
譯文 FaceNet: A Unified Embedding for Face Recognition and Clustering
摘要
Despite significant recent advances in the field of face recognition [10, 14, 15, 17], implementing face verification and recognition efficiently at scale presents serious challenges to current approaches. In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors.儘管最近在人臉識別領域取得了重大進展[10,14,15,17],但大規模有效地實施面部驗證和識別對當前方法提出了嚴峻挑戰。 在本文中,我們提出了一個名為FaceNet的系統,它直接學習從面部影象到緊湊的歐幾里德空間的對映,其中距離直接對應於面部相似性的度量。 生成此空間後,可以使用FaceNet嵌入作為特徵向量的標準技術輕鬆實現面部識別,驗證和聚類等任務。
Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face.我們的方法使用深度卷積網路訓練直接優化嵌入本身,而不是像以前的深度學習方法那樣的中間瓶頸層。 為了訓練,我們使用使用新穎的線上三重挖掘方法生成的大致對齊的匹配/非匹配面部補丁的三元組。 我們的方法的好處是更高的表現效率:我們使用每面只有128個位元組來實現最先進的面部識別效能。
On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result [15] by 30% on both datasets.在廣泛使用的Labeled Faces in the Wild(LFW)資料集中,我們的系統實現了99.63%的新記錄準確率。 在YouTube Faces DB上,它達到了95.12%。 與兩個資料集中的最佳釋出結果[15]相比,我們的系統將錯誤率降低了30%。
We also introduce the concept of harmonic embeddings, and a harmonic triplet loss, which describe different versions of face embeddings (produced by different networks) that are compatible to each other and allow for direct comparison between each other.我們還介紹了諧波嵌入和諧波三重態損耗的概念,它描述了不同版本的面嵌入(由不同網路產生),它們彼此相容並允許彼此之間的直接比較。
1. 介紹
In this paper we present a unified system for face verification (is this the same person), recognition (who is this person) and clustering (find common people among these faces). Our method is based on learning a Euclidean embedding per image using a deep convolutional network. The network is trained such that the squared L2 distances in the embedding space directly correspond to face similarity: faces of the same person have small distances and faces of distinct people have large distances.在本文中,我們提出了一個統一的面部驗證系統(在這裡是指同一個人),識別(誰是這個人)和聚類(在這些面孔中找到相同的人)。 我們的方法基於使用深度卷積網路學習每個影象的歐幾里德嵌入。 訓練網路使得嵌入空間中的平方L2距離直接對應於面部相似性:同一人的面部具有小距離並且不同人的面部具有大距離。
Once this embedding has been produced, then the aforementioned tasks become straight-forward: face verification simply involves thresholding the distance between the two embeddings; recognition becomes a k-NN classification problem; and clustering can be achieved using off-theshelf techniques such as k-means or agglomerative clustering.一旦產生了這種嵌入,則上述任務變得直截了當:面部驗證僅涉及對兩個嵌入之間的距離進行閾值處理; 識別任務成為k-NN分類問題; 並且可以使用諸如k均值或凝聚聚類之類的現有技術來實現聚類。
Previous face recognition approaches based on deep networks use a classification layer [15, 17] trained over a set of known face identities and then take an intermediate bottle-neck layer as a epresentation used to generalize recognition beyond the set of identities used in training. The downsides of this approach are its indirectness and its inefficiency: one has to hope that the bottleneck representation generalizes well to new faces; and by using a bottleneck layer the representation size per face is usually very large (1000s of dimensions). Some recent work [15] has reduced this dimensionality using PCA, but this is a linear transformation that can be easily learnt in one layer of the network.先前基於深度網路的面部識別方法使用在一組已知面部身份上訓練的分類層[15,17],然後採用中間瓶頸層作為表示,用於概括超出訓練中使用的身份集合的識別。 這種方法的缺點是它的間接性和效率低下:人們不得不希望瓶頸表現能夠很好地概括為新面孔; 通過使用瓶頸層,每個面的表示大小通常非常大(1000維)。 最近的一些工作[15]使用PCA降低了這種維度,但這是一種線性轉換,可以在網路的一個層中輕鬆學習。
In contrast to these approaches, FaceNet directly trains its output to be a compact 128-D embedding using a tripletbased loss function based on LMNN [19]. Our triplets consist of two matching face thumbnails and a non-matching face thumbnail and the loss aims to separate the positive pair from the negative by a distance margin. The thumbnails are tight crops of the face area, no 2D or 3D alignment, other than scale and translation is performed.與這些方法相比,FaceNet直接將其輸出訓練為使用基於LMNN的使用三重損耗函式的緊湊128-D嵌入[19]。 我們的三元組由兩個匹配的面部縮圖和一個不匹配的面部縮圖組成,並且損失的目標是將正對與負對分開一個距離邊距。 縮圖是面部區域的緊密裁剪,除了縮放和平移之外,沒有2D或3D對齊。
Choosing which triplets to use turns out to be very important for achieving good performance and, inspired by curriculum learning [1], we present a novel online negative exemplar mining strategy which ensures consistently increasing difficulty of triplets as the network trains. To improve clustering accuracy, we also explore hard-positive mining techniques which encourage spherical clusters for the embeddings of a single person.選擇使用哪些三元組對於實現良好的表現非常重要,並且受Curriculum learning的啟發[1],我們提出了一種新穎的線上負面樣本挖掘策略,確保在網路訓練時不斷增加三元組的難度。 為了提高聚類精度,我們還探索了硬陽性挖掘技術,該技術鼓勵球形聚類用於嵌入單個人。

Figure 1. Illumination and Pose invariance. Pose and illumination have been a long standing problem in face recognition. This figure shows the output distances of FaceNet between pairs of faces of the same and a different person in different pose and illumination combinations. A distance of 0:0 means the faces are identical, 4:0 corresponds to the opposite spectrum, two different identities. You can see that a threshold of 1.1 would classify every pair correctly.圖1.照明和姿勢不變性。 姿勢和照明是人臉識別中長期存在的問題。 該圖顯示了FaceNet在不同姿勢和照明組合中相同和不同人的面對之間的輸出距離。 距離0.0表示面相同,4.0對應相反的光譜,兩個不同的身份。 您可以看到1.1的閾值會正確地對每一對進行分類。
As an illustration of the incredible variability that our method can handle see Figure 1. Shown are image pairs from PIE [13] that previously were considered to be very difficult for face verification systems.作為我們的方法可以處理的令人難以置信的可變性的說明,請參見圖1.顯示來自PIE [13]的影象對,之前被認為對於面部驗證系統來說非常困難。
