
[分散式系統學習]閱讀筆記 Distributed systems for fun and profit 抽象 之二
本文是閱讀 http://book.mixu.net/distsys/abstractions.html 的筆記。
第二章的題目是"Up and down the level of abstraction"。這一章裡面,作者主要介紹了分散式系統裡面的一個重要概念:CAP理論。
什麼是CAP理論呢?就是說在任何情況下,分散式系統只能滿足下面三項中的兩個:
- 一致性(Consistency),這裡指的強一致性。
- 可用性(Availability)。
- 對網路分割容錯(Partition tolerance)。
這三者不能同時滿足。
接下來是詳細內容。
--------------------下面是本次新聞聯播的詳細內容------------------------------
抽象(Abstraction)
要討論理論,就不能不聊到抽象。作者在這裡文藝了一把。首先在哲學意義上討論了抽象。
當我們說X比Y更加抽象,我們在說什麼?
首先,和Y相比,X並沒有引入新的東西。X甚至可能移除了一些東西,顯得更加可控。
其次,X在某些程度上更容易理解。
作者開始掉書袋了。嘖嘖。尼采說過:
Every concept originates through our equating what is unequal. No leaf ever wholly equals another, and the concept "leaf" is formed through an arbitrary abstraction from these individual differences, through forgetting the distinctions; and now it gives rise to the idea that in nature there might be something besides the leaves which would be "leaf" - some kind of original form after which all leaves have been woven, marked, copied, colored, curled, and painted, but by unskilled hands, so that no copy turned out to be a correct, reliable, and faithful image of the original form.
這句話的大概意思,斗膽翻譯如下:
我們從各異的事物中總結出其的共性,從而產生了概念。世界上沒有完全相同的兩片樹葉,但是”樹葉“這個概念卻是我們忽略世界上千萬的不同的葉子的差別,抽象而成的。這說明,有一些本質的東西讓樹葉成為”樹葉“,而這些本質,原始的存在, 彷彿是被一雙技巧拙劣的雙手標記,扭曲,拷貝,上色,成為我們看到的一片片樹葉。它們面目全非,完全不是本質存在的正確,可靠和可信的反映。
抽象,本質上,是假的。每個具體的個體都是唯一的。但是抽象讓世界更加可控。所以如果我們周圍看到的都是本質,那麼我們從中推論出來的結果會廣泛適用。反之,類似推論出來的不可能的結果(impossibility result)則表明,在一些限制和假設下,我們是不能解決某些問題的。
所以抽象就是為了讓事物等價,忽略某些現實生活中並不本質的東西。但是我們怎麼知道該忽略那些呢?
我們沒法提前知道。
我們在做系統設計的時候,每忽略一些事實,我們就冒險引入一些錯誤和效能問題。然後我們就不得不換一條路。那麼,對分散式系統來說,那些本質我們不得不考慮呢?這就是系統模型設計要解決的問題啦。
系統模型
分散式系統的程式有下面幾個特點:
- 在獨立的節點上執行
- 節點之間通過網路連線,所以可能存在不確定性和訊息丟失
- 程式之間不共享記憶體or時鐘
那麼,
- 每個節點同時執行程式
- 資訊本地化:節點能較快訪問本地的資訊,而全域性的資訊有可能凹凸了。
- 節點有可能失靈(Fail)和恢復
- 訊息可能延遲或者丟失,訊息丟失和節點失靈這兩個蠻難區分
- 節點之間的時間不同步
系統模型就是:
對分散式系統實現的環境和設施的基本假設。
一個強壯的系統模型做最少的假設,其演算法容錯能力出眾。而較弱的系統模型,假設更多,但是實現起來可能更加容易理解。比如假設節點從來不失靈,那麼演算法不就很簡單咯,但是寫出來就沒考慮節點失靈的錯誤處理了。
系統模型中的節點(Nodes)
節點上提供了計算和儲存資源。
- 可執行程式
- 儲存資料到記憶體(失靈丟失)和磁碟(失靈不丟失)
- 本地時鐘
這裡的節點,一般系統都假設,要麼失靈(Fail),就是完全crash;要麼正常。還有一種假設是拜占庭將軍問題。就是說節點失靈不是完全crash,而是傳送一些錯誤資訊。後者比較少見,暫時假設不會發生。
節點之間的通訊的假設
通訊鏈路連線不同的節點,允許訊息相互傳播。對通訊的假設不多。這裡主要是區分下節點失靈(Fail)和網路分割(Network Partition)。

左邊是節點失靈,右邊是網路分割。很好理解。
一些演算法會假設網路通訊總是可靠的。不過總體來說,我們還是認為網路不可靠,訊息會丟失和延遲。
時間和序列的假設
不同節點接受到的訊息序列可能是完全不同的。我們可以假設所有節點上的時間都完全一致,或者,做如下假設。
