要用dubbo?不用dubbo可以嗎?
當然可以了,大不了最次,就是各個系統之間,直接基於spring mvc,就純http介面互相通訊唄,還能咋樣。但是這個肯定是有問題的,因為http介面通訊維護起來成本很高,你要考慮超時重試、負載均衡等等各種亂七八糟的問題,比如說你的訂單系統呼叫商品系統,商品系統部署了5臺機器,你怎麼把請求均勻地甩給那5臺機器?這不就是負載均衡?你要是都自己搞那是可以的,但是確實很痛苦。
所以dubbo說白了,是一種rpc框架,就是本地就是進行介面呼叫,但是dubbo會代理這個呼叫請求,跟遠端機器網路通訊,給你處理掉負載均衡了、服務例項上下線自動感知了、超時重試了,等等亂七八糟的問題。那你就不用自己做了,用dubbo就可以了。
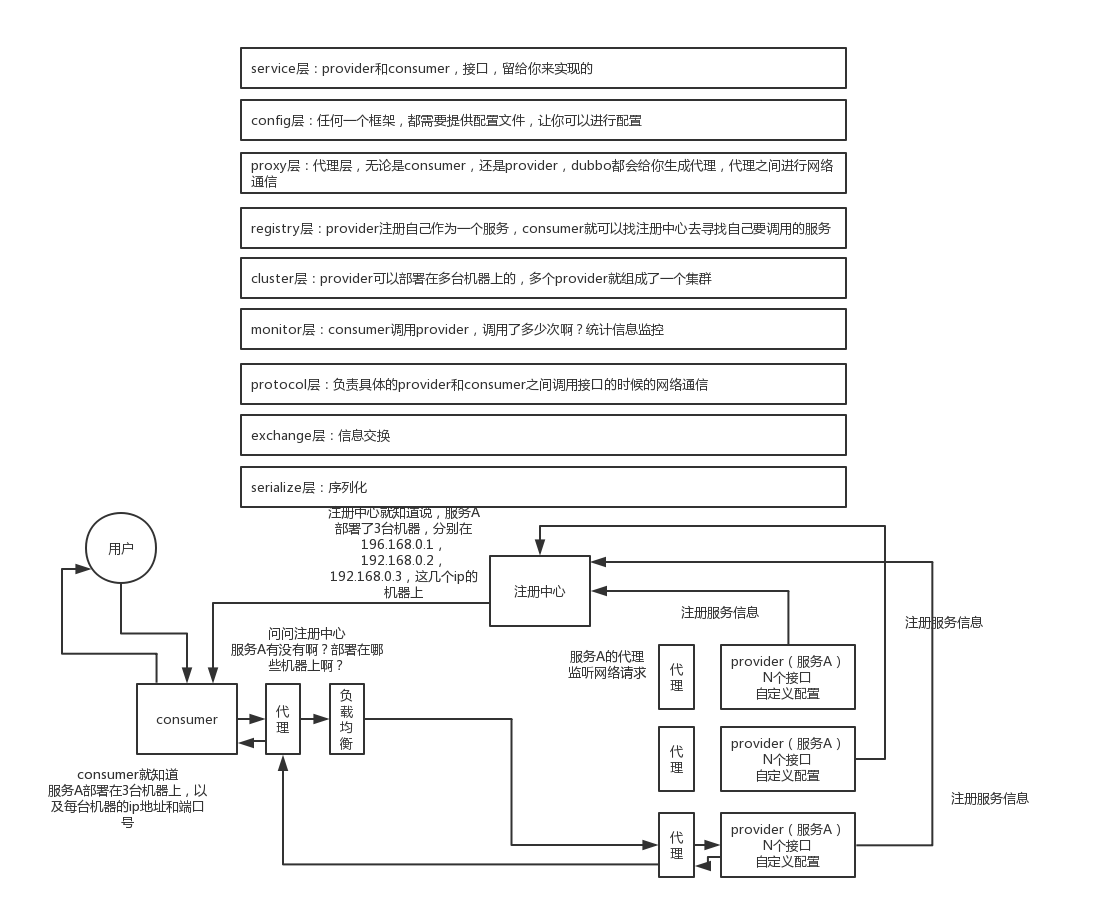
2. dubbo的工作原理
第一層:service層,介面層,給服務提供者和消費者來實現的
第二層:config層,配置層,主要是對dubbo進行各種配置的
第三層:proxy層,服務代理層,透明生成客戶端的stub和服務單的skeleton
第四層:registry層,服務註冊層,負責服務的註冊與發現
第五層:cluster層,叢集層,封裝多個服務提供者的路由以及負載均衡,將多個例項組合成一個服務
第六層:monitor層,監控層,對rpc介面的呼叫次數和呼叫時間進行監控
第七層:protocol層,遠端呼叫層,封裝rpc呼叫
第八層:exchange層,資訊交換層,封裝請求響應模式,同步轉非同步
第九層:transport層,網路傳輸層,抽象mina和netty為統一介面
第十層:serialize層,資料序列化層
工作流程:
1)第一步,provider向註冊中心去註冊
2)第二步,consumer從註冊中心訂閱服務,註冊中心會通知consumer註冊好的服務
3)第三步,consumer呼叫provider
4)第四步,consumer和provider都非同步的通知監控中心
3. dubbo支援的通訊協議以及序列化
(1)dubbo支援不同的通訊協議
1)dubbo協議
預設就是走dubbo協議的,單一長連線,NIO非同步通訊,基於hessian作為序列化協議
適用的場景就是:傳輸資料量很小(每次請求在100kb以內),但是併發量很高
為了要支援高併發場景,一般是服務提供者就幾臺機器,但是服務消費者有上百臺,可能每天呼叫量達到上億次!此時用長連線是最合適的,就是跟每個服務消費者維持一個長連線就可以,可能總共就100個連線。然後後面直接基於長連線NIO非同步通訊,可以支撐高併發請求。
否則如果上億次請求每次都是短連線的話,服務提供者會扛不住。
而且因為走的是單一長連線,所以傳輸資料量太大的話,會導致併發能力降低。所以一般建議是傳輸資料量很小,支撐高併發訪問。
2)rmi協議
走java二進位制序列化,多個短連線,適合消費者和提供者數量差不多,適用於檔案的傳輸,一般較少用
3)hessian協議
走hessian序列化協議,多個短連線,適用於提供者數量比消費者數量還多,適用於檔案的傳輸,一般較少用
4)http協議
走json序列化
5)webservice
走SOAP文字序列化
(2)dubbo支援的序列化協議
所以dubbo實際基於不同的通訊協議,支援hessian、java二進位制序列化、json、SOAP文字序列化多種序列化協議。但是hessian是其預設的序列化協議。
4. dubbo負載均衡以及叢集容錯策略、動態代理
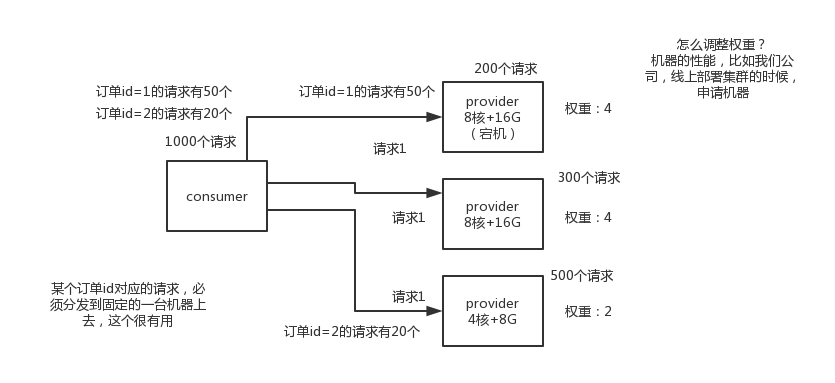
(1)dubbo負載均衡策略
1)random loadbalance
預設情況下,dubbo是random load balance隨機呼叫實現負載均衡,可以對provider不同例項設定不同的權重,會按照權重來負載均衡,權重越大分配流量越高,一般就用這個預設的就可以了。
2)roundrobin loadbalance
這個的話預設就是均勻地將流量打到各個機器上去,但是如果各個機器的效能不一樣,容易導致效能差的機器負載過高。所以此時需要調整權重,讓效能差的機器承載權重小一些,流量少一些。
3)leastactive loadbalance
這個就是自動感知一下,如果某個機器效能越差,那麼接收的請求越少,越不活躍,此時就會給不活躍的效能差的機器更少的請求
4)consistanthash loadbalance
一致性Hash演算法,相同引數的請求一定分發到一個provider上去,provider掛掉的時候,會基於虛擬節點均勻分配剩餘的流量,抖動不會太大。如果你需要的不是隨機負載均衡,是要一類請求都到一個節點,那就走這個一致性hash策略。
(2)dubbo叢集容錯策略
1)failover cluster模式
失敗自動切換,自動重試其他機器,預設就是這個,常見於讀操作
2)failfast cluster模式
一次呼叫失敗就立即失敗,常見於寫操作
3)failsafe cluster模式
出現異常時忽略掉,常用於不重要的介面呼叫,比如記錄日誌
4)failbackc cluster模式
失敗了後臺自動記錄請求,然後定時重發,比較適合於寫訊息佇列這種
5)forking cluster
並行呼叫多個provider,只要一個成功就立即返回
6)broadcacst cluster
逐個呼叫所有的provider
(3)dubbo動態代理策略
預設使用javassist動態位元組碼生成,建立代理類
但是可以通過spi擴充套件機制配置自己的動態代理策略
5. dubbo的SPI原理
spi,簡單來說,就是service provider interface,說白了是什麼意思呢,比如你有個介面,現在這個介面有3個實現類,那麼在系統執行的時候對這個介面到底選擇哪個實現類呢?這就需要spi了,需要根據指定的配置或者是預設的配置,去找到對應的實現類載入進來,然後用這個實現類的例項物件。
