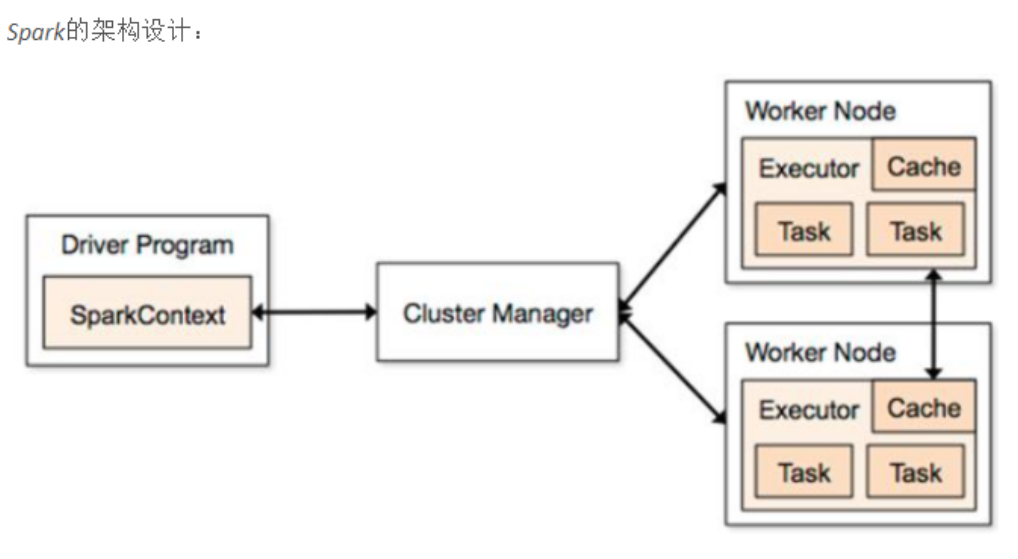
spark原理和spark與mapreduce的最大區別
阿新 • • 發佈:2018-11-29
參考文件:https://files.cnblogs.com/files/han-guang-xue/spark1.pdf
參考網址:https://www.cnblogs.com/wangrd/p/6232826.html
對於spark個人理解:
spark與mapreduce最大不同之處:spark是可以將某個特定的且反覆使用的資料集的迭代演算法高效執行,mapreduce處理資料需要與其他節點的或是框架保持高度並行,無法實現這樣的效果
摘自:sanqima
Spark中最核心的概念是RDD(彈性分散式資料集),近年來,隨著資料量的不斷增長,分散式叢集平行計算(如MapReduce、Dryad等)被廣泛運用於處理日益增長的資料。這些設計優秀的計算模型大都具有容錯性好、可擴充套件性強、負載平衡、程式設計方法簡單等優點,從而使得它們受到眾多企業的青睞,被大多數使用者用來進行大規模資料的處理。
但是,MapReduce這些平行計算大都是基於非迴圈的資料流模型,也就是說,一次資料過程包含從共享檔案系統讀取資料、進行計算、完成計算、寫入計算結果到共享儲存中,在計算過程中,不同計算節點之間保持高度並行
Spark和Spark使用的RDD就是為了解決這種問題而開發出來的,Spark使用了一種特殊設計的資料結構,稱為RDD。RDD的一個重要特徵是,分散式資料集可以在不同的並行環境當中被重複使用,這個特性將Spark和其他並行資料流模型框架(如MapReduce)區別開。
具體實現: