
機器學習常見模型評估指標
阿新 • • 發佈:2018-11-29
1.單值評估指標
在機器學習或深度學習中,為了評估最終模型的好壞,我們經常會引入各種評估指標,為了便於指標的說明,我們這裡具一個例子作為說明。假設我們想要建立一個垃圾郵件的分類模型,此時,模型預測結果的混淆矩陣如下表所示:
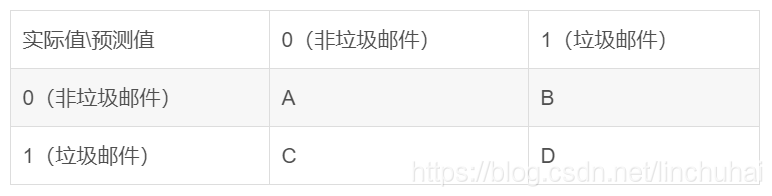
此時,我們常用的評估指標就有如下:
- 準確率:即預測樣本中,類別預測正確的比率,其計算公式為:
;
- 精確率(查準率):即預測為正例的樣本中,真正屬於正例的樣本比率(已經被預測為垃圾郵件的樣本中,實際類別是垃圾郵件的樣本比例),其計算公式為:
;
- 召回率(查全率、靈敏度):即真實情況為正例的樣本中,被預測為正例的樣本比率(實際類別是垃圾郵件的所有樣本中,被預測為垃圾郵件的比例),其計算公式為:;
- 特異度:即負例樣本中被正確分類的比例(所有的非垃圾郵件中被預測為非垃圾郵件的比例),其計算公式為:
2.組合型指標
在實際一些應用場景中,有時模型在各個類別上預測錯誤的成本是不一樣的,比如垃圾郵件分類模型中,我們習慣會認為正常郵件被預測為垃圾郵件的成本是要比垃圾郵件被預測為正常郵件的成本要高的,此時,我們一般不會直接基於某個單值指標,如準確率對模型進行評估,而是採用組合型指標,常見的組合型指標有如下:
- F1值:即精確率和召回率的調和平均,計算公式為:
;
- AUC:AUC值即為ROC曲線下方對應的面積,而ROC曲線是指這樣一條曲線,其橫座標是1-特異度,縱座標是靈敏度,當分類閾值由大到小,從將所有的樣本判定為負類到將所有樣本都判定為正類時,就可以依次獲得各個分類閾值下對應的(1-特異度,靈敏度)座標對,此時將各座標對連線起來即為對應的ROC曲線。一般來講,AUC值在0.5-1範圍比較好,低於0.5則表示模型比隨機猜測還差。
3. 優化指標與滿意度指標
在企業的應用場景中,有時我們除了考慮模型的預測準確性之外,還可能會考慮其他的因素,比如模型的執行時間、模型的引數量大小等,此時,如果直接對這些指標進行直接加和或加權,則可能會導致一個量綱不匹配的問題,因此,我們一般是將模型的準確性指標稱為優化指標(如準確率),將其他的指標稱為滿意度指標(如執行時間),然後在確保滿意度指標達到指定範圍的條件下(比如執行時間小於100ms),去最優化優化指標。