比如說你要通過jar包的方式給某個介面提供實現,然後你就在自己jar包的META-INF/services/目錄下放一個跟介面同名的檔案,裡面指定介面的實現裡是自己這個jar包裡的某個類。ok了,別人用了一個介面,然後用了你的jar包,就會在執行的時候通過你的jar包的那個檔案找到這個介面該用哪個實現類。
這是jdk提供的一個功能。
SPI機制,一般來說用在哪兒?外掛擴充套件的場景,比如說你開發的是一個給別人使用的開源框架,如果你想讓別人自己寫個外掛,插到你的開源框架裡面來,擴充套件某個功能。
經典的思想體現,大家平時都在用,比如說jdbc,java定義了一套jdbc的介面,但是java是沒有提供jdbc的實現類。但是實際上專案跑的時候,要使用jdbc介面的哪些實現類呢?一般來說,我們要根據自己使用的資料庫,比如msyql,你就將mysql-jdbc-connector.jar,引入進來;oracle,你就將oracle-jdbc-connector.jar,引入進來。在系統跑的時候,碰到你使用jdbc的介面,他會在底層使用你引入的那個jar中提供的實現類
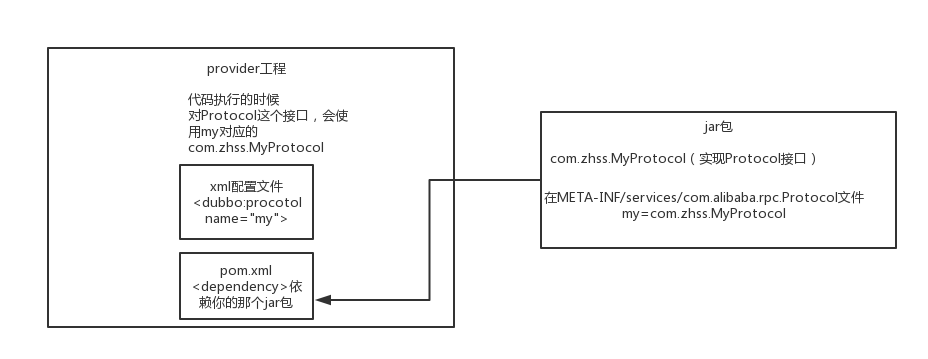
dubbo也用了spi思想,不過沒有用jdk的spi機制,是自己實現的一套spi機制。
Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
Protocol介面,dubbo要判斷一下,在系統執行的時候,應該選用這個Protocol介面的哪個實現類來例項化物件來使用呢?
他會去找一個你配置的Protocol,他就會將你配置的Protocol實現類,載入到jvm中來,然後例項化物件,就用你的那個Protocol實現類就可以了
這行程式碼就是dubbo裡大量使用的,就是對很多元件,都是保留一個介面和多個實現,然後在系統執行的時候動態根據配置去找到對應的實現類。如果你沒配置,那就走預設的實現好了,沒問題。
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
在dubbo自己的jar裡,在/META_INF/dubbo/internal/com.alibaba.dubbo.rpc.Protocol檔案中:
dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol
http=com.alibaba.dubbo.rpc.protocol.http.HttpProtocol
hessian=com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol
所以說,這就看到了dubbo的spi機制預設是怎麼玩兒的了,其實就是Protocol介面,@SPI(“dubbo”)說的是,通過SPI機制來提供實現類,實現類是通過dubbo作為預設key去配置檔案裡找到的,配置檔名稱與介面全限定名一樣的,通過dubbo作為key可以找到預設的實現了就是com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol。
dubbo的預設網路通訊協議,就是dubbo協議,用的DubboProtocol
如果想要動態替換掉預設的實現類,需要使用@Adaptive介面,Protocol介面中,有兩個方法加了@Adaptive註解,就是說那倆介面會被代理實現。
啥意思呢?
比如這個Protocol介面搞了倆@Adaptive註解標註了方法,在執行的時候會針對Protocol生成代理類,這個代理類的那倆方法裡面會有代理程式碼,代理程式碼會在執行的時候動態根據url中的protocol來獲取那個key,預設是dubbo,你也可以自己指定,你如果指定了別的key,那麼就會獲取別的實現類的例項了。
通過這個url中的引數不通,就可以控制動態使用不同的元件實現類
6. dubbo如何做服務治理、服務降級以及重試
(1)服務治理
1)呼叫鏈路自動生成
一個大型的分散式系統,或者說是用現在流行的微服務架構來說吧,分散式系統由大量的服務組成。那麼這些服務之間互相是如何呼叫的?呼叫鏈路是啥?說實話,幾乎到後面沒人搞的清楚了,因為服務實在太多了,可能幾百個甚至幾千個服務。
那就需要基於dubbo做的分散式系統中,對各個服務之間的呼叫自動記錄下來,然後自動將各個服務之間的依賴關係和呼叫鏈路生成出來,做成一張圖,顯示出來,大家才可以看到對吧。
服務A -> 服務B -> 服務C
-> 服務E
-> 服務D
-> 服務F
-> 服務W
2)服務訪問壓力以及時長統計
需要自動統計各個介面和服務之間的呼叫次數以及訪問延時,而且要分成兩個級別。一個級別是介面粒度,就是每個服務的每個介面每天被呼叫多少次,TP50,TP90,TP99,三個檔次的請求延時分別是多少;第二個級別是從源頭入口開始,一個完整的請求鏈路經過幾十個服務之後,完成一次請求,每天全鏈路走多少次,全鏈路請求延時的TP50,TP90,TP99,分別是多少。
這些東西都搞定了之後,後面才可以來看當前系統的壓力主要在哪裡,如何來擴容和優化啊
3)其他的
服務分層(避免迴圈依賴),呼叫鏈路失敗監控和報警,服務鑑權,每個服務的可用性的監控(介面呼叫成功率?幾個9?)99.99%,99.9%,99%
(2)服務降級
比如說服務A呼叫服務B,結果服務B掛掉了,服務A重試幾次呼叫服務B,還是不行,直接降級,走一個備用的邏輯,給使用者返回響應
public interface HelloService {
void sayHello();
}
public class HelloServiceImpl implements HelloService {
public void sayHello() {
System.out.println("hello world......");
}
}
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
<dubbo:application name="dubbo-provider" />
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<dubbo:protocol name="dubbo" port="20880" />
