
Java集合框架之三:HashMap原始碼解析 Java集合框架之三:HashMap原始碼解析
Java集合框架之三:HashMap原始碼解析
版權宣告:本文為博主原創文章,轉載請註明出處,歡迎交流學習!
HashMap在我們的工作中應用的非常廣泛,在工作面試中也經常會被問到,對於這樣一個重要的集合模型我們有必要弄清楚它的使用方法和它底層的實現原理。HashMap是通過key-value鍵值對的方式來儲存資料的,通過put、get方法實現鍵值對的快速存取,這是HashMap最基本的用法。HashMap底層是通過陣列和連結串列相結合的混合結構來存放資料的。我們通過分析底層原始碼來詳細瞭解一下HashMap的實現原理。
1、HashMap的初始化
在HashMap例項化時我們要了解兩個概念:初始容量和載入因子。HashMap是基於雜湊表的Map介面實現,初始容量是雜湊表在建立時的容量。載入因子是雜湊表在其容量自動增加之前可以達到多滿的一種尺度。當雜湊表中的條目數超過了載入因子與當前容量的乘積時,則要對該雜湊表進行rehash操作(即重建內部資料結構),從而雜湊表將具有大約兩倍於當前容量的新的容量。

以上是Java API中HashMap的構造方法,其原始碼如下:

1 static final int DEFAULT_INITIAL_CAPACITY = 16;//預設初始容量16
2 static final int MAXIMUM_CAPACITY = 1 << 30;//定義最大容量
3 static final float DEFAULT_LOAD_FACTOR = 0.75f;//預設負載因子0.75
4 transient Entry[] table;
5 int threshold; //臨界值,值為容量與載入因子的乘積
6 final float loadFactor; //載入因子
7
8 public HashMap() {
9 this.loadFactor = DEFAULT_LOAD_FACTOR;
10 threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
11 table = new Entry[DEFAULT_INITIAL_CAPACITY];
12 init();
13 }
14
15 void init() {
16 }
以上構造方法定義了一個空的HashMap,其預設初始容量為16,預設初始載入因子為0.75,同時聲明瞭一個Entry型別的陣列,陣列初始長度為16。那麼這裡出現的Entry物件是如何定義的呢?看一下它的實現程式碼:
1 static class Entry<K,V> implements Map.Entry<K,V> {
2 final K key;
3 V value;
4 Entry<K,V> next; //指向下一個Entry節點
5 final int hash; //雜湊值
6
7 /**
8 * Creates new entry.
9 */
10 Entry(int h, K k, V v, Entry<K,V> n) {
11 value = v;
12 next = n;
13 key = k;
14 hash = h;
15 }
16
17 public final K getKey() {
18 return key;
19 }
20
21 public final V getValue() {
22 return value;
23 }
24
25 public final V setValue(V newValue) {
26 V oldValue = value;
27 value = newValue;
28 return oldValue;
29 }
30 //重寫equals方法,判斷兩個Entry是否相等,如果兩個Entry物件的key和value相等,則返回true,否則返回false
31 public final boolean equals(Object o) {
32 if (!(o instanceof Map.Entry))
33 return false;
34 Map.Entry e = (Map.Entry)o;
35 Object k1 = getKey();
36 Object k2 = e.getKey();
37 if (k1 == k2 || (k1 != null && k1.equals(k2))) {
38 Object v1 = getValue();
39 Object v2 = e.getValue();
40 if (v1 == v2 || (v1 != null && v1.equals(v2)))
41 return true;
42 }
43 return false;
44 }
45 //重寫hashCode方法,返回key的hashCode值與value的hashCode值異或運算所得的值
46 public final int hashCode() {
47 return (key==null ? 0 : key.hashCode()) ^
48 (value==null ? 0 : value.hashCode());
49 }
50 //重寫toString方法,返回此Entry物件的“key=value”對映關係
51 public final String toString() {
52 return getKey() + "=" + getValue();
53 }
54
55 /**
56 * This method is invoked whenever the value in an entry is
57 * overwritten by an invocation of put(k,v) for a key k that's already
58 * in the HashMap.
59 */
60 void recordAccess(HashMap<K,V> m) { //當向HashMap中新增鍵值對時,會呼叫此方法,這裡方法體為空,即不做處理
61 }
62
63 /**
64 * This method is invoked whenever the entry is
65 * removed from the table.
