
FastDFS(分散式檔案系統)
什麼是FastDFS?
FastDFS是用c語言編寫的一款開源的輕量級分散式檔案系統。
個人的理解)hadoop也是一個分散式檔案系統,hadoop是處理大資料的,什麼是大資料呢?就是海量資料。海量資料你一塊磁碟估計存不下,那麼就需要把資料存到多個磁碟上,還得統一管理,這時就需要一個分散式檔案系統來管理。FastDFS同樣也是這麼一個意思,圖片我們有很多,但容量有上限,所以我們要把這些所有的圖片儲存到多臺伺服器上,還要進行統一管理,那麼就需要一個分散式檔案系統,很顯然那就是FastDFS了,FastDFS適合於存取圖片。
它對檔案進行管理,功能包括:檔案儲存、檔案同步、檔案訪問等,充分考慮了冗餘備份、負載均衡、線性擴容等機制,並注重高可用、高效能等指標,解決了大容量儲存和負載均衡的問題。特別適合以檔案為載體的線上服務,如相簿網站、視訊網站等等。
對於專案中圖片上傳這個功能,可以搭建一個圖片伺服器專門儲存圖片。
FastDFS架構
FastDFS架構包括 Tracker server和Storage server。客戶端請求Tracker server進行檔案上傳、下載,通過Tracker server排程最終由Storage server完成檔案上傳和下載。
Trackerserver作用是負載均衡和排程,通過Trackerserver在檔案上傳時可以根據一些策略找到Storage server提供檔案上傳服務。可以將tracker稱為追蹤伺服器或排程伺服器。
Storageserver作用是檔案儲存,客戶端上傳的檔案最終儲存在Storage伺服器上,Storage server沒有實現自己的檔案系統而是利用作業系統的檔案系統來管理檔案。可以將storage稱為儲存伺服器。
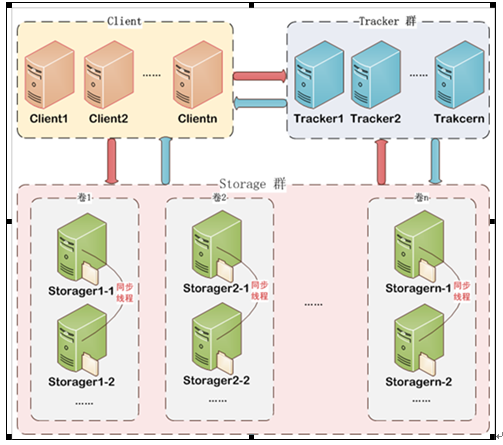
我們從上圖還能看到,Client端可以有多個,也就是同時支援多個客戶端對FastDFS叢集服務進行訪問,Tracker是跟蹤器,負責協調Client與Storage之間的互動,為了實現高可用性,需要用多個Tracker來作為跟蹤器。Storage是專門用來儲存東西的,而且是分組進行儲存的,每一組可以有多臺裝置,這幾臺裝置儲存的內容完全一致,這樣做也是為了高可用性,當現有分組容量不夠時,我們可以水平擴容,即增加分組來達到擴容的目的。另外需要注意的一點是,如果一組中的裝置容量大小不一致,比如裝置A容量是80G,裝置B的容量是100G,那麼這兩臺裝置所在的組的容量會以小的容量為準,也就是說,當儲存的東西大小超過80G時,我們將無法儲存到該組中了。Client端在與Storage進行互動的時候也與Tracker cluster進行互動,說的通俗點就是Storage向Tracker cluster進行彙報登記,告訴Tracker現在自己哪些位置還空閒,剩餘空間是多大。
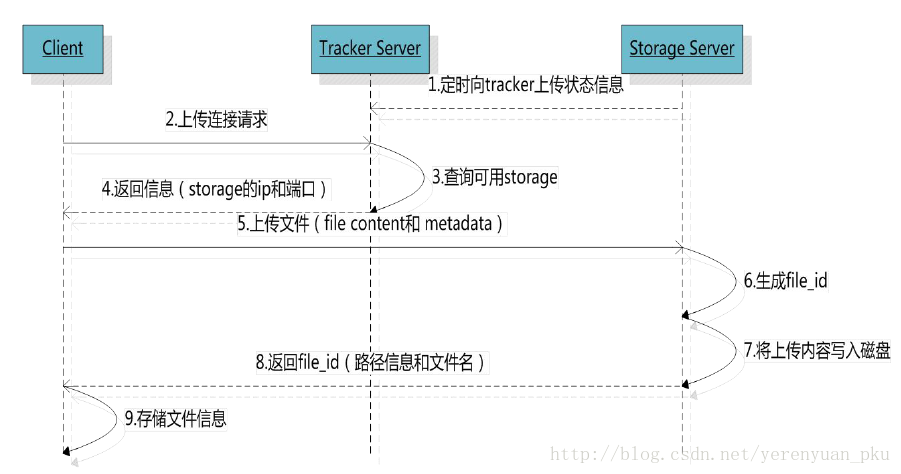
檔案上傳的流程
從中可以看到,Client想上傳圖片,它先向Tracker進行詢問,Tracker檢視一下登記資訊之後,告訴Client哪個storage當前空閒,Tracker會把IP和埠號都返回給Client,Client在拿到IP和埠號之後,便不再需要通過Tracker,直接便向Storage進行上傳圖片,Storage在儲存圖片的同時,會向Tracker進行彙報,告訴Tracker它當前是否還留有剩餘空間,以及剩餘空間大小。彙報完之後,Storage將伺服器上儲存圖片的地址返回給Client,Client可以拿著這個地址進行訪問圖片。說得更加細緻一點,客戶端上傳檔案後儲存伺服器將檔案ID返回給客戶端,此檔案ID用於以後訪問該檔案的索引資訊。檔案索引資訊包括:組名,虛擬磁碟路徑,資料兩級目錄,檔名,如下所示:

- 組名:檔案上傳後所在的storage組名稱,在檔案上傳成功後由storage伺服器返回,需要客戶端自行儲存。
- 虛擬磁碟路徑:storage配置的虛擬路徑,與磁碟選項
store_path*對應。如果配置了store_path0則是M00,如果配置了store_path1則是M01,以此類推。 - 資料兩級目錄:storage伺服器在每個虛擬磁碟路徑下建立的兩級目錄,用於儲存資料檔案。
- 檔名:與檔案上傳時不同。是由儲存伺服器根據特定資訊生成,檔名包含:源儲存伺服器IP地址、檔案建立時間戳、檔案大小、隨機數和檔案拓展名等資訊。
檔案下載的流程
檔案下載的步驟可以是:
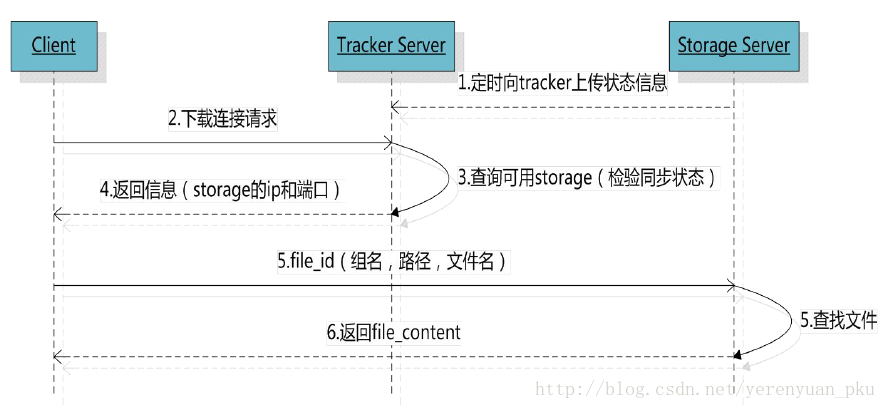
- client詢問tracker下載檔案的storage,引數為檔案標識(組名和檔名)。
- tracker返回一臺可用的storage。
- client直接和storage通訊完成檔案下載。