eclipse 使用maven構建簡單的專案工程操作hadoop HDFSS
阿新 • • 發佈:2018-11-29
通過構建一個簡單的專案工程,圍繞對實現分散式檔案系統HDFS 的操作展開學習。
參考資料:華為大資料 模組2 HDFS的應用開發。
hadoop 叢集的搭建可參考:
https://mp.csdn.net/mdeditor/84288315
jdk 版本:1.8
一、使用maven 建立一個簡單的 maven project,
至於maven 專案怎麼搭建,網上有很多資料,自行檢視。我這裡貼上我使用的pom.xml 配置。
<repositories> <repository> <id>nexus</id> <name>nexus</name> <url>http://central.maven.org/maven2/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository> </repositories> <dependencies> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.5</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.1</version> <exclusions> <exclusion> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-cli</artifactId> <version>2.1.1</version> <exclusions> <exclusion> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.4</version> <exclusions> <exclusion> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>dom4j</groupId> <artifactId>dom4j</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>1.8.6</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.7</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.2.0</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.2.0</version> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies>
三、建立一個類,
public class HDFSUtil { private static Configuration conf = null;// 申明配置屬性值物件 static { conf = new Configuration(); // 指定hdfs的nameservice為cluster1,是NameNode的URI conf.set("fs.defaultFS", "hdfs://cluster1"); // 指定hdfs的nameservice為cluster1 conf.set("dfs.nameservices", "cluster1"); // cluster1下面有兩個NameNode,分別是nna節點和nns節點 conf.set("dfs.ha.namenodes.cluster1", "nna,nns"); // nna節點下的RPC通訊地址 conf.set("dfs.namenode.rpc-address.cluster1.nna", "nna:9000"); // nns節點下的RPC通訊地址 conf.set("dfs.namenode.rpc-address.cluster1.nns", "nns:9000"); // 實現故障自動轉移方式 conf.set("dfs.client.failover.proxy.provider.cluster1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"); } /** 目錄列表操作,展示分散式檔案系統(HDFS)的目錄結構 */ public static void ls(String remotePath) throws IOException { FileSystem fs = FileSystem.get(conf); // 申明一個分散式檔案系統物件 Path path = new Path(remotePath); // 得到操作分散式檔案系統(HDFS)檔案的路徑物件 FileStatus[] status = fs.listStatus(path); // 得到檔案狀態陣列 Path[] listPaths = FileUtil.stat2Paths(status); for (Path p : listPaths) { System.out.println(p); // 迴圈列印目錄結構 } } //此操作只能將dfs系統上的檔案新增到 hdfs, public static void put(String