<dubbo:service interface="com.zhss.service.HelloService" ref="helloServiceImpl" timeout="10000" />
<bean id="helloServiceImpl" class="com.zhss.service.HelloServiceImpl" />
</beans>
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
<dubbo:application name="dubbo-consumer" />
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<dubbo:reference id="fooService" interface="com.test.service.FooService" timeout="10000" check="false" mock="return null">
</dubbo:reference>
</beans>
現在就是mock,如果呼叫失敗統一返回null
但是可以將mock修改為true,然後在跟介面同一個路徑下實現一個Mock類,命名規則是介面名稱加Mock字尾。然後在Mock類裡實現自己的降級邏輯。
public class HelloServiceMock implements HelloService {
public void sayHello() {
// 降級邏輯
}
}
(3)失敗重試和超時重試
所謂失敗重試,就是consumer呼叫provider要是失敗了,比如拋異常了,此時應該是可以重試的,或者呼叫超時了也可以重試。
<dubbo:reference id="xxxx" interface="xx" check="true" async="false" retries="3" timeout="2000"/>
某個服務的介面,要耗費5s,你這邊不能幹等著,你這邊配置了timeout之後,我等待2s,還沒返回,我直接就撤了,不能幹等你
如果是超時了,timeout就會設定超時時間;如果是呼叫失敗了自動就會重試指定的次數
你就結合你們公司的具體的場景來說說你是怎麼設定這些引數的,timeout,一般設定為200ms,我們認為不能超過200ms還沒返回
retries,3次,設定retries,還一般是在讀請求的時候,比如你要查詢個數據,你可以設定個retries,如果第一次沒讀到,報錯,重試指定的次數,嘗試再次讀取2次
7. 分散式服務介面的冪等性如何設計
其實保證冪等性主要是三點:
(1)對於每個請求必須有一個唯一的標識,舉個例子:訂單支付請求,肯定得包含訂單id,一個訂單id最多支付一次,對吧
(2)每次處理完請求之後,必須有一個記錄標識這個請求處理過了,比如說常見的方案是在mysql中記錄個狀態啥的,比如支付之前記錄一條這個訂單的支付流水,而且支付流水採
(3)每次接收請求需要進行判斷之前是否處理過的邏輯處理,比如說,如果有一個訂單已經支付了,就已經有了一條支付流水,那麼如果重複傳送這個請求,則此時先插入支付流水,orderId已經存在了,唯一鍵約束生效,報錯插入不進去的。然後你就不用再扣款了。
上面只是給大家舉個例子,實際運作過程中,你要結合自己的業務來,比如說用redis用orderId作為唯一鍵。只有成功插入這個支付流水,才可以執行實際的支付扣款。
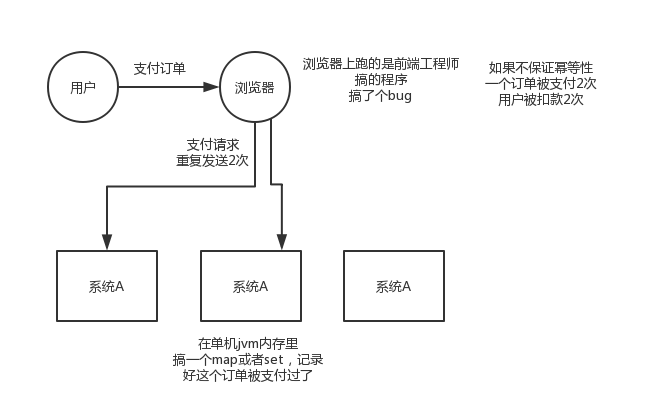
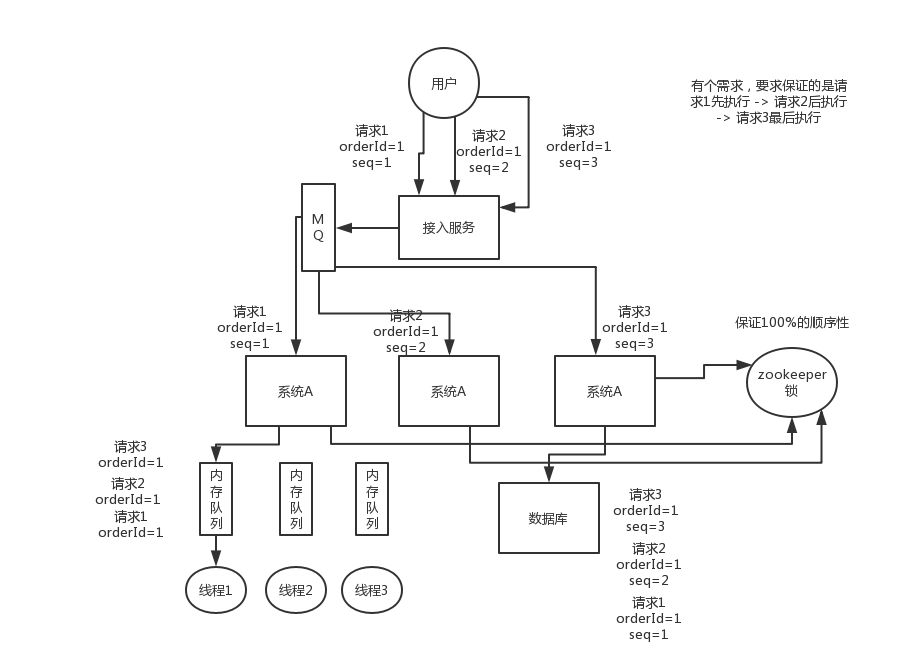
8. 分散式服務介面請求的順序性如何保證
首先,一般來說,我個人給你的建議是,你們從業務邏輯上最好設計的這個系統不需要這種順序性的保證,因為一旦引入順序性保障,會導致系統複雜度上升,而且會帶來效率低下,熱點資料壓力過大,等問題。
下面我給個我們用過的方案吧,簡單來說,首先你得用dubbo的一致性hash負載均衡策略,將比如某一個訂單id對應的請求都給分發到某個機器上去,接著就是在那個機器上因為可能還是多執行緒併發執行的,你可能得立即將某個訂單id對應的請求扔一個記憶體佇列裡去,強制排隊,這樣來確保他們的順序性。
四、zookepper
1. zookeeper一般都有哪些使用場景
(1)分散式協調
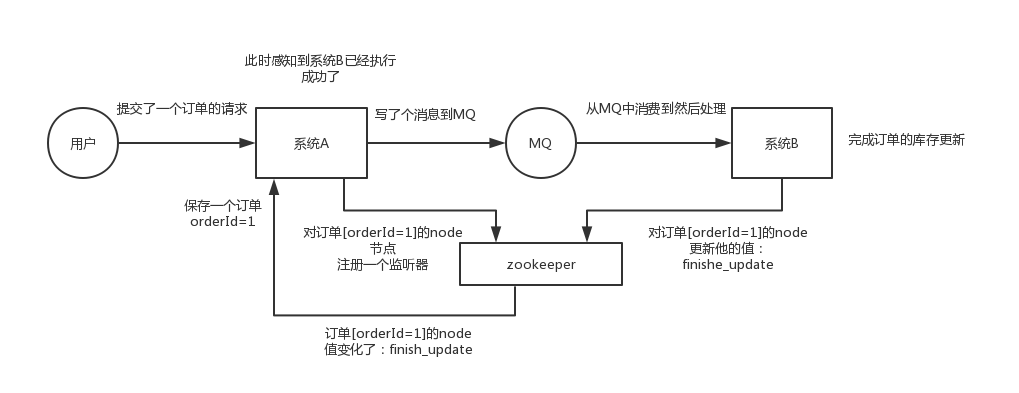
這個其實是zk很經典的一個用法,簡單來說,就好比,你A系統傳送個請求到mq,然後B訊息消費之後處理了。那A系統如何知道B系統的處理結果?用zk就可以實現分散式系統之間的協調工作。A系統傳送請求之後可以在zk上對某個節點的值註冊個監聽器,一旦B系統處理完了就修改zk那個節點的值,A立馬就可以收到通知,完美解決。
(2)分散式鎖
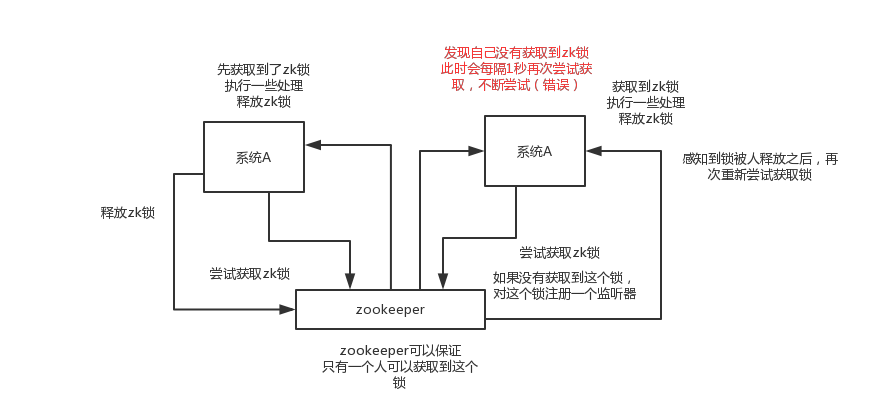
對某一個數據連續發出兩個修改操作,兩臺機器同時收到了請求,但是隻能一臺機器先執行另外一個機器再執行。那麼此時就可以使用zk分散式鎖,一個機器接收到了請求之後先獲取zk上的一把分散式鎖,就是可以去建立一個znode,接著執行操作;然後另外一個機器也嘗試去建立那個znode,結果發現自己建立不了,因為被別人建立了。。。。那隻能等著,等第一個機器執行完了自己再執行。
(3)元資料/配置資訊管理
zk可以用作很多系統的配置資訊的管理,比如kafka、storm等等很多分散式系統都會選用zk來做一些元資料、配置資訊的管理,包括dubbo註冊中心不也支援zk麼
(4)HA高可用性
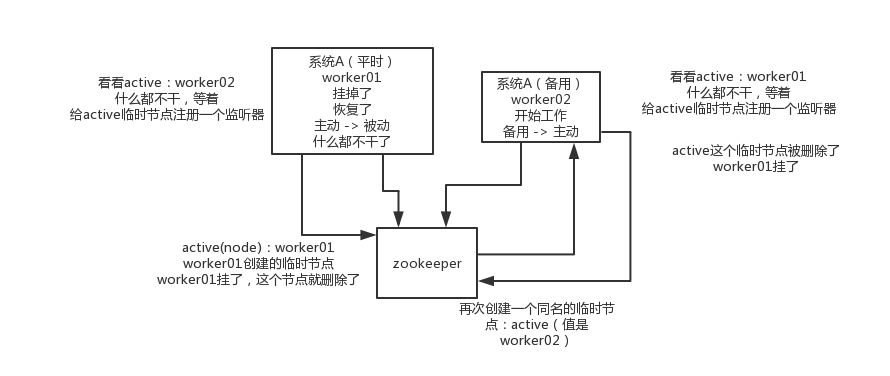
這個應該是很常見的,比如hadoop、hdfs、yarn等很多大資料系統,都選擇基於zk來開發HA高可用機制,就是一個重要程序一般會做主備兩個,主程序掛了立馬通過zk感知到切換到備用程序
2. 分散式鎖是啥?對比下redis和zk兩種分散式鎖的優劣?
