High-Fidelity Pose and Expression Normalization for Face Recognition in the Wild
阿新 • • 發佈:2019-01-22
中科院關於 人臉影象預處理:姿態和表情的歸一化
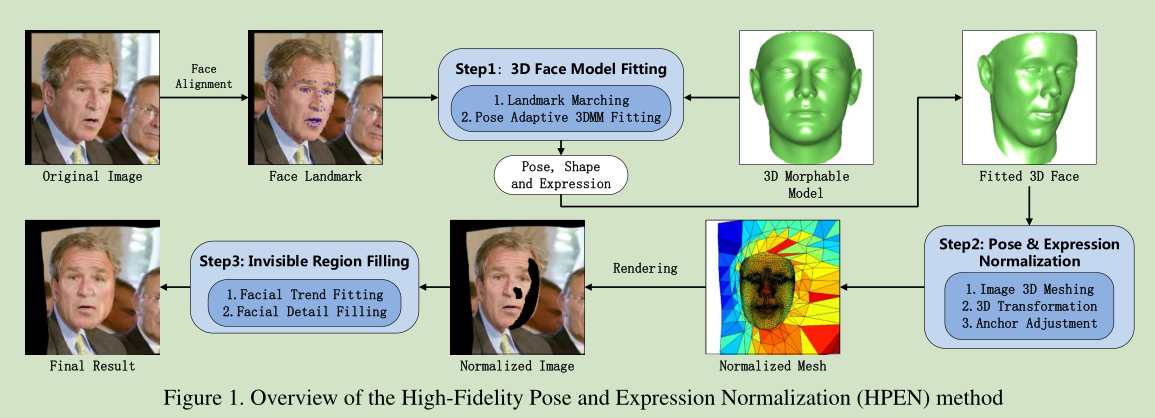
演算法的整體流程圖如下所示:
2 Pose Adaptive 3DMM Fitting
2.1. 3D Morphable Model
本文采用3D模型,我們將 Basel Face Model (BFM) [36] 和 表示表情的Face Warehouse [14]結合起來,得到我們自己的 3DMM(3DMorphableModel)。
我們通過一個 Weak Perspective Projection 將3D模型投影到 影象平面,通過優化下面的公式:
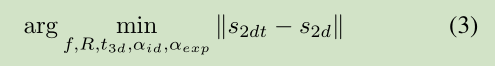
2.2. Landmark Marching
一般來說首先是進行人臉的特徵點檢測,然後將這些特徵點與對應的3D模型建立對映關係。但是有一個問題,就是有一部分特徵點被遮擋了,導致不能準確的建立對映關係。如下圖所示:

本文提出了一個解決方法:landmark marching。
When pose changes, if a contour landmark is visible, it will not move; or it will move along the parallel to the visibility boundary

3 Identity Preserving Normalization
擴充套件到人臉周邊區域,得到更完整的資訊

錨點微調

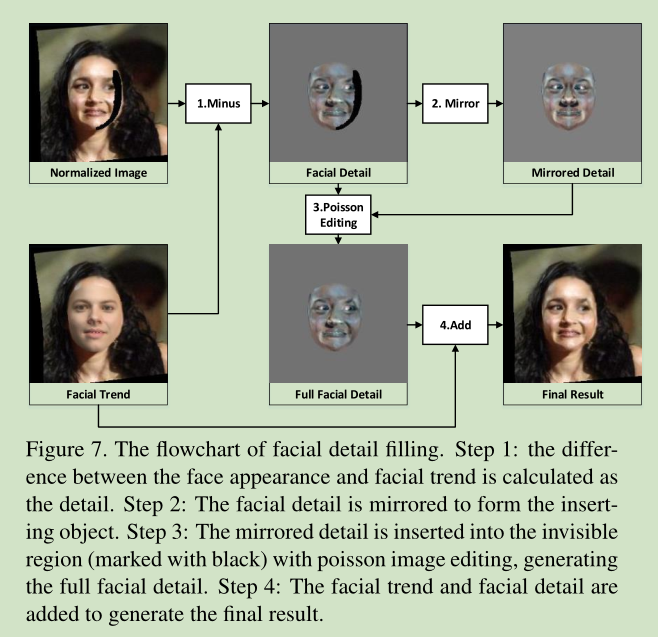
看不見的區域填充
還原背景

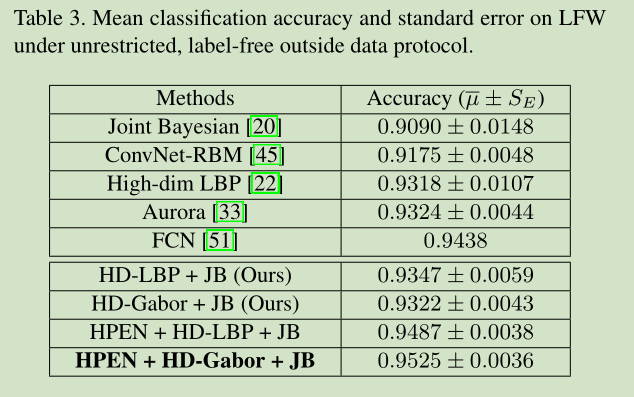
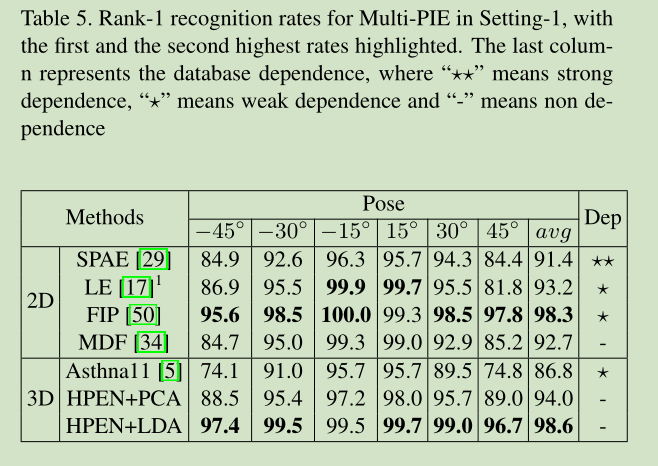
結果