
分散式快取學習筆記
分散式快取
1. 開場白
1.1 為啥在專案裡要用快取呢?
用快取,主要是倆用途,高效能和高併發
1)高效能
假設這麼個場景,你有個操作,一個請求過來,吭哧吭哧各種亂七八糟操作mysql,半天查出來一個結果,耗時600ms。但是這個結果可能接下來幾個小時都不會變了,或者變了也可以不用立即反饋給使用者。那麼此時咋辦?
快取啊,折騰600ms查出來的結果,扔快取裡,一個key對應一個value,下次再有人查,別走mysql折騰600ms了。直接從快取裡,通過一個key查出來一個value,2ms搞定。效能提升300倍。
這就是所謂的高效能。
就是把你一些複雜操作耗時查出來的結果,如果確定後面不咋變了,然後但是馬上還有很多讀請求,那麼直接結果放快取,後面直接讀快取就好了。
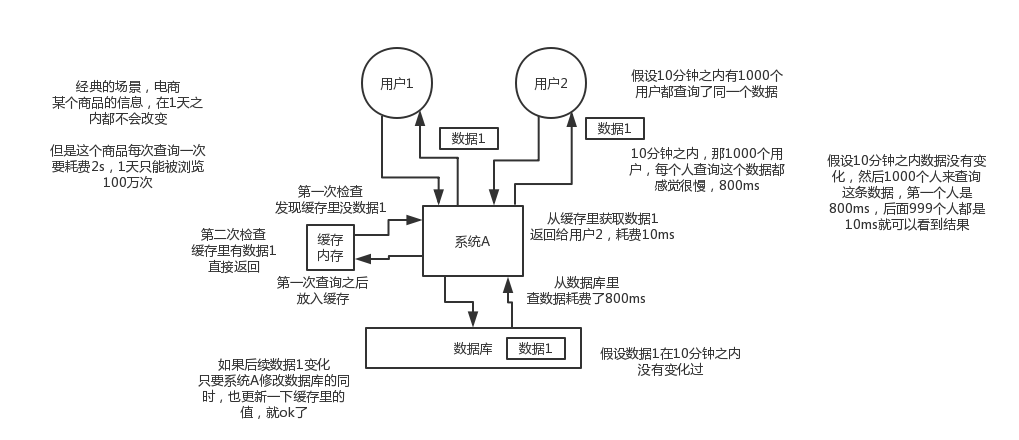
2)高併發
mysql這麼重的資料庫,壓根兒設計不是讓你玩兒高併發的,雖然也可以玩兒,但是天然支援不好。mysql單機支撐到2000qps也開始容易報警了。
所以要是你有個系統,高峰期一秒鐘過來的請求有1萬,那一個mysql單機絕對會死掉。你這個時候就只能上快取,把很多資料放快取,別放mysql。快取功能簡單,說白了就是key-value式操作,單機支撐的併發量輕鬆一秒幾萬十幾萬,支撐高併發so easy。單機承載併發量是mysql單機的幾十倍。
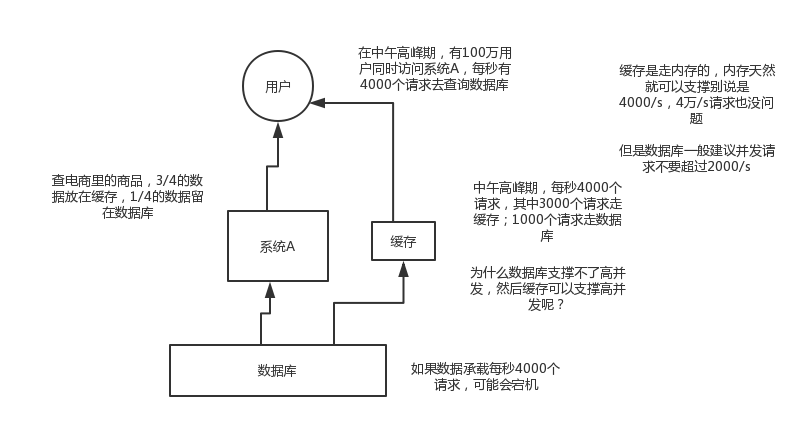
1.2 用了快取之後會有啥不良的後果?
常見的快取問題
1)快取與資料庫雙寫不一致
2)快取雪崩
3)快取穿透
4)快取併發競爭
2. redis執行緒模型
2.1 redis和memcached有啥區別
redis作者給出的幾個比較吧
1)Redis支援伺服器端的資料操作:Redis相比Memcached來說,擁有更多的資料結構和並支援更豐富的資料操作,通常在Memcached裡,你需要將資料拿到客戶端來進行類似的修改再set回去。這大大增加了網路IO的次數和資料體積。在Redis中,這些複雜的操作通常和一般的GET/SET一樣高效。所以,如果需要快取能夠支援更復雜的結構和操作,那麼Redis會是不錯的選擇。
2)記憶體使用效率對比:使用簡單的key-value儲存的話,Memcached的記憶體利用率更高,而如果Redis採用hash結構來做key-value儲存,由於其組合式的壓縮,其記憶體利用率會高於Memcached。
3)效能對比:由於Redis只使用單核,而Memcached可以使用多核,所以平均每一個核上Redis在儲存小資料時比Memcached效能更高。而在100k以上的資料中,Memcached效能要高於Redis,雖然Redis最近也在儲存大資料的效能上進行優化,但是比起Memcached,還是稍有遜色。
4)叢集模式:memcached沒有原生的叢集模式,需要依靠客戶端來實現往叢集中分片寫入資料;但是redis目前是原生支援cluster模式的,redis官方就是支援redis cluster叢集模式的,比memcached來說要更好
2.2 redis的執行緒模型
1)檔案事件處理器
redis基於reactor模式開發了網路事件處理器,這個處理器叫做檔案事件處理器,file event handler。這個檔案事件處理器,是單執行緒的,redis才叫做單執行緒的模型,採用IO多路複用機制同時監聽多個socket,根據socket上的事件來選擇對應的事件處理器來處理這個事件。
如果被監聽的socket準備好執行accept、read、write、close等操作的時候,跟操作對應的檔案事件就會產生,這個時候檔案事件處理器就會呼叫之前關聯好的事件處理器來處理這個事件。
檔案事件處理器是單執行緒模式執行的,但是通過IO多路複用機制監聽多個socket,可以實現高效能的網路通訊模型,又可以跟內部其他單執行緒的模組進行對接,保證了redis內部的執行緒模型的簡單性。
檔案事件處理器的結構包含4個部分:多個socket,IO多路複用程式,檔案事件分派器,事件處理器(命令請求處理器、命令回覆處理器、連線應答處理器,等等)。
多個socket可能併發的產生不同的操作,每個操作對應不同的檔案事件,但是IO多路複用程式會監聽多個socket,但是會將socket放入一個佇列中排隊,每次從佇列中取出一個socket給事件分派器,事件分派器把socket給對應的事件處理器。
然後一個socket的事件處理完之後,IO多路複用程式才會將佇列中的下一個socket給事件分派器。檔案事件分派器會根據每個socket當前產生的事件,來選擇對應的事件處理器來處理。
如果是客戶端要連線redis,那麼會為socket關聯連線應答處理器
如果是客戶端要寫資料到redis,那麼會為socket關聯命令請求處理器
如果是客戶端要從redis讀資料,那麼會為socket關聯命令回覆處理器
2)檔案事件
當socket變得可讀時(比如客戶端對redis執行write操作,或者close操作),或者有新的可以應答的sccket出現時(客戶端對redis執行connect操作),socket就會產生一個AE_READABLE事件。
當socket變得可寫的時候(客戶端對redis執行read操作),socket會產生一個AE_WRITABLE事件。
IO多路複用程式可以同時監聽AE_REABLE和AE_WRITABLE兩種事件,要是一個socket同時產生了AE_READABLE和AE_WRITABLE兩種事件,那麼檔案事件分派器優先處理AE_REABLE事件,然後才是AE_WRITABLE事件。
3)客戶端與redis通訊的一次流程
在redis啟動初始化的時候,redis會將連線應答處理器跟AE_READABLE事件關聯起來,接著如果一個客戶端跟redis發起連線,此時會產生一個AE_READABLE事件,然後由連線應答處理器來處理跟客戶端建立連線,建立客戶端對應的socket,同時將這個socket的AE_READABLE事件跟命令請求處理器關聯起來。
當客戶端向redis發起請求的時候(不管是讀請求還是寫請求,都一樣),首先就會在socket產生一個AE_READABLE事件,然後由對應的命令請求處理器來處理。這個命令請求處理器就會從socket中讀取請求相關資料,然後進行執行和處理。
接著redis這邊準備好了給客戶端的響應資料之後,就會將socket的AE_WRITABLE事件跟命令回覆處理器關聯起來,當客戶端這邊準備好讀取響應資料時,就會在socket上產生一個AE_WRITABLE事件,會由對應的命令回覆處理器來處理,就是將準備好的響應資料寫入socket,供客戶端來讀取。
命令回覆處理器寫完之後,就會刪除這個socket的AE_WRITABLE事件和命令回覆處理器的關聯關係。

2.3 為啥redis單執行緒模型也能效率這麼高?
1)純記憶體操作
2)核心是基於非阻塞的IO多路複用機制
3)單執行緒反而避免了多執行緒的頻繁上下文切換問題
3. redis的資料型別
(1)string
這是最基本的型別了,沒啥可說的,就是普通的set和get,做簡單的kv快取
(2)hash
這個是類似map的一種結構,這個一般就是可以將結構化的資料,比如一個物件(前提是這個物件沒巢狀其他的物件)給快取在redis裡,然後每次讀寫快取的時候,可以就操作hash裡的某個欄位。
key=150
value={
“id”: 150,
“name”: “zhangsan”,
“age”: 20
}
hash類的資料結構,主要是用來存放一些物件,把一些簡單的物件給快取起來,後續操作的時候,你可以直接僅僅修改這個物件中的某個欄位的值
value={
“id”: 150,
“name”: “zhangsan”,
“age”: 21
}
(3)list
有序列表,這個是可以玩兒出很多花樣的
微博,某個大v的粉絲,就可以以list的格式放在redis裡去快取
key=某大v value=[zhangsan, lisi, wangwu]
比如可以通過list儲存一些列表型的資料結構,類似粉絲列表了、文章的評論列表了之類的東西
比如可以通過lrange命令,就是從某個元素開始讀取多少個元素,可以基於list實現分頁查詢,這個很棒的一個功能,基於redis實現簡單的高效能分頁,可以做類似微博那種下拉不斷分頁的東西,效能高,就一頁一頁走
比如可以搞個簡單的訊息佇列,從list頭懟進去,從list尾巴那裡弄出來
(4)set
無序集合,自動去重
直接基於set將系統裡需要去重的資料扔進去,自動就給去重了,如果你需要對一些資料進行快速的全域性去重,你當然也可以基於jvm記憶體裡的HashSet進行去重,但是如果你的某個系統部署在多臺機器上呢?
得基於redis進行全域性的set去重
可以基於set玩兒交集、並集、差集的操作,比如交集吧,可以把兩個人的粉絲列表整一個交集,看看倆人的共同好友是誰?對吧
把兩個大v的粉絲都放在兩個set中,對兩個set做交集
(5)sorted set
排序的set,去重但是可以排序,寫進去的時候給一個分數,自動根據分數排序,這個可以玩兒很多的花樣,最大的特點是有個分數可以自定義排序規則
比如說你要是想根據時間對資料排序,那麼可以寫入進去的時候用某個時間作為分數,人家自動給你按照時間排序了
排行榜:將每個使用者以及其對應的什麼分數寫入進去,zadd board score username,接著zrevrange board 0 99,就可以獲取排名前100的使用者;zrank board username,可以看到使用者在排行榜裡的排名
zadd board 85 zhangsan
zadd board 72 wangwu
zadd board 96 lisi
zadd board 62 zhaoliu
96 lisi
85 zhangsan
72 wangwu
62 zhaoliu
獲取排名前3的使用者
96 lisi
85 zhangsan
72 wangwu
4. redis過期策略
4.1 redis是怎麼對過期key進行刪除的?
