
【Hadoop】MapReduce平行計算框架
MapReduce平行計算框架
基本知識
前言
- MapReduce計算框架是Google提出的一種平行計算框架,是Google雲端計算模型MapReduce的java開源實現,用於大規模資料集(通常1TB級以上)的平行計算。但其實,MR不僅是一種分散式的運算技術,也是簡化的分散式程式設計模式,是用於解決問題的程式開發模型。
核心概念
計算模型
- 計算模型的 核心概念 是”Map(對映)”和”Reduce(歸約)”。使用者需要指定一個Map函式,用來把一組鍵值對對映成一組新的鍵值對,並指定併發的Reduce函式用來合併所有的具有相同中間key值的中間的value值。作業的輸入和輸出都會被儲存在檔案系統中。整個框架負責 任務的排程和監控,以及重新執行已經失敗的任務 。
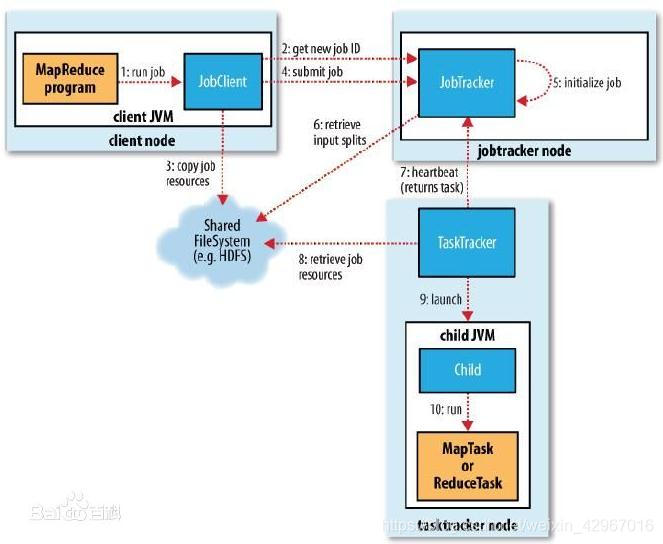
系統架構
-
在系統架構上,MapReduce框架是一種主從架構,由一個單獨的JobTracker節點和多個TaskTracker節點共同組成。
1)JobTracker是MapReduce的Master,負責排程構成一個作業的所有任務,這些任務分佈在不同 的TaskTracker節點上,監控它們的執行,重新執行已經失敗的任務,同時提高狀態和診斷資訊給作業客戶端。
2)TaskTracker是MapReduce的Slave,僅負責執行由Master指派的任務執行。
作業配置
- 對於使用者來講,我們應該在應用程式中 指明輸入和輸出的位置路徑,並通過實現合適的介面或抽象類來提供Map和Reduce函式,再加上其他作業的引數,就構成了作業配置。