An overview of the rest of the paper is as follows: in section 2 we review the literature in this area; section 3.1 defines the triplet loss and section 3.2 describes our novel triplet selection and training procedure; in section 3.3 we describe the model architecture used. Finally in section 4 and 5 we present some quantitative results of our embeddings and also qualitatively explore some clustering results.本文其餘部分的概述如下:在第2節中,我們回顧了該領域的文獻; 第3.1節定義了三重態損失,第3.2節描述了我們新穎的三重態選擇和訓練程式; 在3.3節中,我們描述了使用的模型架構。 最後在第4節和第5節中,我們提供了嵌入的一些定量結果,並定性地探索了一些聚類結果。
2. 相關工作
Similarly to other recent works which employ deep networks [15, 17], our approach is a purely data driven method which learns its representation directly from the pixels of the face. Rather than using engineered features, we use a large dataset of labelled faces to attain the appropriate invariances to pose, illumination, and other variational conditions.與其他最近使用深度網路的作品[15,17]類似,我們的方法是一種純粹的資料驅動方法,它直接從面部畫素中學習它的表示。 我們使用標記過人臉的大型資料集來獲得姿勢,光照和其他變化條件的適當不變性,而不是使用工程特徵。
In this paper we explore two different deep network architectures that have been recently used to great success in the computer vision community. Both are deep convolutional networks [8, 11]. The first architecture is based on the Zeiler&Fergus [22] model which consists of multiple interleaved layers of convolutions, non-linear activations, local response normalizations, and max pooling layers. We additionally add several 11d convolution layers inspired by the work of [9]. The second rchitecture is based on the Inception model of Szegedy et al. which was recently used as the winning approach for ImageNet 2014 [16]. These networks use mixed layers that run several different convolutional and pooling layers in parallel and concatenate their responses. We have found that these models can reduce the number of parameters by up to 20 times and have the potential to reduce the number of FLOPS required for comparable performance.在本文中,我們探討了最近在計算機視覺社群中取得巨大成功的兩種不同的深度網路架構。 兩者都是深度卷積網路[8,11]。 第一種架構基於Zeiler&Fergus [22]模型,該模型由多個交錯的卷積層,非線性啟用,區域性響應歸一化和最大池化層組成。 我們還增加了幾個1*1*d卷積層,靈感來自[9]的工作。 第二種結構基於Szegedy等人的Inception模型。 最近被用作ImageNet 2014的獲勝方法[16]。 這些網路使用混合層,並行執行幾個不同的卷積和池化層並連線它們的響應。 我們發現這些模型可以將引數數量減少多達20倍,並且有可能減少可比效能所需的FLOPS數量。
There is a vast corpus of face verification and recognition works. Reviewing it is out of the scope of this paper so we will only briefly discuss the most relevant recent work.目前有大量的面部驗證和識別工作。 審查它超出了本文的範圍,因此我們將僅簡要討論最相關的最新工作。
The works of [15, 17, 23] all employ a complex system of multiple stages, that combines the output of a deep convolutional network with PCA for dimensionality reduction and an SVM for classification.論文[15,17,23]都使用了一個複雜的多級系統,它將深度卷積網路的輸出與PCA相結合,以降低維數,並將SVM用於分類。
Zhenyao et al. [23] employ a deep network to “warp” faces into a canonical frontal view and then learn CNN that classifies each face as belonging to a known identity. For face verification, PCA on the network output in conjunction with an ensemble of SVMs is used.Zhenyao等 [23]採用深度網路將面部“扭曲”成規範的正面檢視,然後學習CNN,將每個面部分類為屬於已知身份。 對於面部驗證,使用網路輸出上的PCA和一組SVM。
Taigman et al. [17] propose a multi-stage approach that aligns faces to a general 3D shape model. A multi-class network is trained to perform the face recognition task on over four thousand identities. The authors also experimented with a so called Siamese network where they directly optimize the L1-distance between two face features. Their best performance on LFW (97:35%) stems from an ensemble of three networks using different alignments and color channels. The predicted distances (non-linear SVM predictions based on the 2 kernel) of those networks are combined using a non-linear SVM.Taigman等 [17]提出了一種多階段方法,將面部與一般的三維形狀模型對齊。 訓練多級網路以執行超過四千個特徵的面部識別任務。 作者還試驗了一個所謂的連體網路,他們直接優化了兩個面部特徵之間的L1距離。 他們在LFW上的最佳表現(97.35%)源於使用不同比對和顏色通道的三個網路的集合。 使用非線性SVM組合這些網路的預測距離(基於α2核心的非線性SVM預測)。
Sun et al. [14, 15] propose a compact and therefore relatively cheap to compute network. They use an ensemble of 25 of these network, each operating on a different face patch. For their final performance on LFW (99:47% [15]) the authors combine 50 responses (regular and flipped). Both PCA and a Joint Bayesian model [2] that effectively correspond to a linear transform in the embedding space are employed. Their method does not require explicit 2D/3D alignment. The networks are trained by using a combination of classification and verification loss. The verification loss is similar to the triplet loss we employ [12, 19], in that it minimizes the L2-distance between faces of the same identity and enforces a margin between the distance of faces of different identities. The main difference is that only pairs of images are compared, whereas the triplet loss encourages a relative distance constraint.孫等 [14,15]提出了一種緊湊且因此相對便宜的計算網路。 他們使用25個這樣的網路集合,每個網路在不同的面部補丁上執行。 對於他們在LFW上的最終表現(99:47%[15]),作者結合了50個回答(常規和翻轉)。 PCA和聯合貝葉斯模型[2]都有效地對應於嵌入空間中的線性變換。 他們的方法不需要明確的2D / 3D對齊。 通過使用分類和驗證丟失的組合損失函式來訓練網路。 驗證損失函式類似於我們採用的三元組損失[12,19],因為它最小化了相同身份的面部之間的L2距離,並在不同身份的面部距離之間實施了邊界。 主要區別在於僅比較成對影象,而三元組損失促使相對距離約束。
A similar loss to the one used here was explored in Wang et al. [18] for ranking images by semantic and visual similarity.Wang等人研究了與此處使用的類似的損失。 [18]用於通過語義和視覺相似性對影象進行排序。
3. 方法
FaceNet uses a deep convolutional network. We discuss two different core architectures: The Zeiler&Fergus [22] style networks and the recent Inception [16] type networks. The details of these networks are described in section 3.3.FaceNet使用深度卷積網路。 我們討論了兩種不同的核心架構:Zeiler&Fergus [22]式網路和最近的Inception [16]型網路。 這些網路的細節在3.3節中描述。