答案是:定期刪除+惰性刪除
定期刪除,指的是redis預設是每隔100ms就隨機抽取一些設定了過期時間的key,檢查其是否過期,如果過期就刪除。假設redis裡放了10萬個key,都設定了過期時間,你每隔幾百毫秒,就檢查10萬個key,那redis基本上就死了,cpu負載會很高的,消耗在你的檢查過期key上了。注意,這裡可不是每隔100ms就遍歷所有的設定過期時間的key,那樣就是一場效能上的災難。實際上redis是每隔100ms隨機抽取一些key來檢查和刪除的。
但是問題是,定期刪除可能會導致很多過期key到了時間並沒有被刪除掉,那咋整呢?所以就是惰性刪除了。這就是說,在你獲取某個key的時候,redis會檢查一下 ,這個key如果設定了過期時間那麼是否過期了?如果過期了此時就會刪除,不會給你返回任何東西。
並不是key到時間就被刪除掉,而是你查詢這個key的時候,redis再懶惰的檢查一下
通過上述兩種手段結合起來,保證過期的key一定會被幹掉。
很簡單,就是說,你的過期key,靠定期刪除沒有被刪除掉,還停留在記憶體裡,佔用著你的記憶體呢,除非你的系統去查一下那個key,才會被redis給刪除掉。
4.2 如果定期刪除漏掉了很多過期key,然後你也沒及時去查,也就沒走惰性刪除,此時會怎麼樣?如果大量過期key堆積在記憶體裡,導致redis記憶體塊耗盡了,咋整?
答案是:走記憶體淘汰機制。
記憶體淘汰
如果redis的記憶體佔用過多的時候,此時會進行記憶體淘汰,有如下一些策略:
4.2.1 noeviction
當記憶體不足以容納新寫入資料時,新寫入操作會報錯,這個一般沒人用吧,實在是太噁心了
4.2.2 allkeys-lru
當記憶體不足以容納新寫入資料時,在鍵空間中,移除最近最少使用的key(這個是最常用的)
4.2.3 allkeys-random
當記憶體不足以容納新寫入資料時,在鍵空間中,隨機移除某個key,這個一般沒人用吧,為啥要隨機,肯定是把最近最少使用的key給幹掉啊
4.2.4 volatile-lru
當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,移除最近最少使用的key(這個一般不太合適)
4.2.5 volatile-random
當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,隨機移除某個key
4.2.6 volatile-ttl
當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,有更早過期時間的key優先移除
4.3 寫一個LRU演算法?
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
// 這裡就是傳遞進來最多能快取多少資料
public LRUCache(int cacheSize) {
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true); // 這塊就是設定一個hashmap的初始大小,同時最後一個true指的是讓linkedhashmap按照訪問順序來進行排序,最近訪問的放在頭,最老訪問的就在尾
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > CACHE_SIZE; // 這個意思就是說當map中的資料量大於指定的快取個數的時候,就自動刪除最老的資料
}
}
我給你看上面的程式碼,是告訴你最起碼你也得寫出來上面那種程式碼,不求自己純手工從底層開始打造出自己的LRU,但是起碼知道如何利用已有的jdk資料結構實現一個java版的LRU
5.如何保證redis的高併發與高可用
5.0 概要
5.0.1、redis高併發跟整個系統的高併發之間的關係
redis,你要搞高併發的話,不可避免,要把底層的快取搞得很好
mysql,高併發,做到了,那麼也是通過一系列複雜的分庫分表,訂單系統,事務要求的,QPS到幾萬,比較高了
要做一些電商的商品詳情頁,真正的超高併發,QPS上十萬,甚至是百萬,一秒鐘百萬的請求量
光是redis是不夠的,但是redis是整個大型的快取架構中,支撐高併發的架構裡面,非常重要的一個環節
首先,你的底層的快取中介軟體,快取系統,必須能夠支撐的起我們說的那種高併發,其次,再經過良好的整體的快取架構的設計(多級快取架構、熱點快取),支撐真正的上十萬,甚至上百萬的高併發
5.0.2、redis不能支撐高併發的瓶頸在哪裡?
單機
5.0.3、如果redis要支撐超過10萬+的併發,那應該怎麼做?
單機的redis幾乎不太可能說QPS超過10萬+,除非一些特殊情況,比如你的機器效能特別好,配置特別高,物理機,維護做的特別好,而且你的整體的操作不是太複雜
單機在幾萬
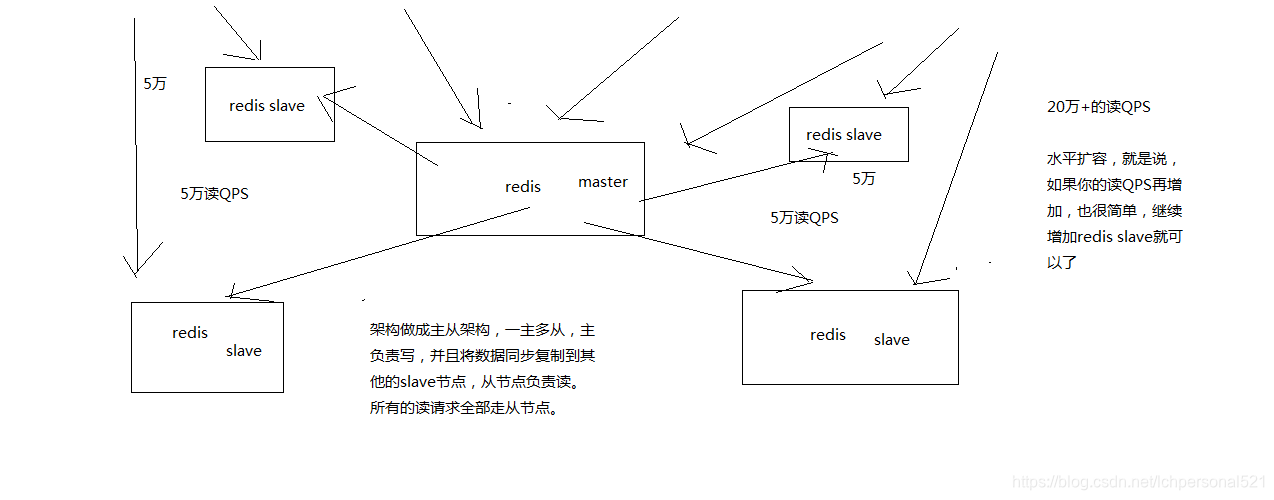
讀寫分離,一般來說,對快取,一般都是用來支撐讀高併發的,寫的請求是比較少的,可能寫請求也就一秒鐘幾千,一兩千
大量的請求都是讀,一秒鐘二十萬次讀
主從架構 -> 讀寫分離 -> 支撐10萬+讀QPS的架構
5.0.4、接下來要講解的一個topic
redis replication
redis主從架構 -> 讀寫分離架構 -> 可支援水平擴充套件的讀高併發架構
5.1 redis主從配置實現讀寫分離,支撐高併發
5.1.1 主從複製配置原理
5.1.2、redis replication的核心機制
(1)redis採用非同步方式複製資料到slave節點,不過redis 2.8開始,slave node會週期性地確認自己每次複製的資料量
(2)一個master node是可以配置多個slave node的
(3)slave node也可以連線其他的slave node
(4)slave node做複製的時候,是不會block master node的正常工作的
(5)slave node在做複製的時候,也不會block對自己的查詢操作,它會用舊的資料集來提供服務; 但是複製完成的時候,需要刪除舊資料集,載入新資料集,這個時候就會暫停對外服務了
(6)slave node主要用來進行橫向擴容,做讀寫分離,擴容的slave node可以提高讀的吞吐量
5.1.3、master持久化對於主從架構的安全保障的意義
如果採用了主從架構,那麼建議必須開啟master node的持久化!
不建議用slave node作為master node的資料熱備,因為那樣的話,如果你關掉master的持久化,可能在master宕機重啟的時候資料是空的,然後可能一經過複製,salve node資料也丟了
master -> RDB和AOF都關閉了 -> 全部在記憶體中
master宕機,重啟,是沒有本地資料可以恢復的,然後就會直接認為自己IDE資料是空的
master就會將空的資料集同步到slave上去,所有slave的資料全部清空
100%的資料丟失
5.1.4、主從架構的核心原理
當啟動一個slave node的時候,它會發送一個PSYNC命令給master node
如果這是slave node重新連線master node,那麼master node僅僅會複製給slave部分缺少的資料; 否則如果是slave node第一次連線master node,那麼會觸發一次full resynchronization
開始full resynchronization的時候,master會啟動一個後臺執行緒,開始生成一份RDB快照檔案,同時還會將從客戶端收到的所有寫命令快取在記憶體中。RDB檔案生成完畢之後,master會將這個RDB傳送給slave,slave會先寫入本地磁碟,然後再從本地磁碟載入到記憶體中。然後master會將記憶體中快取的寫命令傳送給slave,slave也會同步這些資料。
slave node如果跟master node有網路故障,斷開了連線,會自動重連。master如果發現有多個slave node都來重新連線,僅僅會啟動一個rdb save操作,用一份資料服務所有slave node。
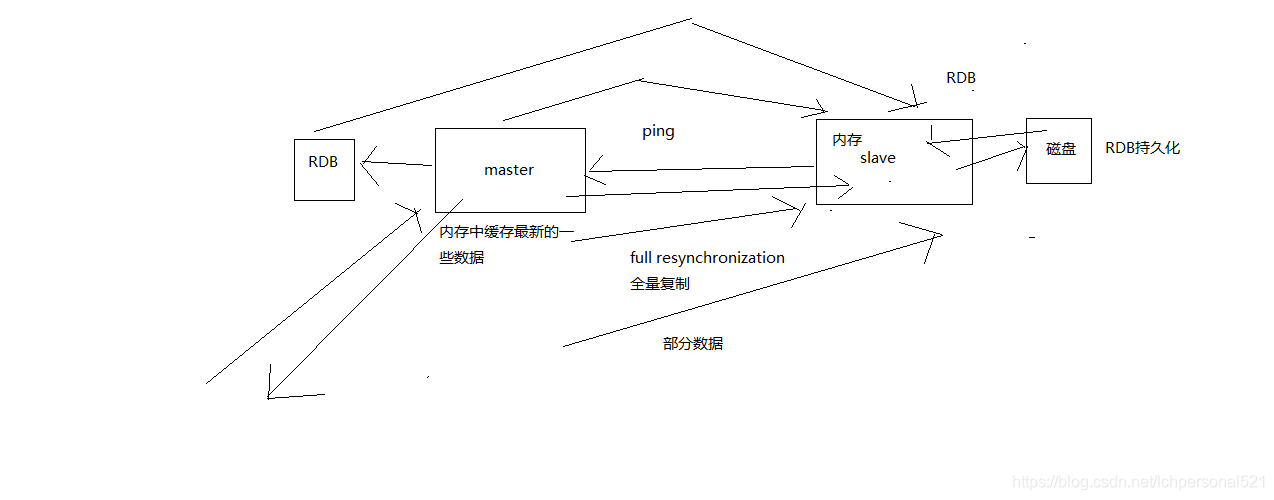