repath,String localPath) throws IOException { FileSystem fs=FileSystem.get(conf); Path remotePath=new Path(repath); Path local=new Path(localPath); fs.copyFromLocalFile(remotePath, local); fs.close(); } //讀取檔案,參考 華為大資料HDFS應用開發.教程 public static void cat(String rmpath) throws IOException { //載入配置檔案 FileSystem fs=FileSystem.get(conf); Path remotePath=new Path(rmpath); FSDataInputStream is=null; try{ if(fs.exists(remotePath)) { //開啟分散式操作物件 is=fs.open(remotePath); //讀取 BufferedReader br=new BufferedReader(new InputStreamReader(is)); //字串拼接 StringBuffer sb=new StringBuffer(); String ltxt; while((ltxt=br.readLine())!=null) { sb.append(ltxt+"\n"); } System.out.println(sb); } }catch(Exception e) { e.printStackTrace(); }finally { is.close(); fs.close(); } } //建立目錄 public static boolean createPath(String path) throws IOException { FileSystem fs=FileSystem.get(conf); Path pa=new Path(path); if(!fs.exists(pa)) { fs.mkdirs(pa); }else { return false; } return true; } //新增檔案 //fullname 檔案的全稱,並非是資料夾 //local 本機目錄 //changeFlag 是做新增操作,還是追加內容操作,“add” 時為新增,其他為追加 public static void changeFile(String fullname,String localpath,String changeFlag) throws IOException { FileSystem