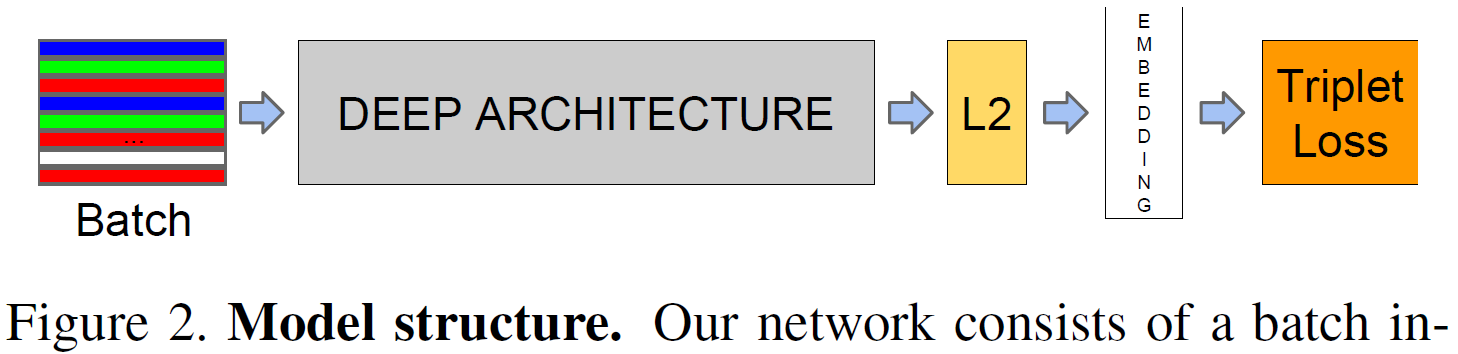
Figure 2. Model structure. Our network consists of a batch input layer and a deep CNN followed by L2 normalization, which results in the face embedding. This is followed by the triplet loss during training.圖2.模型結構。 我們的網路由批量輸入層和深度CNN組成,然後進行L2歸一化,從而實現面嵌入。 接下來是訓練期間的三元組損失。
Given the model details, and treating it as a black box (see Figure 2), the most important part of our approach lies in the end-to-end learning of the whole system. To this end we employ the triplet loss that directly reflects what we want to achieve in face verification, recognition and clustering. Namely, we strive for an embedding f(x), from an image x into a feature space Rd, such that the squared distance between all faces, independent of imaging conditions, of the same identity is small, whereas the squared distance between a pair of face images from different identities is large.將模型細節視為黑盒子(見圖2),我們方法中最重要的部分在於整個系統的端到端學習。 為此,我們採用三元組損失,直接反映了我們想要在面部驗證,識別和聚類中實現的目標。 即,我們努力嵌入f(x),從影象x到特徵空間Rd,使得相同身份的所有面之間的平方距離(與成像條件無關)很小,而一對之間的平方距離很小。 來自不同身份的面部影象很大。
Although we did not directly compare to other losses, e.g. the one using pairs of positives and negatives, as used in [14] Eq. (2), we believe that the triplet loss is more suitable for face verification. The motivation is that the loss from [14] encourages all faces of one identity to be projected onto a single point in the embedding space. The triplet loss, however, tries to enforce a margin between each pair of faces from one person to all other faces. This allows the faces for one identity to live on a manifold, while still enforcing the distance and thus discriminability to other identities.雖然我們沒有直接與其他損失進行比較,例如 使用[14] Eq中使用的正和負對的那個。 (2),我們認為三聯體損失更適合面部識別。 動機是[14]的損失鼓勵將一個身份的所有面部投射到嵌入空間中的單個點上。 然而,三重態損失試圖在從一個人到所有其他面部的每對面部之間強制執行邊緣。 這允許一個身份的面部應用在個人的多樣上,同時仍然強制距離並因此可以與其他身份相區別。
The following section describes this triplet loss and how it can be learned efficiently at scale.以下部分描述了這種三元組損失以及如何有效地大規模學習它。
3.1. 三元組損失
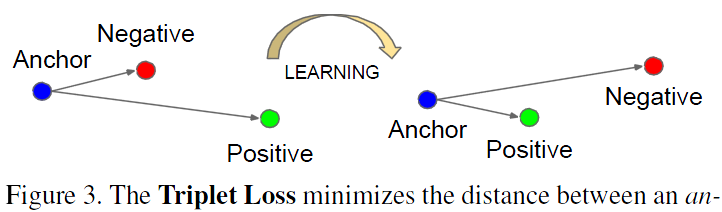
Figure 3. The Triplet Loss minimizes the distance between an anchor and a positive, both of which have the same identity, and maximizes the distance between the anchor and a negative of a different identity.圖3.三聯體損失最小化錨和陽性之間的距離,兩者具有相同的身份,並最大化錨和不同身份的陰性之間的距離。
The embedding is represented by f(x) 2 Rd. It embeds an image x into a d-dimensional Euclidean space. Additionally, we constrain this embedding to live on the d-dimensional hypersphere, i.e. kf(x)k2 = 1. This loss is motivated in [19] in the context of nearest-neighbor classification. Here we want to ensure that an image xai (anchor) of a specific person is closer to all other images xpi (positive) of the same person than it is to any image xni (negative) of any other person. This is visualized in Figure 3.嵌入由f(x)2 Rd表示。 它將影象x嵌入到d維歐幾里德空間中。 另外,我們將這種嵌入限制在d維超球面上,即kf(x)k2 = 1.這種損失在[19]中在最近鄰分類的背景下被激發。 在這裡,我們希望確保特定人的影象xai(錨)更接近同一個人的所有其他影象xpi(正面),而不是任何其他人的任何影象xni(負面)。 見圖3中的圖示。因此
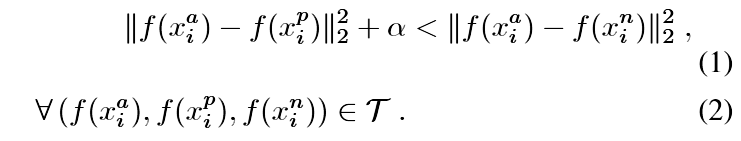
where a is a margin that is enforced between positive and negative pairs. T is the set of all possible triplets in the training set and has cardinality N.在公式裡a是正負對之間區分界限的閾值。 T是訓練集中所有可能的三元組的集合,並具有基數N.損失函式定義為
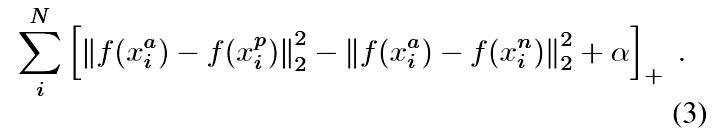
Generating all possible triplets would result in many triplets that are easily satisfied (i.e. fulfill the constraint in Eq. (1)). These triplets would not contribute to the training and result in slower convergence, as they would still be passed through the network. It is crucial to select hard triplets, that are active and can therefore contribute to improving the model. The following section talks about the different approaches we use for the triplet selection.生成所有可能的三元組將導致許多容易滿足的三元組(即滿足方程(1)中的約束)。 這些三元組不會對訓練有所貢獻,導致收斂速度變慢,因為它們仍會通過網路傳遞。 選擇活躍的硬三元組至關重要,因此可以有助於改進模型。 下一節討論了我們用於三元組選擇的不同方法。
3.2. 三元組的選擇
In order to ensure fast convergence it is crucial to select triplets that violate the triplet constraint in Eq. (1). This means that, given xai, we want to select an xpi (hard positive) such that fff and similarly xni(hard negative) such that ddd。為了確保快速收斂,選擇違反方程式(1)中的三元組約束的三元組是至關重要的。 這意味著,對於給定的xai,我們需要選擇一個xpi(硬正)和xni(硬陰性),使得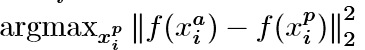 和
和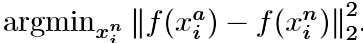 接近。
接近。
It is infeasible to compute the argmin and argmax across the whole training set. Additionally, it might lead to poor training, as mislabelled and poorly imaged faces would dominate the hard positives and negatives. There are two obvious choices that avoid this issue:在整個訓練集中計算argmin和argmax是不可行的。 此外,它可能導致訓練不佳,因為錯誤標記和不良成像的面孔將主導硬性積極和消極。 有兩個明顯的選擇可以避免這個問題:
- Generate triplets offline every n steps, using the most recent network checkpoint and computing the argmin and argmax on a subset of the data.使用最新的網路檢查點並在資料的子集上計算argmin和argmax,每n個步驟生成三元組。
- Generate triplets online. This can be done by selecting the hard positive/negative exemplars from within a mini-batch.線上生成三元組。 這可以通過從小批量中選擇硬正/負樣本來完成。
Here, we focus on the online generation and use large mini-batches in the order of a few thousand exemplars and only compute the argmin and argmax within a mini-batch.在這裡,我們專注於線上生成並使用大約幾千個樣本的大型小批量,並且僅在小批量中計算argmin和argmax。