- 同步系統模型 假設所有node的時序都是一樣的。訊息總是可以在一定時間內傳遞。
- 非同步系統模型 時序不可靠
顯然非同步系統模型更加接近真實時間,同時更加難以實現。
-----------------------核心內容(必考,敲黑板)----------------------------
一致性問題(The Consensus problem)
多臺計算機(或者節點)達到一致表明:
- 共同同意(Agreement):每個程序(Process,這裡就是指獨立執行分散式程式的節點)必須同意某值(Agree on some value)。
- 完整性(Integrity):每個程序都選擇同意某值。同時,如果它們都選擇同意某值,那麼該值一定是其中某些程序提出的。
- 可終結(Termination):所有的程序最終都選擇某一值。
- 有效性(Validity):如果所有正確的程序都提出某值,那麼正確的程序將決定該值。
FLP impossibility result
假設如下:
- 節點 Fail by crash (不會出現拜占庭將軍問題)
- 網路可靠
- 非同步系統模型 訊息可能無限delay
在上面的假設下,FLP 表明,
即使訊息永遠不會丟失,即使最多隻有一個程序失效(Crash),在非同步系統模型下,也不存在一個確定性的分散式演算法。
假設存在這種演算法,那麼任意延遲某訊息(在非同步系統模型中是允許的),在這段時間內該演算法無法讓程序確定選擇某值。我也不是太理解這個解釋。所以放下原文。
This result means that there is no way to solve the consensus problem under a very minimal system model in a way that cannot be delayed forever. The argument is that if such an algorithm existed, then one could devise an execution of that algorithm in which it would remain undecided ("bivalent") for an arbitrary amount of time by delaying message delivery - which is allowed in the asynchronous system model. Thus, such an algorithm cannot exist.
FLP 不可能結果表明,我們需要在非同步系統模型中做折中。在解決一致性問題的時候,當訊息沒辦法保證傳遞,演算法需要放棄safety或者livness。 這裡原文中使用的safety可能是指consistency,liveness 則是availability。
CAP理論
該理論有三個性質。
- 一致性(Consistency):所有節點在同一時刻看到同樣的值(注意這裡指的強一致性)
- 可用性(Availability):某些節點失效並不影響剩餘節點執行
- 對網路分割容錯(Partition tolerance):即使因為網路分割或者節點失效造成的訊息丟失,系統正常執行
上面三個性質,只有兩個可以同時滿足。如下圖。

同時滿足三個性質的系統是不存在的。
比如你要強一致,並且保證高可用性,任何節點失效系統都不失效,那麼對網路分割就沒辦法容忍了,每條訊息都不能丟失。
- CA(Consistency + Availability). 例如嚴格全法定人數協議,例如two-phase commit。 GFS是典型的2PC。
- CP(Consistency + Partition tolerance). 例如大多數法定人數協議,如果發生Partition,包含較少node的部分將不可用。例如Paxos。VMware的 vSAN 作為分散式儲存系統,也屬於這類應用。
- AP (Availibity + Partition tolerance). 弱一致系統。例如Dynamo。
CA和CP都是強一致系統。差別是CA是沒有辦法handle網路分割的。而CP在一個2n+1的系統中容忍n個節點失靈。
CA系統沒辦法區分是網路問題還是節點問題,所以遇到訊息丟失就只有停止write,以防止divergence(一份copy四處不同)。
CP系統通過在Partition兩處構建不對稱node數,只保留節點多的那部分Partition,節點少的那部分就處於不可用狀態,不允許write。
另一個角度來看CAP系統的話,我們始終要保證對網路分割的容錯,
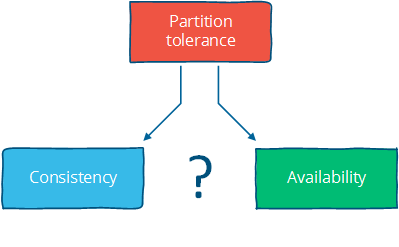
那只有兩種選擇了。要麼實現強一致,放棄部分可用性(of minor partition);要麼實現弱一致,保證可用性(那麼在不同Partition,在同一時刻可能取到不同的值)
所以說,一致性和可用性是此消彼長的關係,是矛盾的統一體。強一致的設計要求,讓我們不得不放棄可用性,因為在發生網路分割的時候,我們不可能在多個Partition還繼續write,使不同Partition出現不一致。
強一致也是效能的敵人。要求每個節點都得到update,那麼對普通操作,代價是很大的。
如果我們在網路分割發生時,堅持可用性,那麼強一致是不可能的。當然,一致性模型不是隻有強一致一種,我們還可以允許其他選擇,比如: