
機器學習之模型評估
'沒有測量,就沒有科學'這是科學家門捷列夫的名言。在電腦科學特別是機器學習領域中,對模型的評估同樣至關重要,只有選擇與問題相匹配的評估方法,才能快速地發現模型選擇或訓練過程中出現的問題,迭代地對模型進行優化。模型評估主要分為離線評估和線上評估兩個階段。針對分類、排序、迴歸、序列預測等不同型別的機器學習問題,評估指標的選擇也有所不同。知道每種評估指標的精確定義、有針對性地選擇合適的評估指標、更具評估指標的反饋進行模型調整,這些都是模型評估階段的關鍵問題
1. 模型評估指標
1.1 準確率
準確率是指分類正確的樣本佔總樣個數的比例:\[Accuracy = \frac{n_{correct}}{n_{total}}\]
\(n_{correct}\)為被正確分類的樣本個數,\(n_{total}\)為總樣本的個數
準確率的侷限性:準確率是分類問題中最簡單也是最直觀的評價指標,但存在明顯的缺陷,當不同總類的樣本比例非常不均衡時,佔比大的類別往往成為影響準確率的最主要因素。比如:當負樣本佔99%,分類器把所有樣本都預測為負樣本也可以得到99%的準確率,換句話說總體準確率高,並不代表類別比例小的準確率高
1.2 精確率和召回率
精確率是指正確分類的正樣本個數佔分類器判定為正樣本的樣本個數的比例
召回率是指正確分類的正樣本個數佔真正的正樣本數的比例
Precison值和Recall值是既矛盾又統一的兩個指標,為了提高Precison值,分類器需要儘量在‘更有把握’時才把樣本預測為正樣本,但此時往往會因為過於保守而漏掉很多‘沒有把握’的正樣本,導致Recall值降低
在排序問題中,通常沒有一個確定的閾值把得到的結果直接判定為正樣本或負樣本,而是採用TopN返回結果的Precision值和Recall值來衡量排序模型的效能,即認為模型返回的TopN的結果就是模型判定的正樣本,然後計算N個位置上的Precision和前N個位置上的Recall
1.3 F1分數
F1分數是精度和召回率的諧波平均值,正常的平均值平等對待所有的值,而諧波平均值回給予較低的值更高的權重,因此,只有當召回率和精度都很高時,分類器才能得到較高的F1分數
\[F_1 = \frac{1}{\frac{1}{精度}+\frac{1}{召回率}}\]
F1分數對那些具有相近的精度和召回率的分類器更為有利。但這並不一定能符合你的期望,在某些情況下,你更關心的是精度,而另一些情況下,你可能真正關心的是召回率。精確率與召回率的權衡將是很值得思考的問題。
1.4 均方誤差、根均方誤差、絕對百分比誤差
均方誤差:\[MSE =\frac{1}{n}\sum_{i=1}^n(y_{pred} - y_i)^2\]
根均方誤差:\[RMES = \sqrt{MSE}\]
均方誤差和根均方誤差都會受到異常值的影響,而影響最終的模型評估
平均絕對百分比誤差:\[MAPE = \sum_{i=1}^n|\frac{(y_{pred}-y_i)}{y_i}|*\frac{100}{n}\]
平均絕對百分比誤差提高了異常值的魯棒性,相當於把每個點的誤差進行了歸一化處理,降低了個別離群帶來的絕對誤差的影響
1.5 ROC曲線
1.5.1 什麼是ROC曲線?