To have a meaningful representation of the anchorpositive distances, it needs to be ensured that a minimal number of exemplars of any one identity is present in each mini-batch. In our experiments we sample the training data such that around 40 faces are selected per identity per minibatch. Additionally, randomly sampled negative faces are added to each mini-batch.為了有效地表示錨定距離,需要確保每個小批量中存在任何一個身份的最小數量的樣本。 在我們的實驗中,我們對訓練資料進行取樣,使得每個小批量每個身份選擇約40個面部。 另外,隨機抽樣的負面被新增到每個小批量。
Instead of picking the hardest positive, we use all anchorpositive pairs in a mini-batch while still selecting the hard negatives. We don’t have a side-by-side comparison of hard anchor-positive pairs versus all anchor-positive pairs within a mini-batch, but we found in practice that the all anchorpositive method was more stable and converged slightly faster at the beginning of training.我們不是挑選最差的正樣本,而是在小批量中使用所有正樣本錨定對,同時仍然選擇硬陰性。 我們沒有對一個小批次中的硬錨陽性對與所有錨 - 陽對進行並排比較,但我們在實踐中發現所有錨定陽性方法在開始時更穩定並且收斂得稍快一些 訓練。
We also explored the offline generation of triplets in conjunction with the online generation and it may allow the use of smaller batch sizes, but the experiments were inconclusive.我們還與線上生成一起探索了三聯體的離線生成,並且可能允許使用更小的批量,但實驗尚無定論。
Selecting the hardest negatives can in practice lead to bad local minima early on in training, specifically it can result in a collapsed model (i.e. f(x) = 0). In order to mitigate this, it helps to select xni such that選擇最難的負樣本實際上可能在訓練早期導致不良的區域性最小值,特別是它可能導致模型崩潰(如f(x)= 0)。 為了減輕這種影響,用如下條件選擇xni會有所幫助
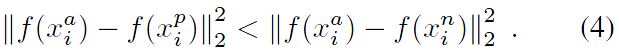
We call these negative exemplars semi-hard, as they are further away from the anchor than the positive exemplar, but still hard because the squared distance is close to the anchorpositive distance. Those negatives lie inside the margin .我們將這些負面樣本稱為半硬,因為它們遠離錨點而不是正樣本,但仍然很難,因為平方距離接近錨定距離。 這些負面影響在閾值範圍內。
As mentioned before, correct triplet selection is crucial for fast convergence. On the one hand we would like to use small mini-batches as these tend to improve convergence during Stochastic Gradient Descent (SGD) [20]. On the other hand, implementation details make batches of tens to hundreds of exemplars more efficient. The main constraint with regards to the batch size, however, is the way we select hard relevant triplets from within the mini-batches. In most experiments we use a batch size of around 1,800 exemplars.如前所述,正確的三元組選擇對於快速收斂至關重要。 一方面,我們希望使用小型小批量,因為這些趨向於在隨機梯度下降(SGD)期間改善收斂[20]。 另一方面,實施細節使得數十到數百個樣本的批次更有效。 然而,關於批量大小的主要限制是我們從小批量中選擇硬相關三元組的方式。 在大多數實驗中,我們使用的批量大小約為1,800個樣本。
3.3. 深度卷積網路
In all our experiments we train the CNN using Stochastic Gradient Descent (SGD) with standard backprop [8, 11] and AdaGrad [5]. In most experiments we start with a learning rate of 0:05 which we lower to finalize the model. The models are initialized from random, similar to [16], and trained on a CPU cluster for 1,000 to 2,000 hours. The decrease in the loss (and increase in accuracy) slows down drastically after 500h of training, but additional training can still significantly improve performance. The margin a is set to 0:2.在我們的所有實驗中,我們使用隨機梯度下降(SGD)的標準反向傳播[8,11]和AdaGrad [5]訓練CNN。 在大多數實驗中,我們從學習率0.05開始,我們降低以完成模型。 模型從隨機初始化,類似於[16],並在CPU叢集上訓練1,000到2,000小時。 在訓練500小時後,損失的減少(以及準確度的增加)急劇減慢,但額外的訓練仍然可以顯著提高效能。 邊距a設定為0.2。
We used two types of architectures and explore their trade-offs in more detail in the experimental section. Their practical differences lie in the difference of parameters and FLOPS. The best model may be different depending on the application. E.g. a model running in a datacenter can have many parameters and require a large number of FLOPS, whereas a model running on a mobile phone needs to have few parameters, so that it can fit into memory. All our models use rectified linear units as the non-linear activation function.我們使用了兩種型別的體系結構,並在實驗部分中更詳細地探討了它們的權衡。 它們的實際差異在於引數和FLOPS的差異。 根據應用,最佳型號可能會有所不同。 例如。 在資料中心中執行的模型可以具有許多引數並且需要大量FLOPS,而在行動電話上執行的模型需要具有很少的引數,以便它可以適合儲存器。 我們所有的模型都使用整流線性單元(RELU)作為非線性啟用函式。
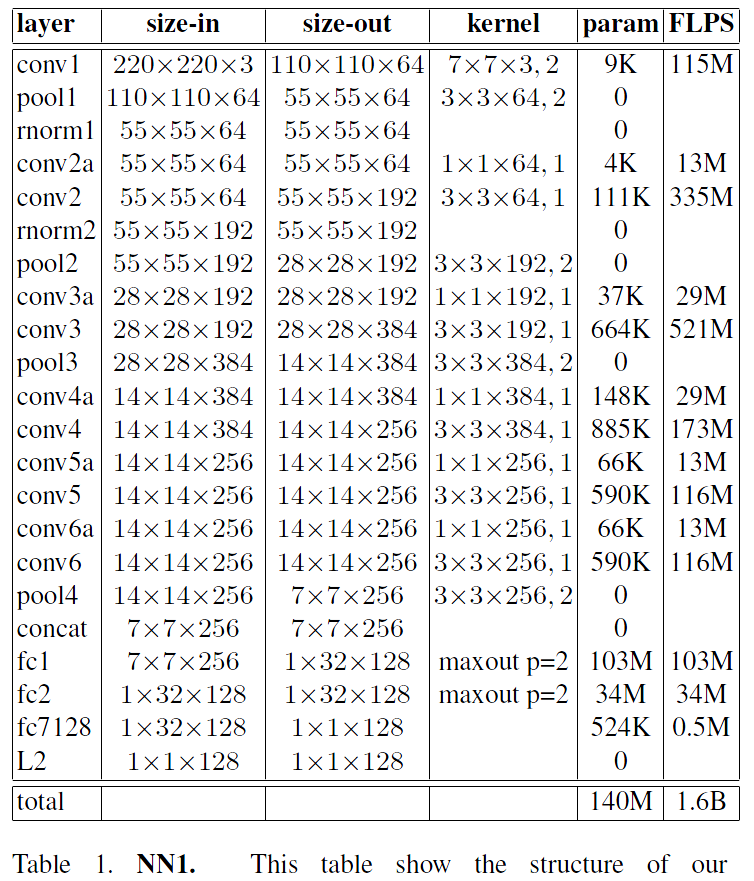
Table 1. NN1. This table show the structure of our Zeiler&Fergus [22] based model with 1*1 convolutions inspired by [9]. The input and output sizes are described in rows*cols*#filters. The kernel is specified as rows*cols; stride and the maxout [6] pooling size as p = 2.表1. NN1。 該表顯示了我們的Zeiler&Fergus [22]模型的結構,其靈感來自於[9]的1*1卷積。 輸入和輸出大小描述為 rows*cols*#filters。 核心被指定為rows*cols; 步幅和maxout [6]的池化大小為p = 2。
The first category, shown in Table 1, adds 11d convolutional layers, as suggested in [9], between the standard convolutional layers of the Zeiler&Fergus [22] architecture and results in a model 22 layers deep. It has a total of 140 million parameters and requires around 1.6 billion FLOPS per image.第一類結構,如表1所示,如[9]中建議,在Zeiler&Fergus [22]架構的標準卷積層之間增加1*1*d卷積層,得到22層深的模型。 它總共有1.4億個引數,每個影象需要大約16億FLOPS。
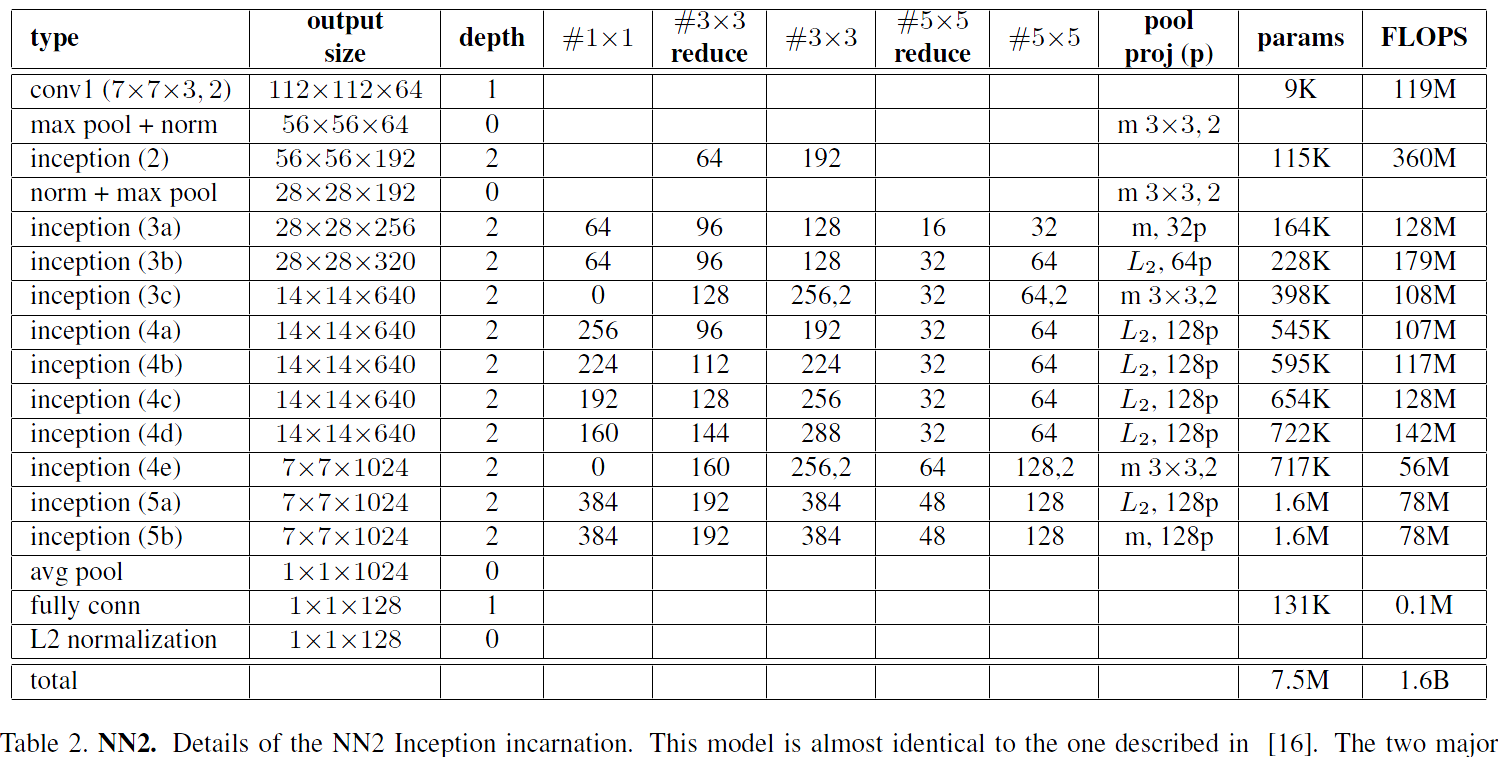
Table 2. NN2. Details of the NN2 Inception incarnation. This model is almost identical to the one described in [16]. The two major differences are the use of L2 pooling instead of max pooling (m), here specified. I.e. instead of taking the spatial max the L2 norm is computed. The pooling is always 33 (aside from the final average pooling) and in parallel to the convolutional modules inside each Inception module. If there is a dimensionality reduction after the pooling it is denoted with p. 11, 33, and 55 pooling are then concatenated to get the final output.表2.NN2。 NN2 Inception 實現的詳細資訊。 該模型幾乎與[16]中描述的模型相同。 兩個主要區別是使用L2池化而不是最大池化(m),這裡指定。即不是取空間最大值,而是計算L2範數。 池化窗總是3*3(除了最終的平均池化),並且與每個Inception模組內的卷積模組並行。 如果在池化後存在降維,則用p表示。 然後連線1*1,3*3和5*5池化會彙集以獲得最終輸出。
