
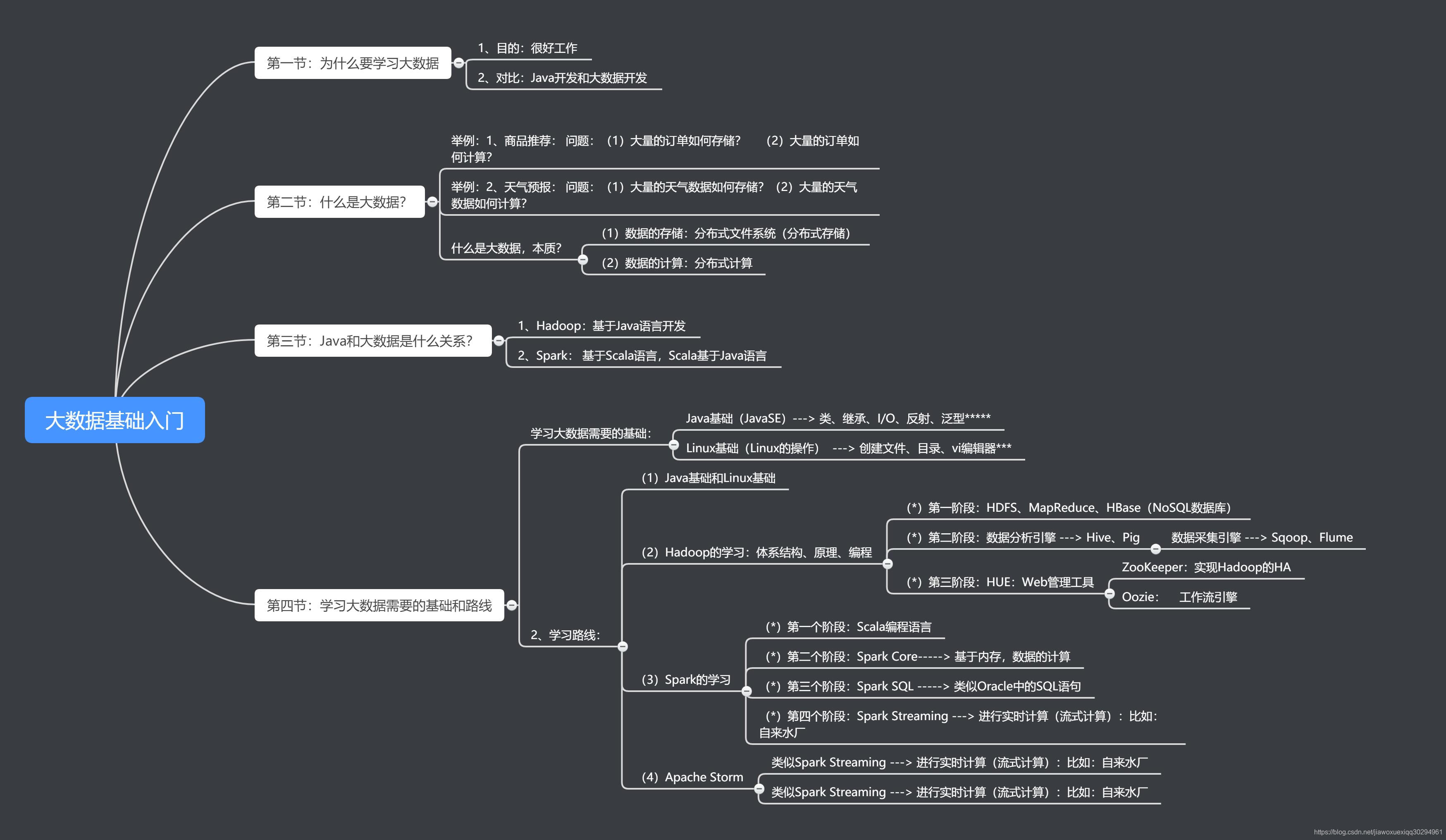
到底學不學大資料?來看看大咖對大資料發展未來趨勢的預測
技術的發展,讓這個世界每天都在源源不斷地產生資料,隨著大資料概念被提出,這個技術逐漸發展成為一個行業,並被不斷看好。那麼大資料行業的未來發展如何?三個方向預測大資料技術發展未來趨勢:
(一)社交網路和物聯網技術拓展了資料採集技術渠道
經過行業資訊化建設,醫療、交通、金融等領域已經積累了許多內部資料,構成大資料資源的“存量”;而移動網際網路和物聯網的發展,大大豐富了大資料的採集渠道,來自外部社交網路、可穿戴裝置、車聯網、物聯網及政府公開資訊平臺的資料將成為大資料增量資料資源的主體。當前,移動網際網路的深度普及,為大資料應用提供了豐富的資料來源。
另外,快速發展的物聯網,也將成為越來越重要的大資料資源提供者。相對於現有網際網路資料雜亂無章和價值密度低的特點,通過可穿戴、車聯網等多種資料採集終端,定向採集的資料資源更具利用價值。例如,智慧化的可穿戴裝置經過幾年的發展,智慧手環、腕帶、手錶等可穿戴正在走向成熟,智慧鑰匙扣、自行車、筷子等裝置層出窮,國外 Intel、Google、Facebook,國內百度、京東、小米等有所佈局。
如果你也苦惱於轉行求職資料分析類崗位,不知道如何下手?很多初學者,對大資料的概念都是模糊不清的,大資料是什麼,能做什麼,學的時候,該按照什麼線路去學習,學完往哪方面發展,想深入瞭解,想學習的同學歡迎加入大資料學習企鵝群:458345782,有大量乾貨(零基礎以及進階的經典實戰)分享給大家,並且有清華大學畢業的資深大資料講師給大家免費授課,給大家分享目前國內最完整的大資料高階實戰實用學習流程體系。
企業內部資料仍是大資料主要來源,但對外部資料的需求日益強烈。當前,有 32%的企業通過外部購買所獲得的資料;只有18%的企業使用政府開放資料。如何促進大資料資源建設,提高資料質量,推動跨界融合流通,是推動大資料應用進一步發展的關鍵問題之一。
總體來看,各行業都在致力於在用好存量資源的基礎之上,積極拓展新興資料收集的技術渠道,開發增量資源。社交媒體、物聯網等大大豐富了資料採集的潛在渠道,理論上,資料獲取將變得越來越容易。
(二) 分散式儲存和計算技術夯實了大資料處理的技術基礎
大資料儲存和計算技術是整個大資料系統的基礎。
在儲存方面,2000 年左右谷歌等提出的檔案系統(GFS)、以及隨後的 Hadoop 的分散式檔案系統 HDFS(Hadoop Distributed File System)奠定了大資料儲存技術的基礎。
與傳統系統相比,GFS/HDFS 將計算和儲存節點在物理上結合在一起,從而避免在資料密集計算中易形成的 I/O吞吐量的制約,同時這類分散式儲存系統的檔案系統也採用了分散式架構,能達到較高的併發訪問能力。