5.1.5、主從複製的斷點續傳
從redis 2.8開始,就支援主從複製的斷點續傳,如果主從複製過程中,網路連線斷掉了,那麼可以接著上次複製的地方,繼續複製下去,而不是從頭開始複製一份
master node會在記憶體中常見一個backlog,master和slave都會儲存一個replica offset還有一個master id,offset就是儲存在backlog中的。如果master和slave網路連線斷掉了,slave會讓master從上次的replica offset開始繼續複製
但是如果沒有找到對應的offset,那麼就會執行一次resynchronization
5.1.5、無磁碟化複製
master在記憶體中直接建立rdb,然後傳送給slave,不會在自己本地落地磁碟了
repl-diskless-sync
repl-diskless-sync-delay,等待一定時長再開始複製,因為要等更多slave重新連線過來
5.1.6、過期key處理
slave不會過期key,只會等待master過期key。如果master過期了一個key,或者通過LRU淘汰了一個key,那麼會模擬一條del命令傳送給slave。
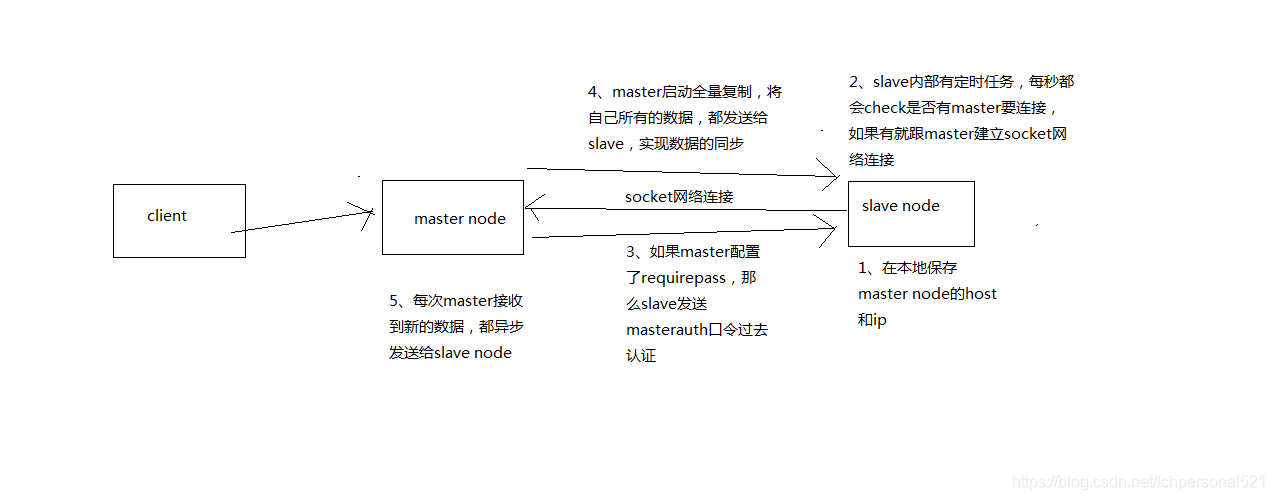
5.1.7、複製的完整流程
(1)slave node啟動,僅僅儲存master node的資訊,包括master node的host和ip,但是複製流程沒開始master host和ip是從哪兒來的,redis.conf裡面的slaveof配置的
(2)slave node內部有個定時任務,每秒檢查是否有新的master node要連線和複製,如果發現,就跟master node建立socket網路連線
(3)slave node傳送ping命令給master node
(4)口令認證,如果master設定了requirepass,那麼salve node必須傳送masterauth的口令過去進行認證
(5)master node第一次執行全量複製,將所有資料發給slave node
(6)master node後續持續將寫命令,非同步複製給slave node
5.1.8、資料同步相關的核心機制
指的就是第一次slave連線msater的時候,執行的全量複製,那個過程裡面你的一些細節的機制
(1)master和slave都會維護一個offset ,master會在自身不斷累加offset,slave也會在自身不斷累加offset,slave每秒都會上報自己的offset給master,同時master也會儲存每個slave的offset,這個倒不是說特定就用在全量複製的,主要是master和slave都要知道各自的資料的offset,才能知道互相之間的資料不一致的情況
(2)backlog
master node有一個backlog,預設是1MB大小
master node給slave node複製資料時,也會將資料在backlog中同步寫一份
backlog主要是用來做全量複製中斷候的增量複製的
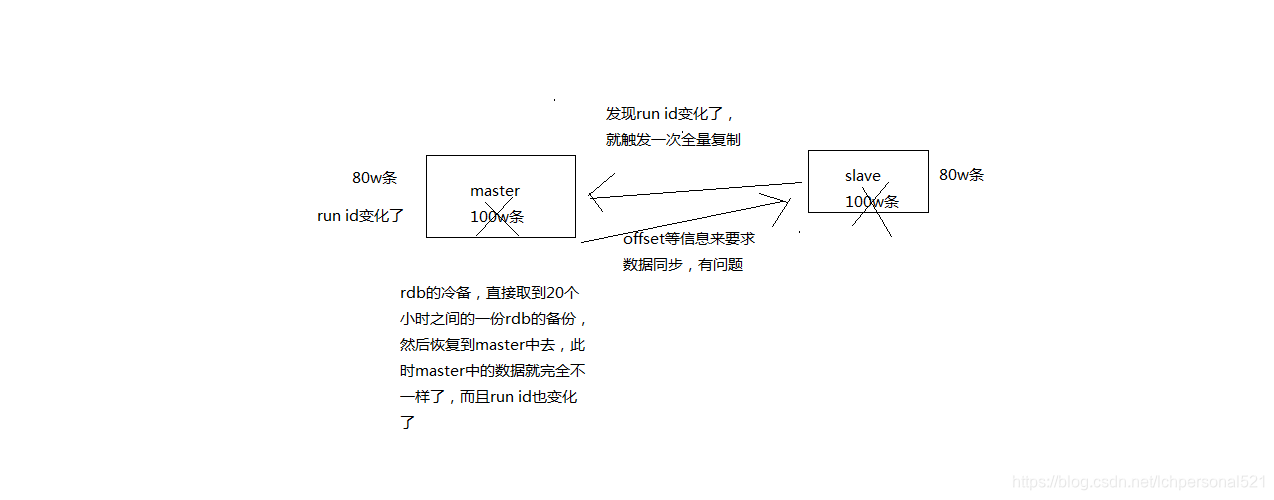
5.1.9、 master run id
info server,可以看到master run id
如果根據host+ip定位master node,是不靠譜的,如果master node重啟或者資料出現了變化,那麼slave node應該根據不同的run id區分,run id不同就做全量複製
如果需要不更改run id重啟redis,可以使用redis-cli debug reload命令
5.1.10、 psync
從節點使用psync從master node進行復制,psync runid offset
master node會根據自身的情況返回響應資訊,可能是FULLRESYNC runid offset觸發全量複製,可能是CONTINUE觸發增量複製
5.1.11、全量複製
(1)master執行bgsave,在本地生成一份rdb快照檔案
(2)master node將rdb快照檔案傳送給salve node,如果rdb複製時間超過60秒(repl-timeout),那麼slave node就會認為複製失敗,可以適當調節大這個引數
(3)對於千兆網絡卡的機器,一般每秒傳輸100MB,6G檔案,很可能超過60s
(4)master node在生成rdb時,會將所有新的寫命令快取在記憶體中,在salve node儲存了rdb之後,再將新的寫命令複製給salve node
(5)client-output-buffer-limit slave 256MB 64MB 60,如果在複製期間,記憶體緩衝區持續消耗超過64MB,或者一次性超過256MB,那麼停止複製,複製失敗
(6)slave node接收到rdb之後,清空自己的舊資料,然後重新載入rdb到自己的記憶體中,同時基於舊的資料版本對外提供服務
(7)如果slave node開啟了AOF,那麼會立即執行BGREWRITEAOF,重寫AOF
rdb生成、rdb通過網路拷貝、slave舊資料的清理、slave aof rewrite,很耗費時間,如果複製的資料量在4G~6G之間,那麼很可能全量複製時間消耗到1分半到2分鐘
5.1.12、增量複製
(1)如果全量複製過程中,master-slave網路連線斷掉,那麼salve重新連線master時,會觸發增量複製
(2)master直接從自己的backlog中獲取部分丟失的資料,傳送給slave node,預設backlog就是1MB
(3)msater就是根據slave傳送的psync中的offset來從backlog中獲取資料的
5.1.13、heartbeat
主從節點互相都會發送heartbeat資訊,master預設每隔10秒傳送一次heartbeat,salve node每隔1秒傳送一個heartbeat
5.1.14、非同步複製
master每次接收到寫命令之後,現在內部寫入資料,然後非同步傳送給slave node
5.2 如何做到redis 99.99%高可用
5.2.1、什麼是99.99%高可用?
架構上,高可用性,99.99%的高可用性,365天,在365天 * 99.99%的時間內,你的系統都是可以嘩嘩對外提供服務的,那就是高可用性,99.99%
5.2.2、redis不可用是什麼?單例項不可用?主從架構不可用?不可用的後果是什麼?
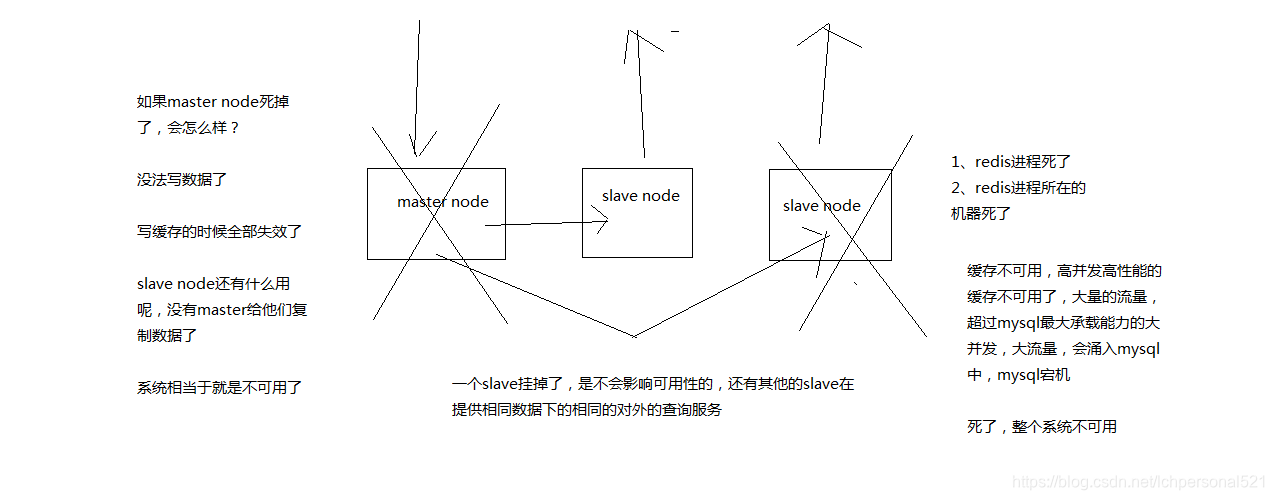
5.2.3、redis怎麼才能做到高可用?
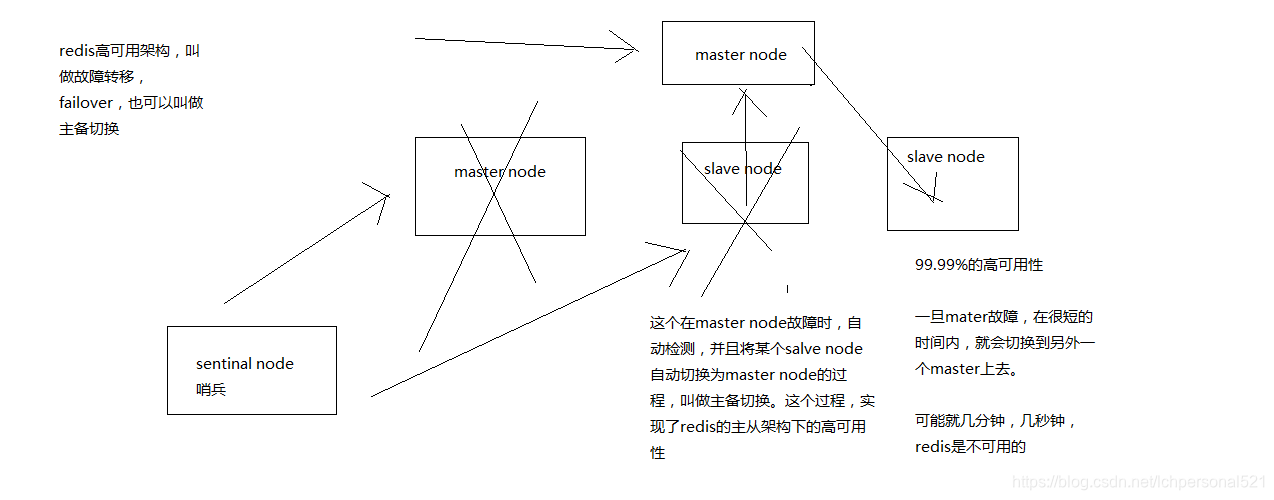
5.2.4、哨兵的介紹
1 sentinal,中文名是哨兵。哨兵是redis叢集架構中非常重要的一個元件,主要功能如下
(1)叢集監控,負責監控redis master和slave程序是否正常工作
(2)訊息通知,如果某個redis例項有故障,那麼哨兵負責傳送訊息作為報警通知給管理員
(3)故障轉移,如果master node掛掉了,會自動轉移到slave node上
(4)配置中心,如果故障轉移發生了,通知client客戶端新的master地址
2 哨兵本身也是分散式的,作為一個哨兵叢集去執行,互相協同工作
(1)故障轉移時,判斷一個master node是宕機了,需要大部分的哨兵都同意才行,涉及到了分散式選舉的問題
(2)即使部分哨兵節點掛掉了,哨兵叢集還是能正常工作的,因為如果一個作為高可用機制重要組成部分的故障轉移系統本身是單點的,那就很坑爹了
目前採用的是sentinal 2版本,sentinal 2相對於sentinal 1來說,重寫了很多程式碼,主要是讓故障轉移的機制和演算法變得更加健壯和簡單
3、哨兵的核心知識
(1)哨兵至少需要3個例項,來保證自己的健壯性
(2)哨兵 + redis主從的部署架構,是不會保證資料零丟失的,只能保證redis叢集的高可用性
(3)對於哨兵 + redis主從這種複雜的部署架構,儘量在測試環境和生產環境,都進行充足的測試和演練
4、為什麼redis哨兵叢集只有2個節點無法正常工作?