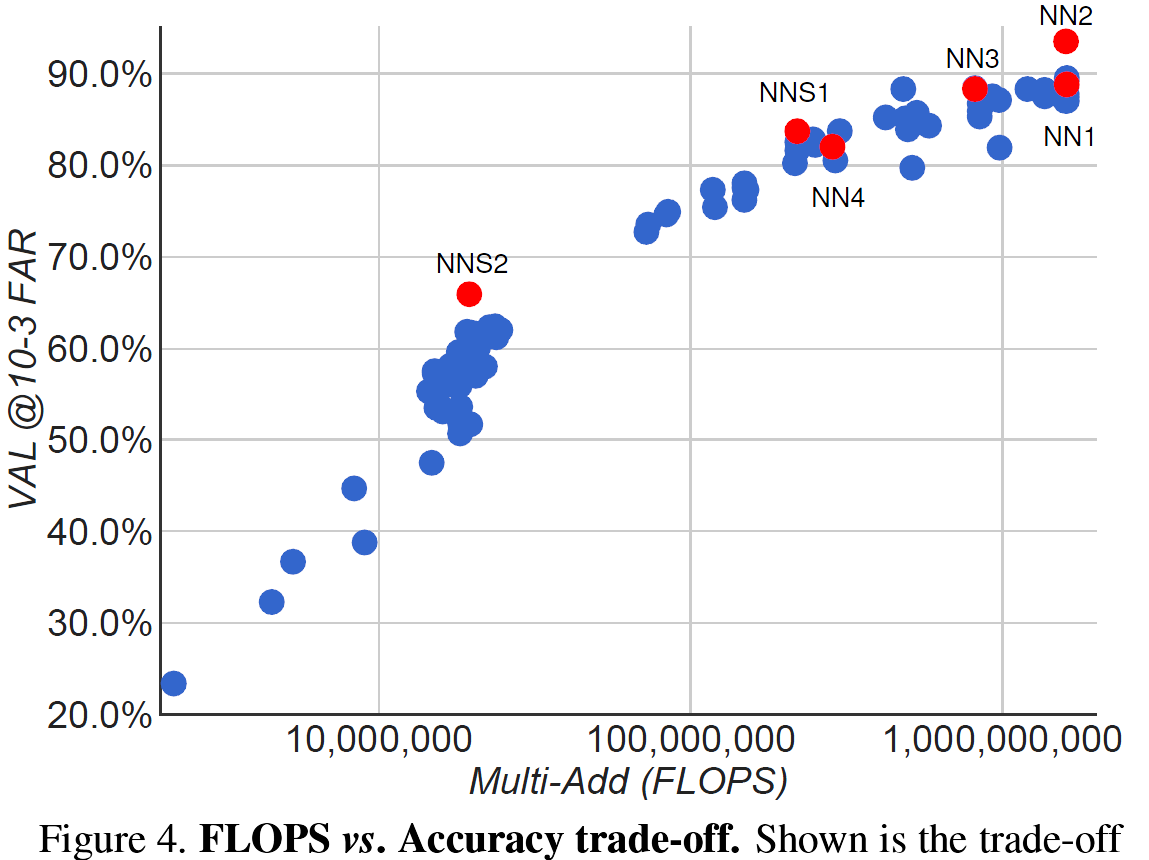
Figure 4. FLOPS vs. Accuracy trade-off. Shown is the trade-off between FLOPS and accuracy for a wide range of different model sizes and architectures. Highlighted are the four models that we focus on in our experiments.圖4. FLOPS與準確性的權衡。 所示為FLOPS與各種不同型號和架構的精度之間的權衡。 重點介紹了我們在實驗中關注的四種模型。
The second category we use is based on GoogLeNet style Inception models [16]. These models have 20* fewer parameters (around 6.6M-7.5M) and up to 5fewer FLOPS (between 500M-1.6B). Some of these models are dramatically reduced in size (both depth and number of filters), so that they can be run on a mobile phone. One, NNS1, has 26M parameters and only requires 220M FLOPS per image. The other, NNS2, has 4.3M parameters and 20M FLOPS. Table 2 describes NN2 our largest network in detail. NN3 is identical in architecture but has a reduced input size of 160x160. NN4 has an input size of only 96x96, thereby drastically reducing the CPU requirements (285M FLOPS vs 1.6B for NN2). In addition to the reduced input size it does not use 5x5 convolutions in the higher layers as the receptive field is already too small by then. Generally we found that the 5x5 convolutions can be removed throughout with only a minor drop in accuracy. Figure 4 compares all our models.我們使用的第二類是基於GoogLeNet風格的Inception模型組[16]。 部分模型使引數減少20倍(約6.6M-7.5M),FLOPS減少5倍(500M-1.6B之間)。 其中一些型號的尺寸(深度和濾波器數量)都大幅減少,因此可以在手機上執行。 一,NNS1,具有26M引數,每個影象僅需要220M FLOPS。 另一個是NNS2,有4.3M引數和20M FLOPS。 表2詳細描述了我們最大的網路NN2。 NN3在架構上是相同的,但輸入尺寸減小了160x160。 NN4的輸入大小僅為96x96,從而大幅降低了CPU要求(NN2為285M FLOPS對1.6B)。 除了減小的輸入尺寸之外,它在較高層中不使用5x5卷積,因為此時感受野已經太小。 一般來說,我們發現5x5卷積可以在整個過程中被移除,只有很小的精度下降。 圖4比較了我們所有的模型。
4. 資料集和評估
We evaluate our method on four datasets and with the exception of Labelled Faces in the Wild and YouTube Faces we evaluate our method on the face verification task. I.e. given a pair of two face images a squared L2 distance threshold D(xi; xj) is used to determine the classification of same and different. All faces pairs (i; j) of the same identity are denoted with Psame, whereas all pairs of different identities are denoted with Pdiff.我們在四個資料集上評估我們的方法,除了Wild和YouTube Faces中的Labeled Faces,我們在面部驗證任務上評估我們的方法。即 給定一對兩個面部影象,使用平方L2距離閾值D(xi; xj)來確定相同和不同的分類。 具有相同身份的所有面部對(i; j)用Psame表示,而所有不同身份對用Pdiff表示。我們定義TA和FA為:
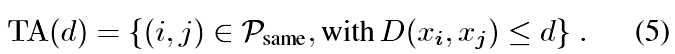
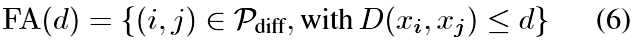
The validation rate VAL(d) and the false accept rate FAR(d) for a given face distance d are then defined as然後將在給定面部距離d下的驗證率VAL(d)和錯誤接受率FAR(d)定義為

4.1. 保持測試集
We keep a hold out set of around one million images, that has the same distribution as our training set, but disjoint identities. For evaluation we split it into five disjoint sets of 200k images each. The FAR and VAL rate are then computed on 100k*100k image pairs. Standard error is reported across the five splits.我們保留了大約一百萬張影象,與我們的訓練集具有相同的分佈,但不相同的身份。 為了評估,我們將它分成五個不相交的資料集,每組200k影象。 然後在100k*100k的影象對上計算FAR和VAL率。 在五個資料集的結果中報告標準錯誤。
4.2. 個人照片
This is a test set with similar distribution to our training set, but has been manually verified to have very clean labels. It consists of three personal photo collections with a total of around 12k images. We compute the FAR and VAL rate across all 12k squared pairs of images.這是一個與我們的訓練集具有類似分佈的測試集,但已經過手動驗證,具有非常乾淨的標籤。 它由三個個人照片集合組成,總共大約12k影象。 我們計算所有12k平方對影象的FAR和VAL率。
4.3. 學術資料集
Labeled Faces in the Wild (LFW) is the de-facto academic test set for face verification [7]. We follow the standard protocol for unrestricted, labeled outside data and report the mean classification accuracy as well as the standard error of the mean.野外標記面(LFW)是面部驗證的事實上的學術測試集[7]。 我們遵循標準協議,對無限制,標記的外部資料進行報告,並報告平均分類準確度以及均值的標準誤差。
Youtube Faces DB [21] is a new dataset that has gained popularity in the face recognition community [17, 15]. The setup is similar to LFW, but instead of verifying pairs of images, pairs of videos are used.Youtube Faces DB [21]是一個新的資料集,在人臉識別領域得到了普及[17,15]。 該設定類似於LFW,但不使用驗證影象對,而是使用視訊對。
5. 實驗
If not mentioned otherwise we use between 100M-200M training face thumbnails consisting of about 8M different identities. A face detector is run on each image and a tight bounding box around each face is generated. These face thumbnails are resized to the input size of the respective network. Input sizes range from 96x96 pixels to 224x224 pixels in our experiments.如果沒有提到,否則我們使用100M-200M訓練面部縮圖,其中包含大約8M個不同的身份。 在每個影象上執行面部檢測器,並且生成圍繞每個面的緊密邊界框。 這些面部縮圖的大小調整為相應網路的輸入大小。 在我們的實驗中,輸入尺寸範圍從96x96畫素到224x224畫素。
5.1. 計算準確性權衡
Before diving into the details of more specific experiments we will discuss the trade-off of accuracy versus number of FLOPS that a particular model requires. Figure 4 shows the FLOPS on the x-axis and the accuracy at 0.001 false accept rate (FAR) on our user labelled test-data set from section 4.2. It is interesting to see the strong correlation between the computation a model requires and the accuracy it achieves. The figure highlights the five models (NN1, NN2, NN3, NNS1, NNS2) that we discuss in more detail in our experiments.在深入瞭解更具體的實驗細節之前,我們將討論精確度與特定模型所需的FLOPS數量之間的權衡。 圖4顯示了x軸上的FLOPS以及4.2節中使用者標記的測試資料集的0.001錯誤接受率(FAR)的準確度。 有趣的是,模型所需的計算與其實現的精度之間存在很強的相關性。 該圖突出顯示了我們在實驗中更詳細討論的五個模型(NN1,NN2,NN3,NNS1,NNS2)。