在計算方面,谷歌在 2004 年公開的 MapReduce 分散式平行計算技術,是新型分散式計算技術的代表。一個 MapReduce 系統由廉價的通用伺服器構成,通過新增伺服器節點可線性擴充套件系統的總處理能力(Scale Out),在成本和可擴充套件性上都有巨大的優勢。
(三) 深度神經網路等新興技術開闢大資料分析技術的新時代
大資料資料分析技術,一般分為聯機分析處理(OLAP,OnlineAnalytical Processing)和資料探勘(Data Mining)兩大類。
OLAP技術,一般基於使用者的一系列假設,在多維資料集上進行互動式的資料集查詢、關聯等操作(一般使用 SQL 語句)來驗證這些假設,代表了演繹推理的思想方法。
資料探勘技術,一般是在海量資料中主動尋找模型,自動發展隱藏在資料中的模式(Pattern),代表了歸納的思想方法。
傳統的資料探勘演算法主要有:
(1)聚類,又稱群分析,是研究(樣品或指標)分類問題的一種統計分析方法,針對資料的相似性和差異性將一組資料分為幾個類別。屬於同一類別的資料間的相似性很大,但不同類別之間資料的相似性很小,跨類的資料關聯性很低。企業通過使用聚類分析演算法可以進行客戶分群,在不明確客戶群行為特徵的情況下對客戶資料從不同維度進行分群,再對分群客戶進行特徵提取和分析,從而抓住客戶特點推薦相應的產品和服務。
(2)分類,類似於聚類,但是目的不同,分類可以使用聚類預先生成的模型,也可以通過經驗資料找出一組資料物件的共同點,將資料劃分成不同的類,其目的是通過分類模型將資料項對映到某個給定的類別中,代表演算法是 CART(分類與迴歸樹)。企業可以將使用者、產品、服務等各業務資料進行分類,構建分類模型,再對新的資料進行預測分析,使之歸於已有類中。分類演算法比較成熟,分類準確率也比較高,對於客戶的精準定位、營銷和服務有著非常好的預測能力,幫助企業進行決策。
(3)迴歸,反映了資料的屬性值的特徵,通過函式表達資料對映的關係來發現屬性值之間的一覽關係。它可以應用到對資料序列的預測和相關關係的研究中。企業可以利用迴歸模型對市場銷售情況進行分析和預測,及時作出對應策略調整。在風險防範、反欺詐等方面也可以通過迴歸模型進行預警。
傳統的資料方法,不管是傳統的 OLAP 技術還是資料探勘技術,都難以應付大資料的挑戰。首先是執行效率低。傳統資料探勘技術都是基於集中式的底層軟體架構開發,難以並行化,因而在處理 TB 級以上資料的效率低。其次是資料分析精度難以隨著資料量提升而得到改進,特別是難以應對非結構化資料。
