
機器學習.周志華《14 概率圖模型 》
目錄

思維導圖轉載自:https://blog.csdn.net/liuyan20062010/article/details/72842007
匯入:
機器學習的核心價值觀:根據一些已觀察到的證據來推斷未知。其中基於概率的模型將學習任務歸結為計算變數的概率分佈;
生成式模型:先對聯合分佈P(Y,R,O)進行建模,從而再來求解後驗概率,例如:貝葉斯分類器先對聯合分佈進行最大似然估計,從而便可以計算類條件概率;
判別式模型:直接對條件分佈P(Y,R|O)進行建模。
推斷:利用已知變數推測未知變數;即由聯合分佈P(Y,R,O)或條件分佈P(Y,R|O)推出條件概率分佈P(Y,O)
概率圖模型(probabilisticgraphical model)是一類用圖
根據邊的性質不同,概率圖模型大致可分為兩類:
1)使用有向無環圖表示變數間的依賴關係,稱為有向圖模型或貝葉斯網(Bayesian network);
2)使用無向圖表示變數間的相關關係,稱為無向圖模型或馬爾可夫網(Markov network);
這裡上一個概率圖模型的思維導圖:

隱馬爾科夫模型
隱馬爾可夫模型(Hidden Markov Model,HMM)是結構最簡單的動態貝葉斯網(dynamic Bayesian network),是著名的有向圖模型,主要用於時序資料建模,在語音識別、自然語言處理等領域有廣泛應用。
1)HMM結構資訊
HMM的變數可分為兩組:
- 第一組是狀態變數{y1,y2,…,yn},其中yi∈Y表示第i時刻的系統狀態,通常假定狀態變數是隱藏的、不可觀測的,因此狀態變數也叫隱變數(hidden variable);
- 第二組是觀測變數{x1,x2,…,xn},其中xi∈X表示第i時刻的觀測值。
在HMM中,系統通常在多個狀態{ s1,s2,…,sN }之間轉換,因此狀態變數yi的取值範圍Y(狀態空間)通常是有N個可能取值的離散空間。觀測變數xi可以是離散型也可以使連續型,這裡僅考慮離散型觀測變數,並假定其取值範圍X為{ o1,o2,…,oM}。
HMM圖結構如下:

圖中箭頭表示了變數間的依賴關係。在任一時刻,觀測變數的取值僅依賴於狀態變數,即x

確定隱馬爾科夫模型
- 狀態變數Y
- 觀測變數X
- 狀態轉移概率A

- 輸出觀測概率B

- 初始狀態概率π


產生觀測序列過程:

實際應用中關注的三個問題:


馬爾科夫隨機場
馬爾科夫隨機場是典型的馬爾科夫網,無向圖模型:

勢函式(因子):
定義在變數子集上的非負實函式,主要用於定義概率分佈函式或者說用定量刻畫變臉記Xq中半年之間的相關關係;且在所騙號的變數取值上有較大的函式值;

團:
圖中結點的一個子集中,若其中任意兩結點都有邊連線,則該結點子集為一個“團;”
極大團:
若在一個團中加入另外任何一個節點都不再構成團,該團為“極大團”;
聯合概率(基於團定義):

聯合概率(基於極大團定義)

注:
若團Q不是極大團,則必被一個極大團Q*所包含;
分離集:





條件隨機場CRF
定義:
若G=<V,E>表示結點與標記變數y中元素一一對應的無向圖,yv表示與結點v的標記變數,n(v)表示結點v的鄰接結點,若圖G的每個變數yv都滿足馬爾可夫性,則(y,x)構成一個條件隨機場。
馬爾可夫性:

鏈式條件隨機場chain-structured CRF:

條件概率

轉移特徵函式:刻畫相鄰標記變數之間的相關關係以及觀測序列對他們的影響;
- 主要判定兩個相鄰的標註是否合理,例如:動詞+動詞顯然語法不通;
狀態特徵函式:刻畫觀測序列對標記變數的影響;
- 主要判定觀測值與對應的標註是否合理,例如: ly結尾的詞–>副詞較合理。
學習與推斷
邊際化:
概率圖模型的推斷方法大致分為兩類:
- 精確推斷方法:變數消去、信念傳播;
- 近似推斷方法:MCMC取樣、變分推斷;
精確推斷
精確推斷的實質是一種動態規劃演算法,他利用圖模型所描述的條件獨立性來削減計算目標概率值所需的計算量。
變數消去

(1)有向圖模型:

(2)對無向圖同樣適用!