66 */
67 void recordRemoval(HashMap<K,V> m) { //當向HashMap中刪除鍵值對對映關係時,會呼叫此方法,這裡方法體為空,即不做處理
68 }
69 }
Entry類是HashMap的內部類,其實現了Map.Entry介面。Entry類裡定義了4個屬性:Object型別的key、value(K、V型別可以看成Object型別),Entry型別的next屬性(這個next其實就是一個指向下一個Entry物件的引用,形成了一個連結串列,通過此Entry物件的next屬性可以找到其下一個Entry物件)和int型的hash值。HashMap底層維護的就是一個個Entry物件。在Entry類裡還重寫了equals方法,若兩個Entry的key和value都相等,則返回true,否則返回false,同時還重寫了hashCode方法。
2、HashMap的底層資料結構
前面提到過HashMap的底層是基於陣列和連結串列來實現的,那麼如何決定一個Entry物件是存放在陣列中的哪個位置的呢?它是通過計算hash值來決定儲存位置的,同時在查詢元素的時候同樣也是計算出一個值來找到對應的位置,因此它具有相當快的查詢速度。HashMap是根據key的hashCode值來計算hash值的,相同的hashCode值計算出來的hash值也是相同的。當儲存的物件達到了一定數量,就有可能出現不同物件的key的hashCode值是相同的,因此計算出來的hash值也相同,這樣就出現了衝突。雜湊衝突的解決方法有很多,比如再雜湊法,這種方法是同時構造多個不同的雜湊函式,當發生衝突時就換另外的函式重新計算hash值,直到不再產生衝突為止。HashMap是通過單鏈表來解決雜湊衝突的,這種方法也被稱為拉鍊法。如圖所示:
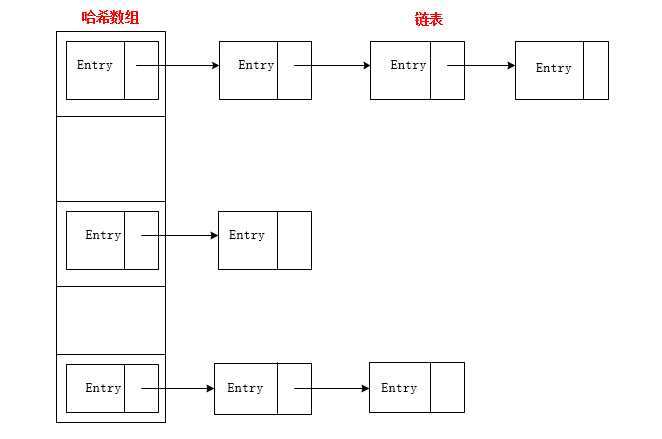
在上圖中,左邊的部分是雜湊表(也稱為雜湊陣列),右邊是一個單鏈表,單鏈表是用來解決雜湊衝突的,數組裡的每一個元素都是一個單鏈表的頭節點,當不同的key計算出的陣列中的存放位置相同時,就將此物件新增到單鏈表中。
3、資料儲存
在HashMap中定義了put方法來向集合中新增資料,資料以鍵值對的形式儲存,put方法的實現如下:
1 public V put(K key, V value) {
2 //如果存入HashMap的key為null,則將該鍵值對新增到table[0]中
3 if (key == null)
4 return putForNullKey(value);
5 //key不為null,呼叫hash方法計算key的hashCode值對應的hash值
6 int hash = hash(key.hashCode());
7 //根據計算出的hash值,結合陣列的長度計算出陣列中的插入位置i
8 int i = indexFor(hash, table.length);
9 //遍歷陣列下標為i處的連結串列,如果連結串列上存在元素,其hash值與上述計算得到的hash值相等,
10 //並且其key值與新增的鍵值對的key值相等,那麼就以新增鍵值對的value替換此元素的value值,
11 //並返回此元素原來的value
12 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
13 Object k;
14 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
15 V oldValue = e.value;
16 e.value = value;
17 e.recordAccess(this);
18 return oldValue;
19 }
20 }
21
22 modCount++; //操作次數加1
23 //如果連結串列上不存在滿足條件的元素,則將鍵值對對應生成的Entry物件新增到table[i]處,
24 //並將下標為i處原先的Entry物件連結到新的Entry物件後面
25 addEntry(hash, key, value, i);
26 return null;
27 }
28
29
30
31 private V putForNullKey(V value) {
32 //遍歷陣列下標為0處的連結串列,如果連結串列中存在元素其key為null,則用value覆蓋此元素原來的value
33 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
34 if (e.key == null) {
35 V oldValue = e.value;
36 e.value = value;
37 e.recordAccess(this);
38 return oldValue;
39 }
40 }
41 modCount++; //運算元加1
42 //如果連結串列中不存在滿足條件的元素,則將此鍵值對生成的Entry物件存放到table[0]
43 addEntry(0, null, value, 0);//key為null,計算出的hash值為0
44 return null;
45 }
46
47
48 //計算hash值
49 static int hash(int h) {
50 // This function ensures that hashCodes that differ only by
51 // constant multiples at each bit position have a bounded
52 // number of collisions (approximately 8 at default load factor).
53 h ^= (h >>> 20) ^ (h >>> 12);
54 return h ^ (h >>> 7) ^ (h >>> 4);
55 }
56
57
58
59 //根據hash值和陣列長度,計算出在陣列中的索引位置
60 static int indexFor(int h, int length) {
61 return h & (length-1); //計算出的值不會超出陣列的長度
62 }
63
64
65
66 void addEntry(int hash, K key, V value, int bucketIndex) {
67 //獲取table[bucketIndex]處的Entry物件
68 Entry<K,V> e = table[bucketIndex];
69 //根據key-value生成新的Entry物件,並將新的Entry物件存入table[bucketIndex]處,將其next引用指向原來的物件
70 table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
71 //如果陣列容量大於或等於臨界值,則進行擴容
72 if (size++ >= threshold)
73 resize(2 * table.length); //容量為原來的2倍
74 }
以上就是put方法的實現原理,我給出了詳細的程式碼註釋。上面已經講到過HashMap底層的資料結構是由陣列和單向連結串列構成的,當我們向HashMap中put一對key-value鍵值對時,首先判斷key是否為null,如果為null,則遍歷table[0]處的連結串列,若此連結串列上存在key為null的元素,則用value覆蓋此元素的value值,如果不存在這樣的元素,那麼將此鍵值對生成的Entry物件存放到table[0]中;如果key不為null,首先根據key的hashCode值計算出hash值,根據hash值和陣列長度計算出要存放到陣列中的位置i,然後遍歷table[i]處的連結串列,如果連結串列上存在元素其hash值與計算得到的hash值相等並且其key值與新增的key相等,那麼就以新增的value覆蓋此元素原來的value並返回原來的value值;如果連結串列上不存在滿足上面條件的元素,則將key-value生成的Entry物件存放到table[i]處,並將其next指向此處原來的Entry物件。這樣經過多次put操作,就構成了陣列加連結串列的儲存結構。
4、資料讀取
HashMap的get方法可以根據key返回其對應的value,如果key為null,則返回null。
1 public V get(Object key) {
2 //如果key為null,則迴圈table[0]處的單鏈表
3 if (key == null)
4 return getForNullKey();
5 //key不為null,根據key的hashCode計算出一個hash值
6 int hash = hash(key.hashCode());
7 //根據hash值和陣列長度計算出一個數組下標值,並且遍歷此下標處的單鏈表
8 for (Entry<K,V> e = table[indexFor(hash, table.length)];
9 e != null;
10 e = e.next) {
11 Object k;
12 //如果Entry物件的hash值跟上面計算得到的hash值相等,並且key也相等,那麼就返回此Entry物件value
13 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
14 return e.value;
15 }
16 //如果單鏈表上不存在滿足上述條件的Entry物件,則表明HashMap不包含該key的對映關係,返回null
17 return null;
18 }
19
20
21
22 private V getForNullKey() {
23 //獲取table[0]處的Entry物件,並迴圈其連結的單鏈表,如果單鏈表上存在不為null的物件,
24 //並且其key為null,那麼就返回此物件的value
25 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
26 if (e.key == null)
27 return e.value;
28 }
29 //如果單鏈表上不存在滿足條件的物件,則返回null
30 return null;
31 }
瞭解了put方法的原理,我們就不難理解get的實現原理了,與之類似也是要根據key的hashCode值來計算出一個hash值,然後根據hash值和陣列長度計算出一個數組下標值,接著迴圈遍歷此下標處的單鏈表,尋找滿足條件的Entry物件並返回value,此value就是HashMap中該key所對映的value。注意分析當key為null時的情況:如果HashMap中有key為null的對映關係,那麼就返回null對映的value,否則就表明HashMap中不存在key為null的對映關係,返回null。同理,當get方法返回的值為null時,並不一定表明該對映不包含該鍵的對映關係,也可能是該對映將該鍵顯示的對映為null,即put(key, null)。可使用containKey方法來區分這兩種情況。
5、移除對映關係
remove方法根據指定的key從HashMap對映中移除相應的對映關係(如果存在),此方法返回一個value。
1 public V remove(Object key) {
