
【Hadoop】MapReduce深度分析
MapReduce深度分析
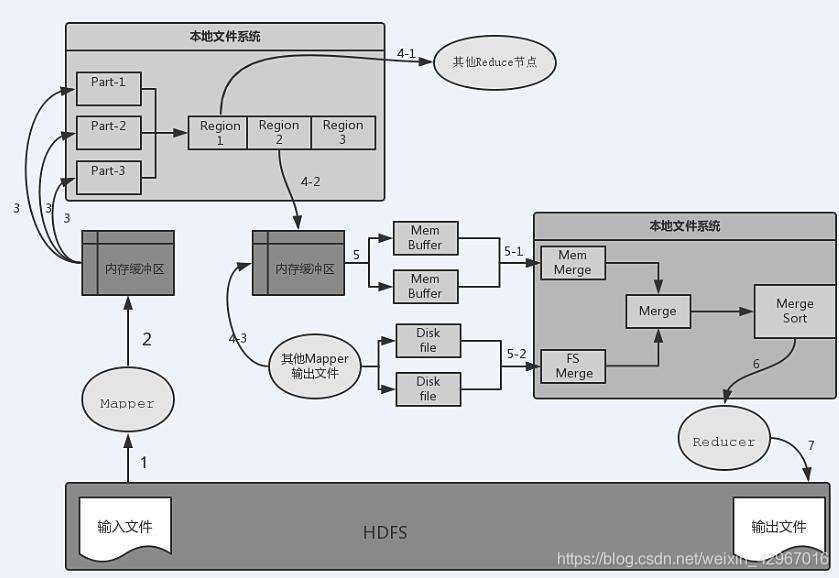
MapReduce總結構分析
資料流向分析
-
1)從HDFS到Mpper節點輸入檔案。
-
2)Mapper輸出到記憶體緩衝區。Mapper的輸出並不是直接寫入本地檔案系統,而是先寫入記憶體緩衝區。
-
3)當緩衝區達到一定的閾值時就將緩衝區中的資料以臨時檔案的形式寫入本地磁碟。預設的緩衝區大小是100MB,溢寫比例預設是0.8 (可通過spill.percent引數來調節)
當達到閾值時,溢寫執行緒就會啟動並鎖定這80MB記憶體執行溢寫過程,這一過程稱為spill。溢寫執行緒啟動的同時還會對這80MB的記憶體資料依據key的序列化位元組做排序。當整個map任務結束後,會對這個map任務產生的所有臨時檔案進行合併,併產生最終的輸出檔案。
需要注意:在寫入記憶體緩衝區的同時執行Partition分割槽。
如果使用者作業設定了Combiner,那麼在溢寫到磁碟之前會對Map輸出的鍵值對呼叫Combiner歸約,這樣可以減少溢寫到本地磁碟檔案的資料量。
-
4)從Mapper端的本地檔案系統流入Reduce端,也就是 Reduce中的Shuffle階段 分三種情況:
- 多個Reduce,需要將Mapper輸出中的分割槽Region檔案遠端複製到相應的Reduce節點,如4-1
- Mapper節點所在機器有Reduce槽位,則會直接寫入本機Reduce緩衝區,如4-2
- 本機的Reduce還會接受其他Mapper輸出的分割槽Region檔案,如4-3
-
5)從Reduce端記憶體緩衝區流向本地磁碟的過程就是Reduce中Merge和Sort階段。Merge分為記憶體檔案合併和磁碟檔案合併,同時還會以key為鍵排序,最終生成已經對相同key的value進行聚集並排序好的輸出檔案。
-
6)流向Reduce函式進行歸約處理
-
7)寫入HDFS中,生成輸出檔案。
處理過程分析
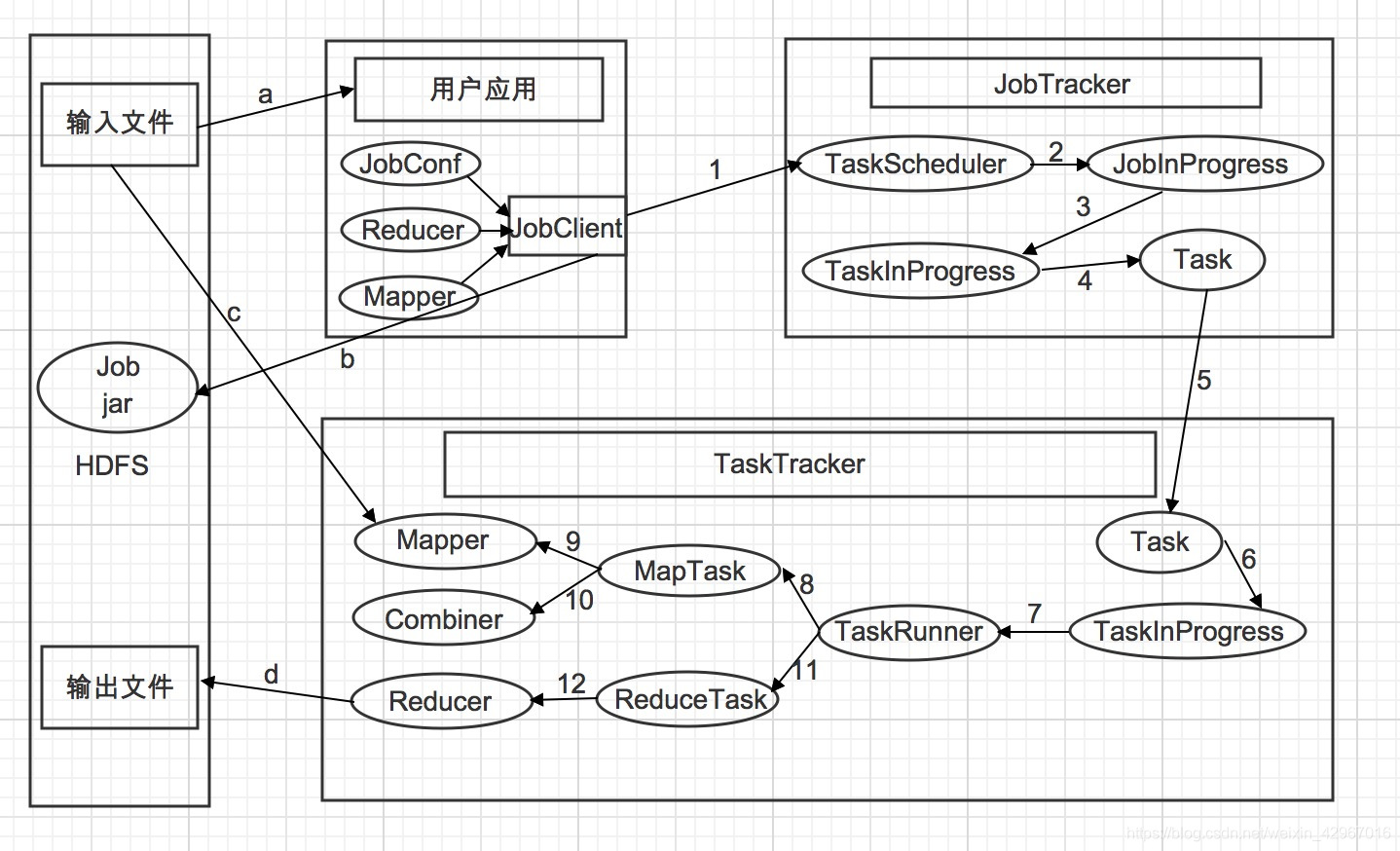
- 1)使用者應用通過JobClient類提交到JobTracker,在JobClient會將Mapper類,Reducer類以及配置JobConf打包成一個JAR檔案並儲存在HDFS中(如b),JobClient在提交作業的同時會把打包的作業JAR檔案的路徑一起提交到JobTracker的master服務,也就是提交給作業排程器。
- 2)提交Job後,JobTracker會建立一個JobInProgress來跟蹤和排程這個作業,並將其新增到排程器的作業佇列中。
- 3)JobInProgress根據JAR檔案中定義的輸入資料集建立相應數量的TaskInProgress用於監控和排程MapTask,同時建立指定數目的TaskInProgress用於監控和排程ReduceTask,預設為一個ReduceTask。
- 4)通過TaskInProgress來啟動作業。