計算流程與機制
作業提交和初始化
- (作業提交)命令列提交->作業上傳->產生切分檔案->提交作業到JobTracker->(作業初始化)->(Setup Task->Map Task->Reduce Task->Cleanup Task)
具體過程會在之後的文章介紹
Mapper
- Mapper是MapReduce框架給使用者暴露的Map程式設計介面,使用者在實現自己的Mapper類時需要繼承這個基類。執行Map Task任務:將輸入鍵值對(key/value pair)對映到一組中間格式的鍵值對集合。
處理流程如下:
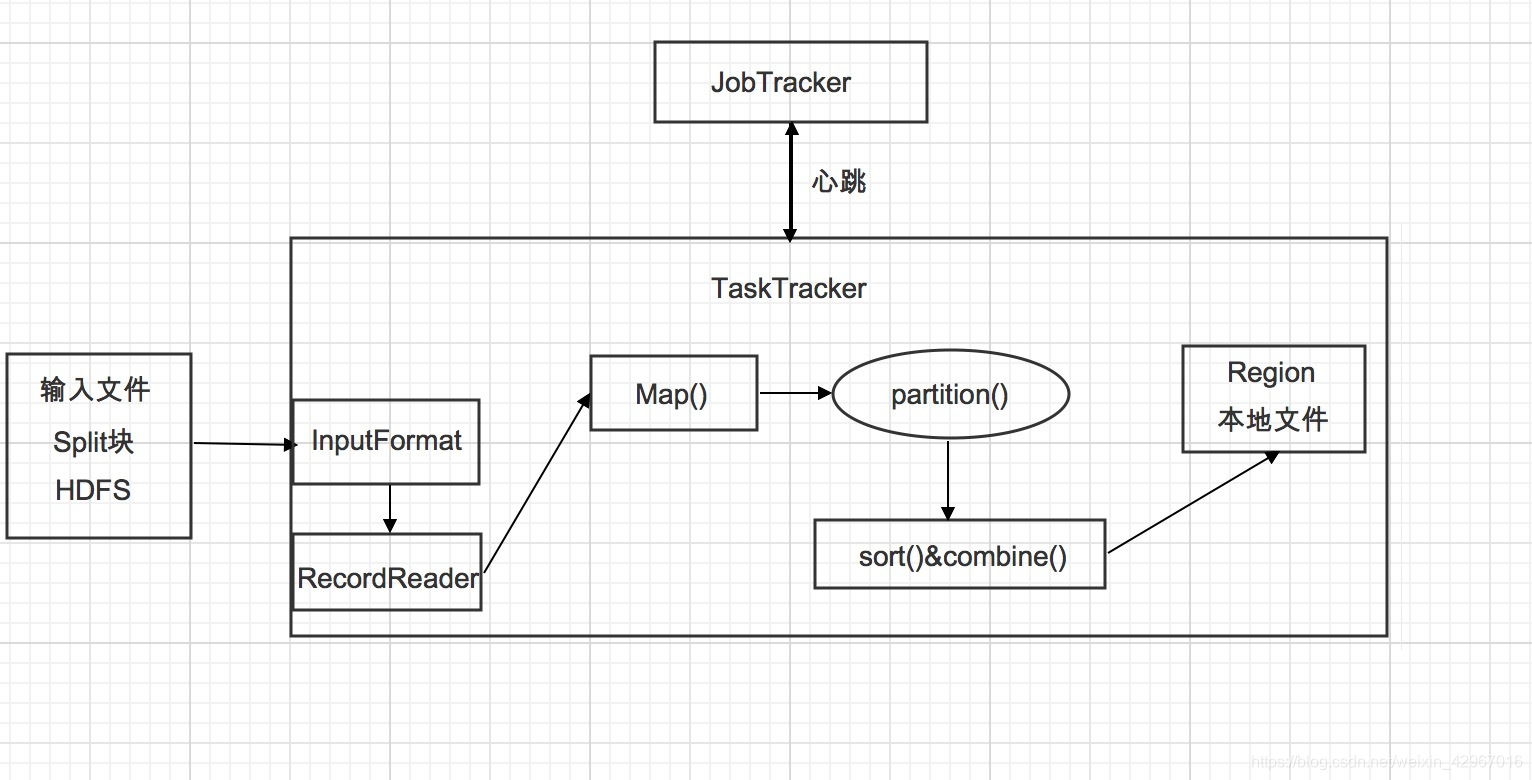
- 通過InputFormat介面獲得InputSplit的實現,然後對輸入的資料切分。每一個Split分塊對應一個Mapper任務。
- 通過RecordReader物件讀取生成<k,v>鍵值對。Map函式接受資料並處理後輸出<k1,v1>鍵值對。
- 通過context.collect方法寫入context物件中。當鍵值對集中被收集後,會被Partition類中的partition()函式以指定方式區分並寫入輸出緩衝區(系統預設的是HashPartitioner),同時呼叫sort()進行排序。
- 如果使用者指定了Combiner,則會將鍵值對進行combine合併(相當於map端的reduce),輸出到reduce寫入檔案。
Reducer
-
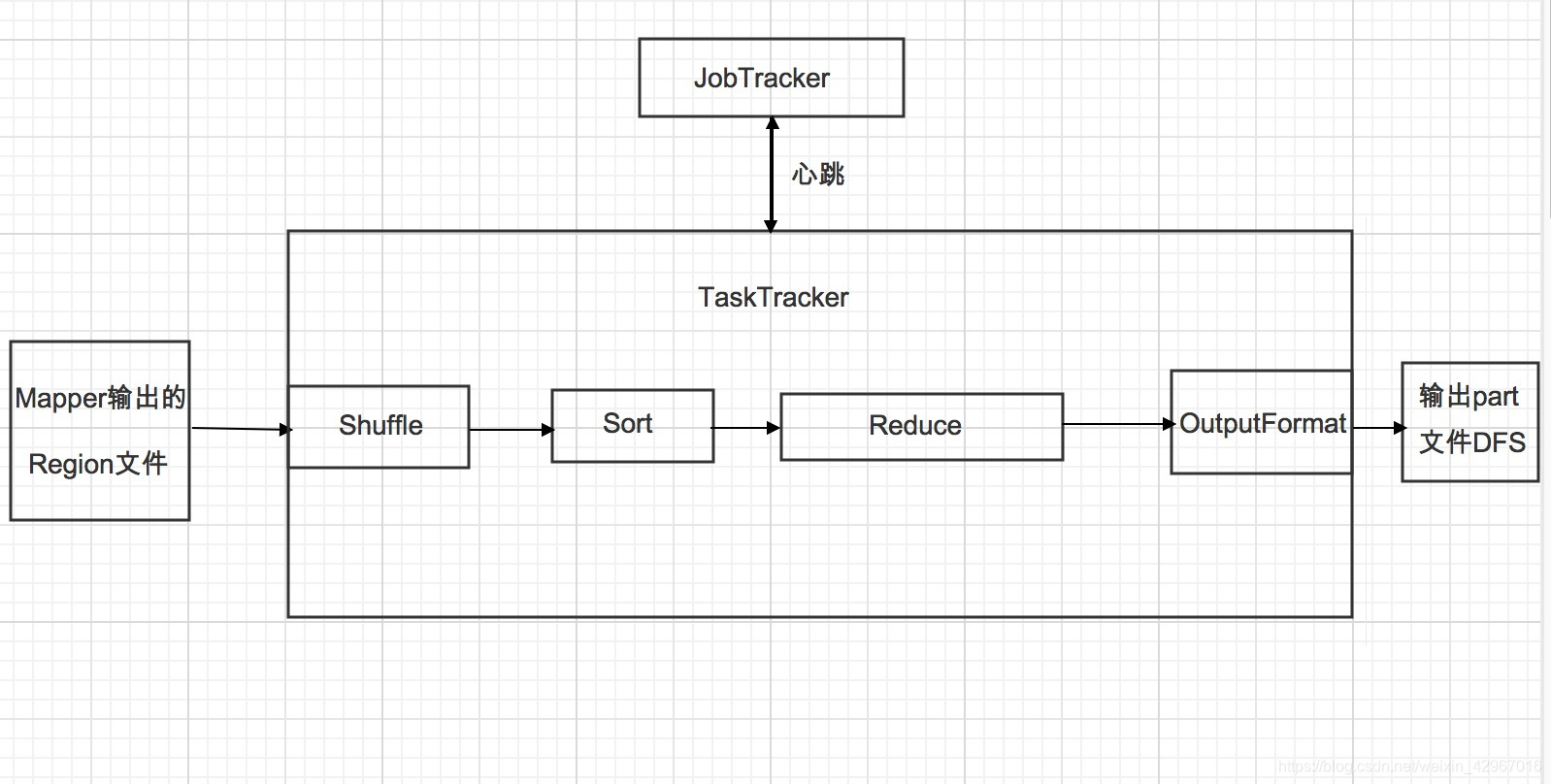
Reducer將與一個key關聯的一組中間數值集歸約為一個更小的數值集。