2 Entry<K,V> e = removeEntryForKey(key);
3 return (e == null ? null : e.value);
4 }
5
6
7
8 final Entry<K,V> removeEntryForKey(Object key) {
9 //根據key的hashCode計算hash值
10 int hash = (key == null) ? 0 : hash(key.hashCode());
11 //根據hash值和陣列長度計算陣列下標值i
12 int i = indexFor(hash, table.length);
13 //獲取下標為i處的陣列元素
14 Entry<K,V> prev = table[i];
15 Entry<K,V> e = prev;
16 //遍歷陣列下標為i處的單鏈表
17 while (e != null) {
18 Entry<K,V> next = e.next;
19 Object k;
20 //如果此單鏈表上存在Entry物件e,其hash值與計算出的hash值相等並且其key也跟傳入的key"相等",則從單鏈表上移除e
21 if (e.hash == hash &&
22 ((k = e.key) == key || (key != null && key.equals(k)))) {
23 modCount++;
24 size--; //map中的對映數減1
25 //判斷滿足條件的Entry物件是在陣列下標i處還是在陣列外面的單鏈表上
26 if (prev == e)
27 table[i] = next;
28 else
29 prev.next = next;
30 e.recordRemoval(this);
31 return e;
32 }
33 prev = e;
34 e = next;
35 }
36
37 return e;
38 }
從上面的原始碼可以看出,remove方法的原理是先找出滿足條件的Entry物件,然後從單鏈表上刪除該物件,並返回該物件中的value,本質上是對單鏈表的操作。
6、總結
從以上原始碼的分析中我們知道了HashMap底層維護的是陣列加連結串列的混合結構,這是HashMap的核心,只要掌握了這一點我們就能很容易弄清楚HashMap中對映關係的各種操作原理,其本質是對陣列和連結串列的操作。要注意的是HashMap不是執行緒安全的,我們可以使用Collections.synchoronizedMap方法來獲得執行緒安全的HashMap。例如:
Map map = Collections.sychronizedMap(new HashMap());
版權宣告:本文為博主原創文章,轉載請註明出處,歡迎交流學習!
HashMap在我們的工作中應用的非常廣泛,在工作面試中也經常會被問到,對於這樣一個重要的集合模型我們有必要弄清楚它的使用方法和它底層的實現原理。HashMap是通過key-value鍵值對的方式來儲存資料的,通過put、get方法實現鍵值對的快速存取,這是HashMap最基本的用法。HashMap底層是通過陣列和連結串列相結合的混合結構來存放資料的。我們通過分析底層原始碼來詳細瞭解一下HashMap的實現原理。
1、HashMap的初始化
在HashMap例項化時我們要了解兩個概念:初始容量和載入因子。HashMap是基於雜湊表的Map介面實現,初始容量是雜湊表在建立時的容量。載入因子是雜湊表在其容量自動增加之前可以達到多滿的一種尺度。當雜湊表中的條目數超過了載入因子與當前容量的乘積時,則要對該雜湊表進行rehash操作(即重建內部資料結構),從而雜湊表將具有大約兩倍於當前容量的新的容量。
以上是Java API中HashMap的構造方法,其原始碼如下:
1 static final int DEFAULT_INITIAL_CAPACITY = 16;//預設初始容量16
2 static final int MAXIMUM_CAPACITY = 1 << 30;//定義最大容量
3 static final float DEFAULT_LOAD_FACTOR = 0.75f;//預設負載因子0.75
4 transient Entry[] table;
5 int threshold; //臨界值,值為容量與載入因子的乘積
6 final float loadFactor; //載入因子
7
8 public HashMap() {
9 this.loadFactor = DEFAULT_LOAD_FACTOR;
10 threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
11 table = new Entry[DEFAULT_INITIAL_CAPACITY];
12 init();
13 }
14
15 void init() {
16 }
以上構造方法定義了一個空的HashMap,其預設初始容量為16,預設初始載入因子為0.75,同時聲明瞭一個Entry型別的陣列,陣列初始長度為16。那麼這裡出現的Entry物件是如何定義的呢?看一下它的實現程式碼:
1 static class Entry<K,V> implements Map.Entry<K,V> {
2 final K key;
3 V value;
4 Entry<K,V> next; //指向下一個Entry節點
5 final int hash; //雜湊值
6
7 /**
8 * Creates new entry.