(1)redis分散式鎖
官方叫做RedLock演算法,是redis官方支援的分散式鎖演算法。
這個分散式鎖有3個重要的考量點,互斥(只能有一個客戶端獲取鎖),不能死鎖,容錯(大部分redis節點或者這個鎖就可以加可以釋放)
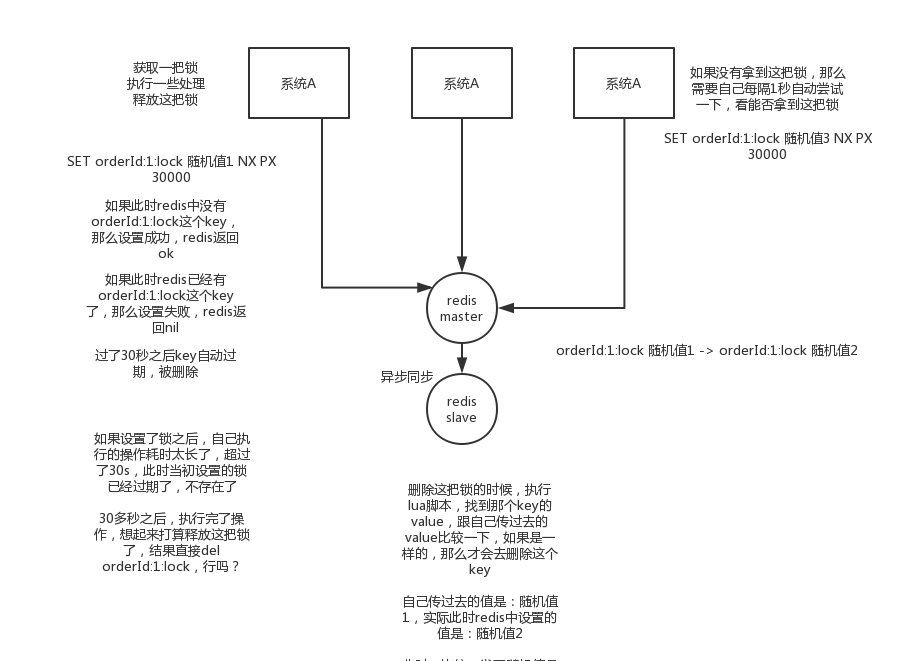
第一個最普通的實現方式,如果就是在redis裡建立一個key算加鎖,SET my:lock 隨機值 NX PX 30000,這個命令就ok,這個的NX的意思就是隻有key不存在的時候才會設定成功,PX 30000的意思是30秒後鎖自動釋放。別人建立的時候如果發現已經有了就不能加鎖了。
釋放鎖就是刪除key,但是一般可以用lua指令碼刪除,判斷value一樣才刪除:
關於redis如何執行lua指令碼,自行百度
if redis.call(“get”,KEYS[1]) == ARGV[1] then
return redis.call(“del”,KEYS[1])
else
return 0
end
為啥要用隨機值呢?因為如果某個客戶端獲取到了鎖,但是阻塞了很長時間才執行完,此時可能已經自動釋放鎖了,此時可能別的客戶端已經獲取到了這個鎖,要是你這個時候直接刪除key的話會有問題,所以得用隨機值加上面的lua指令碼來釋放鎖。
但是這樣是肯定不行的。因為如果是普通的redis單例項,那就是單點故障。或者是redis普通主從,那redis主從非同步複製,如果主節點掛了,key還沒同步到從節點,此時從節點切換為主節點,別人就會拿到鎖。
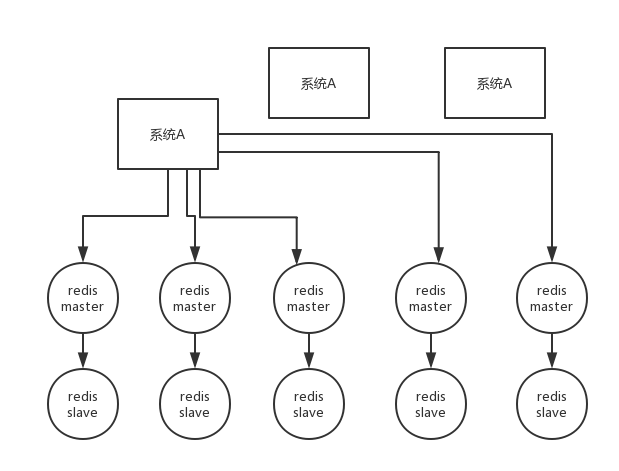
第二個問題,RedLock演算法
這個場景是假設有一個redis cluster,有5個redis master例項。然後執行如下步驟獲取一把鎖:
-
1)獲取當前時間戳,單位是毫秒
-
2)跟上面類似,輪流嘗試在每個master節點上建立鎖,過期時間較短,一般就幾十毫秒
-
3)嘗試在大多數節點上建立一個鎖,比如5個節點就要求是3個節點(n / 2 +1)
-
4)客戶端計算建立好鎖的時間,如果建立鎖的時間小於超時時間,就算建立成功了
-
5)要是鎖建立失敗了,那麼就依次刪除這個鎖
-
6)只要別人建立了一把分散式鎖,你就得不斷輪詢去嘗試獲取鎖
(2)zk分散式鎖
zk分散式鎖,其實可以做的比較簡單,就是某個節點嘗試建立臨時znode,此時建立成功了就獲取了這個鎖;這個時候別的客戶端來建立鎖會失敗,只能註冊個監聽器監聽這個鎖。釋放鎖就是刪除這個znode,一旦釋放掉就會通知客戶端,然後有一個等待著的客戶端就可以再次重新枷鎖。
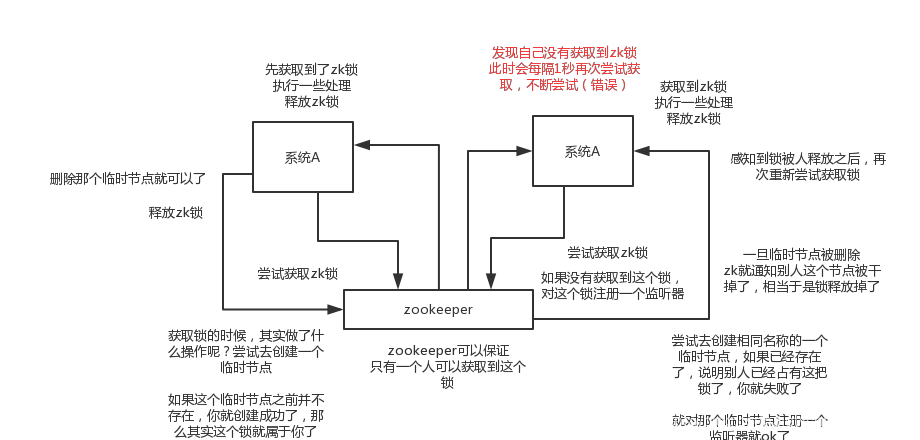
(3)redis分散式鎖和zk分散式鎖的對比
redis分散式鎖,其實需要自己不斷去嘗試獲取鎖,比較消耗效能
zk分散式鎖,獲取不到鎖,註冊個監聽器即可,不需要不斷主動嘗試獲取鎖,效能開銷較小
另外一點就是,如果是redis獲取鎖的那個客戶端bug了或者掛了,那麼只能等待超時時間之後才能釋放鎖;而zk的話,因為建立的是臨時znode,只要客戶端掛了,znode就沒了,此時就自動釋放鎖
redis分散式鎖大家每發現好麻煩嗎?遍歷上鎖,計算時間等等。。。zk的分散式鎖語義清晰實現簡單
所以先不分析太多的東西,就說這兩點,我個人實踐認為zk的分散式鎖比redis的分散式鎖牢靠、而且模型簡單易用
五、session
1. 分散式session方案是啥?