- 5)這時會把Task物件(MapTask和ReduceTask)序列化寫入相應的TaskTracker服務中。
- 6)TaskTracker收到後建立對應的TaskInProgress(不是JobTracker中的,但作用是類似的)用於監控和排程執行該Task。
- 7)啟動具體的Task程序,TaskTracker通過TaskRunner物件來執行具體的Task。
- 8)TaskRunner自動裝載使用者作業JAR檔案,並設定好環境變數後啟動一個獨立的java程序來執行Task,TaskRunner會首先呼叫MapTask。
- 9)MapTask先呼叫Mapper,根據使用者作業JAR中定義的輸入資料集<key1,value1>鍵值對讀入,處理完成生成臨時的<key2,value2>鍵值對。
- 10)如果使用者定義了Combiner,那麼MapTask會在Mapper完成後呼叫Combiner,並將相同key值做歸約處理,以減少Map輸出的鍵值對集合。
- 11)在MapTask任務完成後,TaskRunner緊接著呼叫ReduceTask程序來啟動Reducer。需要注意的是MapTask和ReduceTask 不一定執行在同一個TaskTracker節點中。
- 12)ReduceTask呼叫Reducer類處理Mapper的輸出結果。Reducer生成最終結果<key3,value3>鍵值對,並根據使用者指定的輸出型別寫入HDFS中。
各階段分析
MapTask
MapTask的總邏輯流程,包括以下幾個階段:
- 1)Read階段
通過RecordReader物件,對HDFS上的檔案進行split切分,輸出<key,value>鍵值對。 - 2)Map階段
對輸入的鍵值對呼叫使用者編寫的Map函式進行處理,輸出<key,value>鍵值對 - 3)Collector和Partitioner階段
收集Mapper輸出,在OutputCollector函式內部對鍵值對進行Partitioner分割槽,以便確定相應的Reducer處理,這個階段將最終的鍵值對集合輸出到記憶體緩衝區。 - 4)Spill階段
包含Sort和Combiner階段,當記憶體緩衝區達到閾值後寫入本地磁碟,在這個階段會對Mapper的輸出鍵值對進行排序,如果設定了Combiner會執行Combiner函式。 - 5)Merge階段
對Spill階段在本地磁碟生成的小檔案進行多次合併,最終生成一個大檔案。
(3),(4),(5)也稱Map端的Shuffle
Read階段
//建立InputFormat 物件
InputFormat<INKEY, INVALUE> inputFormat = (InputFormat)ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
//得到使用者指定的InputFormatClass,建立InputFormat物件例項
//InputFormat物件會提供getSplit()方法,通過該方法將輸入檔案切分成多個邏輯InputSplit例項並返回
//---------------------------------------