9 */
10 Entry(int h, K k, V v, Entry<K,V> n) {
11 value = v;
12 next = n;
13 key = k;
14 hash = h;
15 }
16
17 public final K getKey() {
18 return key;
19 }
20
21 public final V getValue() {
22 return value;
23 }
24
25 public final V setValue(V newValue) {
26 V oldValue = value;
27 value = newValue;
28 return oldValue;
29 }
30 //重寫equals方法,判斷兩個Entry是否相等,如果兩個Entry物件的key和value相等,則返回true,否則返回false
31 public final boolean equals(Object o) {
32 if (!(o instanceof Map.Entry))
33 return false;
34 Map.Entry e = (Map.Entry)o;
35 Object k1 = getKey();
36 Object k2 = e.getKey();
37 if (k1 == k2 || (k1 != null && k1.equals(k2))) {
38 Object v1 = getValue();
39 Object v2 = e.getValue();
40 if (v1 == v2 || (v1 != null && v1.equals(v2)))
41 return true;
42 }
43 return false;
44 }
45 //重寫hashCode方法,返回key的hashCode值與value的hashCode值異或運算所得的值
46 public final int hashCode() {
47 return (key==null ? 0 : key.hashCode()) ^
48 (value==null ? 0 : value.hashCode());
49 }
50 //重寫toString方法,返回此Entry物件的“key=value”對映關係
51 public final String toString() {
52 return getKey() + "=" + getValue();
53 }
54
55 /**
56 * This method is invoked whenever the value in an entry is
57 * overwritten by an invocation of put(k,v) for a key k that's already
58 * in the HashMap.
59 */
60 void recordAccess(HashMap<K,V> m) { //當向HashMap中新增鍵值對時,會呼叫此方法,這裡方法體為空,即不做處理
61 }
62
63 /**
64 * This method is invoked whenever the entry is
65 * removed from the table.
66 */
67 void recordRemoval(HashMap<K,V> m) { //當向HashMap中刪除鍵值對對映關係時,會呼叫此方法,這裡方法體為空,即不做處理
68 }
69 }
Entry類是HashMap的內部類,其實現了Map.Entry介面。Entry類裡定義了4個屬性:Object型別的key、value(K、V型別可以看成Object型別),Entry型別的next屬性(這個next其實就是一個指向下一個Entry物件的引用,形成了一個連結串列,通過此Entry物件的next屬性可以找到其下一個Entry物件)和int型的hash值。HashMap底層維護的就是一個個Entry物件。在Entry類裡還重寫了equals方法,若兩個Entry的key和value都相等,則返回true,否則返回false,同時還重寫了hashCode方法。
2、HashMap的底層資料結構
前面提到過HashMap的底層是基於陣列和連結串列來實現的,那麼如何決定一個Entry物件是存放在陣列中的哪個位置的呢?它是通過計算hash值來決定儲存位置的,同時在查詢元素的時候同樣也是計算出一個值來找到對應的位置,因此它具有相當快的查詢速度。HashMap是根據key的hashCode值來計算hash值的,相同的hashCode值計算出來的hash值也是相同的。當儲存的物件達到了一定數量,就有可能出現不同物件的key的hashCode值是相同的,因此計算出來的hash值也相同,這樣就出現了衝突。雜湊衝突的解決方法有很多,比如再雜湊法,這種方法是同時構造多個不同的雜湊函式,當發生衝突時就換另外的函式重新計算hash值,直到不再產生衝突為止。HashMap是通過單鏈表來解決雜湊衝突的,這種方法也被稱為拉鍊法。如圖所示:
在上圖中,左邊的部分是雜湊表(也稱為雜湊陣列),右邊是一個單鏈表,單鏈表是用來解決雜湊衝突的,數組裡的每一個元素都是一個單鏈表的頭節點,當不同的key計算出的陣列中的存放位置相同時,就將此物件新增到單鏈表中。
3、資料儲存
在HashMap中定義了put方法來向集合中新增資料,資料以鍵值對的形式儲存,put方法的實現如下:
1 public V put(K key, V value) {
2 //如果存入HashMap的key為null,則將該鍵值對新增到table[0]中
3 if (key == null)
4 return putForNullKey(value);
