
組合語言初步瞭解-----轉自阮一峰的組合語言網路日誌
轉自http://www.ruanyifeng.com/blog/2018/01/assembly-language-primer.html
作者:阮一峰
學習程式設計其實就是學高階語言,即那些為人類設計的計算機語言。
但是,計算機不理解高階語言,必須通過編譯器轉成二進位制程式碼,才能執行。學會高階語言,並不等於理解計算機實際的執行步驟。
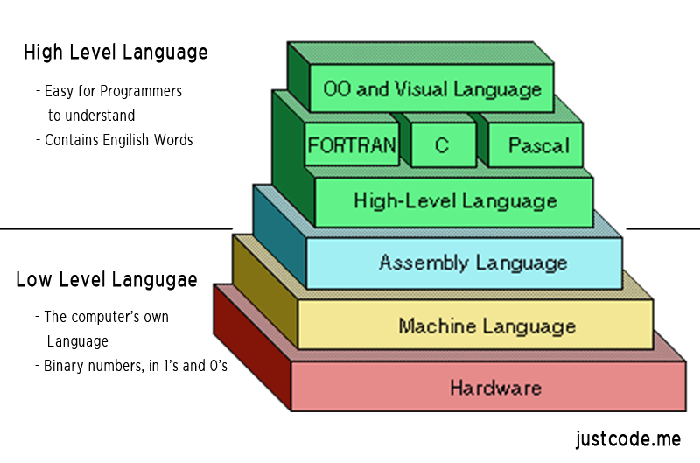
計算機真正能夠理解的是低階語言,它專門用來控制硬體。組合語言就是低階語言,直接描述/控制 CPU 的執行。如果你想了解 CPU 到底幹了些什麼,以及程式碼的執行步驟,就一定要學習組合語言。
組合語言不容易學習,就連簡明扼要的介紹都很難找到。下面我嘗試寫一篇最好懂的組合語言教程,解釋 CPU 如何執行程式碼。

一、組合語言是什麼?
我們知道,CPU 只負責計算,本身不具備智慧。你輸入一條指令(instruction),它就執行一次,然後停下來,等待下一條指令。
這些指令都是二進位制的,稱為操作碼(opcode),比如加法指令就是00000011。編譯器的作用,就是將高階語言寫好的程式,翻譯成一條條操作碼。
對於人類來說,二進位制程式是不可讀的,根本看不出來機器幹了什麼。為了解決可讀性的問題,以及偶爾的編輯需求,就誕生了組合語言。
組合語言是二進位制指令的文字形式,與指令是一一對應的關係。比如,加法指令00000011寫成組合語言就是 ADD。只要還原成二進位制,組合語言就可以被 CPU 直接執行,所以它是最底層的低階語言。
二、來歷
最早的時候,編寫程式就是手寫二進位制指令,然後通過各種開關輸入計算機,比如要做加法了,就按一下加法開關。後來,發明了紙帶打孔機,通過在紙帶上打孔,將二進位制指令自動輸入計算機。
為了解決二進位制指令的可讀性問題,工程師將那些指令寫成了八進位制。二進位制轉八進位制是輕而易舉的,但是八進位制的可讀性也不行。很自然地,最後還是用文字表達,加法指令寫成 ADD。記憶體地址也不再直接引用,而是用標籤表示。
這樣的話,就多出一個步驟,要把這些文字指令翻譯成二進位制,這個步驟就稱為 assembling,完成這個步驟的程式就叫做 assembler。它處理的文字,自然就叫做 aseembly code。標準化以後,稱為 assembly language,縮寫為 asm,中文譯為組合語言。

每一種 CPU 的機器指令都是不一樣的,因此對應的組合語言也不一樣。本文介紹的是目前最常見的 x86 組合語言,即 Intel 公司的 CPU 使用的那一種。
三、暫存器
學習組合語言,首先必須瞭解兩個知識點:暫存器和記憶體模型。
先來看暫存器。CPU 本身只負責運算,不負責儲存資料。資料一般都儲存在記憶體之中,CPU 要用的時候就去記憶體讀寫資料。但是,CPU 的運算速度遠高於記憶體的讀寫速度,為了避免被拖慢,CPU 都自帶一級快取和二級快取。基本上,CPU 快取可以看作是讀寫速度較快的記憶體。
