
[轉載搬運工]Mark概率圖模型學習筆記:HMM、MEMM、CRF
概率圖模型學習筆記:HMM、MEMM、CRF
一、Preface
二、Prerequisite
2.1 概率圖
2.1.1 概覽
2.1.2 有向圖 vs. 無向圖
2.1.3 馬爾科夫假設&馬爾科夫性
2.2 判別式模型 vs. 生成式模型
2.3 序列建模
三、HMM
3.1 理解HMM
3.2 模型執行過程
3.2.1 學習過程
3.2.2 序列標註(解碼)過程
3.2.3 序列概率過程
四、MEMM
4.1 理解MEMM
4.2 模型執行過程
4.2.1 學習過程
4.2.2 序列標註(解碼)過程
4.2.3 序列概率過程
4.3 標註偏置?
五、CRF
5.1 理解CRF
5.2 模型執行過程
5.2.1 學習過程
5.2.2 解碼過程
5.2.3 序列概率過程
5.3 CRF++分析
5.4 LSTM+CRF
六、總結
Referrence
一、Preface
之前剛接觸NLP時做相關的任務,也必然地涉及到了序列處理任務,然後自然要接觸到概率圖模型。當時在全網搜中文資料,陸續失望地發現竟然真的沒有講得清楚的博文,發現基本是把李航老師書裡或CRF tutorial等資料的文字論述和公式抄來抄去的。當然,沒有說別人講的是錯的,只是覺得,要是沒有把東西說的讓讀者看得懂,那也是沒意義啊。或者有些吧,就是講了一大堆的東西,貌似也明白了啥,但還是不能讓我很好的理解CRF這些模型究竟是個啥,完了還是有一頭霧水散不開的感覺。試想,一堆公式扔過來,沒有個感性理解的過渡,怎麼可能理解的了。我甚至覺得,如果部落格讓人看不懂,那說明要麼自己沒理解透要麼就是思維不清晰講不清楚。所以默想,深水區攻堅還是要靠自己,然後去做調研做research,所以就寫了個這個學習記錄。
所以概率圖的研究學習思考列入了我的任務清單。不過平時的時間又非常的緊,只能陸陸續續的思考著,所以時間拖得也真是長啊。
這是個學習筆記。相比其他的學習模型,概率圖貌似確實是比較難以理解的。這裡我基本全部用自己的理解加上自己的語言習慣表達出來,off the official form,表達儘量接地氣。我會盡量將我所有理解過程中的每個關鍵小細節都詳細描述出來,以使對零基礎的初學者友好。包括理論的來龍去脈,抽象具象化,模型的構成,模型的訓練過程,會注重類比的學習。
根據現有資料,我是按照概率圖模型將HMM,MEMM,CRF放在這裡一起對比學習。之所以把他們拿在一起,是因為他們都用於標註問題。並且之所以放在概率圖框架下,是完全因為自己top-down思維模式使然。另外,概率圖下還有很多的模型,這兒只學習標註模型。
正兒八經的,我對這些個概率圖模型有了徹悟,是從我明白了生成式模型與判別式模型的那一刻。一直在思考從概率圖模型角度講他們的區別到底在哪。
另外,篇幅略顯長,但咱們不要急躁,好好看完這篇具有良好的上下文的筆記,那肯定是能理解的,或者就多看幾遍。
個人學習習慣就是,要儘可能地將一群沒有結構的知識點融會貫通,再用一條樹狀結構的繩將之串起來,結構化,就是說要成體系,這樣把繩子頭一拎所有的東西都能拿起來。學習嘛,應該要是一個熵減的過程,卓有成效的學習應該是混亂度越來越小!這個思維方式對我影響還是蠻大的。
在正式內容之前,還是先要明確下面這一點,最好腦子裡形成一個定勢:
統計機器學習所有的模型(個別instant model和優化演算法以及其他的特種工程知識點除外)的工作流程都是如此:
a.訓練模型引數,得到模型(由引數唯一確定),
b.預測給定的測試資料。
拿這個流程去挨個學習模型,思路上會非常順暢。這一點可參見我 另一篇文字介紹。
除此之外,對初學者的關於機器學習的入門學習方式也順帶表達一下(empirical speaking):
a.完整特徵工程競賽
