
阿里深度學習框架開源了!無縫對接TensorFlow、PyTorch
阿里巴巴內部透露將開源內部深度學習框架 X-DeepLearning的計劃,這是業界首個面向廣告、推薦、搜尋等高維稀疏資料場景的深度學習開源框架,可以與TensorFlow、PyTorch 和 MXNet 等現有框架形成互補。
X-Deep Learning(下文簡稱XDL)由阿里巴巴旗下大資料營銷平臺阿里媽媽基於自身廣告業務自主研發,已經大規模部署應用在核心生產場景,在這次的“雙11”中也發揮了重要作用。
阿里媽媽研究人員介紹,XDL整體上跟TensorFlow和PyTorch是同級的,它們很好地解決了目前已有開源深度學習框架分散式執行能力不足,以及大規模稀疏特徵表徵學習能力不足的問題。
XDL 採用了“橋接”的架構設計理念。這種架構使得 XDL 跟業界的開源社群無縫對接。例如,使用者可以非常方便地在XDL框架上應用基於TensorFlow或者PyTorch編寫的最先進開源深度學習演算法。此外,對於已經在使用其他開源框架的企業或者個人使用者,也可以在原有系統基礎上輕鬆進行擴充套件,享受XDL帶來的高維稀疏資料場景下極致的分散式能力。
資料的高維稀疏性是廣告、推薦、搜尋等網際網路眾多核心應用場景的特徵,覆蓋了大多數網際網路企業的資料應用模式。
對於難以與BAT研發能力比肩的眾多網際網路公司而言,工業級深度學習框架XDL及內建演算法方案的開源,將助力各大公司的技術升級,大大提升廣告/推薦/搜尋場景的精準性,縮短技術迭代週期。
2016年左右,阿里媽媽團隊在研發基於深度學習的廣告點選率預估演算法時發現,當時已有的TensorFlow、MXNet等開源框架,用來實驗演算法原型可以,但真正面臨網際網路尺度的規模化資料時,執行效率面臨巨大的挑戰。
“我們第一次基於TensorFlow訓練我們實際生產系統的深度點選率預估模型時,一天的資料量需要執行超過3天的時間模型才能收斂,”阿里媽媽研發人員告訴新智元:“典型的生產模型需要用到的訓練樣本往往都是歷史幾個月的資料,顯然直接使用TensorFlow是不現實的。”
隨後,阿里媽媽團隊也試圖對TensorFlow做一些簡單優化,但發現改動成本巨大。進一步剖析框架後,他們發現本質的原因是TensorFlow、MXNet、PyTorch等框架大都是面向影象、語音等領域的稠密資料設計,對廣告、推薦等場景的高維稀疏資料上的深度學習計算考慮不足
為此,阿里媽媽啟動了XDL框架的研發,希望能夠在複用已有開源框架對稠密資料的計算能力基礎上,重點打造面向工業級應用的分散式規模能力,單機能夠處理的計算則引用現有開源框架。
經過2年的研發與打磨,XDL目前已經在阿里媽媽成功部署到內部的生產系統。以阿里媽媽定向廣告為例,2017年,以 XDL 為基礎的深度學習演算法升級帶來的廣告收入提升超過百億。
“我們注意到今天業界的很多團隊還在類似的重複性工作。開源XDL,是希望把阿里巴巴的能力賦能給大家,推高全行業的整體技術水位,同時也希望能夠吸引業界的夥伴們一起來建設高維稀疏資料場景上的深度學習技術,一起成長與獲益。 ”
“在現有的版本中,我們在單節點稠密深度網路計算上採用橋接技術,複用了 TensorFlow、MxNet 的能力,也是最大程度上覆用了已有開源深度學習框架的能力。”
研究人員表示,後續 XDL 也會考慮加入ONNX。“ONNX針對稀疏計算的表徵能力目前是不完善的,我們也在考慮對ONNX的協議標準進行擴充。”
研究人員表示,他們預計12月在Github公開 XDL的原始碼和使用文件。除了核心的 X-DeepLearning 訓練框架,阿里還將開源面向高維稀疏資料場景的系統化解決方案,計劃分批次對外發布,包括面向線上實時服務的高效能深度學習預估引擎、面向全庫實時檢索的全新深度學習匹配引擎;同時還內建阿里媽媽自主研發的一系列創新演算法,涉及CTR預估模型、CVR預估模型、匹配召回模型、模型壓縮訓練演算法等等。
不管是以廣告、推薦、搜尋為代表業務的企業級使用者,還是對此感興趣的個人使用者,都可以加入到開源計劃當中。
一圖看懂阿里巴巴首次公開深度學習框架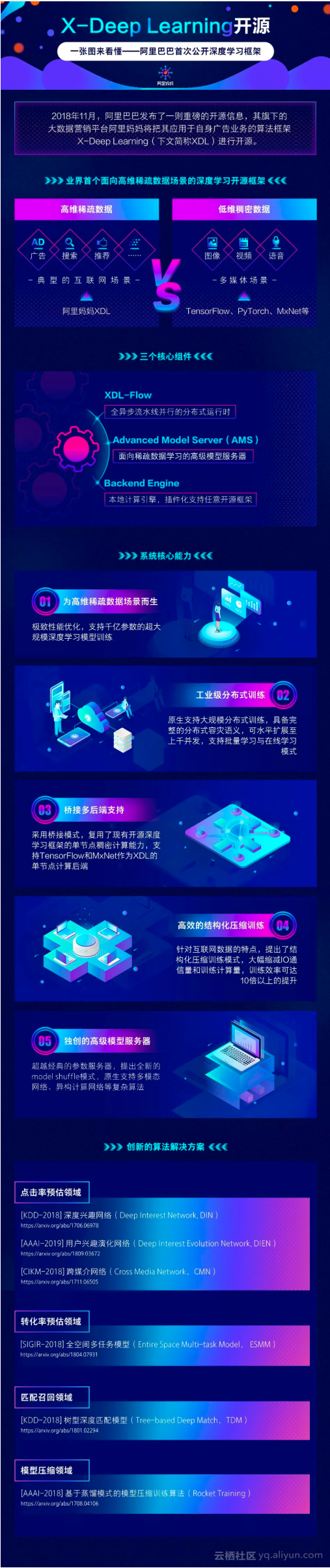 原文釋出時間為:2018-11-29
原文釋出時間為:2018-11-29
本文作者:新智元
本文來自雲棲社群合作伙伴新智元,瞭解相關資訊可以關注“AI_era”。
原文連結:阿里深度學習框架開源了!無縫對接TensorFlow、PyTorch