//重建InputSplit物件
org.apache.hadoop.mapreduce.InputSplit split = null;
//建立一個InputSplit物件,用於對檔案進行資料塊的邏輯切分
split = (org.apache.hadoop.mapreduce.InputSplit)this.getSplitDetails(new Path(splitIndex.getSplitLocation()), splitIndex.getStartOffset());
//每一個InputSplit例項就由對應的一個Mapper來處理
//--------------------------------------
//建立RecordReader物件
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY, INVALUE> input = new MapTask.NewTrackingRecordReader(split, inputFormat, reporter, taskContext);
//RecordReader物件會把InputSplit提供的輸入檔案轉化為Mapper所需要的keys/values鍵值對集合形式
Map階段
- Mapper類中有setup(),map(),cleanup(),run()四個重要方法
一般預設map()是需要使用者重寫的函式。
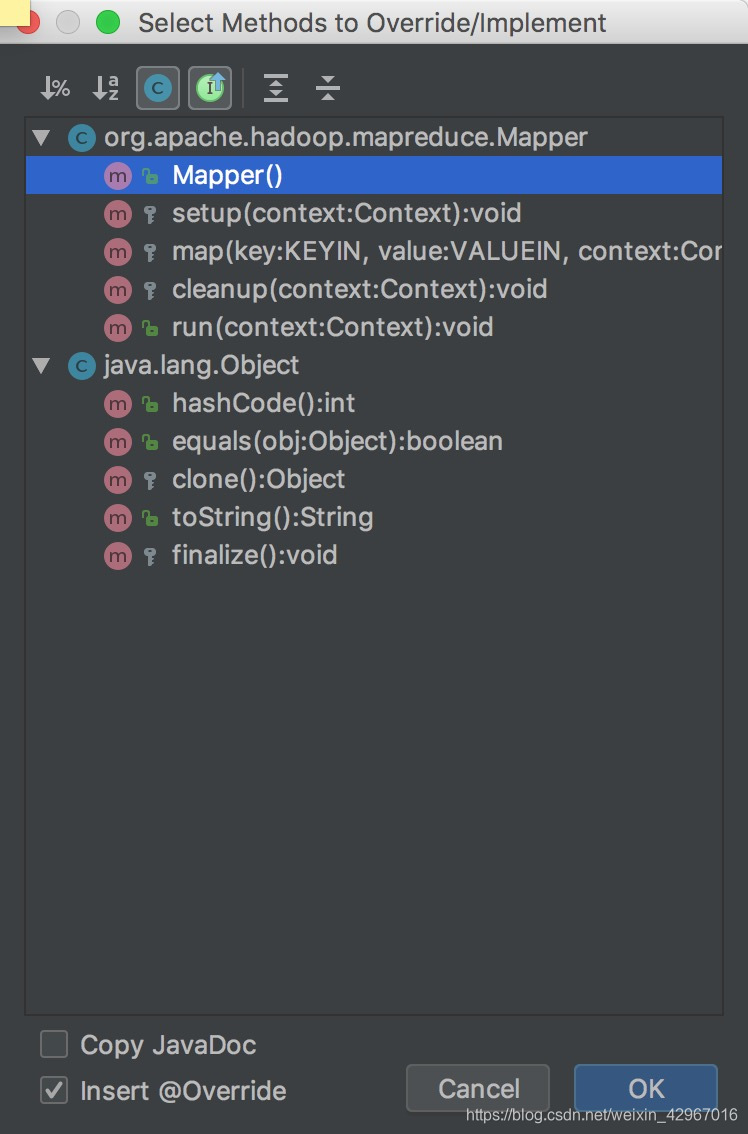
- 下面是run()方法的原始碼
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
//傳入Context物件,然後依次執行setup()->map()->cleanup()
this.setup(context);
try {
while(context.nextKeyValue()) {
this.map(context.getCurrentKey(), context.getCurrentValue(), context);
//得到<key,value>鍵值對,根據使用者的Map操作邏輯進行處理,並呼叫write()輸出
}
} finally {
this.cleanup(context);
}
}
Collector和Partitioner階段
-
map()函式處理完成先寫入緩衝區,被Collector物件收集。
context.write(K,V) -> Partitioner<K,V>()-> collector.collect(K,V,partition)
partition是對應的Reduce分割槽號,是Partitioner的返回值,也就是應該傳輸到哪個Reduce節點處理的。
這裡,以Reduce數目大於0的情況為例分析。
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf
job, TaskUmbilicalProtocol umbilical, TaskReport report