哨兵叢集必須部署2個以上節點
如果哨兵叢集僅僅部署了個2個哨兵例項,quorum=1
±—+ ±—+
| M1 |---------| R1 |
| S1 | | S2 |
±—+ ±—+
Configuration: quorum = 1
master宕機,s1和s2中只要有1個哨兵認為master宕機就可以還行切換,同時s1和s2中會選舉出一個哨兵來執行故障轉移
同時這個時候,需要majority,也就是大多數哨兵都是執行的,2個哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2個哨兵都執行著,就可以允許執行故障轉移
但是如果整個M1和S1執行的機器宕機了,那麼哨兵只有1個了,此時就沒有majority來允許執行故障轉移,雖然另外一臺機器還有一個R1,但是故障轉移不會執行
5、經典的3節點哨兵叢集
+----+
| M1 |
| S1 |
+----+
|
±—+ | ±—+
| R2 |----±—| R3 |
| S2 | | S3 |
±—+ ±—+
Configuration: quorum = 2,majority
如果M1所在機器宕機了,那麼三個哨兵還剩下2個,S2和S3可以一致認為master宕機,然後選舉出一個來執行故障轉移
同時3個哨兵的majority是2,所以還剩下的2個哨兵執行著,就可以允許執行故障轉移
5.3 redis 資料丟失問題
1、兩種資料丟失的情況
主備切換的過程,可能會導致資料丟失
(1)非同步複製導致的資料丟失
因為master -> slave的複製是非同步的,所以可能有部分資料還沒複製到slave,master就宕機了,此時這些部分資料就丟失了
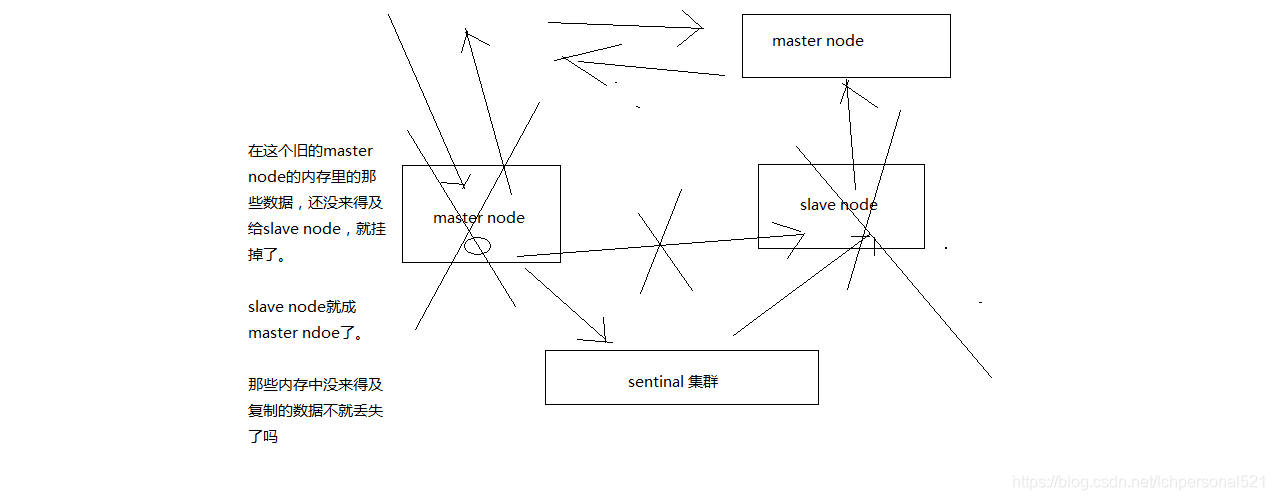
(2)腦裂導致的資料丟失
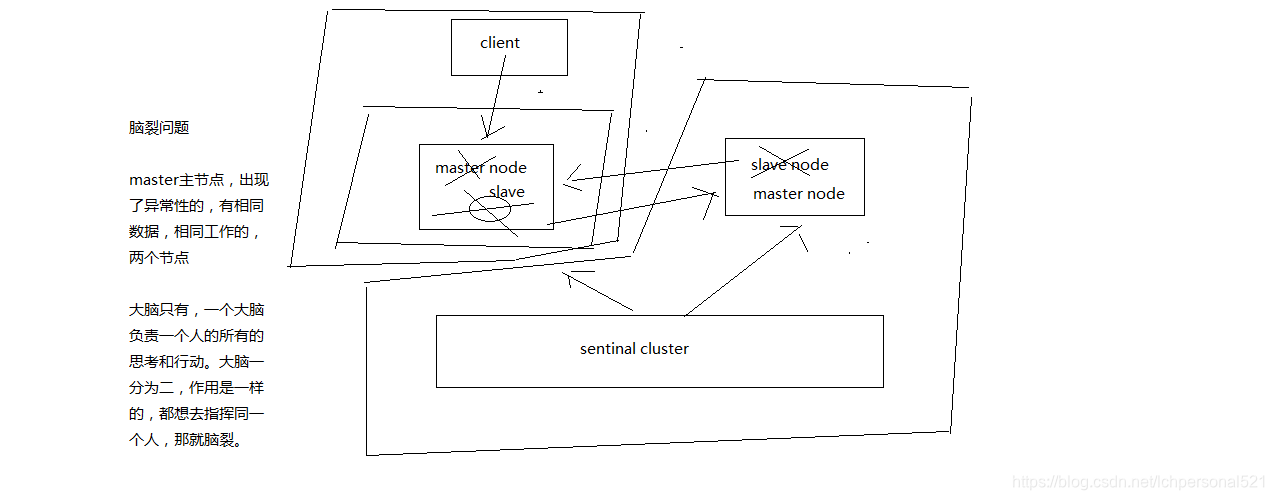
腦裂,也就是說,某個master所在機器突然脫離了正常的網路,跟其他slave機器不能連線,但是實際上master還執行著
此時哨兵可能就會認為master宕機了,然後開啟選舉,將其他slave切換成了master
這個時候,叢集裡就會有兩個master,也就是所謂的腦裂
此時雖然某個slave被切換成了master,但是可能client還沒來得及切換到新的master,還繼續寫向舊master的資料可能也丟失了
因此舊master再次恢復的時候,會被作為一個slave掛到新的master上去,自己的資料會清空,重新從新的master複製資料
2、解決非同步複製和腦裂導致的資料丟失
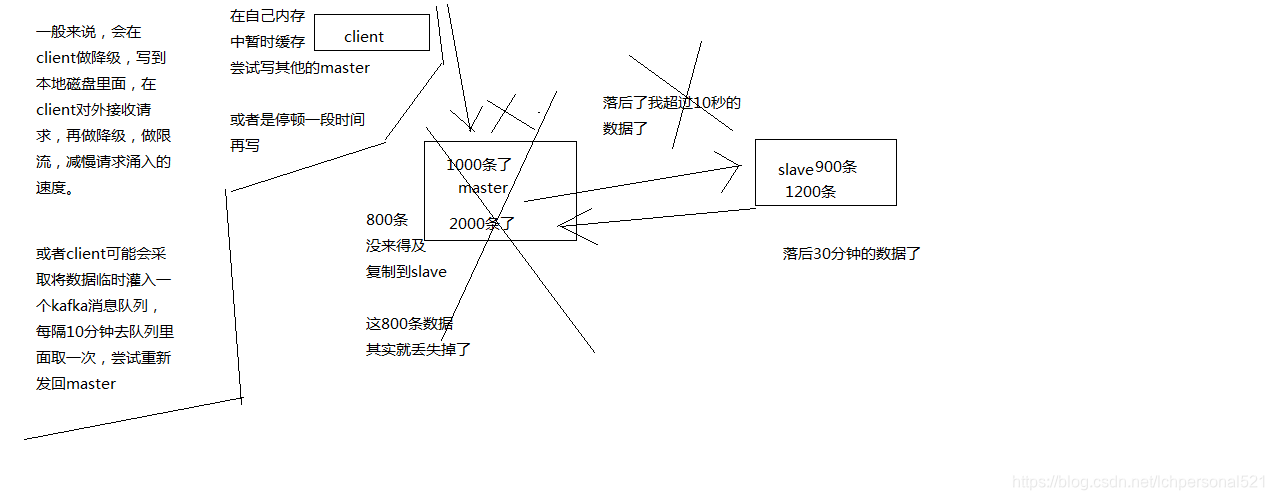
min-slaves-to-write 1
min-slaves-max-lag 10
要求至少有1個slave,資料複製和同步的延遲不能超過10秒
如果說一旦所有的slave,資料複製和同步的延遲都超過了10秒鐘,那麼這個時候,master就不會再接收任何請求了
上面兩個配置可以減少非同步複製和腦裂導致的資料丟失
(1)減少非同步複製的資料丟失
有了min-slaves-max-lag這個配置,就可以確保說,一旦slave複製資料和ack延時太長,就認為可能master宕機後損失的資料太多了,那麼就拒絕寫請求,這樣可以把master宕機時由於部分資料未同步到slave導致的資料丟失降低的可控範圍內
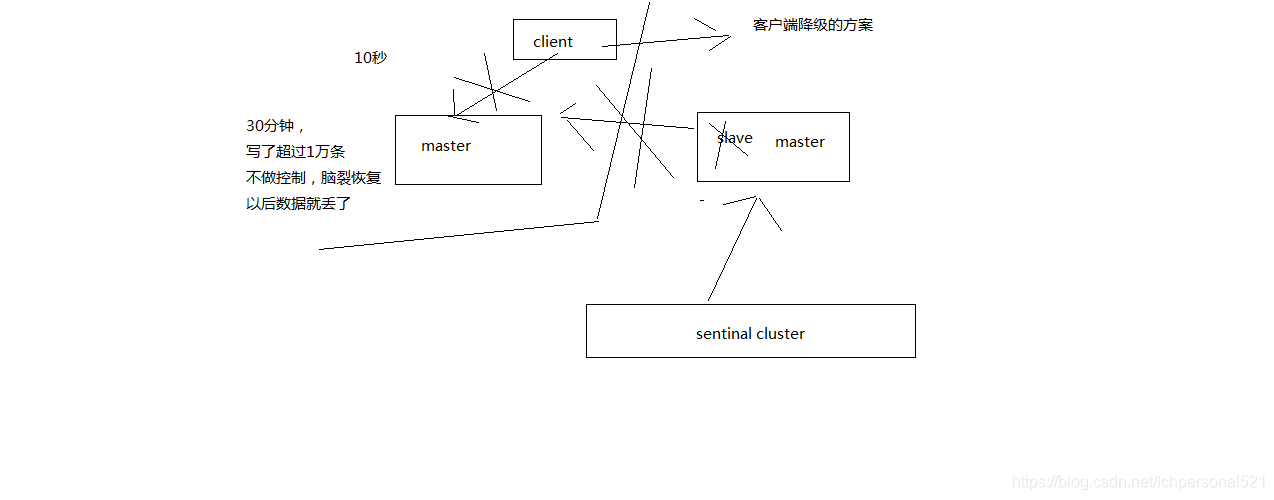
(2)減少腦裂的資料丟失
如果一個master出現了腦裂,跟其他slave丟了連線,那麼上面兩個配置可以確保說,如果不能繼續給指定數量的slave傳送資料,而且slave超過10秒沒有給自己ack訊息,那麼就直接拒絕客戶端的寫請求
這樣腦裂後的舊master就不會接受client的新資料,也就避免了資料丟失
上面的配置就確保了,如果跟任何一個slave丟了連線,在10秒後發現沒有slave給自己ack,那麼就拒絕新的寫請求
因此在腦裂場景下,最多就丟失10秒的資料
5.4 其他概念
1、sdown和odown轉換機制
sdown和odown兩種失敗狀態
sdown是主觀宕機,就一個哨兵如果自己覺得一個master宕機了,那麼就是主觀宕機
odown是客觀宕機,如果quorum數量的哨兵都覺得一個master宕機了,那麼就是客觀宕機
sdown達成的條件很簡單,如果一個哨兵ping一個master,超過了is-master-down-after-milliseconds指定的毫秒數之後,就主觀認為master宕機
sdown到odown轉換的條件很簡單,如果一個哨兵在指定時間內,收到了quorum指定數量的其他哨兵也認為那個master是sdown了,那麼就認為是odown了,客觀認為master宕機
2、哨兵叢集的自動發現機制
哨兵互相之間的發現,是通過redis的pub/sub系統實現的,每個哨兵都會往__sentinel__:hello這個channel裡傳送一個訊息,這時候所有其他哨兵都可以消費到這個訊息,並感知到其他的哨兵的存在
每隔兩秒鐘,每個哨兵都會往自己監控的某個master+slaves對應的__sentinel__:hello channel裡傳送一個訊息,內容是自己的host、ip和runid還有對這個master的監控配置
每個哨兵也會去監聽自己監控的每個master+slaves對應的__sentinel__:hello channel,然後去感知到同樣在監聽這個master+slaves的其他哨兵的存在