We also looked into the accuracy trade-off with regards to the number of model parameters. However, the picture is not as clear in that case. For example, the Inception based model NN2 achieves a comparable performance to NN1, but only has a 20th of the parameters. The number of FLOPS is comparable, though. Obviously at some point the performance is expected to decrease, if the number of parameters is reduced further. Other model architectures may allow further reductions without loss of accuracy, just like Inception [16] did in this case.我們還研究了關於模型引數數量的準確性權衡。 但是,在這種情況下,情況並不那麼清楚。 例如,基於Inception的模型NN2實現了與NN1相當的效能,但只有20個引數。 但是,FLOPS的數量是可比的。 顯然,如果引數的數量進一步減少,預計效能會下降。 其他模型架構可以允許進一步減少而不會損失準確性,就像Inception [16]在這種情況下所做的那樣。
5.2. CNN模型的效果
We now discuss the performance of our four selected models in more detail. On the one hand we have our traditional Zeiler&Fergus based architecture with 11 convolutions [22, 9] (see Table 1). On the other hand we have Inception [16] based models that dramatically reduce the model size. Overall, in the final performance the top models of both architectures perform comparably. However, some of our Inception based models, such as NN3, still achieve good performance while significantly reducing both the FLOPS and the model size.我們現在更詳細地討論我們四個選定模型的效能。 一方面,我們採用傳統的基於Zeiler和Fergus的架構,具有1*1卷積[22,9](見表1)。 另一方面,我們有基於Inception [16]的模型,可以大大減少模型的大小。 總的來說,在最終的表現中,兩種架構的頂級模型表現相當。 但是,我們的一些基於Inception的模型(如NN3)仍然可以實現良好的效能,同時顯著降低FLOPS和模型大小。
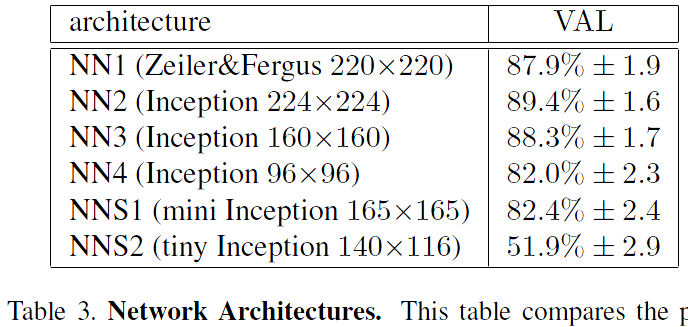
Table 3. Network Architectures. This table compares the performance of our model architectures on the hold out test set (see section 4.1). Reported is the mean validation rate VAL at 10E-3 false accept rate. Also shown is the standard error of the mean across the five test splits.表3.網路體系結構。 該表比較了我們的模型架構在保持測試集上的效能(參見第4.1節)。 報告的是10E-3錯誤接受率下的平均驗證率VAL。 還顯示了五個測試分裂中的平均值的標準誤差。
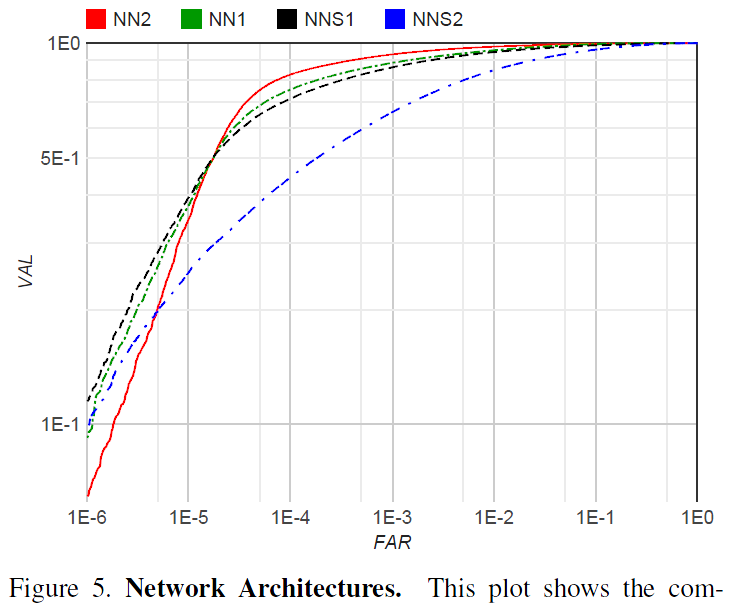
Figure 5. Network Architectures. This plot shows the complete ROC for the four different models on our personal photos test set from section 4.2. The sharp drop at 10E-4 FAR can be explained by noise in the groundtruth labels. The models in order of performance are: NN2: 224224 input Inception based model; NN1: Zeiler&Fergus based network with 11 convolutions; NNS1: small Inception style model with only 220M FLOPS; NNS2: tiny Inception model with only 20M FLOPS.圖5.網路架構 該圖顯示了4.2節中我們個人照片測試集中四種不同模型的完整ROC。 10E-4 FAR的急劇下降可以通過groundtruth標籤中的噪聲來解釋。 效能順序為:NN2:224*224輸入基於初始的模型; NN1:基於Zeiler&Fergus的網路,1*1卷積; NNS1:小型Inception風格型號,僅有220M FLOPS; NNS2:微小的Inception模型,只有20M FLOPS。
The detailed evaluation on our personal photos test set is shown in Figure 5. While the largest model achieves a dramatic improvement in accuracy compared to the tiny NNS2, the latter can be run 30ms / image on a mobile phone and is still accurate enough to be used in face clustering. The sharp drop in the ROC for FAR < 10e-4 indicates noisy labels in the test data groundtruth. At extremely low false accept rates a single mislabeled image can have a significant impact on the curve.我們的個人照片測試裝置的詳細評估如圖5所示。雖然最小的型號與小型NNS2相比可以顯著提高精度,後者可以在手機上執行30ms /影象,並且仍然足夠準確 用於面部聚類。 FAR \<10e-4的ROC急劇下降表明測試資料中的標籤噪聲很大。 在極低的錯誤接受率下,單個錯誤標記的影象會對曲線產生顯著影響。
5.3. 對圖片質量的敏感度
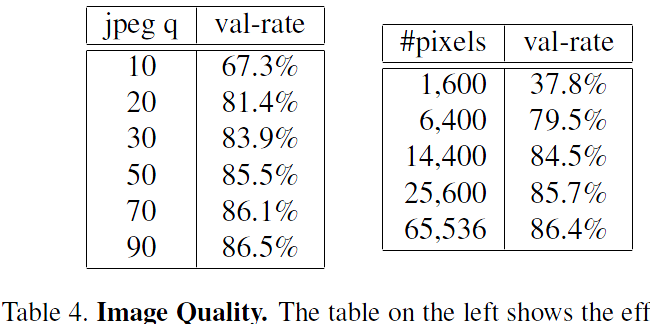
Table 4. Image Quality. The table on the left shows the effect on the validation rate at 10E-3 precision with varying JPEG quality. The one on the right shows how the image size in pixels effects the validation rate at 10E-3 precision. This experiment was done with NN1 on the first split of our test hold-out dataset.表4.影象質量。 左側的表格顯示了不同JPEG質量對10E-3精度的驗證率的影響。 右邊的那個顯示影象大小(以畫素為單位)如何影響10E-3精度的驗證率。 在我們的測試保持資料集的第一次拆分中,使用NN1完成了該實驗。
Table 4 shows the robustness of our model across a wide range of image sizes. The network is surprisingly robust with respect to JPEG compression and performs very well down to a JPEG quality of 20. The performance drop is very small for face thumbnails down to a size of 120x120 pixels and even at 80x80 pixels it shows acceptable performance. This is notable, because the network was trained on 220x220 input images. Training with lower resolution faces could improve this range further.表4顯示了我們的模型在各種影象尺寸上的穩健性。 該網路在JPEG壓縮方面非常強大,並且在JPEG質量為20時表現非常好。對於尺寸為120x120畫素的面部縮圖,效能下降非常小,即使在80x80畫素下也表現出可接受的效能。 這是值得注意的,因為網路是在220x220輸入影象上訓練的。 低解析度面部訓練可以進一步改善這個範圍。
5.4. 嵌入維度
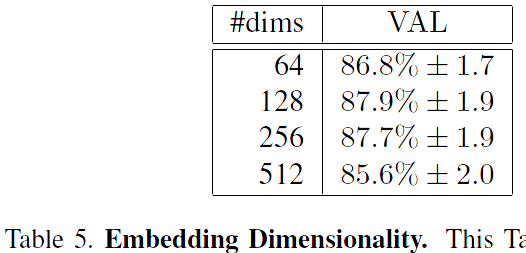
Table 5. Embedding Dimensionality. This Table compares the effect of the embedding dimensionality of our model NN1 on our hold-out set from section 4.1. In addition to the VAL at 10E-3 we also show the standard error of the mean computed across five splits.表5.嵌入維度。 該表比較了我們的模型NN1的嵌入維數對4.1節中的保持集的影響。 除了在10E-3處的VAL之外,我們還顯示了在五個子資料集中計算的平均值的標準誤差。
We explored various embedding dimensionalities and selected 128 for all experiments other than the comparison reported in Table 5. One would expect the larger embeddings to perform at least as good as the smaller ones, however, it is possible that they require more training to achieve the same accuracy. That said, the differences in the performance reported in Table 5 are statistically insignificant.我們探索了各種嵌入維度,並且除了表5中報告的比較之外,所有實驗都選擇了128個。可以預期較大的嵌入至少與較小的嵌入一樣好,但是,它們可能需要更多的訓練來實現 同樣準確。 也就是說,表5中報告的效能差異在統計上是不顯著的。
