
Google MapReduce 的讀後感
-----
簡單介紹
本人雖然不是計算機專業的學生,但是有一點程式設計基礎,目前正在學習計算機知識,對大資料和人工智慧還是比較感興趣。
馬雲在卸任時講到:“很多人還沒搞清楚什麼是PC網際網路,移動網際網路來了,我們還沒搞清楚移動互聯的時候,大資料時代又來了。”可見,正處於大資料時代的我們很有必要了解一下大資料方面的知識。
大資料(Big Data)是指“無法用現有的軟體提取、儲存、搜尋、共享、分析和處理海量的、複雜的資料集合。”
隨著計算機的處理能力不斷加強,資料越多,價值也會很大。傳統行業的資料,收集和分析很慢,網際網路時代,資料收集和分析都變得更快。
在計算機中,資料被儲存在記憶體當中,電腦上的軟體都可以看作資料,其實這些資料由0 1 0 1的位(又稱為位元)序列組成,8個位被組織成一組,稱為位元組,位元組向上分別為KB、MB、GB、TB,每一級為前一級的1024倍。
通常來說,我們所用的電腦可以處理很多資料,但是對於海量的大資料來說,卻不能相提並論,這時候一臺電腦解決不了,就可以再多一臺電腦處理,以此類推,資料越大,可以藉助於很多電腦來進行處理,多臺電腦也就意味著分散式計算。許多臺電腦處理資料的機制,這正是我這篇所要講的主要內容,即讀了 Google的其中一篇論文MapReduce之後產生了一些感想,下面我將從論文的各個方面說明:
(1)介紹
(2)程式設計模型
(3)實現
(4)技巧
(5)效能
(6)經驗
(7)相關工作
(8)我的感悟
介紹
介紹裡面對於 MaReduce 說的很清楚
以下來自譯者:Alex 原文地址:http://blademaster.ixiezi.com/


也就是說 MapReduce 是一個模型,是一個簡單到我們只需要我們想要執行的運算即可,而那些平行計算、容錯、資料分佈、負載均衡等複雜的細節,這些問題都被封裝在一個庫中,我們能直接呼叫。
程式設計模型
MapReduce 庫的使用者用兩個函式 :Map 和 Reduce.
MapReduce 程式設計模型的原理是:利用一個輸 入key/value pair集合來產生一個輸 出的key/value pair集合. 文章中舉了一個例子:就是在一個大的文件中計算每個單詞出現的的次數,它首先用Map函式輸出文件中的每個詞、以及這個詞的出現次數,Reduce函式把Map函式產生的每一個特定的詞的計數累加起來。然後再使用者的程式碼中使用一個可選的調節引數來完成一個符合MapReduce模型規範的物件,在使用中,直接呼叫MapReduce庫,連結在一起,便可實現。2. 普通的網路硬體裝置,每個機器的帶宛為百兆或者千兆,但是遠小於網路的平均頻寬的一半。 3. 叢集中包含成百 上千的機器,因此,機器故障是常態。