fs=FileSystem.get(conf); Path filepath=new Path(fullname); //初始化FSDataOutputStream物件 FSDataOutputStream is="add".equals(changeFlag)?fs.create(filepath):fs.append(filepath); //初始化 化BufferedOutputStream 物件 BufferedOutputStream bufferOutStream=new BufferedOutputStream(is); //獲取資料來源 File file=new File(localpath); InputStream iss=new FileInputStream(file); // bufferOutStream.write(); byte buff[]=new byte[10240]; int count; while((count=iss.read(buff,0,10240))>0) { //BufferedOutputStream.write寫入hdfs資料 bufferOutStream.write(buff,0,count); } //重新整理資料 iss.close(); bufferOutStream.flush(); is.hflush(); } public static void main(String[] args) throws IOException { System.out.println("-----開始遍歷根目錄-------"); ls("/"); System.out.println("-----遍歷根目錄結束---開始建立目錄----"); createPath("/newPath"); System.out.println("-----建立目錄結束---開始在新目錄下新增檔案-"); changeFile("/newPath/newFile.txt","E://uu//uu.txt","add"); System.out.println("-----結束新增檔案---開始檢視新檔案內容----"); cat("/newPath/newFile.txt"); } }
測試結果!
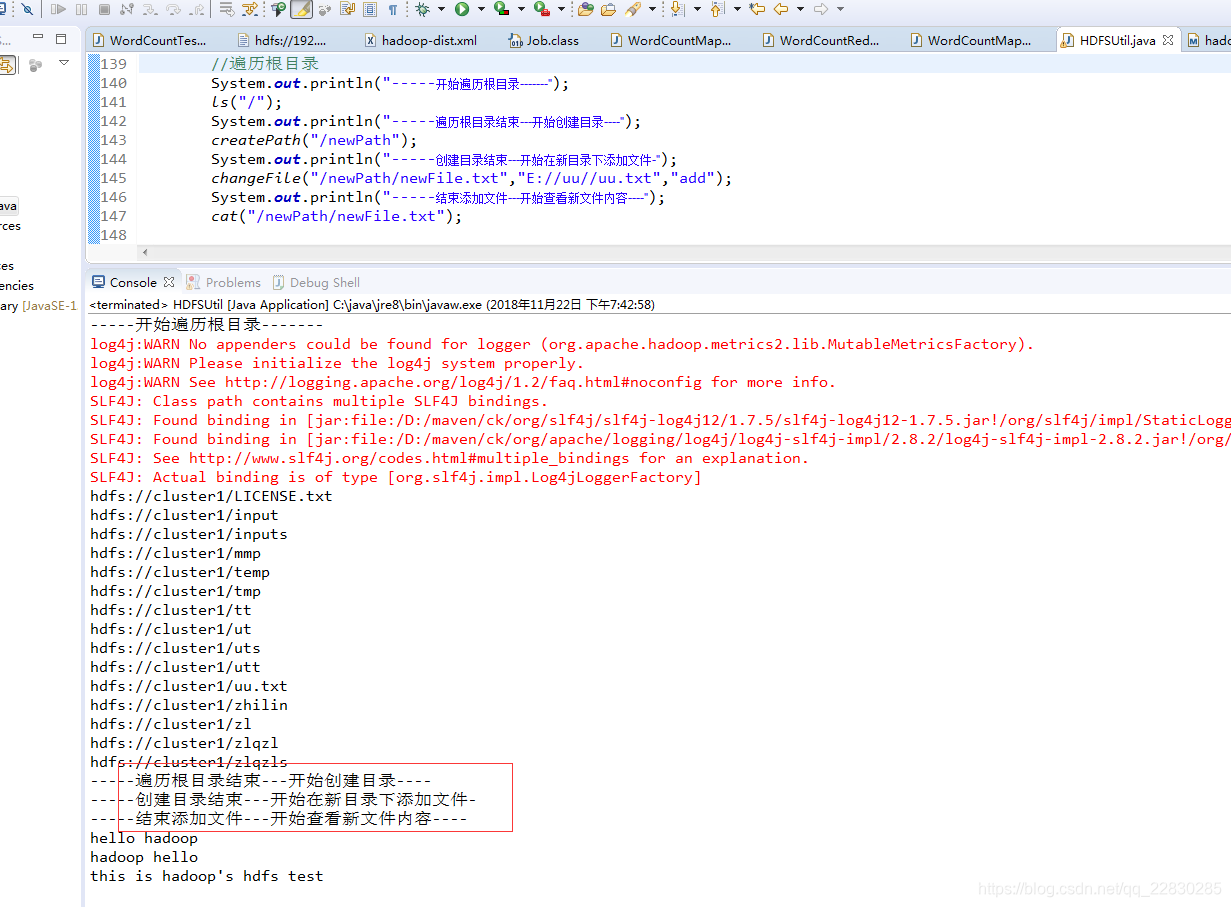
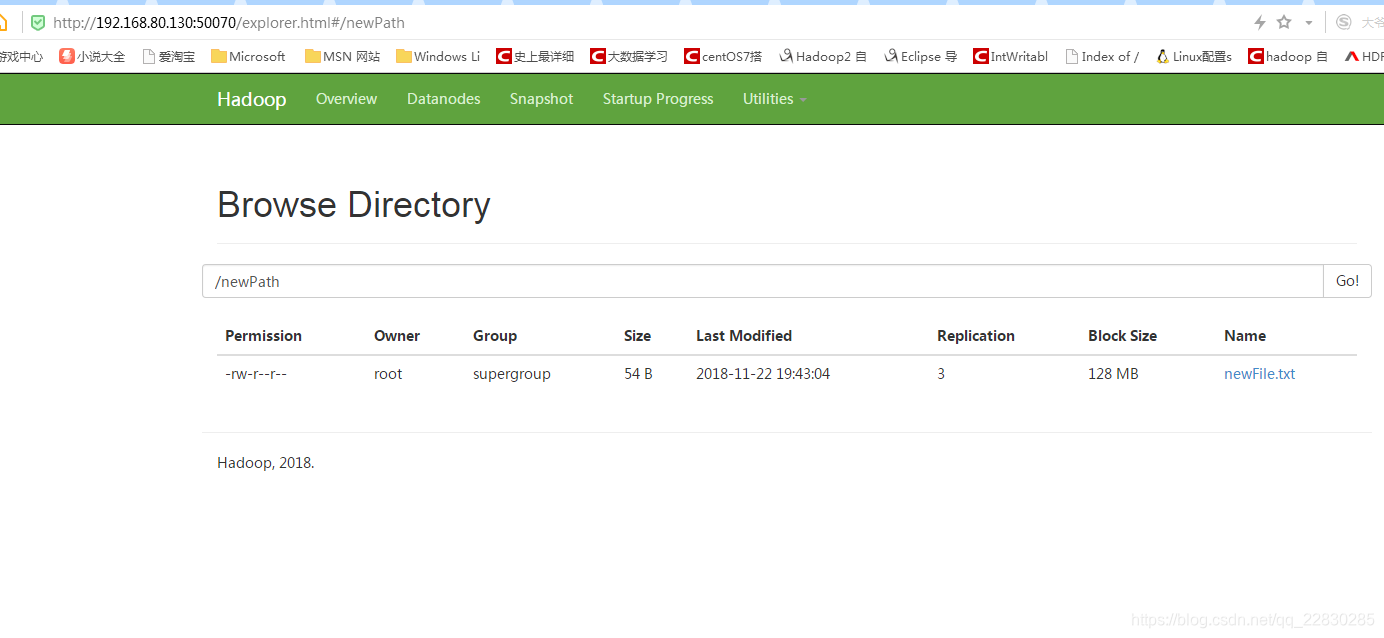
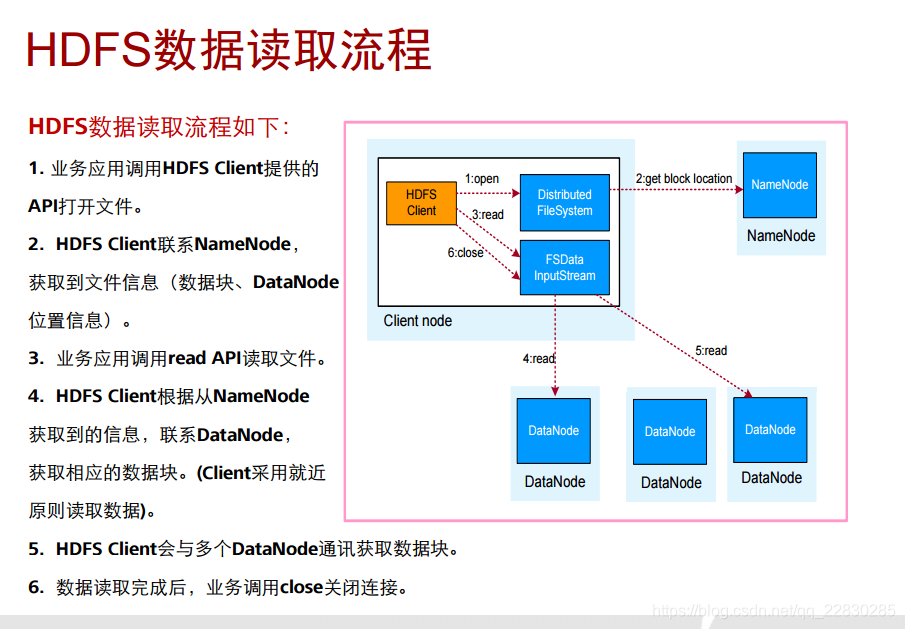
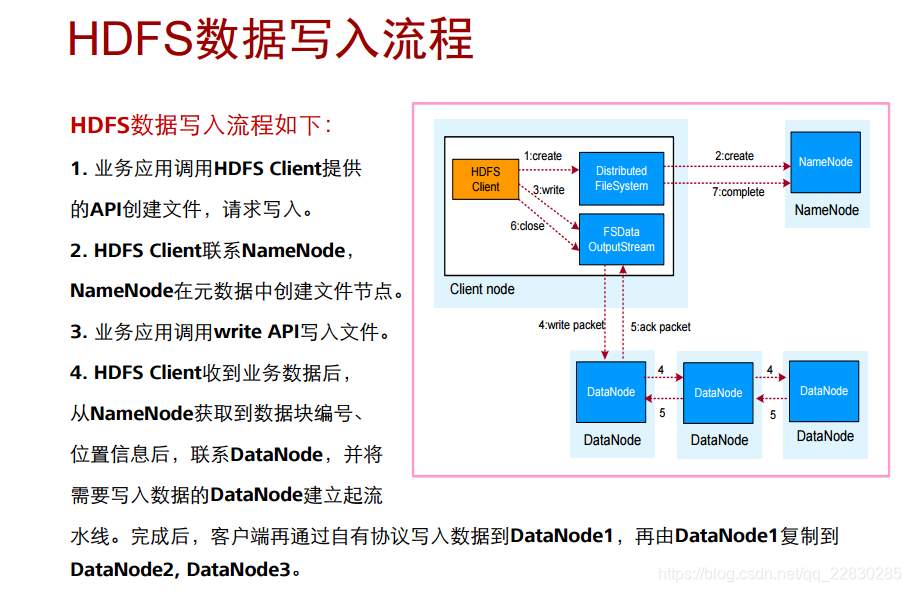
一些流程原理