
MapReduce 中如何處理HBase中的資料?如何讀取HBase資料給Map?如何將結果儲存到HBase中?
阿新 • • 發佈:2018-11-29
MapReduce 中如何處理HBase中的資料?如何讀取HBase資料給Map?如何將結果儲存到HBase中?
Mapper類:包括一個內部類(Context)和四個方法(setup,map,cleanup,run);
setup,cleanup用於管理Mapper生命週期中的資源。setup -> map -> cleanup , run方法執行了這個過程;
map方法用於對一次輸入的key/value對進行map動作,對應HBase操作也就是一行的處理;
job的配置:
1. TableInputFormat完成了什麼功能?
(1)通過設定conf.set(TableInputFormat.INPUT_TABLE,"udc_sell");設定HBase的輸入表;
設定conf.set(TableInputFormat.SCAN, TableMRUtil.convertScanToString(scan));設定對HBase輸入表的scan方式;

(2)通過TableInputFormat.setConf(Configration conf)方法初始化scan物件;
scan物件是從job中設定的物件,以字串的形式傳給TableInputFormat,在TableInputFormat內部將scan字元創轉換為scan物件

* TableMapReduceUtily有兩個方法:convertScanToString和convertStringToScan作用?
將scan例項轉換為Base64字串 和將Base64字串還原為scan例項;
Q:為什麼不直接穿Scan物件而是費盡周折地轉換來轉換去呢?
A:
(3)TableInputFormat繼承了TableInputFormatBase實現了InputFormat抽象類的兩個抽象方法:
getSplits()和createRecordReader()方法:
A:getSplits()斷定輸入物件的切分原則:對於TableInputFormatBase,會遍歷HBase相應表的所有HRegion,每一個HRegion都會被分成一個split,所以切分的塊數是 與表中HRegion的數目是相同的;
InputSplit split = new TableSplit(table.getTableName(),splitStart, splitStop, regionLocation); 在split中只會記載HRegion的其實rowkey和終止rowkey,具體的去讀取 這篇區域的資料是createRecordReader()實現的。
計算出來的每一個分塊都將被作為一個map Task的輸入;http://
Q:但是分出的塊分給那臺機器的那個task去執行Map,即jobTracker如何排程任務給taskTracker?
A: 需要進一步瞭解Map的本地化執行機制和jobTracker的排程演算法;(可能是就近原則)
對於一個map任務,jobtracker會考慮tasktracker的網路位置,並選取一個距離其輸入分片檔案最近的tasktracker。在最理想 的情況下,任務是資料本地化的(data- local),也就是任務執行在輸入分片所在的節點上。同樣,任務也可能是機器本地化的:任務和輸入分片在同一個機架,但不在同 一個節點上。
reduce任務,jobtracker簡單滴從待執行的reduce任務列表中選取下一個來執行,用不著考慮資料段餓本地化。
B:createRecordReader()按照必然格式讀取響應資料:
接收split塊,返回讀取記錄的結果;
public RecordReader<ImmutableBytesWritable, Result> createRecordReader(InputSplit split, TaskAttemptContext context){
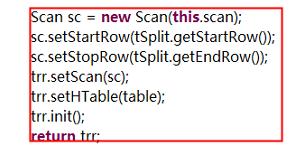
}
trr.init()返回的是這個分塊的起始rowkey的記錄;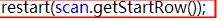
RecordReader將一個split解析成<key,value>對的形式提供給map函式,key就是rowkey,value就是對應的一行資料;
RecordReader用於在劃分中讀取<Key,Value>對。RecordReader有五個虛方法,分別是:
initialize:初始化,輸入引數包括該Reader工作的資料劃分InputSplit和Job的上下文context;
nextKey:得到輸入的下一個Key,如果資料劃分已經沒有新的記錄,返回空;
nextValue:得到Key對應的Value,必須在呼叫nextKey後呼叫;
getProgress:得到現在的進度;
close:來自java.io的Closeable介面,用於清理RecordReader。
2. job.setInputFormatClass(TableInputFormat.class);
3. TableMapReduceUtil.initTableReducerJob("daily_result", DailyReduce.class, job);
使用了該方法就不需要再單獨定義
initTableReducerJob()方法完成了一系列操作:
(1). job.setOutputFormatClass(TableOutputFormat.class); 設定輸出格式;
(2). conf.set(TableOutputFormat.OUTPUT_TABLE, table); 設定輸出表;
(3). 初始化partition
Mapper類:包括一個內部類(Context)和四個方法(setup,map,cleanup,run);
setup,cleanup用於管理Mapper生命週期中的資源。setup -> map -> cleanup , run方法執行了這個過程;
map方法用於對一次輸入的key/value對進行map動作,對應HBase操作也就是一行的處理;
job的配置:
1. TableInputFormat完成了什麼功能?
(1)通過設定conf.set(TableInputFormat.INPUT_TABLE,"udc_sell");設定HBase的輸入表;
設定conf.set(TableInputFormat.SCAN, TableMRUtil.convertScanToString(scan));設定對HBase輸入表的scan方式;
(2)通過TableInputFormat.setConf(Configration conf)方法初始化scan物件;
scan物件是從job中設定的物件,以字串的形式傳給TableInputFormat,在TableInputFormat內部將scan字元創轉換為scan物件
* TableMapReduceUtily有兩個方法:convertScanToString和convertStringToScan作用?
將scan例項轉換為Base64字串 和將Base64字串還原為scan例項;
Q:為什麼不直接穿Scan物件而是費盡周折地轉換來轉換去呢?
A:
(3)TableInputFormat繼承了TableInputFormatBase實現了InputFormat抽象類的兩個抽象方法:
getSplits()和createRecordReader()方法:
A:getSplits()斷定輸入物件的切分原則:對於TableInputFormatBase,會遍歷HBase相應表的所有HRegion,每一個HRegion都會被分成一個split,所以切分的塊數是 與表中HRegion的數目是相同的;
InputSplit split = new TableSplit(table.getTableName(),splitStart, splitStop, regionLocation); 在split中只會記載HRegion的其實rowkey和終止rowkey,具體的去讀取 這篇區域的資料是createRecordReader()實現的。
計算出來的每一個分塊都將被作為一個map Task的輸入;http://
Q:但是分出的塊分給那臺機器的那個task去執行Map,即jobTracker如何排程任務給taskTracker?
A: 需要進一步瞭解Map的本地化執行機制和jobTracker的排程演算法;(可能是就近原則)
對於一個map任務,jobtracker會考慮tasktracker的網路位置,並選取一個距離其輸入分片檔案最近的tasktracker。在最理想 的情況下,任務是資料本地化的(data- local),也就是任務執行在輸入分片所在的節點上。同樣,任務也可能是機器本地化的:任務和輸入分片在同一個機架,但不在同 一個節點上。
reduce任務,jobtracker簡單滴從待執行的reduce任務列表中選取下一個來執行,用不著考慮資料段餓本地化。
B:createRecordReader()按照必然格式讀取響應資料:
接收split塊,返回讀取記錄的結果;
public RecordReader<ImmutableBytesWritable, Result> createRecordReader(InputSplit split, TaskAttemptContext context){
}
trr.init()返回的是這個分塊的起始rowkey的記錄;
RecordReader將一個split解析成<key,value>對的形式提供給map函式,key就是rowkey,value就是對應的一行資料;
RecordReader用於在劃分中讀取<Key,Value>對。RecordReader有五個虛方法,分別是:
initialize:初始化,輸入引數包括該Reader工作的資料劃分InputSplit和Job的上下文context;
nextKey:得到輸入的下一個Key,如果資料劃分已經沒有新的記錄,返回空;
nextValue:得到Key對應的Value,必須在呼叫nextKey後呼叫;
getProgress:得到現在的進度;
close:來自java.io的Closeable介面,用於清理RecordReader。
2. job.setInputFormatClass(TableInputFormat.class);
3. TableMapReduceUtil.initTableReducerJob("daily_result", DailyReduce.class, job);
使用了該方法就不需要再單獨定義
initTableReducerJob()方法完成了一系列操作:
(1). job.setOutputFormatClass(TableOutputFormat.class); 設定輸出格式;
(2). conf.set(TableOutputFormat.OUTPUT_TABLE, table); 設定輸出表;
(3). 初始化partition