每個哨兵還會跟其他哨兵交換對master的監控配置,互相進行監控配置的同步
3、slave配置的自動糾正
哨兵會負責自動糾正slave的一些配置,比如slave如果要成為潛在的master候選人,哨兵會確保slave在複製現有master的資料; 如果slave連線到了一個錯誤的master上,比如故障轉移之後,那麼哨兵會確保它們連線到正確的master上
4、slave->master選舉演算法
如果一個master被認為odown了,而且majority哨兵都允許了主備切換,那麼某個哨兵就會執行主備切換操作,此時首先要選舉一個slave來
會考慮slave的一些資訊
(1)跟master斷開連線的時長
(2)slave優先順序
(3)複製offset
(4)run id
如果一個slave跟master斷開連線已經超過了down-after-milliseconds的10倍,外加master宕機的時長,那麼slave就被認為不適合選舉為master
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
接下來會對slave進行排序
(1)按照slave優先順序進行排序,slave priority越低,優先順序就越高
(2)如果slave priority相同,那麼看replica offset,哪個slave複製了越多的資料,offset越靠後,優先順序就越高
(3)如果上面兩個條件都相同,那麼選擇一個run id比較小的那個slave
5、quorum和majority
每次一個哨兵要做主備切換,首先需要quorum數量的哨兵認為odown,然後選舉出一個哨兵來做切換,這個哨兵還得得到majority哨兵的授權,才能正式執行切換
如果quorum < majority,比如5個哨兵,majority就是3,quorum設定為2,那麼就3個哨兵授權就可以執行切換
但是如果quorum >= majority,那麼必須quorum數量的哨兵都授權,比如5個哨兵,quorum是5,那麼必須5個哨兵都同意授權,才能執行切換
6、configuration epoch
哨兵會對一套redis master+slave進行監控,有相應的監控的配置
執行切換的那個哨兵,會從要切換到的新master(salve->master)那裡得到一個configuration epoch,這就是一個version號,每次切換的version號都必須是唯一的
如果第一個選舉出的哨兵切換失敗了,那麼其他哨兵,會等待failover-timeout時間,然後接替繼續執行切換,此時會重新獲取一個新的configuration epoch,作為新的version號
7、configuraiton傳播
哨兵完成切換之後,會在自己本地更新生成最新的master配置,然後同步給其他的哨兵,就是通過之前說的pub/sub訊息機制
這裡之前的version號就很重要了,因為各種訊息都是通過一個channel去釋出和監聽的,所以一個哨兵完成一次新的切換之後,新的master配置是跟著新的version號的
其他的哨兵都是根據版本號的大小來更新自己的master配置的
5.5 Redis掛掉之後資料如何恢復
實際上就是Redis的持久化方式,優缺點以及實現原理
1.redis持久化的意義
資料備份和故障恢復
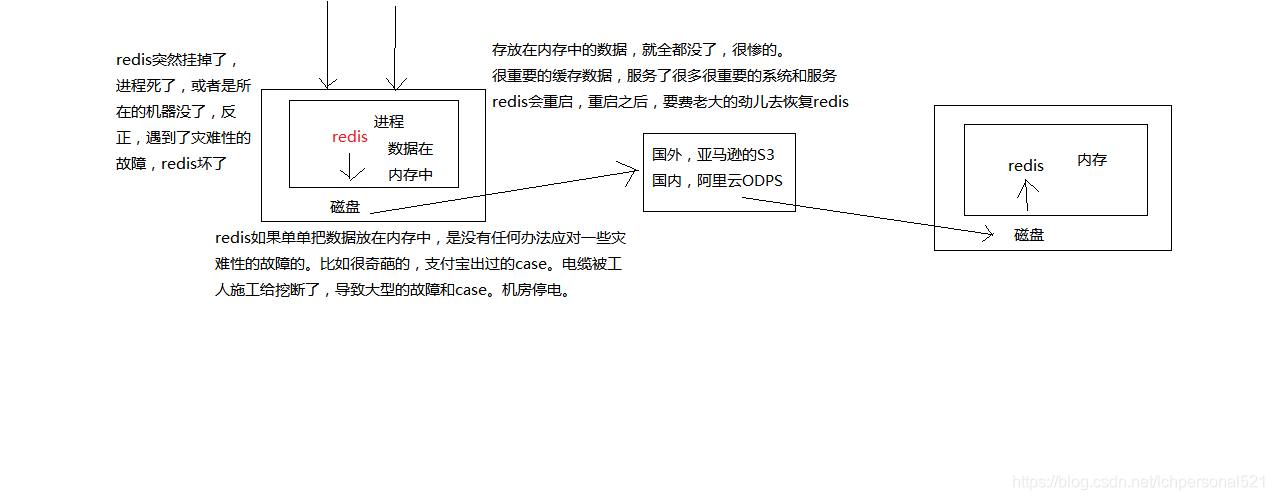
2. RDB和AOF兩種持久化機制的介紹
RDB持久化機制,對redis中的資料執行週期性的持久化
AOF機制對每條寫入命令作為日誌,以append-only的模式寫入一個日誌檔案中,在redis重啟的時候,可以通過回放AOF日誌中的寫入指令來重新構建整個資料集
如果我們想要redis僅僅作為純記憶體的快取來用,那麼可以禁止RDB和AOF所有的持久化機制
通過RDB或AOF,都可以將redis記憶體中的資料給持久化到磁碟上面來,然後可以將這些資料備份到別的地方去,比如說阿里雲,雲服務
如果redis掛了,伺服器上的記憶體和磁碟上的資料都丟了,可以從雲服務上拷貝回來之前的資料,放到指定的目錄中,然後重新啟動redis,redis就會自動根據持久化資料檔案中的資料,去恢復記憶體中的資料,繼續對外提供服務
如果同時使用RDB和AOF兩種持久化機制,那麼在redis重啟的時候,會使用AOF來重新構建資料,因為AOF中的資料更加完整

3. RDB持久化機制的優點
(1)RDB會生成多個數據檔案,每個資料檔案都代表了某一個時刻中redis的資料,這種多個數據檔案的方式,非常適合做冷備,可以將這種完整的資料檔案傳送到一些遠端的安全儲存上去,比如說Amazon的S3雲服務上去,在國內可以是阿里雲的ODPS分散式儲存上,以預定好的備份策略來定期備份redis中的資料
(2)RDB對redis對外提供的讀寫服務,影響非常小,可以讓redis保持高效能,因為redis主程序只需要fork一個子程序,讓子程序執行磁碟IO操作來進行RDB持久化即可
(3)相對於AOF持久化機制來說,直接基於RDB資料檔案來重啟和恢復redis程序,更加快速
4. RDB持久化機制的缺點
(1)如果想要在redis故障時,儘可能少的丟失資料,那麼RDB沒有AOF好。一般來說,RDB資料快照檔案,都是每隔5分鐘,或者更長時間生成一次,這個時候就得接受一旦redis程序宕機,那麼會丟失最近5分鐘的資料
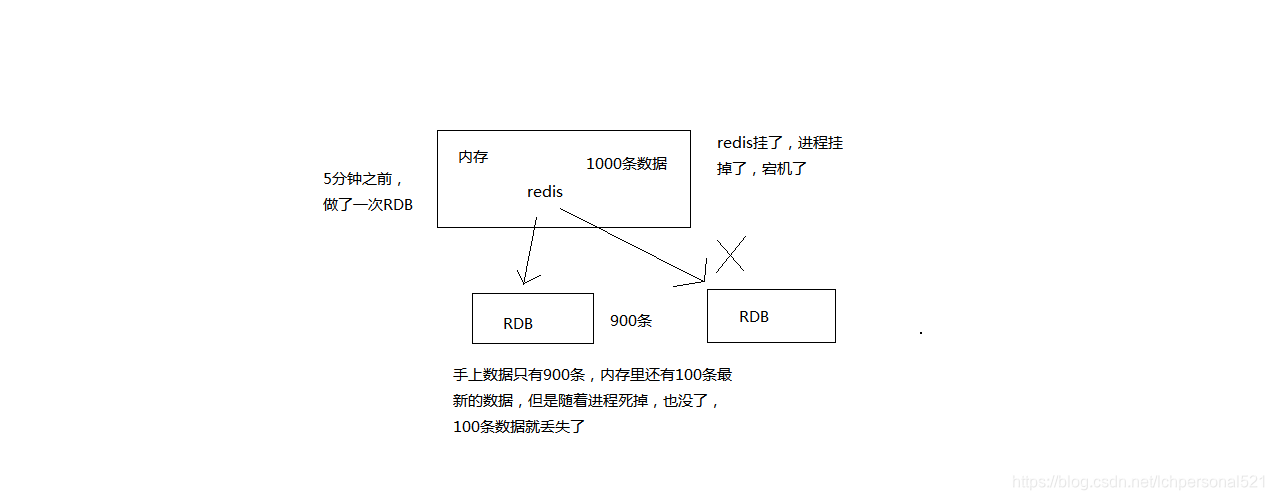