二值分類器是機器學習領域中最常見也是應用最廣泛的分類器。評價二值分類器的指標很多,比如precision,recall,F1 score,P-R曲線等,但發現這些指標或多或少只能反映模型在某一方面的效能,相比而言,ROC曲線則有很多優點,經常作為評估二值分類器最重要的指標之一
ROC曲線是Receiver Operating Characteristic Curve的簡稱,中文名為'受試者工作特徵曲線'
ROC曲線的橫座標為假陽性率(FPR),縱座標為真陽性率(TPR),FPR和TPR的計算方法分別為:\[FPR = \frac{FP}{N}\] \[TPR = \frac{TP}{P}\]
P是真實的正樣本數量,N是真實的負樣本數量,TP是P個正樣本中被分類器預測為正樣本的個數,FP為N個負樣本中被預測為正樣本的個數
1.5.2 ROC曲線繪製
建立資料集
import pandas as pd
column_name = ['真實標籤','模型輸出概率']
datasets = [['p',0.9],['p',0.8],['n',0.7],['p',0.6],
['p',0.55],['p',0.54],['n',0.53],['n',0.52],
['p',0.51],['n',0.505],['p',0.4],['p',0.39],
['p',0.38],['n',0.37],['n',0.36],['n',0.35],
['p',0.34],['n',0.33],['p',0.30],['n',0.1]]
data = pd.DataFrame(datasets,index = [i for i in range(1,21,1)],columns=column_name)
print(data) 真實標籤 模型輸出概率
1 p 0.900
2 p 0.800
3 n 0.700
4 p 0.600
5 p 0.550
6 p 0.540
7 n 0.530
8 n 0.520
9 p 0.510
10 n 0.505
11 p 0.400
12 p 0.390
13 p 0.380
14 n 0.370
15 n 0.360
16 n 0.350
17 p 0.340
18 n 0.330
19 p 0.300
20 n 0.100繪製ROC曲線
# 計算各種概率情況下對應的(假陽率,真陽率)
points = {0.1:[1,1],0.3:[0.9,1],0.33:[0.9,0.9],0.34:[0.8,0.9],0.35:[0.8,0.8],
0.36:[0.7,0.8],0.37:[0.6,0.8],0.38:[0.5,0.8],0.39:[0.5,0.7],0.40:[0.4,0.7],
0.505:[0.4,0.6],0.51:[0.3,0.6],0.52:[0.3,0.5],0.53:[0.2,0.5],0.54:[0.1,0.5],
0.55:[0.1,0.4],0.6:[0.1,0.3],0.7:[0.1,0.2],0.8:[0,0.2],0.9:[0,0.1]}
X = []
Y = []
for value in points.values():
X.append(value[0])
Y.append(value[1])
import matplotlib.pyplot as plt
plt.scatter(X,Y,c = 'r',marker = 'o')
plt.plot(X,Y)
plt.xlim(0,1)
plt.ylim(0,1)
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.show()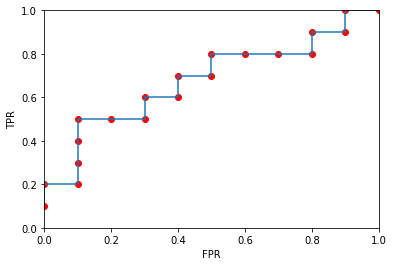
AUC指ROC曲線下的面積大小,該值能夠量化地反映基於ROC曲線衡量出的模型效能,AUC越大說明分類器越可能把真正的正樣本排在前面,分類效能越好
ROC曲線相比P-R曲線,當正負樣本的分佈發生變化時,ROC曲線的形狀能夠儲存基本不變,而P-R曲線的形狀一般會發生激烈的變化,這個特點讓ROC曲線能夠儘量降低不同測試集帶來的干擾,更加客觀地衡量模型本身的效能
2. 模型評估方法
2.1 Holdout檢驗
Holdout檢驗是最簡單也是最直接的驗證方法,它將原始的樣本隨機劃分為訓練集和驗證集兩部分。sklearn.model_selction.train_test_split函式就是使用該方法。比方說,將樣本按照70%-30%的比例分成兩部分,70%的樣本用於模型訓練,30%的樣本用於模型驗證
Holdout檢驗的缺點很明顯,即在驗證集上計算出來的評估指標與原始分組有很大關係,為了消除隨機性,研究者們引入了'交叉驗證'的思想
2.2 交叉驗證
k-flod交叉驗證:首先將全部樣本劃分成K個大小相等的樣本子集,依次遍歷這k個子集,每次把當前子集作為驗證集,其餘的子集作為訓練集。最後把K次評估指標的平均值作為最終的評估指標,在實際實驗中,K經常取10