5 //key不為null,呼叫hash方法計算key的hashCode值對應的hash值
6 int hash = hash(key.hashCode());
7 //根據計算出的hash值,結合陣列的長度計算出陣列中的插入位置i
8 int i = indexFor(hash, table.length);
9 //遍歷陣列下標為i處的連結串列,如果連結串列上存在元素,其hash值與上述計算得到的hash值相等,
10 //並且其key值與新增的鍵值對的key值相等,那麼就以新增鍵值對的value替換此元素的value值,
11 //並返回此元素原來的value
12 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
13 Object k;
14 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
15 V oldValue = e.value;
16 e.value = value;
17 e.recordAccess(this);
18 return oldValue;
19 }
20 }
21
22 modCount++; //操作次數加1
23 //如果連結串列上不存在滿足條件的元素,則將鍵值對對應生成的Entry物件新增到table[i]處,
24 //並將下標為i處原先的Entry物件連結到新的Entry物件後面
25 addEntry(hash, key, value, i);
26 return null;
27 }
28
29
30
31 private V putForNullKey(V value) {
32 //遍歷陣列下標為0處的連結串列,如果連結串列中存在元素其key為null,則用value覆蓋此元素原來的value
33 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
34 if (e.key == null) {
35 V oldValue = e.value;
36 e.value = value;
37 e.recordAccess(this);
38 return oldValue;
39 }
40 }
41 modCount++; //運算元加1
42 //如果連結串列中不存在滿足條件的元素,則將此鍵值對生成的Entry物件存放到table[0]
43 addEntry(0, null, value, 0);//key為null,計算出的hash值為0
44 return null;
45 }
46
47
48 //計算hash值
49 static int hash(int h) {
50 // This function ensures that hashCodes that differ only by
51 // constant multiples at each bit position have a bounded
52 // number of collisions (approximately 8 at default load factor).
53 h ^= (h >>> 20) ^ (h >>> 12);
54 return h ^ (h >>> 7) ^ (h >>> 4);
55 }
56
57
58
59 //根據hash值和陣列長度,計算出在陣列中的索引位置
60 static int indexFor(int h, int length) {
61 return h & (length-1); //計算出的值不會超出陣列的長度
62 }
63
64
65
66 void addEntry(int hash, K key, V value, int bucketIndex) {
67 //獲取table[bucketIndex]處的Entry物件
68 Entry<K,V> e = table[bucketIndex];
69 //根據key-value生成新的Entry物件,並將新的Entry物件存入table[bucketIndex]處,將其next引用指向原來的物件
70 table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
71 //如果陣列容量大於或等於臨界值,則進行擴容
72 if (size++ >= threshold)
73 resize(2 * table.length); //容量為原來的2倍
74 }
以上就是put方法的實現原理,我給出了詳細的程式碼註釋。上面已經講到過HashMap底層的資料結構是由陣列和單向連結串列構成的,當我們向HashMap中put一對key-value鍵值對時,首先判斷key是否為null,如果為null,則遍歷table[0]處的連結串列,若此連結串列上存在key為null的元素,則用value覆蓋此元素的value值,如果不存在這樣的元素,那麼將此鍵值對生成的Entry物件存放到table[0]中;如果key不為null,首先根據key的hashCode值計算出hash值,根據hash值和陣列長度計算出要存放到陣列中的位置i,然後遍歷table[i]處的連結串列,如果連結串列上存在元素其hash值與計算得到的hash值相等並且其key值與新增的key相等,那麼就以新增的value覆蓋此元素原來的value並返回原來的value值;如果連結串列上不存在滿足上面條件的元素,則將key-value生成的Entry物件存放到table[i]處,並將其next指向此處原來的Entry物件。這樣經過多次put操作,就構成了陣列加連結串列的儲存結構。
4、資料讀取