b.野部落格理論入門理解
c.再回到程式碼深入理解模型內部
d.再跨理論,查閱經典理論鉅作。這時感性理性都有一定高度,會遇到很多很大的理解上的疑惑,這時3大經典可能就可以發揮到最大作用了。
很多beginer,就比如說學CRF模型,然後一上來就擺一套複雜的公式,什麼我就問,這能理解的了嗎?這是正確的開啟姿勢嗎?當然了,也要怪那些博主,直接整一大堆核心公式,實際上讀者的理解門檻可能就是一個過渡性的細枝末節而已。沒有上下文的教育肯定是失敗的(這一點我又想吐槽國內絕大部分本科的院校教育模式)。所以說帶有完整上下文資訊以及過程來龍去脈交代清楚才算到位吧。
而不是一上來就死啃被人推薦的“經典資料”,這一點相信部分同學會理解。好比以前本科零基礎學c++ JAVA,上來就看primr TIJ,結果浪費了時間精力一直在門外兜圈。總結方法吸取教訓,應該快速上手程式碼,才是最高效的。經典最好是用來查閱的工具書,我目前是李航周志華和經典的那3本迭代輪詢看了好多輪,經常會反覆查詢某些model或理論的來龍去脈;有時候要查很多相關的東西,看這些書還是難以貫通,然後發現有些人的部落格寫的會更容易去理解。所以另外,學習資料渠道也要充分才行。
最後提示一下,請務必按照標題層級結構和目錄一級一級閱讀,防止跟丟。
二、Prerequisite
2.1 概率圖
之前剛接觸CRF時,一上來試圖越過一堆繁瑣的概率圖相關概念,不過sad to say, 這是後面的前驅知識,後面還得反過來補這個點。所以若想整體把握,系統地拿下這一塊,應該還是要越過這塊門檻的。
當然了,一開始只需略略快速看一篇,後面可再返過來補查。
2.1.1 概覽
在統計概率圖(probability graph models)中,參考宗成慶老師的書,是這樣的體系結構(個人非常喜歡這種型別的圖):
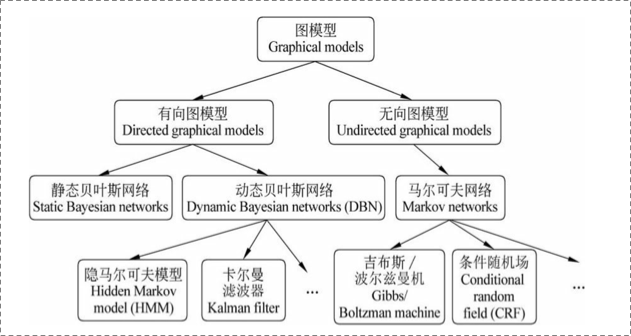
在概率圖模型中,資料(樣本)由公式 建模表示:
表示節點,即隨機變數(放在此處的,可以是一個token或者一個label),具體地,用
為隨機變數建模,注意
現在是代表了一批隨機變數(想象對應一條sequence,包含了很多的token),
為這些隨機變數的分佈;
表示邊,即概率依賴關係。具體咋理解,還是要在後面結合HMM或CRF的graph具體解釋。
2.1.2 有向圖 vs. 無向圖
上圖可以看到,貝葉斯網路(信念網路)都是有向的,馬爾科夫網路無向。所以,貝葉斯網路適合為有單向依賴的資料建模,馬爾科夫網路適合實體之間互相依賴的建模。具體地,他們的核心差異表現在如何求 ,即怎麼表示
這個的聯合概率。
1. 有向圖
對於有向圖模型,這麼求聯合概率:
舉個例子,對於下面的這個有向圖的隨機變數(注意,這個圖我畫的還是比較廣義的):
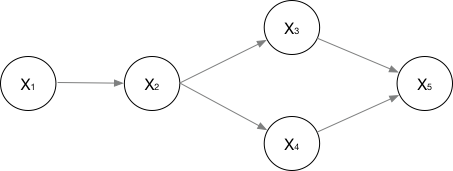
應該這樣表示他們的聯合概率:
應該很好理解吧。
2. 無向圖
對於無向圖,我看資料一般就指馬爾科夫網路(注意,這個圖我畫的也是比較廣義的)。
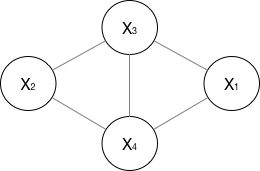
如果一個graph太大,可以用因子分解將 寫為若干個聯合概率的乘積。咋分解呢,將一個圖分為若干個“小團”,注意每個團必須是“最大團”(就是裡面任何兩個點連在了一塊,具體……算了不解釋,有點“最大連通子圖”的感覺),則有:
, 其中 ,公式應該不難理解吧,歸一化是為了讓結果算作概率。
所以像上面的無向圖:
其中, 是一個最大團
上隨機變數們的聯合概率,一般取指數函式的:
好了,管這個東西叫做勢函式。注意 是否有看到CRF的影子。
那麼概率無向圖的聯合概率分佈可以在因子分解下表示為:
注意,這裡的理解還蠻重要的,注意遞推過程,敲黑板,這是CRF的開端!