It should be noted, that during training a 128 dimensional float vector is used, but it can be quantized to 128-bytes without loss of accuracy. Thus each face is compactly represented by a 128 dimensional byte vector, which is ideal for large scale clustering and recognition. Smaller embeddings are possible at a minor loss of accuracy and could be employed on mobile devices.應該注意,在訓練期間使用128維浮點向量,但是它可以被量化為128位元組而不會損失精度。 因此,每個面由128維位元組向量緊湊地表示,這對於大規模聚類和識別是理想的。 較小的嵌入可能會在很小的精度下丟失,並且可以在移動裝置上使用。
5.5. 訓練資料的大小
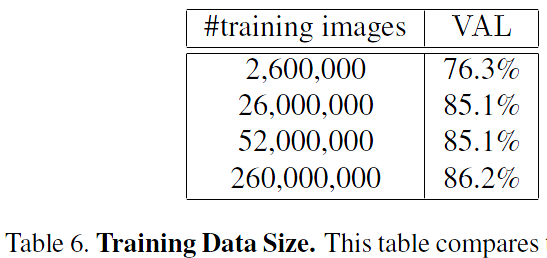
Table 6. Training Data Size. This table compares the performance after 700h of training for a smaller model with 96x96 pixel inputs. The model architecture is similar to NN2, but without the 5x5 convolutions in the Inception modules.表6.培訓資料大小。 該表比較了較小型號與96x96畫素輸入的700h訓練後的效能。 模型體系結構類似於NN2,但在Inception模組中沒有5x5卷積。
Table 6 shows the impact of large amounts of training data. Due to time constraints this evaluation was run on a smaller model; the effect may be even larger on larger models. It is clear that using tens of millions of exemplars results in a clear boost of accuracy on our personal photo test set from section 4.2. Compared to only millions of images the relative reduction in error is 60%. Using another order of magnitude more images (hundreds of millions) still gives a small boost, but the improvement tapers off.表6顯示了大量訓練資料的影響。 由於時間限制,此評估是在較小的模型上執行的; 在較大型號上效果可能更大。 很明顯,使用數千萬個樣本可以明顯提高4.2節中我們個人照片測試集的準確性。 與僅數百萬的影象相比,誤差的相對減少為60%。 使用另一個數量級的更多影象(數億)仍然可以提供小幅提升,但改進逐漸減少。
5.6. 在LFW資料集上的表現
We evaluate our model on LFW using the standard protocol for unrestricted, labeled outside data. Nine training splits are used to select the L2-distance threshold. Classification (same or different) is then performed on the tenth test split. The selected optimal threshold is 1.242 for all test splits except split eighth (1.256).我們使用標準協議評估LFW上的模型,用於不受限制的標記外部資料。 九個訓練分裂用於選擇L2距離閾值。 然後在第十個測試分割上執行分類(相同或不同)。 對於除分裂八分之一(1.256)之外的所有測試分裂,所選擇的最佳閾值是1.242。
Our model is evaluated in two modes:我們的模型有兩種評估模式:
- Fixed center crop of the LFW provided thumbnail.固定的LFW中心裁剪提供了縮圖。
- A proprietary face detector (similar to Picasa [3]) is run on the provided LFW thumbnails. If it fails to align the face (this happens for two images), the LFW alignment is used.專有的人臉檢測器(類似於Picasa [3])在提供的LFW縮圖上執行。 如果它無法對齊面部(兩個影象會發生這種情況),則使用LFW對齊。


Figure 6. LFW errors. This shows all pairs of images that were incorrectly classified on LFW. Only eight of the 13 false rejects shown here are actual errors the other five are mislabeled in LFW.圖6. LFW錯誤。 這顯示了在LFW上錯誤分類的所有影象對。 這裡顯示的13個拒絕錯誤中只有8個是實際錯誤,其他5個是LFW中的錯誤標記。
Figure 6 gives an overview of all failure cases. It shows false accepts on the top as well as false rejects at the bottom. We achieve a classification accuracy of 98.87%0:15 when using the fixed center crop described in (1) and the record breaking 99.63%0.09 standard error of the mean when using the extra face alignment (2). This reduces the error reported for DeepFace in [17] by more than a factor of 7 and the previous state-of-the-art reported for DeepId2+ in [15] by 30%. This is the performance of model NN1, but even the much smaller NN3 achieves performance that is not statistically significantly different.圖6概述了所有故障情況。 它顯示頂部的錯誤接受以及底部的錯誤拒絕。 當使用(1)中描述的固定中心作物時,我們實現了98.87%≤0.15的分類精度,並且當使用額外面部對齊時(2),平均值達到99.63%?0.09標準誤差。 這將[17]中針對DeepFace報告的錯誤減少了7倍以上,並且[15]中針對DeepId2 +報告的先前最新技術水平降低了30%。 這是NN1型號的效能,但即使是更小的NN3也能實現統計上沒有顯著差異的效能。
5.7. 在YouTube Faces DB資料集上的表現
We use the average similarity of all pairs of the first one hundred frames that our face detector detects in each video. This gives us a classification accuracy of 95.12%0:39. Using the first one thousand frames results in 95.18%. Compared to [17] 91.4% who also evaluate one hundred frames per video we reduce the error rate by almost half. DeepId2+ [15] achieved 93.2% and our method reduces this error by 30%, comparable to our improvement on LFW.我們使用人臉檢測器在每個視訊中檢測到的前100幀的所有對的平均相似度。 這使我們的分類準確度為95.12%?0.39。 使用前一千幀導致95.18%。 與[17] 91.4%同時評估每個視訊100幀的人相比,我們將錯誤率降低了近一半。 DeepId2 + [15]達到93.2%,我們的方法將此誤差減少了30%,與我們對LFW的改進相當。
5.8. 人臉聚類


Figure 7. Face Clustering. Shown is an exemplar cluster for one user. All these images in the users personal photo collection were clustered together.圖7.面部聚類。 顯示的是一個使用者的示例群集。 使用者個人照片集中的所有這些影象都聚集在一起。
Our compact embedding lends itself to be used in order to cluster a users personal photos into groups of people with the same identity. The constraints in assignment imposed by clustering faces, compared to the pure verification task,lead to truly amazing results. Figure 7 shows one cluster in a users personal photo collection, generated using agglomerative clustering. It is a clear showcase of the incredible invariance to occlusion, lighting, pose and even age.我們的緊湊嵌入適合用於將使用者個人照片聚集到具有相同身份的人群中。 與純驗證任務相比,聚類面臨的約束導致真正驚人的結果。 圖7顯示了使用凝聚聚類生成的使用者個人照片集中的一個聚類。 它清晰地展示了遮擋,光線,姿勢甚至年齡的驚人不變性。
6. 總結
We provide a method to directly learn an embedding into an Euclidean space for face verification. This sets it apart from other methods [15, 17] who use the CNN bottleneck layer, or require additional post-processing such as concatenation of multiple models and PCA, as well as SVM classification. Our end-to-end training both simplifies the setup and shows that directly optimizing a loss relevant to the task at hand improves performance.我們提供了一種直接學習嵌入歐幾里德空間進行面部驗證的方法。 這使得它與使用CNN瓶頸層的其他方法[15,17]不同,或者需要額外的後處理,例如多個模型和PCA的串聯,以及SVM分類。 我們的端到端培訓既簡化了設定,又表明直接優化與手頭任務相關的損失可以提高效能。