HashMap的get方法可以根據key返回其對應的value,如果key為null,則返回null。
1 public V get(Object key) {
2 //如果key為null,則迴圈table[0]處的單鏈表
3 if (key == null)
4 return getForNullKey();
5 //key不為null,根據key的hashCode計算出一個hash值
6 int hash = hash(key.hashCode());
7 //根據hash值和陣列長度計算出一個數組下標值,並且遍歷此下標處的單鏈表
8 for (Entry<K,V> e = table[indexFor(hash, table.length)];
9 e != null;
10 e = e.next) {
11 Object k;
12 //如果Entry物件的hash值跟上面計算得到的hash值相等,並且key也相等,那麼就返回此Entry物件value
13 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
14 return e.value;
15 }
16 //如果單鏈表上不存在滿足上述條件的Entry物件,則表明HashMap不包含該key的對映關係,返回null
17 return null;
18 }
19
20
21
22 private V getForNullKey() {
23 //獲取table[0]處的Entry物件,並迴圈其連結的單鏈表,如果單鏈表上存在不為null的物件,
24 //並且其key為null,那麼就返回此物件的value
25 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
26 if (e.key == null)
27 return e.value;
28 }
29 //如果單鏈表上不存在滿足條件的物件,則返回null
30 return null;
31 }
瞭解了put方法的原理,我們就不難理解get的實現原理了,與之類似也是要根據key的hashCode值來計算出一個hash值,然後根據hash值和陣列長度計算出一個數組下標值,接著迴圈遍歷此下標處的單鏈表,尋找滿足條件的Entry物件並返回value,此value就是HashMap中該key所對映的value。注意分析當key為null時的情況:如果HashMap中有key為null的對映關係,那麼就返回null對映的value,否則就表明HashMap中不存在key為null的對映關係,返回null。同理,當get方法返回的值為null時,並不一定表明該對映不包含該鍵的對映關係,也可能是該對映將該鍵顯示的對映為null,即put(key, null)。可使用containKey方法來區分這兩種情況。
5、移除對映關係
remove方法根據指定的key從HashMap對映中移除相應的對映關係(如果存在),此方法返回一個value。
1 public V remove(Object key) {
2 Entry<K,V> e = removeEntryForKey(key);
3 return (e == null ? null : e.value);
4 }
5
6
7
8 final Entry<K,V> removeEntryForKey(Object key) {
9 //根據key的hashCode計算hash值
10 int hash = (key == null) ? 0 : hash(key.hashCode());
11 //根據hash值和陣列長度計算陣列下標值i
12 int i = indexFor(hash, table.length);
13 //獲取下標為i處的陣列元素
14 Entry<K,V> prev = table[i];
15 Entry<K,V> e = prev;
16 //遍歷陣列下標為i處的單鏈表
17 while (e != null) {
18 Entry<K,V> next = e.next;
19 Object k;
20 //如果此單鏈表上存在Entry物件e,其hash值與計算出的hash值相等並且其key也跟傳入的key"相等",則從單鏈表上移除e
21 if (e.hash == hash &&
22 ((k = e.key) == key || (key != null && key.equals(k)))) {
23 modCount++;
24 size--; //map中的對映數減1
25 //判斷滿足條件的Entry物件是在陣列下標i處還是在陣列外面的單鏈表上
26 if (prev == e)
27 table[i] = next;
28 else
29 prev.next = next;
30 e.recordRemoval(this);
31 return e;
32 }
33 prev = e;
34 e = next;
35 }
36
37 return e;
38 }
從上面的原始碼可以看出,remove方法的原理是先找出滿足條件的Entry物件,然後從單鏈表上刪除該物件,並返回該物件中的value,本質上是對單鏈表的操作。
6、總結
從以上原始碼的分析中我們知道了HashMap底層維護的是陣列加連結串列的混合結構,這是HashMap的核心,只要掌握了這一點我們就能很容易弄清楚HashMap中對映關係的各種操作原理,其本質是對陣列和連結串列的操作。要注意的是HashMap不是執行緒安全的,我們可以使用Collections.synchoronizedMap方法來獲得執行緒安全的HashMap。例如:
Map map = Collections.sychronizedMap(new HashMap());