但是,CPU 快取還是不夠快,另外資料在快取裡面的地址是不固定的,CPU 每次讀寫都要定址也會拖慢速度。因此,除了快取之外,CPU 還自帶了暫存器(register),用來儲存最常用的資料。也就是說,那些最頻繁讀寫的資料(比如迴圈變數),都會放在暫存器裡面,CPU 優先讀寫暫存器,再由暫存器跟記憶體交換資料。
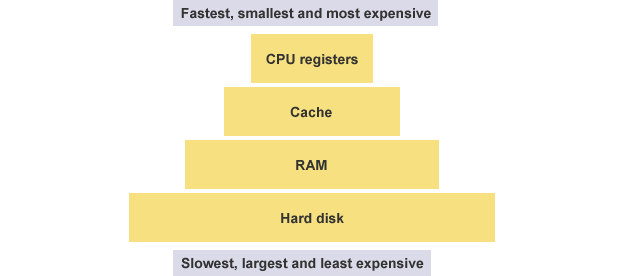
暫存器不依靠地址區分資料,而依靠名稱。每一個暫存器都有自己的名稱,我們告訴 CPU 去具體的哪一個暫存器拿資料,這樣的速度是最快的。有人比喻暫存器是 CPU 的零級快取。
四、暫存器的種類
早期的 x86 CPU 只有8個暫存器,而且每個都有不同的用途。現在的暫存器已經有100多個了,都變成通用暫存器,不特別指定用途了,但是早期暫存器的名字都被儲存了下來。
- EAX
- EBX
- ECX
- EDX
- EDI
- ESI
- EBP
- ESP
上面這8個暫存器之中,前面七個都是通用的。ESP 暫存器有特定用途,儲存當前 Stack 的地址(詳見下一節)。
我們常常看到 32位 CPU、64位 CPU 這樣的名稱,其實指的就是暫存器的大小。32 位 CPU 的暫存器大小就是4個位元組。
五、記憶體模型:Heap
暫存器只能存放很少量的資料,大多數時候,CPU 要指揮暫存器,直接跟記憶體交換資料。所以,除了暫存器,還必須瞭解記憶體怎麼儲存資料。
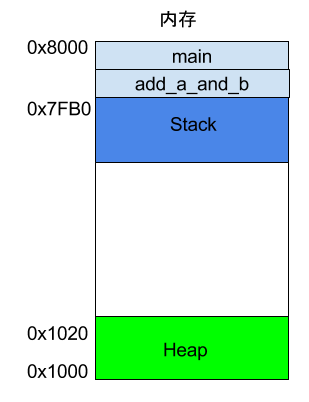
程式執行的時候,作業系統會給它分配一段記憶體,用來儲存程式和執行產生的資料。這段記憶體有起始地址和結束地址,比如從0x1000到0x8000,起始地址是較小的那個地址,結束地址是較大的那個地址。

程式執行過程中,對於動態的記憶體佔用請求(比如新建物件,或者使用malloc命令),系統就會從預先分配好的那段記憶體之中,劃出一部分給使用者,具體規則是從起始地址開始劃分(實際上,起始地址會有一段靜態資料,這裡忽略)。舉例來說,使用者要求得到10個位元組記憶體,那麼從起始地址0x1000開始給他分配,一直分配到地址0x100A,如果再要求得到22個位元組,那麼就分配到0x1020。
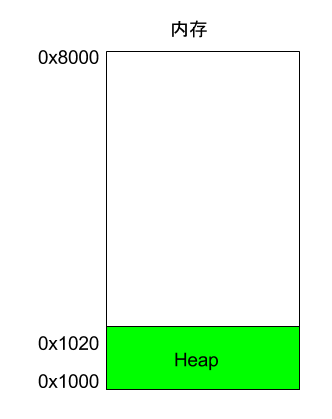
這種因為使用者主動請求而劃分出來的記憶體區域,叫做 Heap(堆)。它由起始地址開始,從低位(地址)向高位(地址)增長。Heap 的一個重要特點就是不會自動消失,必須手動釋放,或者由垃圾回收機制來回收。
六、記憶體模型:Stack
除了 Heap 以外,其他的記憶體佔用叫做 Stack(棧)。簡單說,Stack 是由於函式執行而臨時佔用的記憶體區域。
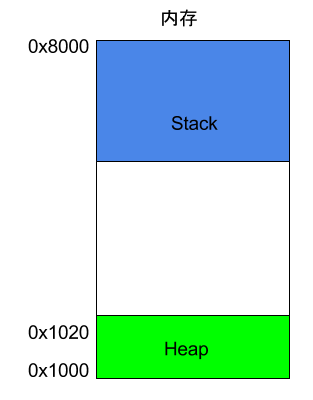
請看下面的例子。
int main() { int a = 2; int b = 3; }
上面程式碼中,系統開始執行main函式時,會為它在記憶體裡面建立一個幀(frame),所有main的內部變數(比如a和b)都儲存在這個幀裡面。main函式執行結束後,該幀就會被回收,釋放所有的內部變數,不再佔用空間。
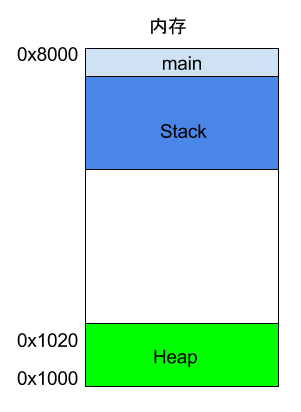
如果函式內部呼叫了其他函式,會發生什麼情況?
int main() { int a = 2; int b = 3; return add_a_and_b(a, b); }
上面程式碼中,main函式內部呼叫了add_a_and_b函式。執行到這一行的時候,系統也會為add_a_and_b新建一個幀,用來儲存它的內部變數。也就是說,此時同時存在兩個幀:main和add_a_and_b。一般來說,呼叫棧有多少層,就有多少幀。
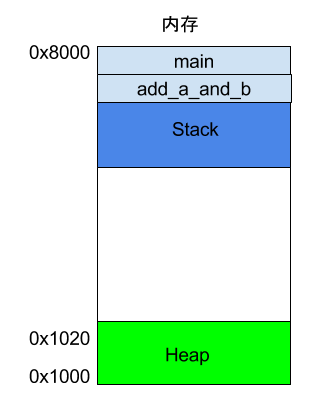
等到add_a_and_b執行結束,它的幀就會被回收,系統會回到函式main剛才中斷執行的地方,繼續往下執行。通過這種機制,就實現了函式的層層呼叫,並且每一層都能使用自己的本地變數。
所有的幀都存放在 Stack,由於幀是一層層疊加的,所以 Stack 叫做棧。生成新的幀,叫做"入棧",英文是 push;棧的回收叫做"出棧",英文是 pop。Stack 的特點就是,最晚入棧的幀最早出棧(因為最內層的函式呼叫,最先結束執行),這就叫做"後進先出"的資料結構。每一次函式執行結束,就自動釋放一個幀,所有函式執行結束,整個 Stack 就都釋放了。
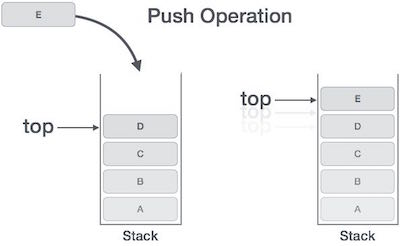
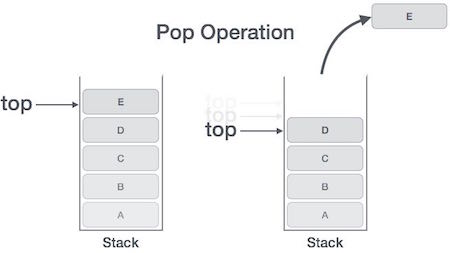
Stack 是由記憶體區域的結束地址開始,從高位(地址)向低位(地址)分配。比如,記憶體區域的結束地址是0x8000,第一幀假定是16位元組,那麼下一次分配的地址就會從0x7FF0開始;第二幀假定需要64位元組,那麼地址就會移動到0x7FB0。
七、CPU 指令
7.1 一個例項
瞭解暫存器和記憶體模型以後,就可以來看組合語言到底是什麼了。下面是一個簡單的程式example.c。
int add_a_and_b(int a, int b) { return a + b; } int main() { return add_a_and_b(2, 3); }
gcc 將這個程式轉成組合語言。
$ gcc -S example.c
上面的命令執行以後,會生成一個文字檔案example.s,裡面就是組合語言,包含了幾十行指令。這麼說吧,一個高階語言的簡單操作,底層可能由幾個,甚至幾十個 CPU 指令構成。CPU 依次執行這些指令,完成這一步操作。
example.s經過簡化以後,大概是下面的樣子。
_add_a_and_b: push %ebx mov %eax, [%esp+8] mov %ebx, [%esp+12] add %eax, %ebx pop %ebx ret _main: push 3 push 2 call _add_a_and_b add %esp, 8 ret
可以看到,原程式的兩個函式add_a_and_b和main,對應兩個標籤_add_a_and_b和_main。每個標籤裡面是該函式所轉成的 CPU 執行流程。
每一行就是 CPU 執行的一次操作。它又分成兩部分,就以其中一行為例。
push %ebx
這一行裡面,push是 CPU 指令,%ebx是該指令要用到的運運算元。一個 CPU 指令可以有零個到多個運運算元。
下面我就一行一行講解這個彙編程式,建議讀者最好把這個程式,在另一個視窗拷貝一份,省得閱讀的時候再把頁面滾動上來。
7.2 push 指令
根據約定,程式從_main標籤開始執行,這時會在 Stack 上為main建立一個幀,並將 Stack 所指向的地址,寫入 ESP 暫存器。後面如果有資料要寫入main這個幀,就會寫在 ESP 暫存器所儲存的地址。
然後,開始執行第一行程式碼。
push 3
push指令用於將運運算元放入 Stack,這裡就是將3寫入main這個幀。
雖然看上去很簡單,push指令其實有一個前置操作。它會先取出 ESP 暫存器裡面的地址,將其減去4個位元組,然後將新地址寫入 ESP 暫存器。使用減法是因為 Stack 從高位向低位發展,4個位元組則是因為3的型別是int,佔用4個位元組。得到新地址以後, 3 就會寫入這個地址開始的四個位元組。
push 2
第二行也是一樣,push指令將2寫入main這個幀,位置緊貼著前面寫入的3。這時,ESP 暫存器會再減去 4個位元組(累計減去8)。

7.3 call 指令
第三行的call指令用來呼叫函式。
call _add_a_and_b
上面的程式碼表示呼叫add_a_and_b函式。這時,程式就會去找_add_a_and_b標籤,併為該函式建立一個新的幀。
下面就開始執行_add_a_and_b的程式碼。
push %ebx
這一行表示將 EBX 暫存器裡面的值,寫入_add_a_and_b這個幀。這是因為後面要用到這個暫存器,就先把裡面的值取出來,用完後再寫回去。
這時,push指令會再將 ESP 暫存器裡面的地址減去4個位元組(累計減去12)。
7.4 mov 指令
mov指令用於將一個值寫入某個暫存器。
mov %eax, [%esp+8]
這一行程式碼表示,先將 ESP 暫存器裡面的地址加上8個位元組,得到一個新的地址,然後按照這個地址在 Stack 取出資料。根據前面的步驟,可以推算出這裡取出的是2,再將2寫入 EAX 暫存器。
下一行程式碼也是幹同樣的事情。
mov %ebx, [%esp+12]
上面的程式碼將 ESP 暫存器的值加12個位元組,再按照這個地址在 Stack 取出資料,這次取出的是3,將其寫入 EBX 暫存器。
7.5 add 指令
add指令用於將兩個運運算元相加,並將結果寫入第一個運運算元。
add %eax, %ebx
上面的程式碼將 EAX 暫存器的值(即2)加上 EBX 暫存器的值(即3),得到結果5,再將這個結果寫入第一個運運算元 EAX 暫存器。
7.6 pop 指令
pop指令用於取出 Stack 最近一個寫入的值(即最低位地址的值),並將這個值寫入運運算元指定的位置。
pop %ebx
上面的程式碼表示,取出 Stack 最近寫入的值(即 EBX 暫存器的原始值),再將這個值寫回 EBX 暫存器(因為加法已經做完了,EBX 暫存器用不到了)。
注意,pop指令還會將 ESP 暫存器裡面的地址加4,即回收4個位元組。
7.7 ret 指令
ret指令用於終止當前函式的執行,將執行權交還給上層函式。也就是,當前函式的幀將被回收。
ret
可以看到,該指令沒有運運算元。
隨著add_a_and_b函式終止執行,系統就回到剛才main函式中斷的地方,繼續往下執行。
add %esp, 8
上面的程式碼表示,將 ESP 暫存器裡面的地址,手動加上8個位元組,再寫回 ESP 暫存器。這是因為 ESP 暫存器的是 Stack 的寫入開始地址,前面的pop操作已經回收了4個位元組,這裡再回收8個位元組,等於全部回收。
ret
最後,main函式執行結束,ret指令退出程式執行。
八、參考連結
- Introduction to reverse engineering and Assembly, by Youness Alaoui
- x86 Assembly Guide, by University of Virginia Computer Science