(2)RDB每次在fork子程序來執行RDB快照資料檔案生成的時候,如果資料檔案特別大,可能會導致對客戶端提供的服務暫停數毫秒,或者甚至數秒
5. AOF持久化機制的優點
(1)AOF可以更好的保護資料不丟失,一般AOF會每隔1秒,通過一個後臺執行緒執行一次fsync操作,最多丟失1秒鐘的資料
(2)AOF日誌檔案以append-only模式寫入,所以沒有任何磁碟定址的開銷,寫入效能非常高,而且檔案不容易破損,即使檔案尾部破損,也很容易修復
(3)AOF日誌檔案即使過大的時候,出現後臺重寫操作,也不會影響客戶端的讀寫。因為在rewrite log的時候,會對其中的指導進行壓縮,創建出一份需要恢復資料的最小日誌出來。再建立新日誌檔案的時候,老的日誌檔案還是照常寫入。當新的merge後的日誌檔案ready的時候,再交換新老日誌檔案即可。
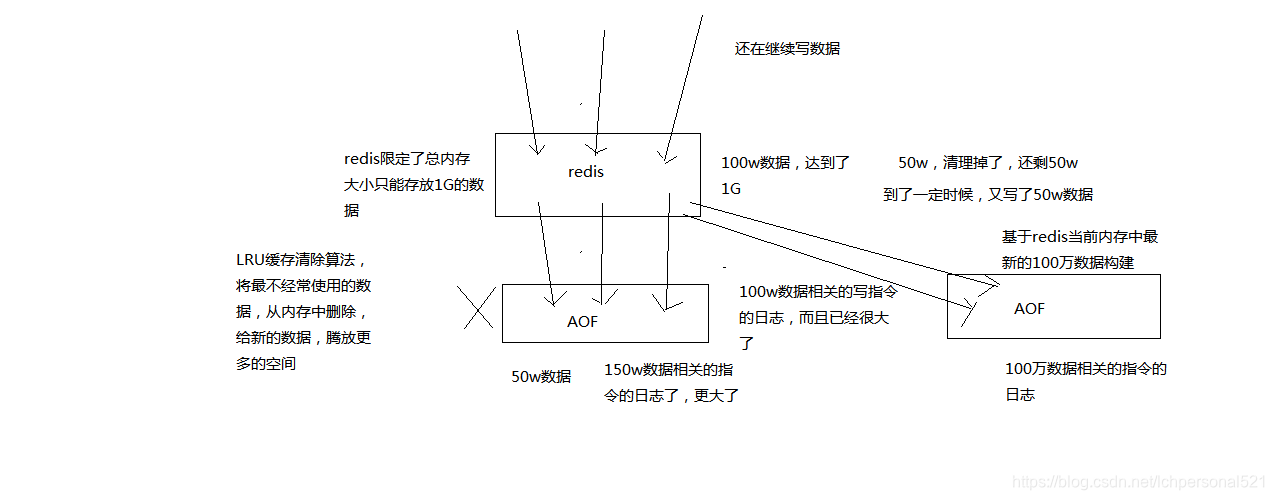
(4)AOF日誌檔案的命令通過非常可讀的方式進行記錄,這個特性非常適合做災難性的誤刪除的緊急恢復。比如某人不小心用flushall命令清空了所有資料,只要這個時候後臺rewrite還沒有發生,那麼就可以立即拷貝AOF檔案,將最後一條flushall命令給刪了,然後再將該AOF檔案放回去,就可以通過恢復機制,自動恢復所有資料
6. AOF持久化機制的缺點
(1)對於同一份資料來說,AOF日誌檔案通常比RDB資料快照檔案更大
(2)AOF開啟後,支援的寫QPS會比RDB支援的寫QPS低,因為AOF一般會配置成每秒fsync一次日誌檔案,當然,每秒一次fsync,效能也還是很高的
(3)以前AOF發生過bug,就是通過AOF記錄的日誌,進行資料恢復的時候,沒有恢復一模一樣的資料出來。所以說,類似AOF這種較為複雜的基於命令日誌/merge/回放的方式,比基於RDB每次持久化一份完整的資料快照檔案的方式,更加脆弱一些,容易有bug。不過AOF就是為了避免rewrite過程導致的bug,因此每次rewrite並不是基於舊的指令日誌進行merge的,而是基於當時記憶體中的資料進行指令的重新構建,這樣健壯性會好很多。
7. RDB和AOF到底該如何選擇
(1)不要僅僅使用RDB,因為那樣會導致你丟失很多資料
(2)也不要僅僅使用AOF,因為那樣有兩個問題,第一,你通過AOF做冷備,沒有RDB做冷備,來的恢復速度更快; 第二,RDB每次簡單粗暴生成資料快照,更加健壯,可以避免AOF這種複雜的備份和恢復機制的bug
(3)綜合使用AOF和RDB兩種持久化機制,用AOF來保證資料不丟失,作為資料恢復的第一選擇; 用RDB來做不同程度的冷備,在AOF檔案都丟失或損壞不可用的時候,還可以使用RDB來進行快速的資料恢復
5.6. Redis cluster
1、單機redis在海量資料面前的瓶頸
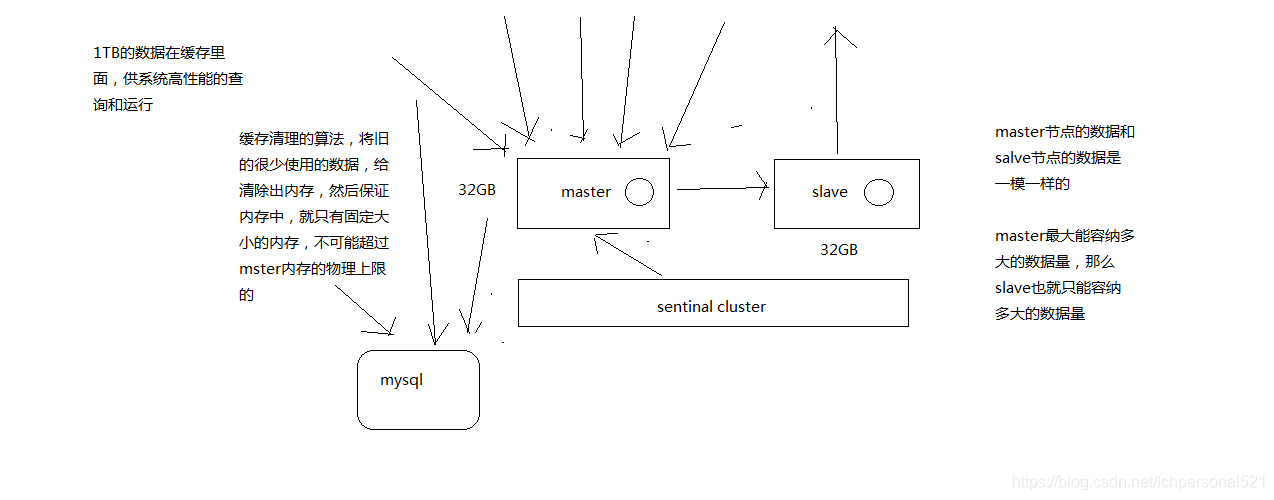
2、怎麼才能夠突破單機瓶頸,讓redis支撐海量資料?
3、redis的叢集架構
1. redis cluster
支撐N個redis master node,每個master node都可以掛載多個slave node
讀寫分離的架構,對於每個master來說,寫就寫到master,然後讀就從mater對應的slave去讀
高可用,因為每個master都有salve節點,那麼如果mater掛掉,redis cluster這套機制,就會自動將某個slave切換成master
redis cluster(多master + 讀寫分離 + 高可用)
我們只要基於redis cluster去搭建redis叢集即可,不需要手工去搭建replication複製+主從架構+讀寫分離+哨兵叢集+高可用
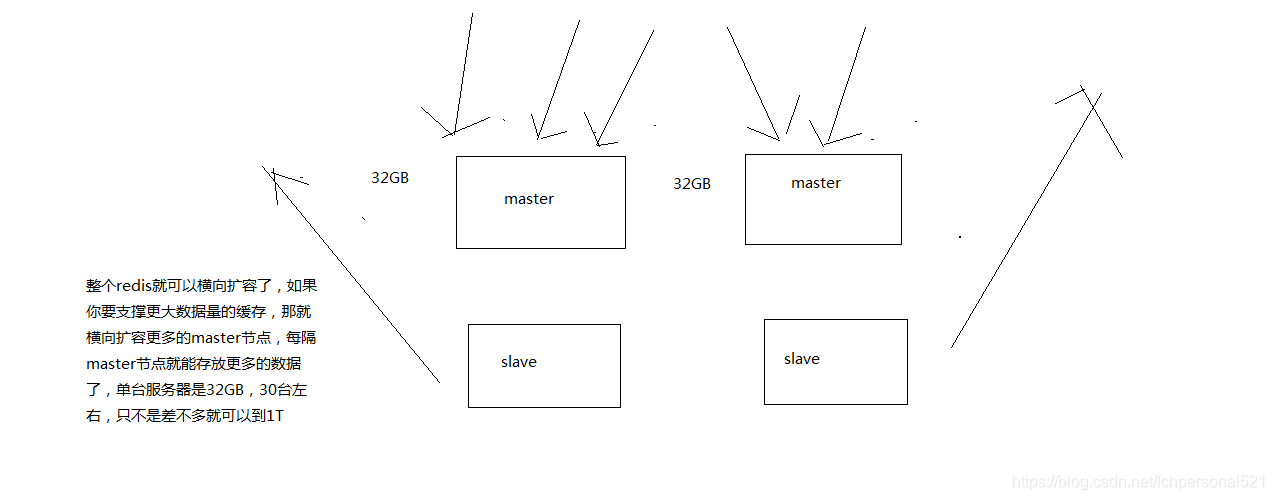
(1)自動將資料進行分片,每個master上放一部分資料
(2)提供內建的高可用支援,部分master不可用時,還是可以繼續工作的
在redis cluster架構下,每個redis要放開兩個埠號,比如一個是6379,另外一個就是加10000的埠號,比如16379
16379埠號是用來進行節點間通訊的,也就是cluster bus的東西,叢集匯流排。cluster bus的通訊,用來進行故障檢測,配置更新,故障轉移授權
cluster bus用了另外一種二進位制的協議,主要用於節點間進行高效的資料交換,佔用更少的網路頻寬和處理時間
2. 資料分佈的演算法
hash演算法 -> 一致性hash演算法(memcached) -> redis cluster,hash slot演算法
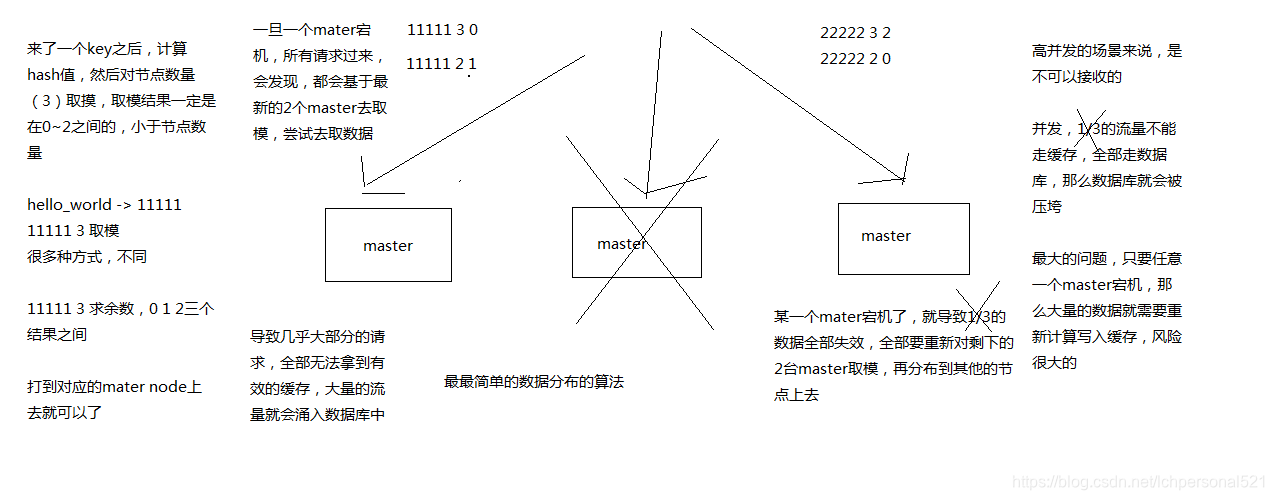
2.1 最老土的hash演算法和弊端(大量快取重建)
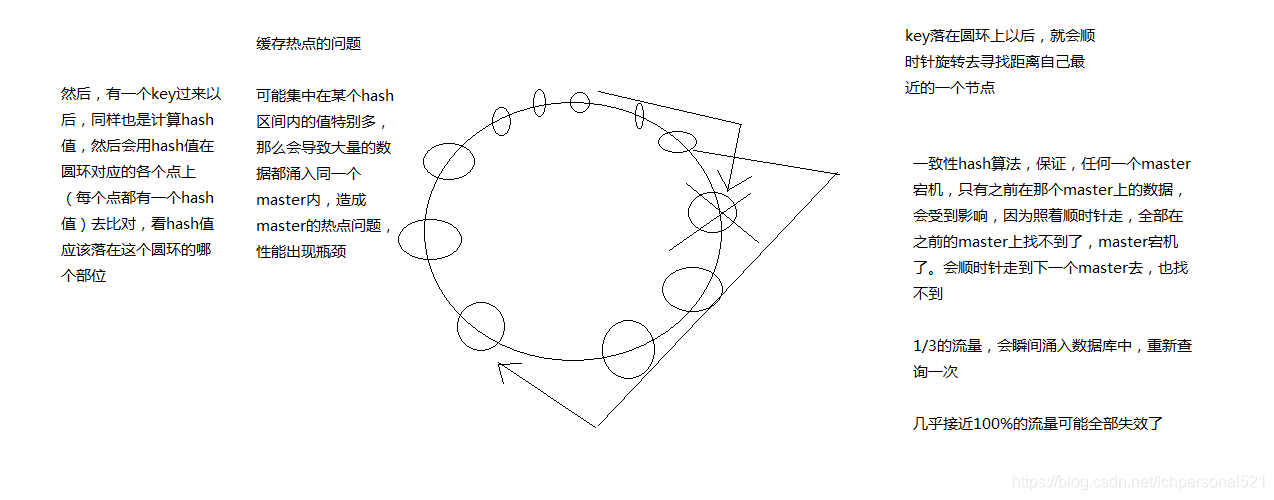
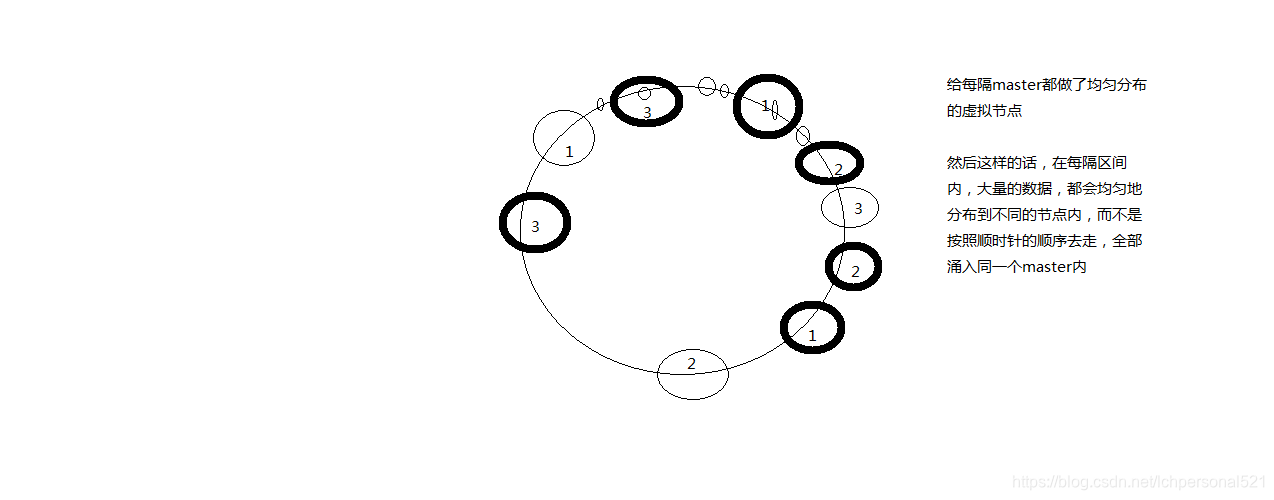
2.2. 一致性hash演算法(自動快取遷移)+虛擬節點(自動負載均衡)
2.3. redis cluster的hash slot演算法
redis cluster有固定的16384個hash slot,對每個key計算CRC16值,然後對16384取模,可以獲取key對應的hash slot
redis cluster中每個master都會持有部分slot,比如有3個master,那麼可能每個master持有5000多個hash slot