這個由Hammersly-Clifford law保證,具體不展開。
2.1.3 馬爾科夫假設&馬爾科夫性
這個也屬於前饋知識。
1. 馬爾科夫假設
額應該是齊次馬爾科夫假設,這樣假設:馬爾科夫鏈 裡的
總是隻受
一個人的影響。
馬爾科夫假設這裡相當於就是個1-gram。
馬爾科夫過程呢?即,在一個過程中,每個狀態的轉移只依賴於前n個狀態,並且只是個n階的模型。最簡單的馬爾科夫過程是一階的,即只依賴於器哪一個狀態。
2. 馬爾科夫性
馬爾科夫性是是保證或者判斷概率圖是否為概率無向圖的條件。
三點內容:a. 成對,b. 區域性,c. 全域性。
我覺得這個不用展開。
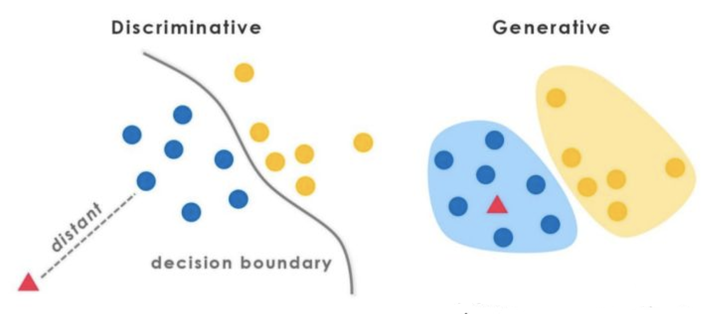
2.2 判別式(discriminative)模型 vs. 生成式(generative)模型
在監督學習下,模型可以分為判別式模型與生成式模型。
重點來了。上面有提到,我理解了HMM、CRF模型的區別是從理解了判別式模型與生成式模型的那刻,並且瞬間對其他的模型有一個恍然大悟。我記得是一年前就開始糾結這兩者的區別,但我只能說,栽在了一些爛部落格上,大部分都沒有自己的insightful理解,也就是一頓官話,也真是難以理解。後來在知乎上一直琢磨別人的答案,然後某日早晨終於豁然開朗,就是這種感覺。
好了,我要用自己的理解來轉述兩者的區別了below。
先問個問題,根據經驗,A批模型(神經網路模型、SVM、perceptron、LR、DT……)與B批模型(NB、LDA……),有啥區別不?(這個問題需要一些模型使用經驗)應該是這樣的:
1. A批模型是這麼工作的,他們直接將資料的Y(或者label),根據所提供的features,學習,最後畫出了一個明顯或者比較明顯的邊界(具體怎麼做到的?通過複雜的函式對映,或者決策疊加等等mechanism),這一點線性LR、線性SVM應該很明顯吧。
2. B批模型是這麼工作的,他們先從訓練樣本資料中,將所有的資料的分佈情況摸透,然後最終確定一個分佈,來作為我的所有的輸入資料的分佈,並且他是一個聯合分佈(注意
包含所有的特徵
,
包含所有的label)。然後我來了新的樣本資料(inference),好,通過學習來的模型的聯合分佈

好了,應該說清楚了。
1. 判別式模型
那麼A批模型對應了判別式模型。根據上面的兩句話的區別,可以知道判別模型的特徵了,所以有句話說:判別模型是直接對 建模,就是說,直接根據X特徵來對Y建模訓練。
具體地,我的訓練過程是確定構件 模型裡面“複雜對映關係”中的引數,完了再去inference一批新的sample。
所以判別式模型的特徵總結如下:
- 對
建模
- 對所有的樣本只構建一個模型,確認總體判別邊界
- 觀測到輸入什麼特徵,就預測最可能的label
- 另外,判別式的優點是:對資料量要求沒生成式的嚴格,速度也會快,小資料量下準確率也會好些。
2. 生成式模型
同樣,B批模型對應了生成式模型。並且需要注意的是,在模型訓練中,我學習到的是X與Y的聯合模型 ,也就是說,我在訓練階段是隻對
建模,我需要確定維護這個聯合概率分佈的所有的資訊引數。完了之後在inference再對新的sample計算
,匯出
,但這已經不屬於建模階段了。
結合NB過一遍生成式模型的工作流程。學習階段,建模: (當然,NB具體流程去隔壁參考),然後
。
另外,LDA也是這樣,只是他更過分,需要確定很多個概率分佈,而且建模抽樣都蠻複雜的。
所以生成式總結下有如下特點:
- 對
- 這裡我們主要講分類問題,所以是要對每個label(
)都需要建模,最終選擇最優概率的label為結果,所以沒有什麼判別邊界。(對於序列標註問題,那隻需要構件一個model)
- 中間生成聯合分佈,並可生成取樣資料。
- 生成式模型的優點在於,所包含的資訊非常齊全,我稱之為“上帝資訊”,所以不僅可以用來輸入label,還可以幹其他的事情。生成式模型關注結果是如何產生的。但是生成式模型需要非常充足的資料量以保證取樣到了資料本來的面目,所以速度相比之下,慢。
這一點明白後,後面講到的HMM與CRF的區別也會非常清晰。
最後identity the picture below:
2.3 序列建模
為了號召零門檻理解,現在解釋如何為序列問題建模。
序列包括時間序列以及general sequence,但兩者無異。連續的序列在分析時也會先離散化處理。常見的序列有如:時序資料、本文句子、語音資料、等等。
廣義下的序列有這些特點:
- 節點之間有關聯依賴性/無關聯依賴性