缺點:
- 若需要計算多個邊際分佈,重複使用變數消去會造成大量的冗餘計算。
信念傳播
解決求解多個邊際分佈的重複計算問題:將變數消去法中的求和操作看做一個訊息傳遞的過程;

信念傳播演算法步驟:

信念傳播演算法圖示:

近似推斷
兩大類方法:
- 取樣:採用隨機化方法完成近似;
- 確定性近似:典型代表變分推斷;
取樣
可以參考的部落格:https://www.cnblogs.com/ironstark/p/5229085.html
典型代表:馬爾科夫鏈蒙特卡羅MCMC
目的:通過構造‘平穩分佈為p的馬爾科夫鏈’來產生樣本;
平穩分佈:假設平穩馬爾科夫鏈T的狀態轉移概率為T(x'|x),t時刻狀態的分佈為P(x^t),則若在某個時刻馬爾科夫鏈滿足平穩條件:

則p(x)是該馬爾科夫鏈的平穩分佈
步驟:
- 構造馬爾科夫鏈;
- 逼近(收斂)至平穩分佈恰為帶估計引數的後驗分佈;
- 用馬爾科夫鏈產生符合該後驗分佈的樣本,並基於這些樣本進行估計
重點:馬爾科夫鏈轉移概率的構造
MH(MCMC代表):基於“拒絕取樣”來逼近平穩分佈p;

MC演算法特例:吉布斯取樣

變分推斷
附變分推斷的知乎討論:https://www.zhihu.com/question/41765860
目標:通過使用已知簡單分佈來逼近需推斷的複雜分佈,並通過限制及時釋出的型別,從而得到一種區域性最優、但具有確定街的近似後驗分佈。
盤式記憶:

(b)中所能觀測到的變數x的聯合分佈的概率密度函式:

對應的對數似然函式:

推斷和學習的任務:
由觀察到的變數x來估計隱變數z和分佈引數變數Θ,即求解P(z|x,Θ)
解決方法:
EM演算法
總結:
1、如何拆解隱變數;
2、假設各變數子集服從的分佈;
3、服從的最優分佈;
4、EM演算法;
話題模型
生產式有向圖模型,主要處理離散型資料(如文字集合)。
隱狄利克雷分配模型(Latent Dirichlet Allocation,簡稱LDA)
基本概念:詞(word)、文件(document)、話題(topic)。
詞:最基本的離散單元;
文件:待處理的資料物件,由一組片語成,詞在文件中不計順序;(詞袋bag-of-words)
話題:表示一個概念,具體表現為一系列相關的詞,以及它們該概念下出現的概率。這組詞具有較強的相關關係。
在現實任務中,一般我們可以得出一個文件的詞頻分佈,但不知道該文件對應著哪些話題,LDA話題模型正是為了解決這個問題。
具體來說:LDA認為每篇文件包含多個話題,且其中每一個詞都對應著一個話題。因此可以假設文件是通過如下方式生成:

這樣一個文件中的所有詞都可以認為是通過話題模型來生成的,當已知一個文件的詞頻分佈後(即一個N維向量,N為詞庫大小),則可以認為:每一個詞頻元素都對應著一個話題,而話題對應的詞頻分佈則影響著該詞頻元素的大小。
LDA變數關係:

因此很容易寫出LDA模型對應的聯合概率函式:

補充:
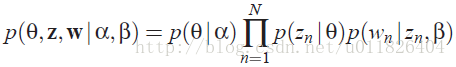

從上圖可以看出,LDA的三個表示層被三種顏色表示出來:
corpus-level(紅色): α和β表示語料級別的引數,也就是每個文件都一樣,因此生成過程只採樣一次。
document-level(橙色): θ是文件級別的變數,每個文件對應一個θ。
word-level(綠色): z和w都是單詞級別變數,z由θ生成,w由z和β共同生成,一個單詞w對應一個主題z。
通過上面對LDA生成模型的討論,可以知道LDA模型主要是想從給定的輸入語料中學習訓練出兩個控制引數α和β,當學習出了這兩個控制引數就確定了模型,便可以用來生成文件。其中α和β分別對應以下各個資訊:
α:分佈p(θ)需要一個向量引數,即Dirichlet分佈的引數,用於生成一個主題θ向量;
β:各個主題對應的單詞概率分佈矩陣p(w|z)。
把w當做觀察變數,θ和z當做隱藏變數,就可以通過EM演算法學習出α和β,求解過程中遇到後驗概率p(θ,z|w)無法直接求解,需要找一個似然函式下界來近似求解,原作者使用基於分解(factorization)假設的變分法(varialtional inference)進行計算,用到了EM演算法。每次E-step輸入α和β,計算似然函式,M-step最大化這個似然函式,算出α和β,不斷迭代直到收斂。