
tensorflow學習(4):損失函式+優化方法
一、損失函式
提起損失函式,大概最常用的就是交叉熵和均方誤差了。
1.交叉熵損失函式:針對分類問題
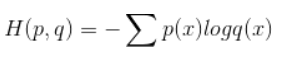
假設某個樣例的正確答案是(1,0,0),預測值是[0.5,0.4,0.1]
那麼其交叉熵為H((1,0,0),(0.5,0.4,0.1))=-(1log0.5+0log0.4+0*log0.1)=0.3
所以,在程式碼實現時如下:假設label為y,預測值為y’,則交叉熵為
cross_entropy = -tf.reduce_mean(y * log(y’))
這裡的乘法是對應元素相乘,reduce_mean函式時求平均值
另外,在得到預測值過程中,往往採用softmax,所以cross_entropy一般和softmax連用,有如下已經封裝好的損失函式:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=y’)
2.均方差(MSE):針對迴歸問題
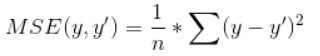
mse = tf.reduce_mean(tf.square(y-y’))
3.除了以上兩個現成的函式,我們還可以自定義函式,如分段函式:
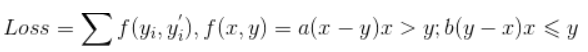
大家將就著看看吧,f是分段函式,Loss是對f求和。
這裡引入兩個新的函式:
1)tf.greater(x,y):比較張量x,y中每一個元素的大小,返回的比較結果和輸入張量的維度相同。大於則True,反之False
2)tf.where(condition,a,b):第一個為選擇條件根據,當選擇條件為True時,tf.where選擇第二個引數中的值,否則選擇第三個引數中的值。
因此,針對上述損失函式,我們有如下表達:
Loss = tf.reduce_sum(tf.where(tf.greater(x,y),a*(x-y),b*(y-x)))
二、優化方法
有了損失函式後,就需要採用反向傳播演算法來減小Loss值,使之收斂到一個最小值(如果是凸函式肯定是最小值,反之是極小值)
1.tf.train_exponential_decay
在使用反向傳播演算法時,學習速率learning_rate的設定非常關鍵,不能過大(無法收斂)也不能過小(收斂太慢),因此我們要採取一種較好的方式。而tensorflow提供了一種靈活的學習率設定方法——指數衰減法。tf.train_exponential_decay函式實現了指數衰減學習率。通過這個函式,可以先使用較大的學習率來快速得到一個比較優的解,然後隨著迭代的繼續逐步減小學習率,使得模型在訓練後期更加穩定。該函式會指數級的減小學習率,它實現瞭如下程式碼的功能:
dacayed_learning_rate = learning_rate*decay_rate ^(global_step/decay_steps)
其中,learning_rate是初始學習率,decay_rate是衰減係數,decay_steps為衰減速度。
而且tf.train_exponential_decay可以通過設定staircase的值來設定衰減方式,預設值為True,就是上述公式;如果設定為FALSE,則global_step/decay_steps轉化為整數,可以想象就是一節一節的臺階。
好了,將完了各引數含義,接下來就是使用了:
learning_rate = tf.train.exponential_decay(0.1,global_step,100,0.96,staircase=True)
初始學習率為0.1,每100輪後學習率乘以0.96(因為staircase=True)
2.正則化
為了避免過擬合問題,一個非常常用的方法就是正則化,分為L1正則化和L2正則化。一般L2正則化比較常用:
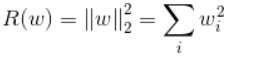
regularization = tf.contrib.layers.l2_regularizer(lambda)(w)
lambda是正則化項的權重,一般指定為0.5
但是,當網路結構複雜之後定義網路結構的部分和計算損失函式的部分可能不在同一個函式中,這樣通過變數這種方式計算損失函式就很不方便了(比如有20層,那麼要重寫20次上面這個函式,複雜的同時也不易讀懂)。為了解決這個問題,可以使用tensorflow提供了集合collection,它可以在一個計算圖中儲存一組實體(比如張量)。以下程式碼給出了計算5層神經網路帶L2正則化的計算方法
import tensorflow as tf
def get_weitght(shape,lambda):
var = tf.Variable(tf.random_normal(shape),dtype = tf.float32)
#add_to_collection函式將這個新生成邊浪的L2正則化損失項加入這個集合。
#第一個引數是集合的名字,第二個引數是要加入這個集合的內容
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(lambda)(var))
return var
x = tf.placeholder(tf.float32,shape=(None,2))
y_ = tf.tf.placeholder(tf.float32,shape=(None,1))
batch_size = 8
layer_dimension = [2,10,10,10,1]
num_layers = len(layer_dimension)
cur_layer = x #這個變數維護前向傳播時最深層的節點,開始的時候是輸入層
in_dimension = layer_dimension[0]
#通過迴圈來生成5層全連線的神經網路結構
for i in range(1,num_layers):
out_dimension = layer_dimension[i]
weight = get_weight([in_dimension, out_dimension], 0.001)
bias = tf.Variable(tf.constant(0.1, shape = [out_dimension]))
cur_layer = tf.nn.relu(tf.matmul(cur_layer, weight) + bias)
in_dimension = layer_dimension[i]
mse_loss = tf.reduce_mean(tf.square(y_ - cur_layer))
tf.add_to_collection('losses', mse_loss)
#tf.add_n是將一個列表的元素相加
loss = tf.add_n(tf.get_collection('losses'))
3.滑動平均模型
這個模型是作用在變數上的,可以使模型在測試資料上更加robust的方法。在採用隨機梯度下降演算法訓練神經網路時,使用滑動平均模型在很多應用中都可以在一定程度提高最終模型在測試資料上的表現。
在tensorflow中提供了tf.train.ExponentialMovingAverage來實現滑動平均模型。在初始化ExponentialMovingAverage時,需要提供一個衰減率decay,這個衰減率將用於控制模型更新的速度。ExponentialMovingAverage對每一個變數會維護一個影子變數(shadow variable),這個影子變數的初始值就是相應變數的初始值,而每次執行變數更新時,影子變數的值會更新為:
shadow_variable = decay*shadow_variable+(1-decay)*variable
為了使得模型在訓練前期可以更新的更快,ExponentialMovingAverage還提供了num_updates引數來動態設定decay大小,如果在ExponentialMovingAverage初始化時提供了num_updates引數,那麼每次使用的衰減率將是:
min{decay, (1+num_updates)/(10+num_updates)}
下面展示如何使用滑動平均模型(注:使用滑動平均模型的引數都必須是float型別的)
v1 = tf.Variable(0,dtype = tf.float32)
#這裡的step就是全域性訓練的輪數,和上述num_updates意義相同
#定義一個滑動平均的類ema
ema = tf.train.ExponentialMovingAverage(0.99, step)
#定義一個更新變數滑動平均的操作,這裡需要給定一個列表,每次
#執行這個操作時,列表中的變數都會被更新
maintian_averages_op = ema.apply([v1])
使用起來是不是很簡單,哈哈哈