4. 儲存為廉價的內建 IDE硬碟。 5.使用者提交工作(job)給排程系統。 原文中作者有一個很清晰的圖來說明各個排程之間的關係:
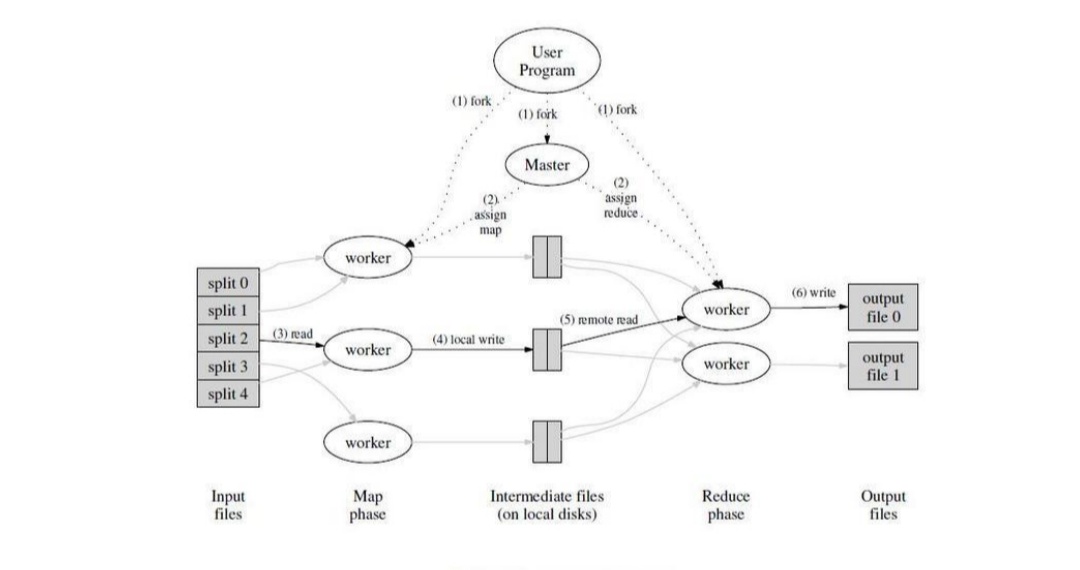 Master持有一些資料結構,它儲存每一個Map和Reduce任務的狀態,以及Worker機器的標識。
Maser就像一個數據管道,中向檔案儲存區域的位畳資訊通過這個管道從Map傳遞到Reduce.因此,對於每個已完成的Map任務, master儲存了Map任務產生的檔案儲存區域的大小和位置。當Map任務完成時,Maser 接收到位置和大小的更新資訊,這些資訊被逐步遞增的推送給那些正在工作的Reduce任務。
MapReduce中還有著良好的容錯機制。因為MapReduce庫的設計初衷是使用由成百上千的機器組成的叢集來處理超大規模的資料,所以,這個庫必須要很好的能夠處理機器故障。
技巧
Master持有一些資料結構,它儲存每一個Map和Reduce任務的狀態,以及Worker機器的標識。
Maser就像一個數據管道,中向檔案儲存區域的位畳資訊通過這個管道從Map傳遞到Reduce.因此,對於每個已完成的Map任務, master儲存了Map任務產生的檔案儲存區域的大小和位置。當Map任務完成時,Maser 接收到位置和大小的更新資訊,這些資訊被逐步遞增的推送給那些正在工作的Reduce任務。
MapReduce中還有著良好的容錯機制。因為MapReduce庫的設計初衷是使用由成百上千的機器組成的叢集來處理超大規模的資料,所以,這個庫必須要很好的能夠處理機器故障。
技巧
雖然簡單的Map和Reduce函式提供的基本功能已經能夠滿足大部分的計算需要,但是還是發掘出了一些有價值的擴充套件功能。
文中有以下幾個方面 分割槽函式、順序保證、Combiner函式、輸入和輸出型別、副作用、跳過損壞的記錄、本地執行、狀態資訊、計數器方面進行了說明。
效能
這一節則是一個大型叢集上執行的兩個計算來衡量MapReduce的效能。一個計算在大約1TB的資料中進行特定的模式匹配,另一個計算對大約1TB的資料進行排序。
這兩個程式在大量的使用MapReduce的實際應用中是非常典型的一一類是對資料格式進行轉換,從一種表現形式轉換為另外一種表現形式:另一類是從海量資料中抽取少部分的使用者感興趣的資料。
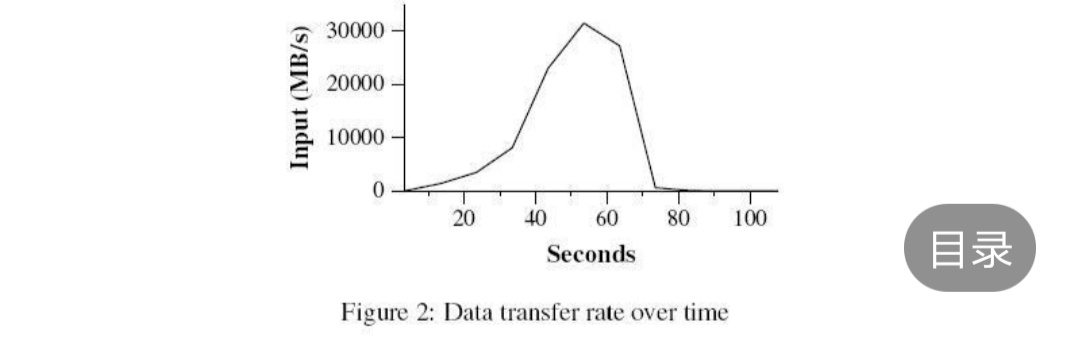
這個圖則是