- 序列的節點是隨機的/確定的
- 序列是線性變化/非線性的
- ……
對不同的序列有不同的問題需求,常見的序列建模方法總結有如下:
- 擬合,預測未來節點(或走勢分析):
a. 常規序列建模方法:AR、MA、ARMA、ARIMA
b. 迴歸擬合
c. Neural Networks
2. 判斷不同序列類別,即分類問題:HMM、CRF、General Classifier(ML models、NN models)
3. 不同時序對應的狀態的分析,即序列標註問題:HMM、CRF、RecurrentNNs
在本篇文字中,我們只關注在2. & 3.類問題下的建模過程和方法。
三、HMM
最早接觸的是HMM。較早做過一個專案,關於聲波手勢識別,跟聲音識別的機制一樣,使用的正是HMM的一套方法。後來又用到了kalman filter,之後做序列標註任務接觸到了CRF,所以整個概率圖模型還是接觸的方面還蠻多。
3.1 理解HMM
在2.2、2.3中提序列的建模問題時,我們只是討論了常規的序列資料,e.g., ,像2.3的圖片那樣。像這種序列一般用馬爾科夫模型就可以勝任。實際上我們碰到的更多的使用HMM的場景是每個節點
下還附帶著另一個節點
,正所謂隱含馬爾科夫模型,那麼除了正常的節點,還要將隱含狀態節點也得建模進去。正兒八經地,將
換成
,並且他們的名稱變為狀態節點、觀測節點。狀態節點正是我的隱狀態。
HMM屬於典型的生成式模型。對照2.1的講解,應該是要從訓練資料中學到資料的各種分佈,那麼有哪些分佈呢以及是什麼呢?直接正面回答的話,正是HMM的5要素,其中有3個就是整個資料的不同角度的概率分佈:
,隱藏狀態集
, 我的隱藏節點不能隨意取,只能限定取包含在隱藏狀態集中的符號。
,觀測集
, 同樣我的觀測節點不能隨意取,只能限定取包含在觀測狀態集中的符號。
,狀態轉移概率矩陣,這個就是其中一個概率分佈。他是個矩陣,
(N為隱藏狀態集元素個數),其中
即第i個隱狀態節點,即所謂的狀態轉移嘛。
,觀測概率矩陣,這個就是另一個概率分佈。他是個矩陣,
(N為隱藏狀態集元素個數,M為觀測集元素個數),其中
即第i個觀測節點,
即第i個隱狀態節點,即所謂的觀測概率(發射概率)嘛。
,在第一個隱狀態節點
,我得人工單獨賦予,我第一個隱狀態節點的隱狀態是
所以圖看起來是這樣的:
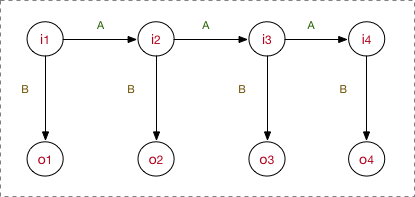
看的很清楚,我的模型先去學習要確定以上5要素,之後在inference階段的工作流程是:首先,隱狀態節點 是不能直接觀測到的資料節點,
才是能觀測到的節點,並且注意箭頭的指向表示了依賴生成條件關係,
在A的指導下生成下一個隱狀態節點
,並且
在
的指導下生成依賴於該
的觀測節點
, 並且我只能觀測到序列
。
好,舉例子說明(序列標註問題,POS,標註集BES):
input: "學習出一個模型,然後再預測出一條指定"
expected output: 學/B 習/E 出/S 一/B 個/E 模/B 型/E ,/S 然/B 後/E 再/E 預/B 測/E ……
其中,input裡面所有的char構成的字表,形成觀測集,這些概率分佈資訊(上帝資訊)都是我在學習過程中所確定的引數。
然後一般初次接觸的話會疑問:為什麼要這樣?……好吧,就應該是這樣啊,根據具有同時帶著隱藏狀態節點和觀測節點的型別的序列,在HMM下就是這樣子建模的。
下面來點高層次的理解:
- 根據概率圖分類,可以看到HMM屬於有向圖,並且是生成式模型,直接對聯合概率分佈建模
(注意,這個公式不在模型執行的任何階段能體現出來,只是我們都去這麼來表示HMM是個生成式模型,他的聯合概率
就是這麼計算的)。
- 並且B中
,這意味著o對i有依賴性。
- 在A中,
,也就是說只遵循了一階馬爾科夫假設,1-gram。試想,如果資料的依賴超過1-gram,那肯定HMM肯定是考慮不進去的。這一點限制了HMM的效能。
3.2 模型執行過程
模型的執行過程(工作流程)對應了HMM的3個問題。
3.2.1 學習訓練過程
對照2.1的講解,HMM學習訓練的過程,就是找出資料的分佈情況,也就是模型引數的確定。
主要學習演算法按照訓練資料除了觀測狀態序列 是否還有隱狀態序列
分為:
- 極大似然估計, with 隱狀態序列
- Baum-Welch(前向後向), without 隱狀態序列
感覺不用做很多的介紹,都是很實實在在的演算法,看懂了就能理解。簡要提一下。
1. 極大似然估計
一般做NLP的序列標註等任務,在訓練階段肯定是有隱狀態序列的。所以極大似然估計法是非常常用的學習演算法,我見過的很多程式碼裡面也是這麼計算的。比較簡單。