常見常用的是兩種:
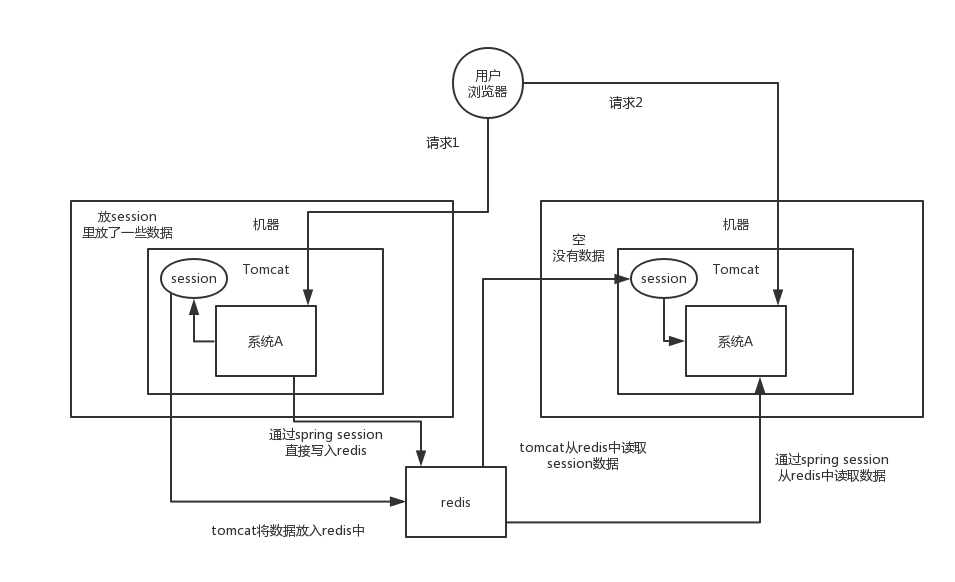
(1)tomcat + redis
這個其實還挺方便的,就是使用session的程式碼跟以前一樣,還是基於tomcat原生的session支援即可,然後就是用一個叫做Tomcat RedisSessionManager的東西,讓所有我們部署的tomcat都將session資料儲存到redis即可。
在tomcat的配置檔案中,配置一下
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager"
host="{redis.host}"
port="{redis.port}"
database="{redis.dbnum}"
maxInactiveInterval="60"/>
<!--搞一個類似上面的配置即可,你看是不是就是用了RedisSessionManager,然後指定了redis的host和 port就ok了。-->
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager"
sentinelMaster="mymaster"
sentinels="<sentinel1-ip>:26379,<sentinel2-ip>:26379,<sentinel3-ip>:26379"
maxInactiveInterval="60"/>
還可以用上面這種方式基於redis哨兵支援的redis高可用叢集來儲存session資料,都是ok的
(2)spring session + redis
分散式會話的這個東西重耦合在tomcat中,如果我要將web容器遷移成jetty,難道你重新把jetty都配置一遍嗎?
因為上面那種tomcat + redis的方式好用,但是會嚴重依賴於web容器,不好將程式碼移植到其他web容器上去,尤其是你要是換了技術棧咋整?比如換成了spring cloud或者是spring boot之類的。還得好好思忖思忖。
所以現在比較好的還是基於java一站式解決方案,spring了。人家spring基本上包掉了大部分的我們需要使用的框架了,spirng cloud做微服務了,spring boot做腳手架了,所以用sping session是一個很好的選擇。
六、分散式事務
1. 單系統與分散式
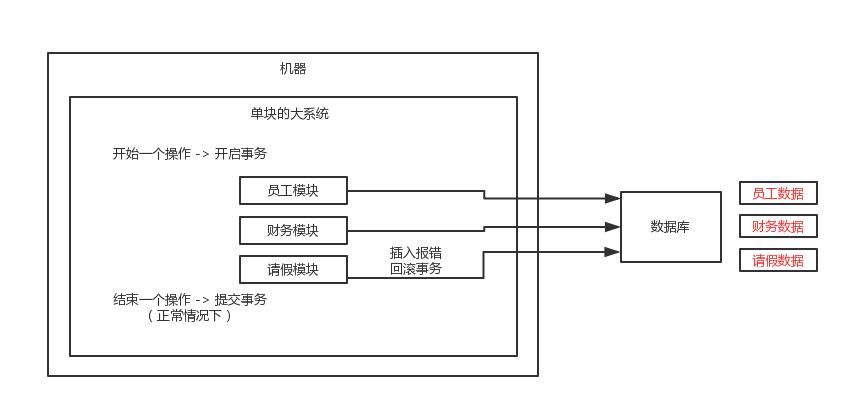
1.1 但系統中的事務
1.2 分散式系統中的事務
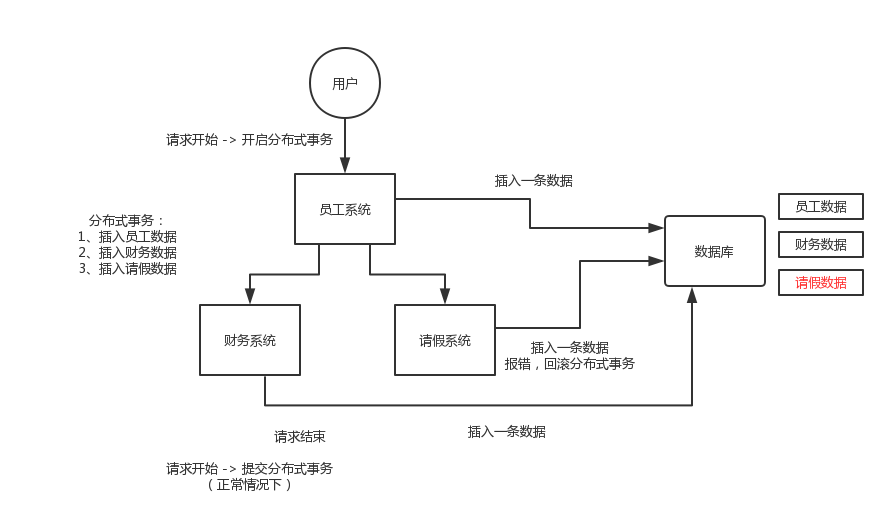
2. 常見的分散式事務解決方案
(1)兩階段提交方案/XA方案
也叫做兩階段提交事務方案,這個舉個例子,比如說咱們公司裡經常tb是吧(就是團建),然後一般會有個tb主席(就是負責組織團建的那個人)。
第一個階段,一般tb主席會提前一週問一下團隊裡的每個人,說,大傢伙,下週六我們去滑雪+燒烤,去嗎?這個時候tb主席開始等待每個人的回答,如果所有人都說ok,那麼就可以決定一起去這次tb。如果這個階段裡,任何一個人回答說,我有事不去了,那麼tb主席就會取消這次活動。
第二個階段,那下週六大家就一起去滑雪+燒烤了
所以這個就是所謂的XA事務,兩階段提交,有一個事務管理器的概念,負責協調多個數據庫(資源管理器)的事務,事務管理器先問問各個資料庫你準備好了嗎?如果每個資料庫都回復ok,那麼就正式提交事務,在各個資料庫上執行操作;如果任何一個數據庫回答不ok,那麼就回滾事務。
這種分散式事務方案,比較適合單塊應用裡,跨多個庫的分散式事務,而且因為嚴重依賴於資料庫層面來搞定複雜的事務,效率很低,絕對不適合高併發的場景.