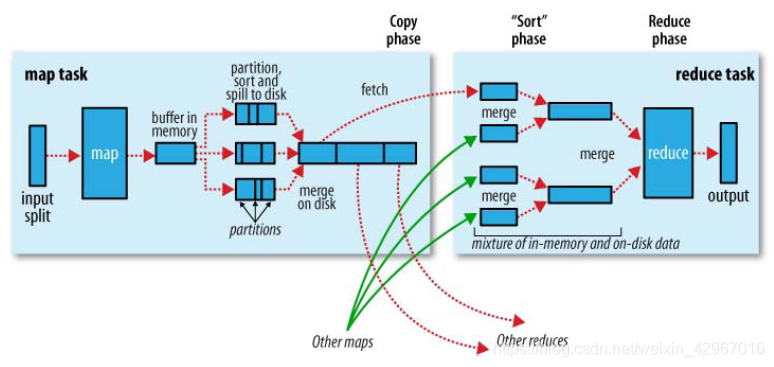
1.Shuffle階段。框架通過HTTP協議為每個Reducer獲得所有Mapper輸出中與之相關的分塊,這一階段也稱混洗階段,所做的大量操作就是資料複製,因此也可以稱為資料複製階段。
2.Sort階段。 框架按照key的值對Reducer的輸入進行分組(因為不同的Mapper輸出可能會有相同的key)。 Shuffle和Sort是同時進行的,Map的輸出也是一邊被取回一邊被合併的。 如果需要改變分組方式,則需要指定一個Compartor,實現二次排序(後面會介紹)。
3.Reduce階段。 呼叫Reduce()函式,對Shuffle和sort得到的<key,(list of values)>進行處理,輸出結果到DFS中。
結構圖示
輸入/輸出格式(常用)
- InputFormat
- 檢查作業輸入的有效性。
- 把輸入檔案切分成多個邏輯InputSplit例項,並把每個例項分發給一個Mapper(一對一);FileSplit是預設的InputSplit,通過write(DataOutput out)和readFields(DataInput in)兩種方法進行序列化和反序列化。
- 提供RecordReader實現。
- OutputFormat
- 檢驗作業的輸出。
- 驗證輸出結果型別是否如在Config中所配置的。
- 提供一個RecordWriter的實現,用來輸出作業結果。
核心問題
Map和Reduce數量
-
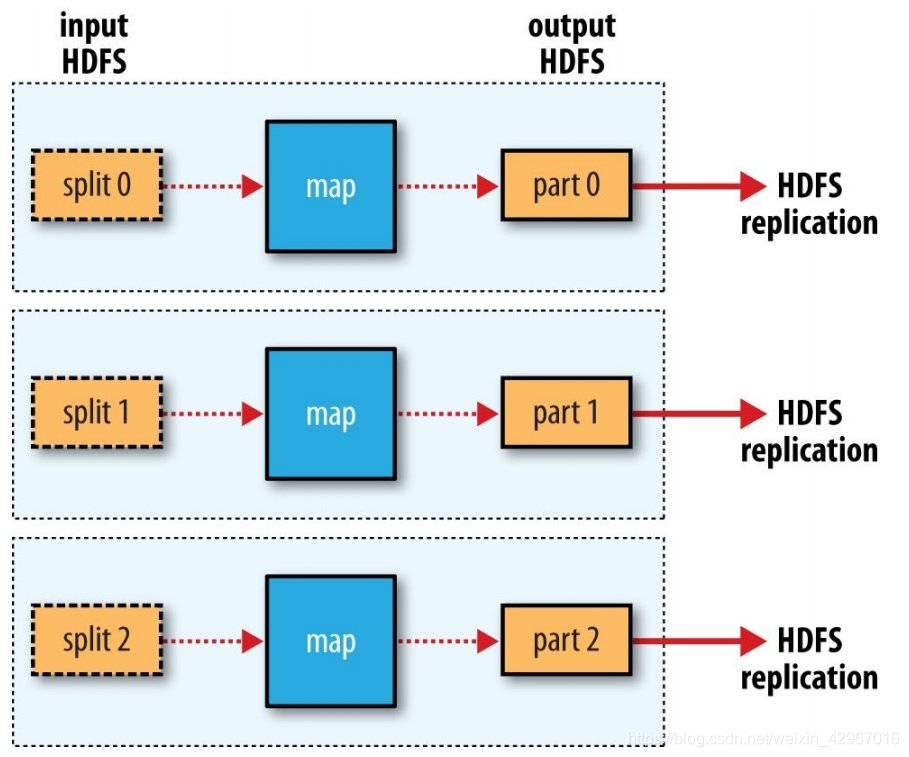
Map數量通常由 Hadoop叢集的DFS塊大小確定 ,也就是輸入檔案的總塊數。大致是每一個Node是10~100個。
Reduce的數量有3種情況:0(特殊),1,多個。
-
單個Reduce:

-
多個Reduce

-
數量為0(適應於不需要歸約和處理的作業)
作業配置
- 作業配置的相關設定方法
| 作業配置方法 | 功能說明 |
|---|---|
| setNumReduceTasks | 設定reduce數目 |
| setNumMapTasks | 設定Map數目 |
| setInputFormatClass | 設定輸入檔案格式類 |
| setOutputFormatClass | 設定輸出檔案格式類 |
| setMapperClass | 輸出Map類 |
| setCombiner | 設定Combiner類 |
| setReducerClass | 設定Reduce類 |
| setPartitionerClass | 設定Partitioner類 |
| setMapOutputKeyClass | 設定Map輸出的Key類 |
| setMapOutputValueClass | 設定Map輸出的Value類 |
| setOutputKeyClass | 設定輸出key類 |
| setCompressMapOutput | 設定Map輸出是否壓縮 |
| setOutputValueClass | 設定輸出value類 |
| setJobName | 設定作業名字 |
| setSpeculativeExecution | 設定是否開啟預防性執行 |
| setMapSpeculativeExecution | 設定是否開啟Map任務的預防性執行 |
| setReduceSpeculativeExecution | 設定是否開啟Reduce任務的預防性執行 |
作業排程
- 排程的功能是將各種型別的作業在排程演算法作用下分配給Hadoop叢集中的計算節點,從而達到 分散式和平行計算 的目的。
- 排程演算法模組中至少涉及兩個重要流程:1.作業的選擇 2.任務的分配。
排程過程 :
-
1)MapReduce框架中作業通常是通過JobClient.runJob(job)方法提交到JobTracker,JobTracker接收到JobClient的請求後將其加入作業排程佇列中。
2)然後JobTracker一直等待JobClient通過RPC向其提交作業,而TaskTracker則一直通過RPC向JobTracker傳送心跳訊號詢問是否有任務可執行,有則請求JobTracker派發任務給它執行。
3)如果JobTracker的作業佇列不為空,則TaskTracker傳送的心跳將會獲得JobTracker向它派發的任務。
這是一個主動請求的任務:slave的TaskTracker主動向master的JobTracker請求任務。4)當TaskTracker接到任務後,通過自身排程在本slave建立起Task,執行任務。
常用排程器 主要包括:JobQueueTaskScheduler(FIFO排程器),CapacityScheduler(容量排程器),Fair Scheduler(公平排程器)等。
有用的MapReduce特性
- Counters 計數器
- DistributedCache 分散式快取
- Tool 工具
- Compression 資料壓縮
(後面會做介紹)