留一驗證:每次留下一個樣本作為驗證集,其餘所有樣本作為測試集,樣本總數為n,依次對n個樣本進行遍歷,進行n次驗證,再將評估指標求平均值得到最終的評估指標,在樣本總數較多的情況下,留一驗證法的時間開銷極大
2.3 自助法
不管是Holdout檢驗還是交叉驗證,都是基於劃分訓練集和測試集的方法進行模型評估的,然而,當樣本規模較小時,將樣本集進行劃分會讓訓練集進一步減少,這可能會影響模型訓練效果,自助法是可以維持訓練集樣本規模的驗證方法
自助法是基於自助取樣法的檢驗方法,對於總數為n的樣本集合,進行n次有放回的隨機抽樣,得到大小為n的訓練集,n次取樣過程中,有的樣本會被重複取樣,有的樣本沒有被抽到過,將這些沒有被抽到過的樣本作為訓練集,進行模型驗證
2.4 超引數調優
為了進行超引數調優,一般會採用網格搜尋、隨機搜尋、貝葉斯優化等演算法。超引數搜尋演算法一般包括以下幾個要素:
- (1)目標函式,即演算法需要最大化/最小化的目標
- (2)搜尋範圍,一般通過上限和下限來確定
- (3)演算法的其他引數,如搜尋步長
2.4.1 網格搜尋
網格搜尋可能是最簡單、應用最廣泛的超引數搜尋演算法,它通過查詢搜尋範圍內的所有的點來確定最優值。如果採用較大的搜尋範圍以及較小的步長,網格搜尋有很大概率找到全域性最優解,然而這種搜尋方案十分消耗計算資源和時間,特別是需要調優的超引數比較的時候,因此,在實際應用過程中,網格搜尋法一般會先使用較大的搜尋範圍和較大的步長,來尋找全域性最優解可能的位置,然後會逐漸縮小搜尋範圍和步長,來尋找更精確的最優值,這種操作方案可以降低所需的時間和計算量,但由於目標函式一般是非凸的,所有很可能會錯過全域性最優解,sklearn提供了GridSearchCV類實現網格搜尋
2.4.2 隨機搜尋
隨機搜尋的思想與網格搜尋的思想比較相似,只是不再測試上界和下界之間的所有值,而是在搜尋範圍中隨機選取樣本點。它的理論依據是,如果樣本點足夠大,那麼通過隨機取樣也能大概率地找到全域性最優解或近似解,隨機搜尋一般會比網格搜尋要快一些,但是和網格搜尋的快速版一樣,它的結果也是沒法保證的,sklearn提供了RandomizedSearchCV類實現隨機搜尋
2.4.3 貝葉斯優化演算法
貝葉斯優化演算法在尋找最優超引數時,採用了與網格搜尋,隨機搜尋完全不同的方法,網格搜尋和隨機搜尋在測試一個新點時,會忽略前一個點的資訊,而貝葉斯優化演算法則充分利用了之前的資訊,貝葉斯優化演算法通過對目標函式形狀進行學習,找到使目標函式向全域性最優值提升的引數。具體來說,它學習目標函式形狀的方法是,首先根據先驗分佈,假設一個搜尋函式,然後,每一次使用新的取樣點來測試目標函式時,利用這個資訊來更新目標函式的先驗分佈,最後,演算法測試由後驗分佈給出的全域性最值最可能出現的位置的點。
對於貝葉斯優化演算法,有一個需要注意的地方,一旦找到了一個區域性最優值,它會在該區域不斷取樣,所以很容易陷入區域性最優值,為了彌補這個缺陷,貝葉斯優化演算法會在探索和利用之間找到一個平衡點,'探索'就是在還未取樣的區域獲取取樣點,而'利用'則是根據後驗分佈在最可能出現全域性最優值的區域進行取樣
3. 優化過擬合與欠擬合
3.1 降低過擬合風險的方法
- (1)從資料入手,後的更多的訓練資料。使用更多的訓練資料是解決過擬合問題最有效的手段,因為更多的樣本能夠讓模型學習到更多更有效的特徵,減少噪音的影響,當然,直接增加實驗資料一般是很困難的,但是可以通過一定的規則來擴充訓練資料。比如,在影象分類的問題上,可以通過影象的平移、旋轉、縮放等方式擴充資料;更進一步地,可以使用生成式對抗網路來合成大量的新訓練資料
- (2)降低模型複雜度。在資料較少時,模型過於複雜是產生過擬合的主要因素,適當降低模型複雜度可以避免擬合過多的取樣噪音。例如,在神經網路中減少網路層數、神經元個數等;在決策樹模型中降低樹的深度、進行剪枝等
- (3)正則化方法
- (4)整合學習方法。整合學習是把多個模型整合在一起,來降低單一模型的過擬合風險
3.2 降低欠擬合風險方法
- (1)新增新特徵。當特徵不足或現有特徵與樣本標籤的相關性不強時,模型容易出現不擬合,通過挖掘'上下文特徵''ID類特徵''組合特徵'等新的特徵,往往能夠取得更好的效果,在深度學習的潮流中,有很多型別可以幫組完成特徵工程,如因子分解機
- (2)增加模型複雜度。簡單模型的學習能力較差,通過增加模型的複雜度可以使模型擁有更強的擬合能力,例如,線上性模型中新增高次項,在神經網路模型中增加網路層數或神經元個數等
- (3)減少正則化係數。正則化是用來防止過擬合的,但當模型出現欠擬合現象時,則需要針對性地減少正則化係數
參考資料:
- (1)<機器學習實戰基於Scikit-Learn和TensorFlow>
- (2)<百面機器學習>