這個方案,我們很少用,一般來說某個系統內部如果出現跨多個庫的這麼一個操作,是不合規的。
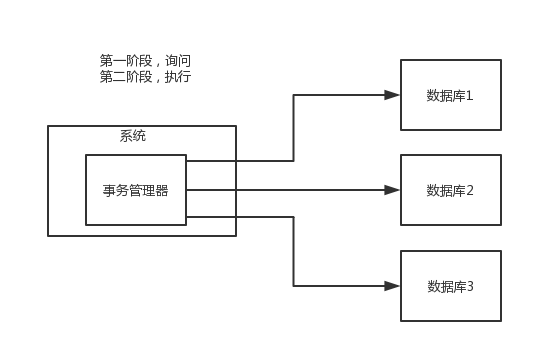
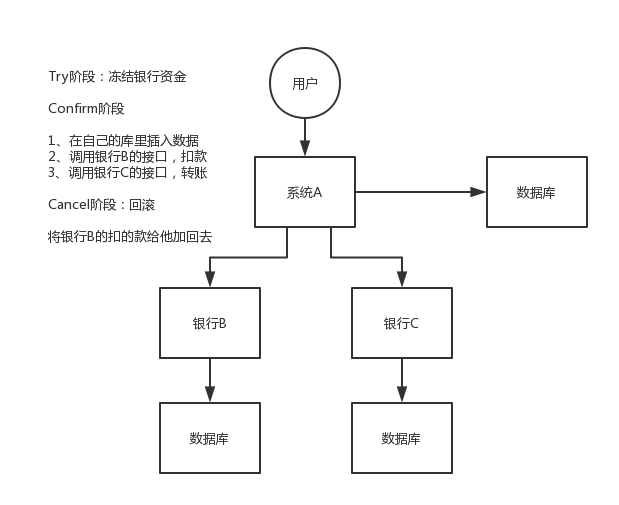
(2)TCC方案
TCC的全程是:Try、Confirm、Cancel。
這個其實是用到了補償的概念,分為了三個階段:
1)Try階段:這個階段說的是對各個服務的資源做檢測以及對資源進行鎖定或者預留
2)Confirm階段:這個階段說的是在各個服務中執行實際的操作
3)Cancel階段:如果任何一個服務的業務方法執行出錯,那麼這裡就需要進行補償,就是執行已經執行成功的業務邏輯的回滾操作
給大家舉個例子吧,比如說跨銀行轉賬的時候,要涉及到兩個銀行的分散式事務,如果用TCC方案來實現,思路是這樣的:
1)Try階段:先把兩個銀行賬戶中的資金給它凍結住就不讓操作了
2)Confirm階段:執行實際的轉賬操作,A銀行賬戶的資金扣減,B銀行賬戶的資金增加
3)Cancel階段:如果任何一個銀行的操作執行失敗,那麼就需要回滾進行補償,就是比如A銀行賬戶如果已經扣減了,但是B銀行賬戶資金增加失敗了,那麼就得把A銀行賬戶資金給加回去
這種方案說實話幾乎很少用人使用,我們用的也比較少,但是也有使用的場景。因為這個事務回滾實際上是嚴重依賴於你自己寫程式碼來回滾和補償了,會造成補償程式碼巨大,非常之噁心。
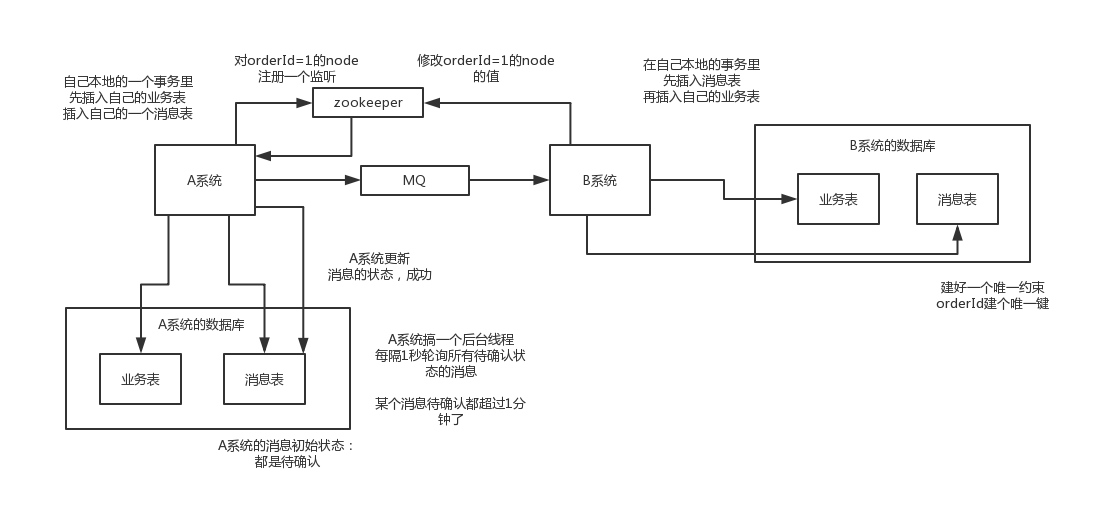
(3)本地訊息表
國外的ebay搞出來的這麼一套思想
這個大概意思是這樣的
1)A系統在自己本地一個事務裡操作同時,插入一條資料到訊息表
2)接著A系統將這個訊息傳送到MQ中去
3)B系統接收到訊息之後,在一個事務裡,往自己本地訊息表裡插入一條資料,同時執行其他的業務操作,如果這個訊息已經被處理過了,那麼此時這個事務會回滾,這樣保證不會重複處理訊息
4)B系統執行成功之後,就會更新自己本地訊息表的狀態以及A系統訊息表的狀態
5)如果B系統處理失敗了,那麼就不會更新訊息表狀態,那麼此時A系統會定時掃描自己的訊息表,如果有沒處理的訊息,會再次傳送到MQ中去,讓B再次處理
6)這個方案保證了最終一致性,哪怕B事務失敗了,但是A會不斷重發訊息,直到B那邊成功為止
這個方案說實話最大的問題就在於嚴重依賴於資料庫的訊息表來管理事務啥的???這個會導致如果是高併發場景咋辦呢?咋擴充套件呢?所以一般確實很少用
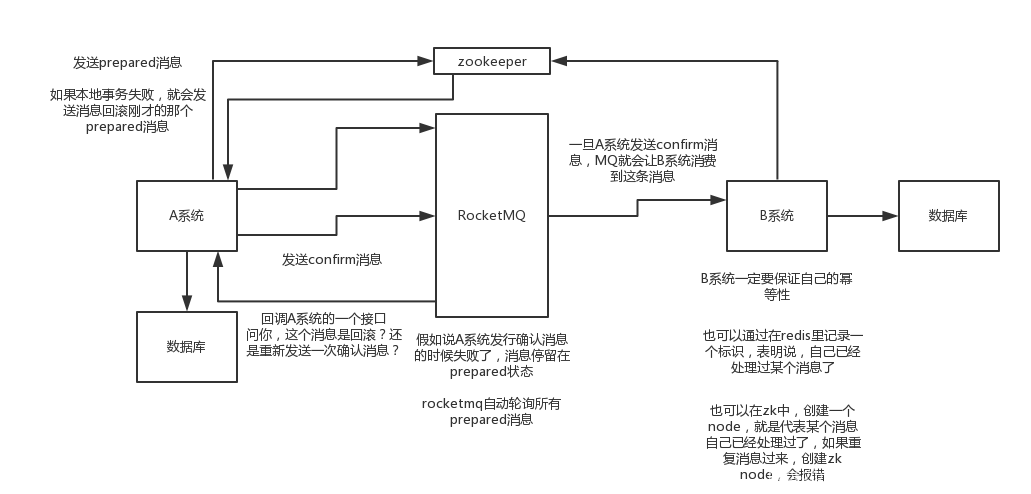
(4)可靠訊息最終一致性方案
這個的意思,就是乾脆不要用本地的訊息表了,直接基於MQ來實現事務。比如阿里的RocketMQ就支援訊息事務。
大概的意思就是:
1)A系統先發送一個prepared訊息到mq,如果這個prepared訊息傳送失敗那麼就直接取消操作別執行了
2)如果這個訊息傳送成功過了,那麼接著執行本地事務,如果成功就告訴mq傳送確認訊息,如果失敗就告訴mq回滾訊息
3)如果傳送了確認訊息,那麼此時B系統會接收到確認訊息,然後執行本地的事務
4)mq會自動定時輪詢所有prepared訊息回撥你的介面,問你,這個訊息是不是本地事務處理失敗了,所有沒傳送確認訊息?那是繼續重試還是回滾?一般來說這裡你就可以查下資料庫看之前本地事務是否執行,如果回滾了,那麼這裡也回滾吧。這個就是避免可能本地事務執行成功了,別確認訊息傳送失敗了。
5)這個方案裡,要是系統B的事務失敗了咋辦?重試咯,自動不斷重試直到成功,如果實在是不行,要麼就是針對重要的資金類業務進行回滾,比如B系統本地回滾後,想辦法通知系統A也回滾;或者是傳送報警由人工來手工回滾和補償
這個還是比較合適的,目前國內網際網路公司大都是這麼玩兒的,要不你舉用RocketMQ支援的,要不你就自己基於類似ActiveMQ?RabbitMQ?自己封裝一套類似的邏輯出來,總之思路就是這樣子的
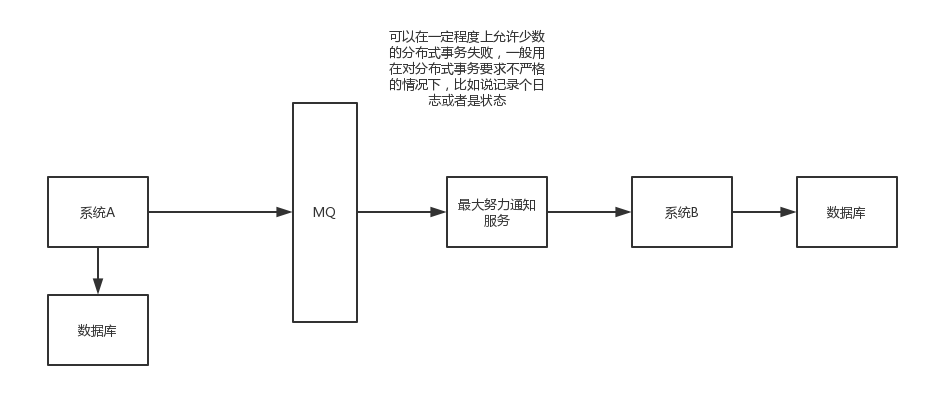
(5)最大努力通知方案
這個方案的大致意思就是:
1)系統A本地事務執行完之後,傳送個訊息到MQ
2)這裡會有個專門消費MQ的最大努力通知服務,這個服務會消費MQ然後寫入資料庫中記錄下來,或者是放入個記憶體佇列也可以,接著呼叫系統B的介面
3)要是系統B執行成功就ok了;要是系統B執行失敗了,那麼最大努力通知服務就定時嘗試重新呼叫系統B,反覆N次,最後還是不行就放棄
六、分庫分表
1. 用過哪些分庫分表中介軟體?不同的分庫分表中介軟體都有什麼優點和缺點?