) throws IOException, ClassCastException{
colector = new MapTask.MapOutputBuffer<K,V>(umbilical,job,reporter);
//寫入記憶體緩衝區
partitions = jobContext.getNumReduceTasks();
//得到Reduce數目
if (partition > 0){
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
//預設的Partitioner是HashPartitioner ReflectionUtils.newInstance(jobContext.getPartitionerClass(),job);
//通過反射得到具體的Partitioner例項物件
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition (K key, V value, int numPartitions){
return -1;
}
}
}
}
在得到鍵值對的Reduce分割槽號後,通過呼叫NewOutputCollector收集器類的write()方法進行collect操作。
public void write (K key, V value) throws IOException, InterruptedException {
collector.collect(key, value, partitioner.getPartition(key, value, partitions));
}
Spill階段
-
Spill階段有兩個重要的邏輯,Sort和Combiner(如果使用者設定了Combiner)。
-
首先介紹一個緩衝區。如圖所示,真正在記憶體中的是一個環形緩衝區。
| kvoffsets | int[]型別 | <key,value>偏移量陣列,就是其在kvindices中的偏移量 |
|---|---|---|
| kvindices | int[]型別 | <key,value>鍵值對索引,就是鍵值對在kvbuffer中的起始位置 |
| kvbuffer | byte[]型別 | 記錄儲存陣列,真正儲存<key,value>鍵值對的記憶體緩衝區 |
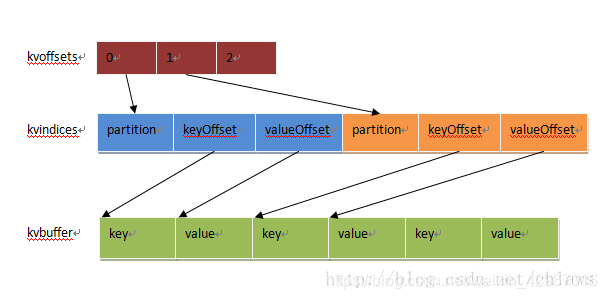
(keyOffset代表key的偏移量,valueOffset代表value的偏移量)
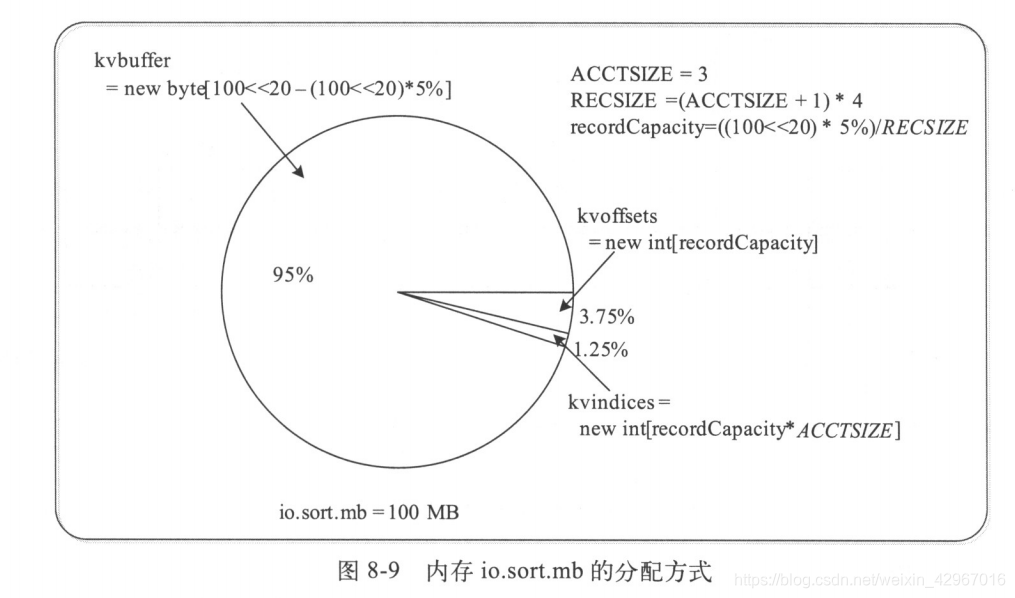
- 具體sortAndSpill過程如下:
-
先建立Spill檔案
-
根據partition分割槽號對<key,value>鍵值對進行排序,也就是Map端的sort階段。具體使用的是快速排序演算法。
-
迴圈依次將每一個partition寫入磁碟檔案
1)如果有combiner,則先combine對同一partition中輸出的<key,value>簡直對進行歸約操作,寫入磁碟檔案