- step1. 算A
- step2. 算B
- step3. 直接估計
比如說,在程式碼裡計算完了就是這樣的:



2. Baum-Welch(前向後向)
就是一個EM的過程,如果你對EM的工作流程有經驗的話,對這個Baum-Welch一看就懂。EM的過程就是初始化一套值,然後迭代計算,根據結果再調整值,再迭代,最後收斂……好吧,這個理解是沒有捷徑的,去隔壁鑽研EM吧。
這裡只提一下核心。因為我們手裡沒有隱狀態序列 資訊,所以我先必須給初值
,初步確定模型,然後再迭代計算出
,中間計算過程會用到給出的觀測狀態序列
。另外,收斂性由EM的XXX定理保證。
3.2.2 序列標註(解碼)過程
好了,學習完了HMM的分佈引數,也就確定了一個HMM模型。需要注意的是,這個HMM是對我這一批全部的資料進行訓練所得到的引數。
序列標註問題也就是“預測過程”,通常稱為解碼過程。對應了序列建模問題3.。對於序列標註問題,我們只需要學習出一個HMM模型即可,後面所有的新的sample我都用這一個HMM去apply。
我們的目的是,在學習後已知了 ,現在要求出
,進一步
再直白點就是,我現在要在給定的觀測序列下找出一條隱狀態序列,條件是這個隱狀態序列的概率是最大的那個。
具體地,都是用Viterbi演算法解碼,是用DP思想減少重複的計算。Viterbi也是滿大街的,不過要說的是,Viterbi不是HMM的專屬,也不是任何模型的專屬,他只是恰好被滿足了被HMM用來使用的條件。誰知,現在大家都把Viterbi跟HMM捆綁在一起了, shame。
Viterbi計算有向無環圖的一條最大路徑,應該還好理解。如圖:
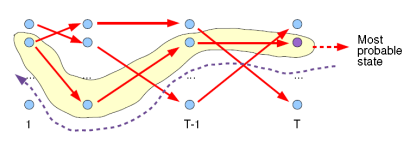
關鍵是注意,每次工作熱點區只涉及到t 與 t-1,這對應了DP的無後效性的條件。如果對某些同學還是很難理解,請參考這個答案下@Kiwee的回答吧。
3.2.3 序列概率過程
我通過HMM計算出序列的概率又有什麼用?針對這個點我把這個問題詳細說一下。
實際上,序列概率過程對應了序列建模問題2.,即序列分類。
在3.2.2第一句話我說,在序列標註問題中,我用一批完整的資料訓練出了一支HMM模型即可。好,那在序列分類問題就不是訓練一個HMM模型了。我應該這麼做(結合語音分類識別例子):
目標:識別聲音是A發出的還是B發出的。
HMM建模過程:
1. 訓練:我將所有A說的語音資料作為dataset_A,將所有B說的語音資料作為dataset_B(當然,先要分別對dataset A ,B做預處理encode為元資料節點,形成sequences),然後分別用dataset_A、dataset_B去訓練出HMM_A/HMM_B
2. inference:來了一條新的sample(sequence),我不知道是A的還是B的,沒問題,分別用HMM_A/HMM_B計算一遍序列的概率得到,比較兩者大小,哪個概率大說明哪個更合理,更大概率作為目標類別。
所以,本小節的理解重點在於,如何對一條序列計算其整體的概率。即目標是計算出 。這個問題前輩們在他們的經典中說的非常好了,比如參考李航老師整理的:
- 直接計演算法(窮舉搜尋)
- 前向演算法
- 後向演算法
後面兩個演算法採用了DP思想,減少計算量,即每一次直接引用前一個時刻的計算結果以避免重複計算,跟Viterbi一樣的技巧。
還是那句,因為這篇文件不是專門講演算法細節的,所以不詳細展開這些。畢竟,所有的科普HMM、CRF的部落格貌似都是在扯這些演算法,妥妥的街貨,就不搬運了。
四、MEMM
MEMM,即最大熵馬爾科夫模型,這個是在接觸了HMM、CRF之後才知道的一個模型。說到MEMM這一節時,得轉換思維了,因為現在這MEMM屬於判別式模型。
不過有一點很尷尬,MEMM貌似被使用或者講解引用的不及HMM、CRF。
4.1 理解MEMM
這裡還是囉嗦強調一下,MEMM正因為是判別模型,所以不廢話,我上來就直接為了確定邊界而去建模,比如說序列求概率(分類)問題,我直接考慮找出函式分類邊界。這一點跟HMM的思維方式發生了很大的變化,如果不對這一點有意識,那麼很難理解為什麼MEMM、CRF要這麼做。
HMM中,觀測節點 依賴隱藏狀態節點
,也就意味著我的觀測節點只依賴當前時刻的隱藏狀態。但在更多的實際場景下,觀測序列是需要很多的特徵來刻畫的,比如說,我在做NER時,我的標註
不僅跟當前狀態
相關,而且還跟前後標註
相關,比如字母大小寫、詞性等等。