hash slot讓node的增加和移除很簡單,增加一個master,就將其他master的hash slot移動部分過去,減少一個master,就將它的hash slot移動到其他master上去
移動hash slot的成本是非常低的
客戶端的api,可以對指定的資料,讓他們走同一個hash slot,通過hash tag來實現
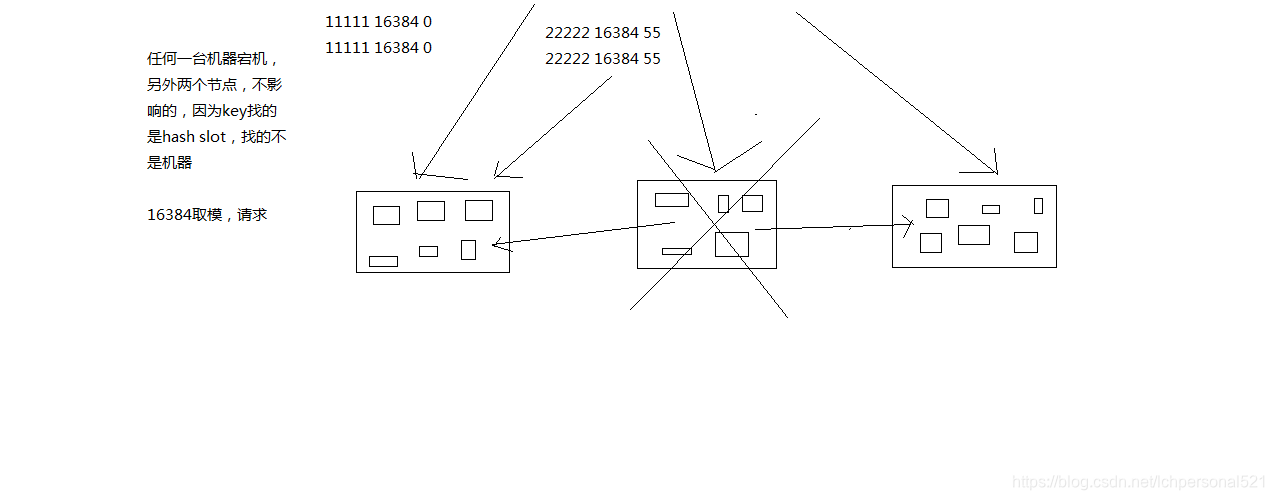
3. redis cluster VS replication + sentinal
如果你的資料量很少,主要是承載高併發高效能的場景,比如你的快取一般就幾個G,單機足夠了
replication,一個mater,多個slave,要幾個slave跟你的要求的讀吞吐量有關係,然後自己搭建一個sentinal叢集,去保證redis主從架構的高可用性,就可以了
redis cluster,主要是針對海量資料+高併發+高可用的場景,海量資料,如果你的資料量很大,那麼建議就用redis cluster
4.節點間的內部通訊機制
1、基礎通訊原理
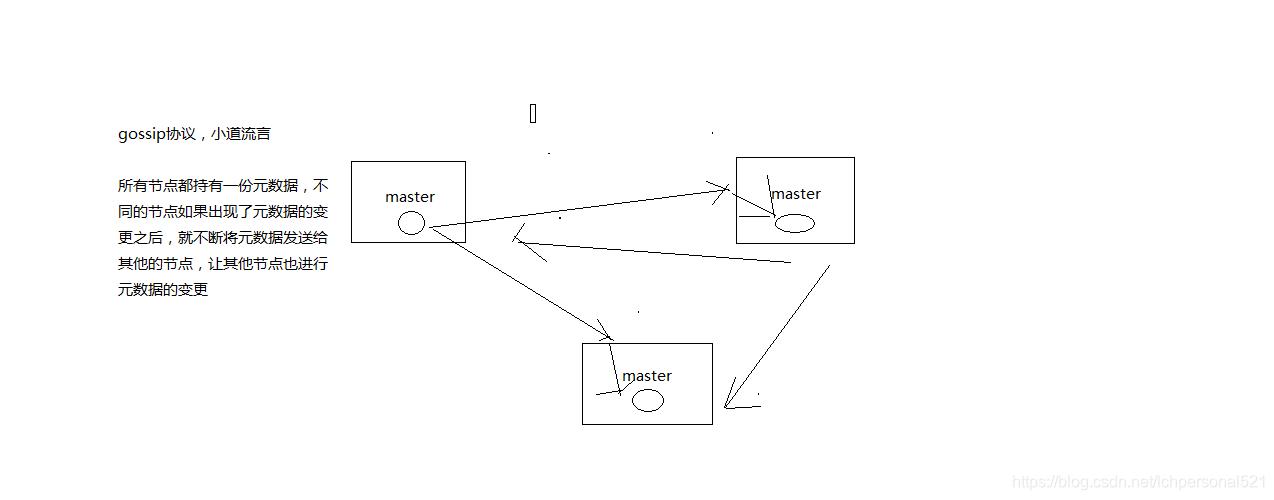
(1)redis cluster節點間採取gossip協議進行通訊
跟集中式不同,不是將叢集元資料(節點資訊,故障,等等)集中儲存在某個節點上,而是互相之間不斷通訊,保持整個叢集所有節點的資料是完整的
維護叢集的元資料用得,集中式,一種叫做gossip
集中式:好處在於,元資料的更新和讀取,時效性非常好,一旦元資料出現了變更,立即就更新到集中式的儲存中,其他節點讀取的時候立即就可以感知到; 不好在於,所有的元資料的跟新壓力全部集中在一個地方,可能會導致元資料的儲存有壓力
gossip:好處在於,元資料的更新比較分散,不是集中在一個地方,更新請求會陸陸續續,打到所有節點上去更新,有一定的延時,降低了壓力; 缺點,元資料更新有延時,可能導致叢集的一些操作會有一些滯後
我們剛才做reshard,去做另外一個操作,會發現說,configuration error,達成一致
(2)10000埠
每個節點都有一個專門用於節點間通訊的埠,就是自己提供服務的埠號+10000,比如7001,那麼用於節點間通訊的就是17001埠
每隔節點每隔一段時間都會往另外幾個節點發送ping訊息,同時其他幾點接收到ping之後返回pong
(3)交換的資訊
故障資訊,節點的增加和移除,hash slot資訊,等等
2、gossip協議
gossip協議包含多種訊息,包括ping,pong,meet,fail,等等
meet: 某個節點發送meet給新加入的節點,讓新節點加入叢集中,然後新節點就會開始與其他節點進行通訊
redis-trib.rb add-node
其實內部就是傳送了一個gossip meet訊息,給新加入的節點,通知那個節點去加入我們的叢集
ping: 每個節點都會頻繁給其他節點發送ping,其中包含自己的狀態還有自己維護的叢集元資料,互相通過ping交換元資料
每個節點每秒都會頻繁傳送ping給其他的叢集,ping,頻繁的互相之間交換資料,互相進行元資料的更新
pong: 返回ping和meet,包含自己的狀態和其他資訊,也可以用於資訊廣播和更新
fail: 某個節點判斷另一個節點fail之後,就傳送fail給其他節點,通知其他節點,指定的節點宕機了
3、ping訊息深入
ping很頻繁,而且要攜帶一些元資料,所以可能會加重網路負擔
每個節點每秒會執行10次ping,每次會選擇5個最久沒有通訊的其他節點
當然如果發現某個節點通訊延時達到了cluster_node_timeout / 2,那麼立即傳送ping,避免資料交換延時過長,落後的時間太長了
比如說,兩個節點之間都10分鐘沒有交換資料了,那麼整個叢集處於嚴重的元資料不一致的情況,就會有問題
所以cluster_node_timeout可以調節,如果調節比較大,那麼會降低傳送的頻率
每次ping,一個是帶上自己節點的資訊,還有就是帶上1/10其他節點的資訊,傳送出去,進行資料交換
至少包含3個其他節點的資訊,最多包含總節點-2個其他節點的資訊
5、面向叢集的jedis內部實現原理
開發,jedis,redis的java client客戶端,redis cluster,jedis cluster api
jedis cluster api與redis cluster叢集互動的一些基本原理
1、基於重定向的客戶端
redis-cli -c,自動重定向
(1)請求重定向
客戶端可能會挑選任意一個redis例項去傳送命令,每個redis例項接收到命令,都會計算key對應的hash slot
如果在本地就在本地處理,否則返回moved給客戶端,讓客戶端進行重定向
cluster keyslot mykey,可以檢視一個key對應的hash slot是什麼
用redis-cli的時候,可以加入-c引數,支援自動的請求重定向,redis-cli接收到moved之後,會自動重定向到對應的節點執行命令
(2)計算hash slot
計算hash slot的演算法,就是根據key計算CRC16值,然後對16384取模,拿到對應的hash slot
用hash tag可以手動指定key對應的slot,同一個hash tag下的key,都會在一個hash slot中,比如set mykey1:{100}和set mykey2:{100}
(3)hash slot查詢
節點間通過gossip協議進行資料交換,就知道每個hash slot在哪個節點上
2、smart jedis