2)如果沒有combiner,則直接寫入磁碟。
這一過程會把Spill的資料儲存在spill.out格式檔案中。
-
生成索引檔案,格式為spill.out.index 。內容實質就是kvindices的內容。
-
Merge階段
- MapTask最終將Spill階段後生成的臨時檔案經過多次合併成一個大的輸出檔案。
(spill.out和spill.out.index檔案)
ReduceTask
ReduceTask的總邏輯流程,包括以下幾個階段:
- 1)Shuffle階段
這個階段就是Reduce中的Copy階段,執行Reducer的TaskTracker需要從各個Mapper節點遠端複製屬於自己處理的一段資料。 - 2)Merge階段
由於執行Shuffle階段時會從各個Mapper節點複製很多同一partition段的資料,因此需要進行多次合併,以防止ReduceTask節點上記憶體使用過多或小檔案過多。 - 3)Sort階段
雖然每個Mapper的輸出是按照key排序好的,但是經過Shuffle和Merge階段後並不是統一有序的,因此還需要在Reduce端進行多輪歸併排序。 - 4)Reduce階段
Reduce的輸入要求是按照key排序的,因此只有在Sort階段執行完成之後才可以對資料呼叫使用者編寫的Reduce類進行歸約處理。
shuffle階段
又稱copy階段。Reduce任務擁有多個複製執行緒,可以並行獲得Map輸出。Map任務可能會在不同時間內完成,只要其中一個任務完成了,ReduceTask任務就開始複製它的輸出。
Merge階段
分為基於記憶體的合併和基於磁碟的合併。
Sort階段
由於每個Mapper複製的輸出資料是區域性排序的,因此Merge的同時還會經過多次歸併排序最終生成整體按照key有序的結果資料。
實質上,Shuffle,Merge,Sort階段基本是同時執行的
Reduce階段
- Reducer類中有setup(),reduce(),cleanup(),run()的四個核心方法,其中setup()和cleanup()與Mapper的類似。
預設reduce()函式是需要使用者重寫的方法。
- run()方法的實現如下:
public void run (Context context) throws IOException, InterruptedException {
//傳入context物件,依次執行setup(),reduce(),cleanup()函式
setup(context);
while(context.nextKey()){
reduce(context.getCurrentKey(), context.getValues (), context);
//獲得key和value, 然後對相同key下的所有value依照使用者的reduce()函式邏輯進行歸約處理,呼叫write()進行輸出。
//需要注意Reduce的輸出是直接寫入HDFS進行持久化儲存的,就是輸出目錄中可見的的檔案
}
cleanup(context);
}