為此,提出來的MEMM模型就是能夠直接允許“定義特徵”,直接學習條件概率,即 , 總體為:
並且, 這個概率通過最大熵分類器建模(取名MEMM的原因):
重點來了,這是ME的內容,也是理解MEMM的關鍵: 這部分是歸一化;
是特徵函式,具體點,這個函式是需要去定義的;
是特徵函式的權重,這是個未知引數,需要從訓練階段學習而得。
比如我可以這麼定義特徵函式:
其中,特徵函式 個數可任意制定,
所以總體上,MEMM的建模公式這樣:
是的,公式這部分之所以長成這樣,是由ME模型決定的。
請務必注意,理解判別模型和定義特徵兩部分含義,這已經涉及到CRF的雛形了。
所以說,他是判別式模型,直接對條件概率建模。 上圖:
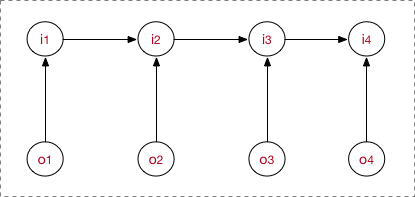
MEMM需要兩點注意:
- 與HMM的
依賴
不一樣,MEMM當前隱藏狀態
- 需要注意,之所以圖的箭頭這麼畫,是由MEMM的公式決定的,而公式是creator定義出來的。
好了,走一遍完整流程。
step1. 先預定義特徵函式,
step2. 在給定的資料上,訓練模型,確定引數,即確定了MEMM模型
step3. 用確定的模型做序列標註問題或者序列求概率問題。
4.2 模型執行過程
MEMM模型的工作流程也包括了學習訓練問題、序列標註問題、序列求概率問題。
4.2.1 學習訓練過程
一套MEMM由一套引數唯一確定,同樣地,我需要通過訓練資料學習這些引數。MEMM模型很自然需要學習裡面的特徵權重λ。
不過跟HMM不用的是,因為HMM是生成式模型,引數即為各種概率分佈元引數,資料量足夠可以用最大似然估計。而判別式模型是用函式直接判別,學習邊界,MEMM即通過特徵函式來界定。但同樣,MEMM也有極大似然估計方法、梯度下降、牛頓迭代發、擬牛頓下降、BFGS、L-BFGS等等。各位應該對各種優化方法有所瞭解的。
嗯,具體詳細求解過程貌似問題不大。
4.2.2 序列標註過程
還是跟HMM一樣的,用學習好的MEMM模型,在新的sample(觀測序列 )上找出一條概率最大最可能的隱狀態序列
。
只是現在的圖中的每個隱狀態節點的概率求法有一些差異而已,正確將每個節點的概率表示清楚,路徑求解過程還是一樣,採用viterbi演算法。
4.2.3 序列求概率過程
跟HMM舉的例子一樣的,也是分別去為每一批資料訓練構建特定的MEMM,然後根據序列在每個MEMM模型的不同得分概率,選擇最高分數的模型為wanted類別。
應該可以不用展開,吧……
4.3 標註偏置?
MEMM討論的最多的是他的labeling bias 問題。
1. 現象
是從街貨上烤過來的……
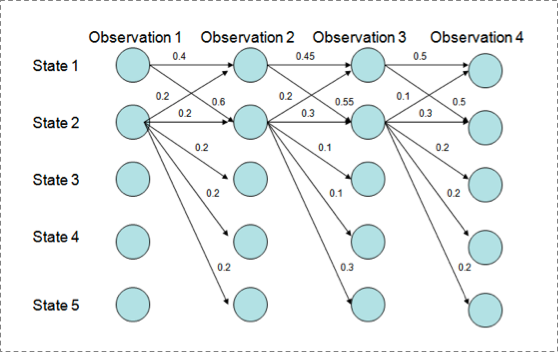
用Viterbi演算法解碼MEMM,狀態1傾向於轉換到狀態2,同時狀態2傾向於保留在狀態2。 解碼過程細節(需要會viterbi演算法這個前提):
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 ,
P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018,
P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06,
P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066
但是得到的最優的狀態轉換路徑是1->1->1->1,為什麼呢?因為狀態2可以轉換的狀態比狀態1要多,從而使轉移概率降低,即MEMM傾向於選擇擁有更少轉移的狀態。
2. 解釋原因
直接看MEMM公式:
求和的作用在概率中是歸一化,但是這裡歸一化放在了指數內部,管這叫local歸一化。 來了,viterbi求解過程,是用dp的狀態轉移公式(MEMM的沒展開,請參考CRF下面的公式),因為是區域性歸一化,所以MEMM的viterbi的轉移公式的第二部分出現了問題,導致dp無法正確的遞迴到全域性的最優。
五、CRF
我覺得一旦有了一個清晰的工作流程,那麼按部就班地,沒有什麼很難理解的地方,因為整體框架已經胸有成竹了,剩下了也只有添磚加瓦小修小補了。有了上面的過程基礎,CRF也是類似的,只是有方法論上的細微區別。
5.1 理解CRF
請看第一張概率圖模型構架圖,CRF上面是馬爾科夫隨機場(馬爾科夫網路),而條件隨機場是在給定的隨機變數 (具體,對應觀測序列
)條件下,隨機變數
(具體,對應隱狀態序列
的馬爾科夫隨機場。