比較常見的包括:cobar、TDDL、atlas、sharding-jdbc、mycat
- cobar:阿里b2b團隊開發和開源的,屬於proxy層方案。早些年還可以用,但是最近幾年都沒更新了,基本沒啥人用,差不多算是被拋棄的狀態吧。而且不支援讀寫分離、儲存過程、跨庫join和分頁等操作。
- TDDL:淘寶團隊開發的,屬於client層方案。不支援join、多表查詢等語法,就是基本的crud語法是ok,但是支援讀寫分離。目前使用的也不多,因為還依賴淘寶的diamond配置管理系統
- atlas:360開源的,屬於proxy層方案,以前是有一些公司在用的,但是確實有一個很大的問題就是社群最新的維護都在5年前了。所以,現在用的公司基本也很少了。
- sharding-jdbc:噹噹開源的,屬於client層方案。確實之前用的還比較多一些,因為SQL語法支援也比較多,沒有太多限制,而且目前推出到了2.0版本,支援分庫分表、讀寫分離、分散式id生成、柔性事務(最大努力送達型事務、TCC事務)。而且確實之前使用的公司會比較多一些(這個在官網有登記使用的公司,可以看到從2017年一直到現在,是不少公司在用的),目前社群也還一直在開發和維護,還算是比較活躍,個人認為算是一個現在也可以選擇的方案。
- mycat:基於cobar改造的,屬於proxy層方案,支援的功能非常完善,而且目前應該是非常火的而且不斷流行的資料庫中介軟體,社群很活躍,也有一些公司開始在用了。但是確實相比於sharding jdbc來說,年輕一些,經歷的錘鍊少一些。
所以綜上所述,現在其實建議考量的,就是sharding-jdbc和mycat,這兩個都可以去考慮使用。
2. 你們具體是如何對資料庫如何進行垂直拆分或水平拆分的?
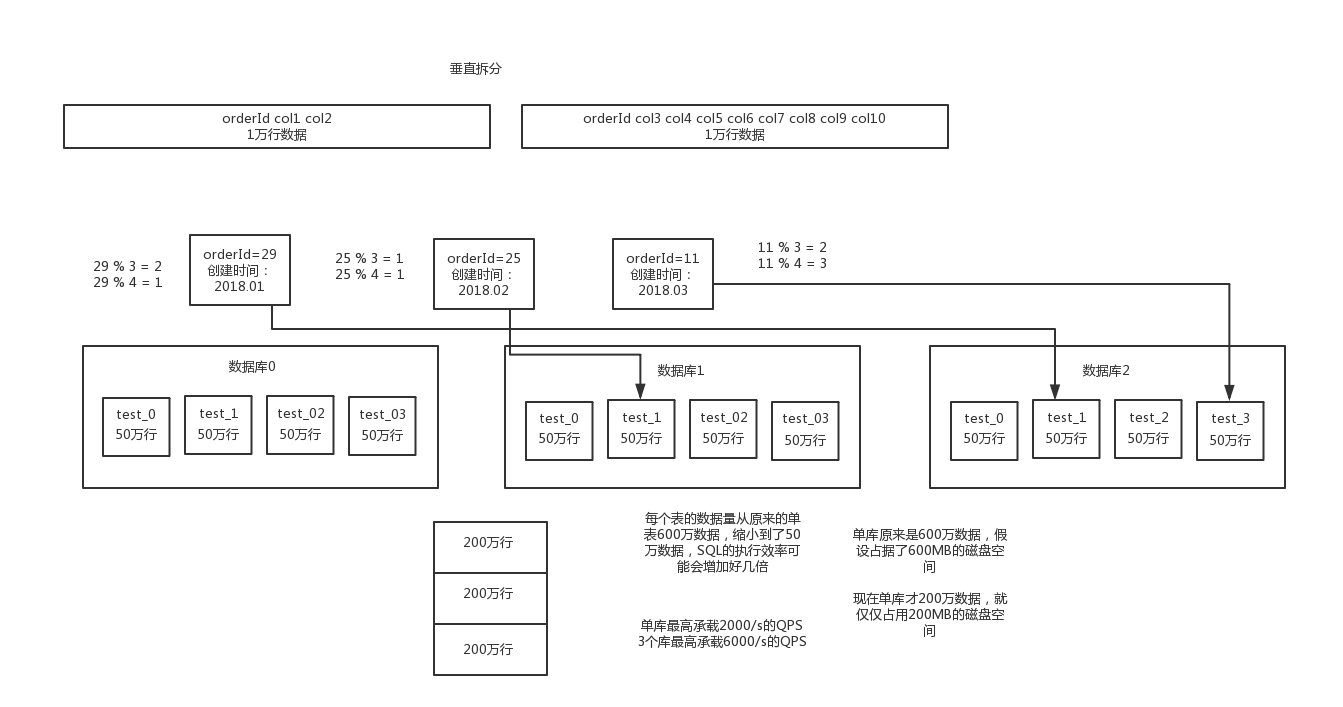
水平拆分的意思,就是把一個表的資料給弄到多個庫的多個表裡去,但是每個庫的表結構都一樣,只不過每個庫表放的資料是不同的,所有庫表的資料加起來就是全部資料。水平拆分的意義,就是將資料均勻放更多的庫裡,然後用多個庫來抗更高的併發,還有就是用多個庫的儲存容量來進行擴容。
垂直拆分的意思,就是把一個有很多欄位的表給拆分成多個表,或者是多個庫上去。每個庫表的結構都不一樣,每個庫表都包含部分欄位。一般來說,會將較少的訪問頻率很高的欄位放到一個表裡去,然後將較多的訪問頻率很低的欄位放到另外一個表裡去。因為資料庫是有快取的,你訪問頻率高的行欄位越少,就可以在快取裡快取更多的行,效能就越好。這個一般在表層面做的較多一些。
這個其實挺常見的,不一定我說,大家很多同學可能自己都做過,把一個大表拆開,訂單表、訂單支付表、訂單商品表。
還有表層面的拆分,就是分表,將一個表變成N個表,就是讓每個表的資料量控制在一定範圍內,保證SQL的效能。否則單表資料量越大,SQL效能就越差。一般是200萬行左右,不要太多,但是也得看具體你怎麼操作,也可能是500萬,或者是100萬。你的SQL越複雜,就最好讓單錶行數越少。
好了,無論是分庫了還是分表了,上面說的那些資料庫中介軟體都是可以支援的。就是基本上那些中介軟體可以做到你分庫分表之後,中介軟體可以根據你指定的某個欄位值,比如說userid,自動路由到對應的庫上去,然後再自動路由到對應的表裡去。
你就得考慮一下,你的專案裡該如何分庫分表?一般來說,垂直拆分,你可以在表層面來做,對一些欄位特別多的表做一下拆分;水平拆分,你可以說是併發承載不了,或者是資料量太大,容量承載不了,你給拆了,按什麼欄位來拆,你自己想好;分表,你考慮一下,你如果哪怕是拆到每個庫裡去,併發和容量都ok了,但是每個庫的表還是太大了,那麼你就分表,將這個表分開,保證每個表的資料量並不是很大。
