
hadoop原生平臺搭建教程
搭建準備hadoop-3.1.1.tar.gz jdk-8u77-linux-x64.tar.gz(官網下載)
0x1 基礎環境配置
centos 7.1系統
我這裡使用的是雙節點。建立兩臺虛擬機器 master、slaver 並使用hostnamectl set-hostname改名
開啟主機的DHCP模式,自動獲取ip地址。方法如下:
cd /etc/sysconfig/network-scripts/ //進入網絡卡編輯目錄 vi ifcfg-enp16777736 //編輯網絡卡enp0s3的配置檔案
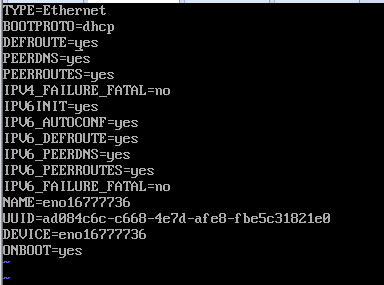
重啟網絡卡 service network restart然後設定hosts,所有節點都要設定

設定ssh免密登陸:ssh-keygen所有節點都要設定

所有節點輸入:ssh-copy-id slaver
ssh-copy-id master使用ssh master(ssh slaver)來驗證免密登陸是否成功,如果不需要輸入密碼則成功

0x2 編輯環境變數
建立jdk資料夾:mkdir -p /usr/jdk64 將jdk解壓到改資料夾:tar -zxvf jdk-8u77-linux-x64.tar.gz -C /usr/jdk64/
解壓hadoop將其移動到/opt/bigdate
解壓: tar -zxvf hadoop-3.1.1.tar.gz
驗證環境:hadoop version
修改配置檔案

紅框是java環境,藍框是hadoop環境
完成後生效環境變數
source /etc/profile0x3更改配置檔案
進入/opt/bigdate/hadoop-3.1.1/etc/hadoop目錄更改core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml配置檔案
編輯 vi hadoop-env.sh
新增:export JAVA_HOME=/usr/jdk64/jdk1.8.0_77/
編輯 vi core-site.sh
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/opt/bigdate/hadoop-3.1.1/tmp</value>
</property>
</configuration>配置vi hdfs-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/bigdate/hadoop-3.1.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdate/hadoop-3.1.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>配置vi mapred-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0:50060</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/bigdate/hadoop-3.1.1/etc/hadoop,
/opt/bigdate/hadoop-3.1.1/share/hadoop/common/*,
/opt/bigdate/hadoop-3.1.1/share/hadoop/common/lib/*,
/opt/bigdate/hadoop-3.1.1/share/hadoop/hdfs/*
/opt/bigdate/hadoop-3.1.1/share/hadoop/hdfs/lib/*
/opt/bigdate/hadoop-3.1.1/share/hadoop/mapreduce/*
/opt/bigdate/hadoop-3.1.1/share/hadoop/yarn/*
/opt/bigdate/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>配置vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
</configuration>配置 vi workers
此處因為前面配置了hosts,所以此處可以直接寫主機名,如果沒有配置,必須輸入相應主機的ip地址。配置的workers,hadoop會把配置在這裡的主機當作datanode

將hadoop資料夾複製到其他節點
scp -r /opt/bigdate/hadoop-3.1.1 master:/opt/bigdate/完成後在/opt/bigdate/hadoop-3.1.1/sbin(根據你們自己的配置來)
輸入start-all.sh即可
0x4排錯
如果遇到
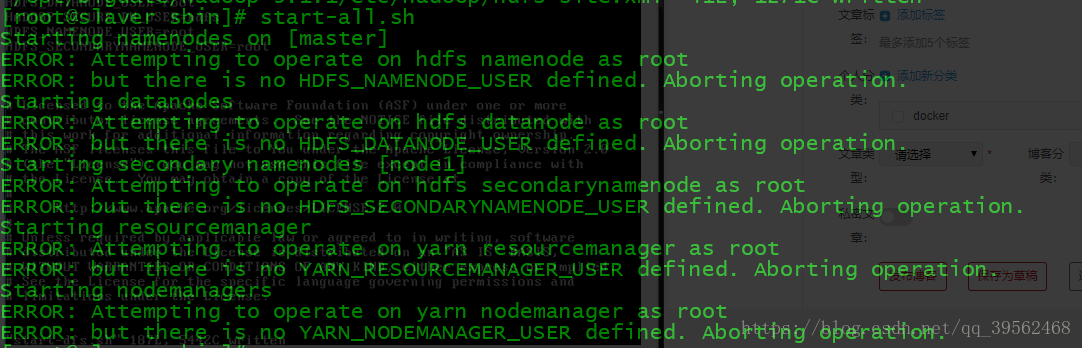
需要修改start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh
四個檔案的使用者名稱,並需要修改/etc/SELINUX/confde配置
配置vi start-dfs.sh新增
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root配置vi stop-dfs.sh新增
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root配置vi start-yarn.sh新增
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root配置vi stop-yarn.sh 新增
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root配置vi /etc/selinux/config 修改SELINUX=enforcing更改為SELINUX=disabled
最後將其重新複製到其他節點
然後啟動hadoop就行了