廣義的CRF的定義是: 滿足 的馬爾科夫隨機場叫做條件隨機場(CRF)。
不過一般說CRF為序列建模,就專指CRF線性鏈(linear chain CRF):
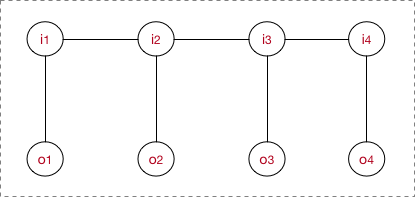
在2.1.2中有提到過,概率無向圖的聯合概率分佈可以在因子分解下表示為:
而線上性鏈CRF示意圖中,每一個( )對為一個最大團,即在上式中
。並且線性鏈CRF滿足
。
所以CRF的建模公式如下:
我要敲黑板了,這個公式是非常非常關鍵的,注意遞推過程啊,我是怎麼從 跳到
的。
不過還是要多囉嗦一句,想要理解CRF,必須判別式模型的概念要深入你心。正因為是判別模型,所以不廢話,我上來就直接為了確定邊界而去建模,因為我創造出來就是為了這個分邊界的目的的。比如說序列求概率(分類)問題,我直接考慮找出函式分類邊界。所以才為什麼會有這個公式。所以再看到這個公式也別懵逼了,he was born for discriminating the given data from different classes. 就這樣。不過待會還會具體介紹特徵函式部分的東西。
除了建模總公式,關鍵的CRF重點概念在MEMM中已強調過:判別式模型、特徵函式。
1. 特徵函式
上面給出了CRF的建模公式:
- 下標i表示我當前所在的節點(token)位置。
- 下標k表示我這是第幾個特徵函式,並且每個特徵函式都附屬一個權重
,也就是這麼回事,每個團裡面,我將為
構造M個特徵,每個特徵執行一定的限定作用,然後建模時我再為每個特徵函式加權求和。
是用來歸一化的,為什麼?想想LR以及softmax為何有歸一化呢,一樣的嘛,形成概率值。
- 再來個重要的理解。
這個表示什麼?具體地,表示了在給定的一條觀測序列
條件下,我用CRF所求出來的隱狀態序列
的概率,注意,這裡的I是一條序列,有多個元素(一組隨機變數),而至於觀測序列
J條隱狀態I,但我肯定最終選的是最優概率的那條(by viterbi)。這一點希望你能理解。
對於CRF,可以為他定義兩款特徵函式:轉移特徵&狀態特徵。 我們將建模總公式展開:
其中:
為i處的轉移特徵,對應權重
,每個
- 舉個例子:
- sl為i處的狀態特徵,對應權重μl,每個tokeni都有L個特徵
- 舉個例子:
不過一般情況下,我們不把兩種特徵區別的那麼開,合在一起:
滿足特徵條件就取值為1,否則沒貢獻,甚至你還可以讓他打負分,充分懲罰。
再進一步理解的話,我們需要把特徵函式部分摳出來:
是的,我們為 打分,滿足條件的就有所貢獻。最後將所得的分數進行log線性表示,求和後歸一化,即可得到概率值……完了又扯到了log線性模型。現在稍作解釋:
log-linear models take the following form:

我覺得對LR或者sotfmax熟悉的對這個應該秒懂。然後CRF完美地滿足這個形式,所以又可以歸入到了log-linear models之中。
5.2 模型執行過程
模型的工作流程,跟MEMM是一樣的:
- step1. 先預定義特徵函式
,
- step2. 在給定的資料上,訓練模型,確定引數
- step3. 用確定的模型做
序列標註問題或者序列求概率問題。
可能還是沒做到100%懂,結合例子說明:
……
5.2.1 學習訓練過程
一套CRF由一套引數λ唯一確定(先定義好各種特徵函式)。
同樣,CRF用極大似然估計方法、梯度下降、牛頓迭代、擬牛頓下降、IIS、BFGS、L-BFGS等等。各位應該對各種優化方法有所瞭解的。其實能用在log-linear models上的求參方法都可以用過來。
嗯,具體詳細求解過程貌似問題不大。
5.2.2 序列標註過程
還是跟HMM一樣的,用學習好的CRF模型,在新的sample(觀測序列 )上找出一條概率最大最可能的隱狀態序列
相關推薦
[轉載搬運工]Mark概率圖模型學習筆記:HMM、MEMM、CRF
概率圖模型學習筆記:HMM、MEMM、CRF 一、Preface 二、Prerequisite 2.1 概率圖 2.1.1 概覽2.1.2 有向圖 vs. 無向圖2.1.3 馬爾科夫假設&馬爾科夫性2.2 判別式模型 vs. 生成式模型2.3 序列建模 三、HMM
概率圖模型學習(一)概述
本文內容根據Stanford 教授 Daphne Koller 的公開課 Probabilistic Graphical Model內容整理。 1.什麼是概率圖模型 概率圖模型即為解決某一類應用問題的一個框架。在理解這個概念之前,首先來看兩個例子: 1) 上面這張圖片