而且這兒還有兩種分庫分表的方式,一種是按照range來分,就是每個庫一段連續的資料,這個一般是按比如時間範圍來的,但是這種一般較少用,因為很容易產生熱點問題,大量的流量都打在最新的資料上了;或者是按照某個欄位hash一下均勻分散,這個較為常用。
range來分,好處在於說,後面擴容的時候,就很容易,因為你只要預備好,給每個月都準備一個庫就可以了,到了一個新的月份的時候,自然而然,就會寫新的庫了;缺點,但是大部分的請求,都是訪問最新的資料。實際生產用range,要看場景,你的使用者不是僅僅訪問最新的資料,而是均勻的訪問現在的資料以及歷史的資料
hash分法,好處在於說,可以平均分配沒給庫的資料量和請求壓力;壞處在於說擴容起來比較麻煩,會有一個數據遷移的這麼一個過程
3. 如何把系統遷移到分庫分表
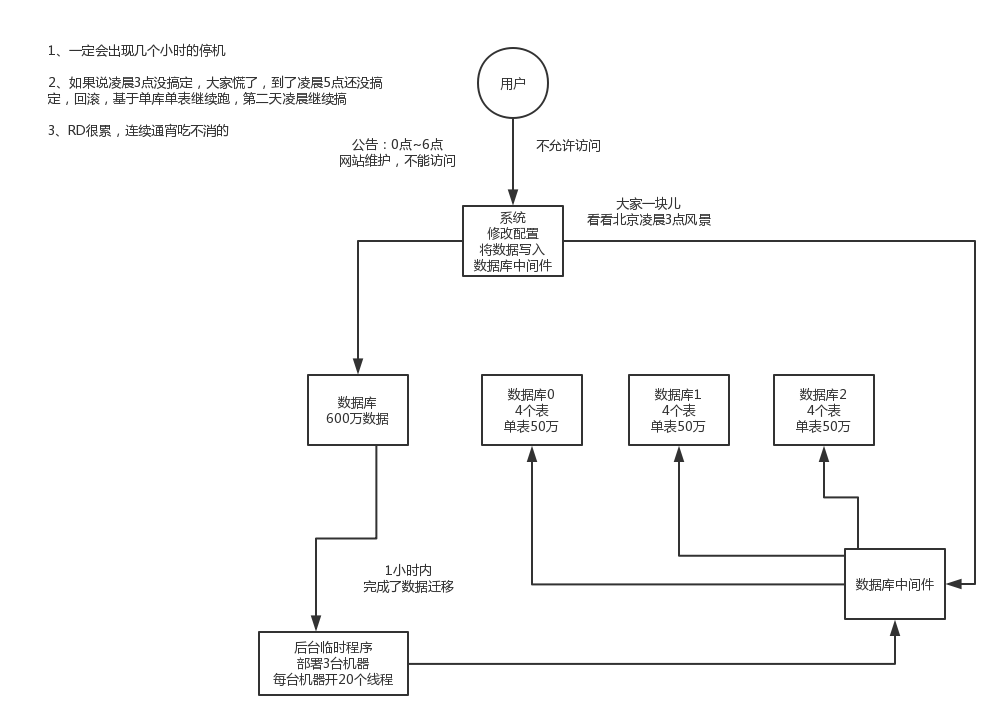
(1)停機遷移方案
我先給你說一個最low的方案,就是很簡單,大家夥兒凌晨12點開始運維,網站或者app掛個公告,說0點到早上6點進行運維,無法訪問。。。。。。
接著到0點,停機,系統挺掉,沒有流量寫入了,此時老的單庫單表資料庫靜止了。然後你之前得寫好一個導數的一次性工具,此時直接跑起來,然後將單庫單表的資料嘩嘩譁讀出來,寫到分庫分表裡面去。
導數完了之後,就ok了,修改系統的資料庫連線配置啥的,包括可能程式碼和SQL也許有修改,那你就用最新的程式碼,然後直接啟動連到新的分庫分表上去。
驗證一下,ok了,完美,大家伸個懶腰,看看看凌晨4點鐘的北京夜景,打個滴滴回家吧
但是這個方案比較low,誰都能幹,我們來看看高大上一點的方案
(2)雙寫遷移方案
這個是我們常用的一種遷移方案,比較靠譜一些,不用停機,不用看北京凌晨4點的風景
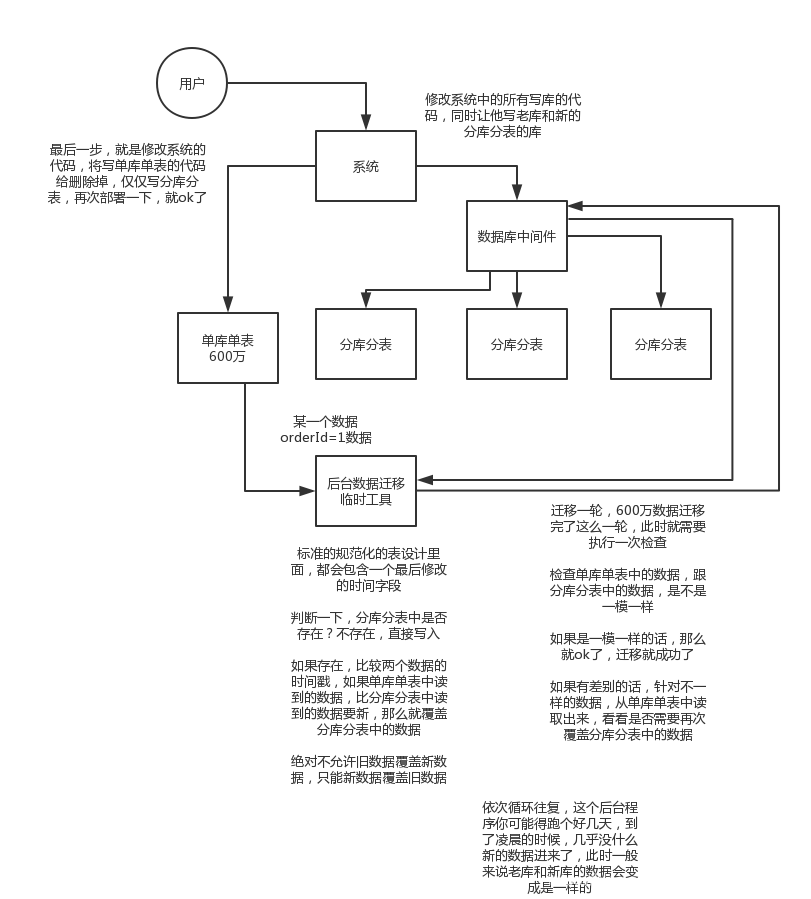
簡單來說,就是在線上系統裡面,之前所有寫庫的地方,增刪改操作,都除了對老庫增刪改,都加上對新庫的增刪改,這就是所謂雙寫,同時寫倆庫,老庫和新庫。
然後系統部署之後,新庫資料差太遠,用之前說的導數工具,跑起來讀老庫資料寫新庫,寫的時候要根據gmt_modified這類欄位判斷這條資料最後修改的時間,除非是讀出來的資料在新庫裡沒有,或者是比新庫的資料新才會寫。
接著導萬一輪之後,有可能資料還是存在不一致,那麼就程式自動做一輪校驗,比對新老庫每個表的每條資料,接著如果有不一樣的,就針對那些不一樣的,從老庫讀資料再次寫。反覆迴圈,直到兩個庫每個表的資料都完全一致為止。
接著當資料完全一致了,就ok了,基於僅僅使用分庫分表的最新程式碼,重新部署一次,不就僅僅基於分庫分表在操作了麼,還沒有幾個小時的停機時間,很穩。所以現在基本玩兒資料遷移之類的,都是這麼幹了。
4. 如何設計可以動態擴容縮容的分庫分表方案
一開始上來就是32個庫,每個庫32個表,1024張表
我可以告訴各位同學說,這個分法,第一,基本上國內的網際網路肯定都是夠用了,第二,無論是併發支撐還是資料量支撐都沒問題
每個庫正常承載的寫入併發量是1000,那麼32個庫就可以承載32 * 1000 = 32000的寫併發,如果每個庫承載1500的寫併發,32 * 1500 = 48000的寫併發,接近5萬/s的寫入併發,前面再加一個MQ,削峰,每秒寫入MQ 8萬條資料,每秒消費5萬條資料。
有些除非是國內排名非常靠前的這些公司,他們的最核心的系統的資料庫,可能會出現幾百臺數據庫的這麼一個規模,128個庫,256個庫,512個庫
1024張表,假設每個表放500萬資料,在MySQL裡可以放50億條資料
每秒的5萬寫併發,總共50億條資料,對於國內大部分的網際網路公司來說,其實一般來說都夠了剛開始的時候,這個庫可能就是邏輯庫,建在一個數據庫上的,就是一個mysql伺服器可能建了n個庫,比如16個庫。後面如果要拆分,