在人類全部數字化資料中,僅有非常小的一部分(約佔總資料量的 1%)數值型資料得到了深入分析和挖掘(如迴歸、分類、聚類),大型網際網路企業對網頁索引、社交資料等半結構化資料進行了淺層分析(如排序),佔總量近 60%的語音、圖片、視訊等非結構化資料還難以進行有效的分析。
所以,大資料分析技術的發展需要在兩個方面取得突破,一是對體量龐大的結構化和半結構化資料進行高效率的深度分析,挖掘隱性知識,如從自然語言構成的文字網頁中理解和識別語義、情感、意圖等;二是對非結構化資料進行分析,將海量複雜多源的語音、影象和視訊資料轉化為機器可識別的、具有明確語義的資訊,進而從中提取有用的知識。
目前來看,以深度神經網路等新興技術為代表的大資料分析技術已經得到一定發展。
神經網路是一種先進的人工智慧技術,具有自身自行處理、分佈儲存和高度容錯等特性,非常適合處理非線性的以及那些以模糊、不完整、不嚴密的知識或資料,十分適合解決大資料探勘的問題。
典型的神經網路模型主要分為三大類:第一類是以用於分類預測和模式識別的前饋式神經網路模型,其主要代表為函式型網路、感知機;第二類是用於聯想記憶和優化演算法的反饋式神經網路模型,以 Hopfield的離散模型和連續模型為代表。第三類是用於聚類的自組織對映方法,以 ART 模型為代表。不過,雖然神經網路有多種模型及演算法,但在特定領域的資料探勘中使用何種模型及演算法並沒有統一的規則,而且人們很難理解網路的學習及決策過程。
隨著網際網路與傳統行業融合程度日益加深,對於 web 資料的挖掘和分析成為了需求分析和市場預測的重要段。Web 資料探勘是一項綜合性的技術,可以從文件結構和使用集合中發現隱藏的輸入到輸出的對映過程。
目前研究和應用比較多的是 PageRank 演算法。PageRank是Google演算法的重要內容,於2001年9月被授予美國專利,以Google創始人之一拉里·佩奇(Larry Page)命名。PageRank 根據網站的外部連結和內部連結的數量和質量衡量網站的價值。這個概念的靈感,來自於學術研究中的這樣一種現象,即一篇論文的被引述的頻度越多,一般會判斷這篇論文的權威性和質量越高。
需要指出的是,資料探勘與分析的行業與企業特點強,除了一些最基本的資料分析工具外,目前還缺少針對性的、一般化的建模與分析工具。各個行業與企業需要根據自身業務構建特定資料模型。資料分析模型構建的能力強弱,成為不同企業在大資料競爭中取勝的關鍵。
如果你也苦惱於轉行求職資料分析類崗位,不知道如何下手?很多初學者,對大資料的概念都是模糊不清的,大資料是什麼,能做什麼,學的時候,該按照什麼線路去學習,學完往哪方面發展,想深入瞭解,想學習的同學歡迎加入大資料學習企鵝群:458345782,有大量乾貨(零基礎以及進階的經典實戰)分享給大家,並且有清華大學畢業的資深大資料講師給大家免費授課,給大家分享目前國內最完整的大資料高階實戰實用學習流程體系。