Tensorflow學習筆記:變數作用域、模型的載入與儲存、執行緒與佇列實現多執行緒讀取樣本
# tensorflow變數作用域 用上下文語句規定作用域 with tf.variable_scope("作用域_name") ......
python學習筆記:迭代器、生成器、yield關鍵字
一、迭代器 ---iterator 所有能用for...in...語法的叫做迭代器,列表、字串、檔案等等。 #This is a iterator, #Here uses "[ ]" not "( )" ☆ mylist=[x*x for x in range(3)] for i in my
Tensorflow學習筆記:讀取二進位制檔案、讀寫TFRecord檔案
#影象基本知識 OpenCV已經學過 #圖片操作目的: 增加圖片資料的統一性:大小與格式統一 縮小圖片資料量,防止增加開銷 #圖片操作:放大或縮小
js學習筆記:事件——事件流、事件處理程式、事件物件
Javascript與HTML之間的互動是通過事件實現的。 事件,就是文件或瀏覽器視窗中發生的一些特定的互動瞬間。 可以使用偵聽器來預定事件,以便事件發生時執行相應程式碼。 事件流 事件流描述的是從頁面中接受事件的順序。 事件冒泡 IE的事件
OpenCV學習筆記:運動物體檢測、跟蹤和繪製曲線運動軌跡
一、簡介本文章的起源是本人在做一個專案,用攝像頭識別筆,根據筆的運動,繪製出其軌跡。主要應用到的方法,有運動物體識別、運動物體檢測,以及繪製運動物體的運動軌跡。1、 運動物體的識別方法很多,主要就是要提取相關物體的特徵,主要分為: (1)各種色彩空間直方圖,利用
《機器學習》 周志華學習筆記第十四章 概率圖模型(課後習題)python實現
一、基本內容 1.隱馬爾可夫模型 1.1. 假定所有關心的變數集合為Y,可觀測變數集合為O,其他變數集合為R, 生成式模型考慮聯合分佈P(Y,R,O),判別式模型考慮條件分佈P(Y,R|O),給定一組觀測變數值,推斷就是要由P(Y,R,O)或者P(Y,R|O)得到條件概率分佈P(Y,
從零開始-Machine Learning學習筆記(30)-概率圖模型
文章目錄 1. 隱馬爾可夫模型(Hidden Markov Model,HMM) 2. 馬爾科夫隨機場(Markov Random Field, MRF) 3. 條件隨機場(Conditional Random Field,
機器學習筆記(七):概率圖模型
機器學習最重要的任務,是根據一些已觀察到的證據(例如訓練樣本)來對感興趣的未知變數(例如類別標記)進行估計和推測。概率模型提供了一種描述框架,將學習任務歸結為計算變數的概率分佈。概率圖模型(probabilistic graphical model,簡稱PGM)是一類用圖來表達變數相關關係的概率模型
周志華《Machine Learning》學習筆記(16)--概率圖模型
轉自:http://blog.csdn.net/u011826404/article/details/75090562 上篇主要介紹了半監督學習,首先從如何利用未標記樣本所蘊含的分佈資訊出發,引入了半監督學習的基本概念,即訓練資料同時包含有標記樣本和未標記樣本的學習方法
學習筆記:結構化概率模型
"結構化概率模型"(structured probabilistic model),是一類用圖形模式表達基於概率相關關係的模型的總稱,也稱“圖模型”(graphical model)英文簡稱,PGM 概率圖模型具有圖論和概率論兩大理論基礎,是生成模型的基礎。因此它可以
機器學習理論與實戰(十六)概率圖模型04
04、概率圖模型應用例項 最近一篇文章《Deformable Model Fitting by Regularized Landmark Mean-Shift》中的人臉點檢測演算法在速度和精度折中上達到了一個相對不錯的水平,這篇技術報告就來闡
機器學習(周志華) 參考答案 第十四章 概率圖模型
機器學習(周志華西瓜書) 參考答案 總目錄 1.試用盤式記法表示條件隨機場和樸素貝葉斯分類器。 條件隨機場: 這樣畫的問題在於無法表示N個y之間的關係,到底怎麼畫我也不知道。 樸素貝葉斯分類器:y依賴於所有的變數x 2.證明
深度學習--概率圖模型(一)
這份資料看了好幾遍了,終於有點知識框架了,總結一下,方便以後檢視。 一、概率圖模型(PGM)引入: 在實際應用中,變數之間往往存在很多的獨立性假設或近似獨立,隨機變數與隨機變數之間存在極少數的關聯。PGM根據變數之間的獨立性假設,為我們提供瞭解決這類問題的機制,PGM
機器學習 —— 概率圖模型(馬爾科夫與條件隨機場)
種類 方向 方法 所有 href 個人 tro 傳遞 很好 機器學習 —— 概率圖模型(馬爾科夫與條件隨機場) 再一次遇到了Markov模型與條件隨機場的問題,學而時習之,又有了新的體會。所以我決定從頭開始再重新整理一次馬爾科夫模型與條件隨機場。 馬
機器學習.周志華《14 概率圖模型 》
目錄思維導圖轉載自:https://blog.csdn.net/liuyan20062010/article/details/72842007匯入:機器學習的核心價值觀:根據一些已觀察到的證據來推斷未知。其中基於概率的模型將學習任務歸結為計算變數的概率分佈;生成式模型:先對聯
機器學習理論與實戰(十三)概率圖模型01
01 簡單介紹 概率圖模型是圖論和概率論結合的產物,它的開創者是鼎鼎大名的Judea Pearl,我十分喜歡概率圖模型這個工具,它是一個很有力的多變數而且變數關係視覺化的建模工具,主要包括兩個大方向:無向圖模型和有向圖模型。無向圖模型又稱
隱馬爾科夫模型學習筆記
種類 算法比較 計算 oid 分類 html 解碼 ask 參數估計 隱馬爾科夫模型在股票量化交易中有應用,最早我們找比特幣交易模型了解到了這個概念,今天又看了一下《統計學習方法》裏的隱馬爾科夫模型一章。 隱馬爾科夫模型從馬爾科夫鏈的概念而來,馬爾科夫鏈是指下一個狀態只和當
Linux學習筆記:OSI七層模型
路由器 交換機 比特流 兼容性 linux OSI七層模型: OSI(Open System Interconnection,開放系統互連)七層網絡模型稱為開放式系統互聯參考模型 ,是一個邏輯上的定義,一個規範,它把網絡從邏輯上分為了7層。每一層都有相關、相對應的物理設備,比如路由器