其中Y軸表示輸入資料的處理速度。處理速度隨著參與 MapReduce計算的機器數量的增加而增加,當1764 臺worker 參與計算的時,處理速度達到了30GB/s。 當Map任務結束的時候,即在計算開始後80秒,輸入的處理速度降到0。整個計算過程從開始到結束一共花了大概150秒。這包括了大約一分鐘的初始啟動階段。初始啟動階段消耗的時間包括了是把這個程式傳送到各個worker機器上的時間、等待GFS檔案系統開啟1000個輸入檔案集合的時間、獲取相關的檔案本地位置優 化資訊的時間。 以下則是排序過程: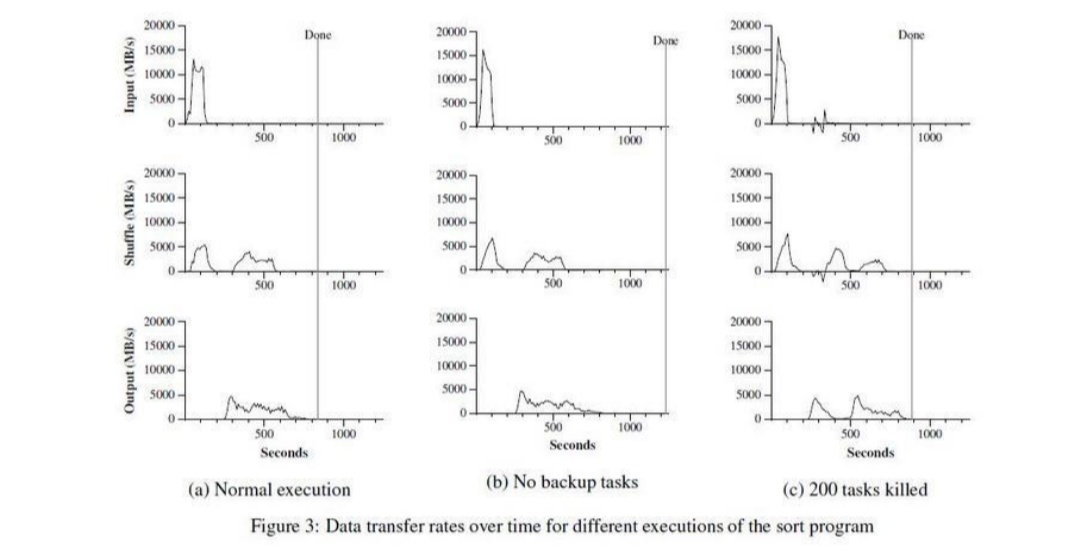
顯示了這個排序程式的正常執行過程。左上的圖顯示了輸入資料讀取的速度。資料讀取速度峰值會達到13GB/s,並且所有Map任務完成之後,即大約200秒之後迅速滑落到0。值得注意的是,排序程式輸入資料讀取速度小於分散式grep程式。這是因為排序程式的Map任務花了大約一半的處理時間和I/O頻寬把中間輸出結果寫到本地硬碟。相應的分散式grep程式的中間結果輸出幾乎可以忽略不計。 左邊中間的圖顯示了中間資料從Map任務傳送到Reduce任務的網路速度。這個過程從第一一個Map任務完成之後就開始緩慢啟動了。圖示的第-一個高峰是啟動了第一批大概1700個Reduce任務,整個MapReduce分佈到大概1700臺機器上,每臺機器1次最多執行1個Reduce任務。排序程式執行大約300秒後,第一-批啟動的Reduce任務有些完成了,我們開始執行剩下的Reduce任務。所有的處理在大約600秒後結束。 經驗 經驗如下: 1. 大規模機器學習問題。 2. Google News和Froogle產品的叢集問題。 3.從公眾查詢產品 (比如Google的Zeigeist)的報告中抽取資料。 4.從大量的新應用 和新產品的網頁中提取有用資訊( 比如,從大量的位置搜尋網頁中抽取地理位置資訊)。 5.大規模的圖形計算。 相關 MapReduce程式設計模型在Google內部成功應用於多個領域。原因有這幾個方面:首先,由於MapReduce封裝了並行處理、容錯處理、資料本地化優化、負載均衡等等技術難點的細節,這使得MapReduce庫易於使用。即便對於完全沒有並行或者分散式系統開發經驗的程式設計師而言,其次,大量不同型別的問題都可以通過MapReduce簡單的解決。比如,MapReduce用於生成Google的網路搜尋服務所需要的資料、用來排序、用來資料探勘、用於機器學習,以及很多其它的系統;第三,我們實現了一個在數千臺計算機組成的大型叢集,上靈活部署執行的MapReduce。這個實現使得有效利用這些豐富的計算資源變得非常簡單,因此也適合用來解決Google遇到的其他很多需要大量計算的問題。 想法 簡單來說,MapReduce能將海量的資料濃縮成人們想要的資料。Hadoop的兩大核心是HDFS和MapReduce,Hadoop的體系結構主要通過HDFS的分散式儲存作為底層資料支援的。並且通過MapReduce來進行計算。 參考資料 Google MapReduce 中文版
------