(1)什麼是smart jedis
基於重定向的客戶端,很消耗網路IO,因為大部分情況下,可能都會出現一次請求重定向,才能找到正確的節點
所以大部分的客戶端,比如java redis客戶端,就是jedis,都是smart的
本地維護一份hashslot -> node的對映表,快取,大部分情況下,直接走本地快取就可以找到hashslot -> node,不需要通過節點進行moved重定向
(2)JedisCluster的工作原理
在JedisCluster初始化的時候,就會隨機選擇一個node,初始化hashslot -> node對映表,同時為每個節點建立一個JedisPool連線池
每次基於JedisCluster執行操作,首先JedisCluster都會在本地計算key的hashslot,然後在本地對映表找到對應的節點
如果那個node正好還是持有那個hashslot,那麼就ok; 如果說進行了reshard這樣的操作,可能hashslot已經不在那個node上了,就會返回moved
如果JedisCluter API發現對應的節點返回moved,那麼利用該節點的元資料,更新本地的hashslot -> node對映表快取
重複上面幾個步驟,直到找到對應的節點,如果重試超過5次,那麼就報錯,JedisClusterMaxRedirectionException
jedis老版本,可能會出現在叢集某個節點故障還沒完成自動切換恢復時,頻繁更新hash slot,頻繁ping節點檢查活躍,導致大量網路IO開銷
jedis最新版本,對於這些過度的hash slot更新和ping,都進行了優化,避免了類似問題
(3)hashslot遷移和ask重定向
如果hash slot正在遷移,那麼會返回ask重定向給jedis
jedis接收到ask重定向之後,會重新定位到目標節點去執行,但是因為ask發生在hash slot遷移過程中,所以JedisCluster API收到ask是不會更新hashslot本地快取
已經可以確定說,hashslot已經遷移完了,moved是會更新本地hashslot->node對映表快取的
6、高可用性與主備切換原理
redis cluster的高可用的原理,幾乎跟哨兵是類似的
1、判斷節點宕機
如果一個節點認為另外一個節點宕機,那麼就是pfail,主觀宕機
如果多個節點都認為另外一個節點宕機了,那麼就是fail,客觀宕機,跟哨兵的原理幾乎一樣,sdown,odown
在cluster-node-timeout內,某個節點一直沒有返回pong,那麼就被認為pfail
如果一個節點認為某個節點pfail了,那麼會在gossip ping訊息中,ping給其他節點,如果超過半數的節點都認為pfail了,那麼就會變成fail
2、從節點過濾
對宕機的master node,從其所有的slave node中,選擇一個切換成master node
檢查每個slave node與master node斷開連線的時間,如果超過了cluster-node-timeout * cluster-slave-validity-factor,那麼就沒有資格切換成master
這個也是跟哨兵是一樣的,從節點超時過濾的步驟
3、從節點選舉
哨兵:對所有從節點進行排序,slave priority,offset,run id
每個從節點,都根據自己對master複製資料的offset,來設定一個選舉時間,offset越大(複製資料越多)的從節點,選舉時間越靠前,優先進行選舉
所有的master node開始slave選舉投票,給要進行選舉的slave進行投票,如果大部分master node(N/2 + 1)都投票給了某個從節點,那麼選舉通過,那個從節點可以切換成master
從節點執行主備切換,從節點切換為主節點
4、與哨兵比較
整個流程跟哨兵相比,非常類似,所以說,redis cluster功能強大,直接集成了replication和sentinal的功能
沒有辦法去給大家深入講解redis底層的設計的細節,核心原理和設計的細節,那個除非單獨開一門課,redis底層原理深度剖析,redis原始碼
對於咱們這個架構課來說,主要關注的是架構,不是底層的細節,對於架構來說,核心的原理的基本思路,是要梳理清晰的
5.7 如何應對雪崩以及穿透效應
1. 快取雪崩發生的現象
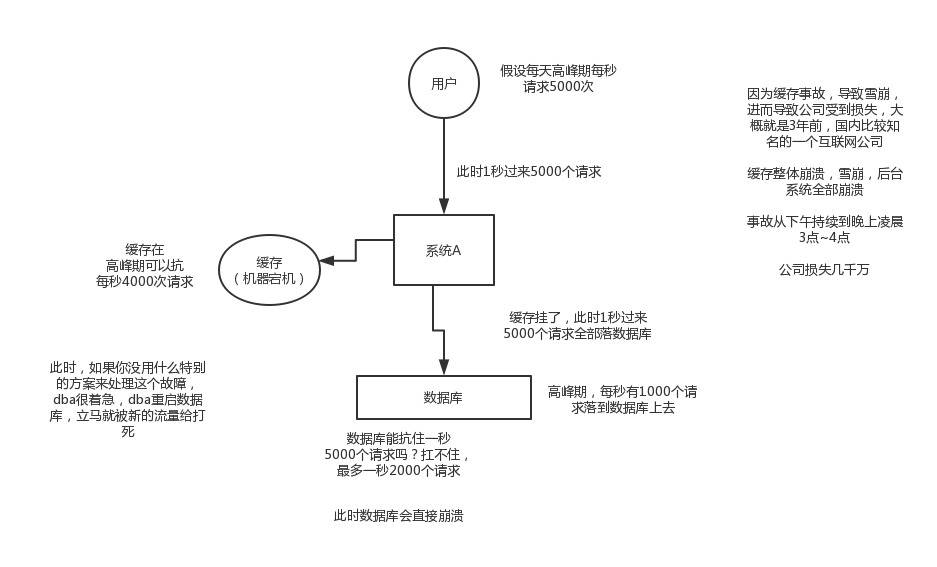
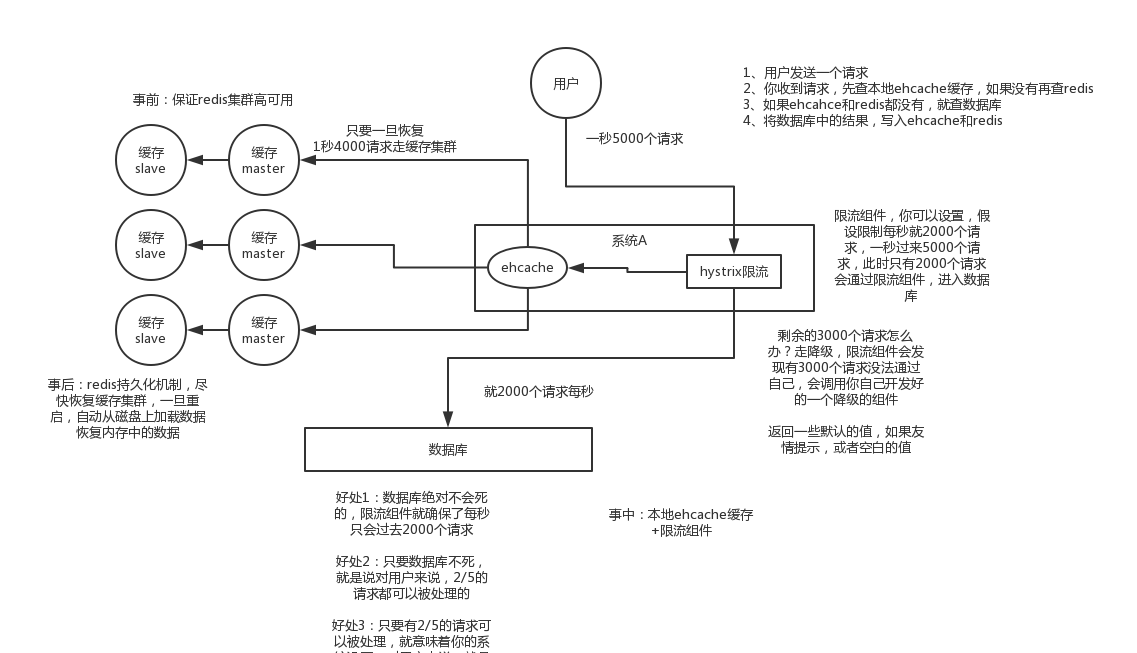
2. 快取雪崩的事前事中事後的解決方案
事前:redis高可用,主從+哨兵,redis cluster,避免全盤崩潰
事中:本地ehcache快取 + hystrix限流&降級,避免MySQL被打死
事後:redis持久化,快速恢復快取資料
3. 快取穿透的現象
快取穿透的解決方法
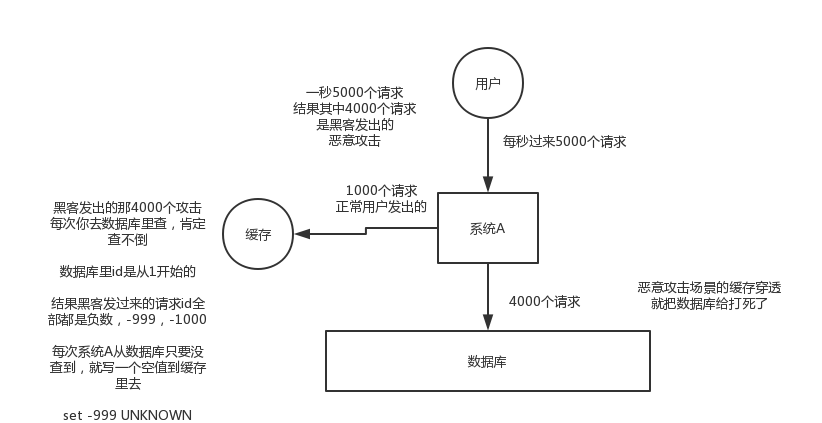
5.8 快取與資料庫雙寫資料的一致性問題
最經典的快取+資料庫讀寫的模式,cache aside pattern
1、Cache Aside Pattern
(1)讀的時候,先讀快取,快取沒有的話,那麼就讀資料庫,然後取出資料後放入快取,同時返回響應
(2)更新的時候,先刪除快取,然後再更新資料庫
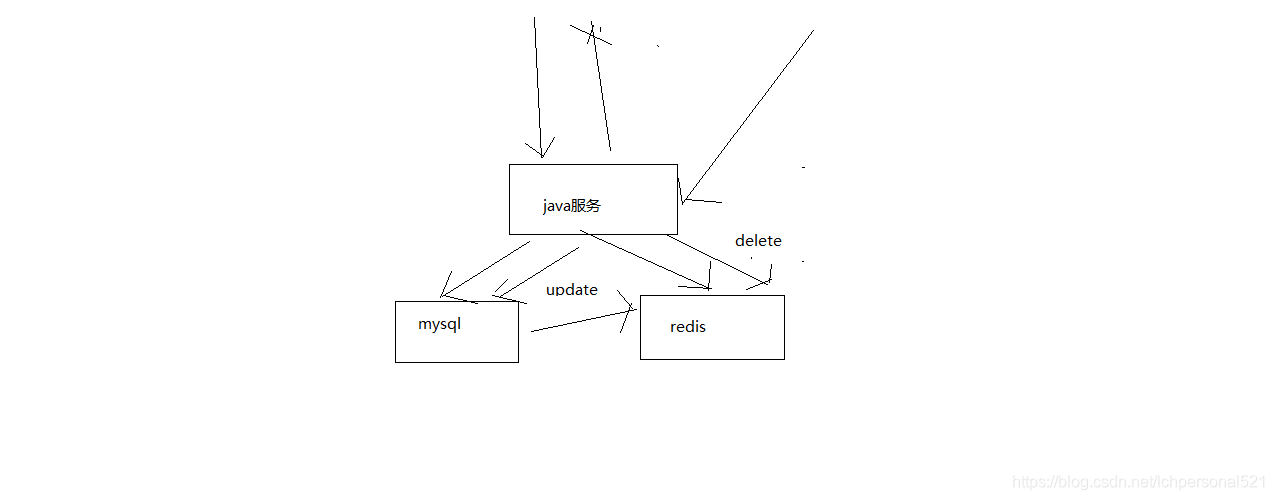
2、為什麼是刪除快取,而不是更新快取呢?
問題在於,這個快取到底會不會被頻繁訪問到???
舉個例子,一