Another strength of our model is that it only requires minimal alignment (tight crop around the face area). [17], for example, performs a complex 3D alignment. We also experimented with a similarity transform alignment and notice that this can actually improve performance slightly. It is not clear if it is worth the extra complexity.我們模型的另一個優勢是它只需要最小的對齊(面部周圍緊密的裁剪)。 [17],例如,執行復雜的3D對齊。 我們還嘗試了相似性變換對齊,並注意到這實際上可以略微提高效能。 目前尚不清楚是否值得額外的複雜性。
Future work will focus on better understanding of the error cases, further improving the model, and also reducing model size and reducing CPU requirements. We will also look into ways of improving the currently extremely long training times, e.g. variations of our curriculum learning with smaller batch sizes and offline as well as online positive and negative mining.未來的工作將側重於更好地理解錯誤情況,進一步改進模型,並減少模型大小和降低CPU要求。 我們還將探討如何改善目前極長的訓練時間,例如: 我們的課程學習的變化與較小的批量和離線以及線上積極和消極的挖掘。
7. 附錄:諧波嵌入
In this section we introduce the concept of harmonic embeddings. By this we denote a set of embeddings that are generated by different models v1 and v2 but are compatible in the sense that they can be compared to each other.在本節中,我們將介紹諧波嵌入的概念。 通過這個,我們表示由不同模型v1和v2生成的一組嵌入,但是在它們可以彼此比較的意義上是相容的。
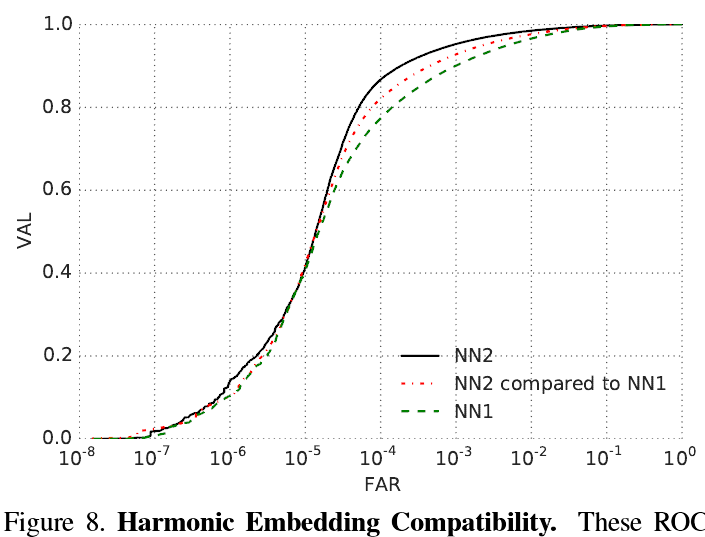
Figure 8. Harmonic Embedding Compatibility. These ROCs show the compatibility of the harmonic embeddings of NN2 to the embeddings of NN1. NN2 is an improved model that performs much better than NN1. When comparing embeddings generated by NN1 to the harmonic ones generated by NN2 we can see the compatibility between the two. In fact, the mixed mode performance is still better than NN1 by itself.圖8.諧波嵌入相容性。 這些ROC顯示了NN2的諧波嵌入與NN1嵌入的相容性。 NN2是一種改進的模型,其效能遠優於NN1。 當比較NN1生成的嵌入與NN2生成的諧波嵌入時,我們可以看到兩者之間的相容性。 實際上,混合模式效能本身仍然優於NN1。
This compatibility greatly simplifies upgrade paths. E.g. in an scenario where embedding v1 was computed across a large set of images and a new embedding model v2 is being rolled out, this compatibility ensures a smooth transition without the need to worry about version incompatibilities. Figure 8 shows results on our 3G dataset. It can be seen that the improved model NN2 significantly outperforms NN1, while the comparison of NN2 embeddings to NN1 embeddings performs at an intermediate level.這種相容性極大地簡化了升級路徑。 例如。 在一個大型影象集中計算嵌入v1並且正在推出新的嵌入模型v2的情況下,這種相容性可確保平滑過渡,而無需擔心版本不相容。 圖8顯示了我們的3G資料集的結果。 可以看出,改進的模型NN2明顯優於NN1,而NN2嵌入與NN1嵌入的比較在中間水平上執行。
7.1. 諧波三元組損失
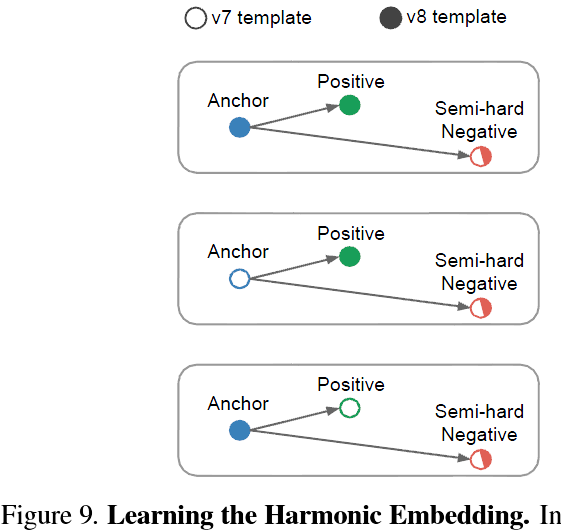
Figure 9. Learning the Harmonic Embedding. In order to learn a harmonic embedding, we generate triplets that mix the v1 embeddings with the v2 embeddings that are being trained. The semihard negatives are selected from the whole set of both v1 and v2 embeddings.圖9.學習諧波嵌入。 為了學習諧波嵌入,我們生成三元組,將v1嵌入與正在訓練的v2嵌入混合。 從整個v1和v2嵌入集合中選擇半硬性負樣本。
In order to learn the harmonic embedding we mix embeddings of v1 together with the embeddings v2, that are being learned. This is done inside the triplet loss and results in additionally generated triplets that encourage the compatibility between the different embedding versions. Figure 9 visualizes the different combinations of triplets that contribute to the triplet loss.為了學習諧波嵌入,我們將v1的嵌入與v2的嵌入混合,這是正在學習的。 這是在元組損失內部完成的,並導致額外生成的三元組,這些三元組促進了不同嵌入版本之間的相容性。 圖9顯示了導致三重態損失的三重態的不同組合。
We initialized the v2 embedding from an independently trained NN2 and retrained the last layer (embedding layer) from random initialization with the compatibility encouraging triplet loss. First only the last layer is retrained, then we continue training the whole v2 network with the harmonic loss.我們從獨立訓練的NN2初始化v2嵌入,並從隨機初始化中重新訓練最後一層(嵌入層),相容性鼓勵三重態丟失。 首先只重新訓練最後一層,然後我們繼續訓練整個v2網路的諧波損失。
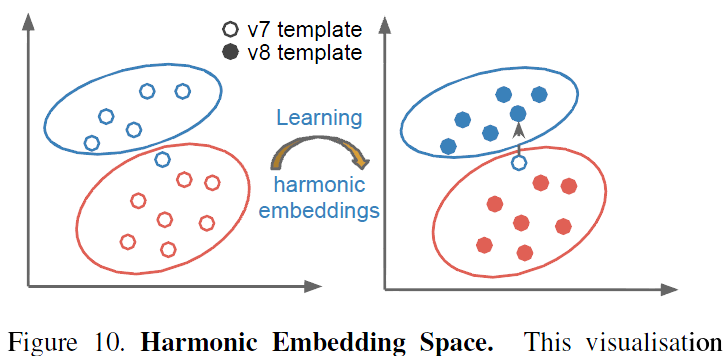
Figure 10. Harmonic Embedding Space. This visualisation sketches a possible interpretation of how harmonic embeddings are able to improve verification accuracy while maintaining compatibility to less accurate embeddings. In this scenario there is one misclassified face, whose embedding is perturbed to the “correct” location in v2.圖10.諧波嵌入空間。 該視覺化概述了諧波嵌入如何在提高驗證準確性的同時保持與不太精確的嵌入的相容性的可能解釋。 在這種情況下,有一個錯誤分類的面,其嵌入被擾亂到v2中的“正確”位置。
Figure 10 shows a possible interpretation of how this compatibility may work in practice. The vast majority of v2 embeddings may be embedded near the corresponding v1 embedding, however, incorrectly placed v1 embeddings can be perturbed slightly such that their new location in embedding space improves verification accuracy.圖10顯示了這種相容性在實踐中如何起作用的可能解釋。 絕大多數v2嵌入可以嵌入在相應的v1嵌入附近,然而,錯誤放置的v1嵌入可以稍微擾動,使得它們在嵌入空間中的新位置提高了驗證準確性。
7.2. 總結
These are very interesting findings and it is somewhat surprising that it works so well. Future work can explore how far this idea can be extended. Presumably there is a limit as to how much the v2 embedding can improve over v1, while still being compatible. Additionally it would be interesting to train small networks that can run on a mobile phone and are compatible to a larger server side model.這些都是非常有趣的發現,它有點令人驚訝,它運作良好。 未來的工作可以探索這個想法可以擴充套件到多遠。 據推測,v2嵌入可以比v1提高多少,但仍然相容。 另外,培訓可以在行動電話上執行並且與更大的伺服器端模型相容的小型網路將是有趣的。
致謝
We would li