
Focal Loss(RetinaNet) 與 OHEM
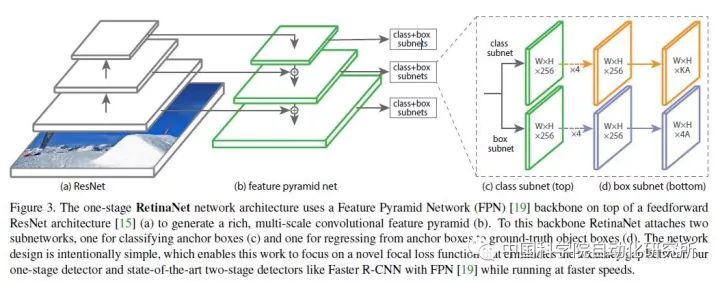
Focal Loss for Dense Object Detection-RetinaNet
YOLO和SSD可以算one-stage演算法裡的佼佼者,加上R-CNN系列演算法,這幾種演算法可以說是目標檢測領域非常經典的演算法了。這幾種演算法在提出之後經過數次改進,都得到了很高的精確度,但是one-stage的演算法總是稍遜two-stage演算法一籌,於是就有了Focal Loss來找場子。
在Focal Loss這篇論文中中,作者認為one-stage精確度不如two-stage是因為下面的原因:
① 正負樣本比例極度不平衡。由於one-stage detector沒有專門生成候選框的子網路,無法將候選框的數量減小到一個比較小的數量級(主流方法可以將候選框的數目減小到數千),導致了絕大多數候選框都是背景類,大大分散了放在非背景類上的精力;
② 梯度被簡單負樣本主導。我們將背景類稱為負樣本。儘管單個負樣本造成的loss很小,但是由於它們的數量極其巨大,對loss的總體貢獻還是佔優的,而真正應該主導loss的正樣本由於數量較少,無法真正發揮作用。這樣就導致收斂不到一個好的結果。
既然負樣本數量眾多,one-stage detector又不能減小負樣本的數量,那麼很自然的,作者就想到減小負樣本所佔的權重,使正樣本佔據更多的權重,這樣就會使訓練集中在真正有意義的樣本上去,這也就是Focal Loss這個題目的由來。
其實在Focal Loss之前,就有人提出了OHEM(online hard example mining)方法。OHEM的核心思想就是增加錯分類樣本的權重,但是OHEM卻忽略了易分類樣本,而我們知道這一部分是所有樣本中的絕大部分。

與OHEM不同,Focal Loss把注意力放在了易分類樣本上,它的形式如圖所示。Focal Loss是一種可變比例的交叉熵損失,當正確分類可能性提高時比例係數會趨近於0。這樣一來,即使再多的易分類樣本也不會主導梯度下降的過程,於是訓練網路自然可以自動對易分類樣本降權,從而快速地集中處理難分類樣本。
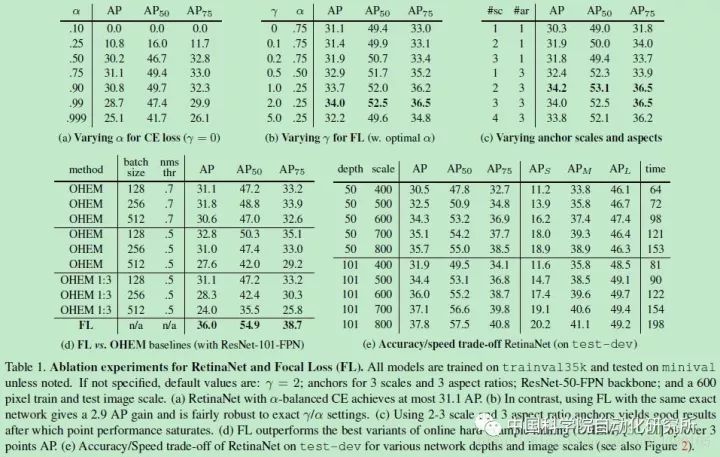
可以看出,Focal Loss打敗了所有state-of-the-art的演算法,而且竟然在速度上也是一馬當先,可以說相當有說服力。但是作者為了證明Focal Loss的有效性,並沒有設計更新穎的網路,這與其他演算法提高精確度的做法是不一樣的——他們要麼改造原有演算法的網路結構,要麼另闢蹊徑。另外,Focal Loss函式的形式並不是不可變的,只要可以達到對易分類樣本降權的目的,可以在形式上有所變化。
總之,Class imbalance是阻礙one-stage方法提高準確率的主要障礙,過多的easy negative examples會在訓練過程中佔據主導地位,使訓練結果惡化,所以要用Focal Loss對easy negative examples進行降權,而把更多的注意力集中在hard examples上。
OHEM: Training Region-based Object Detectors with Online Hard Example Mining
Hard example mining:https://github.com/abhi2610/ohem
主要有2種參見Hard example mining演算法,優化SVM時候的演算法和非SVM時的利用。
在優化SVM中使用Hard example mining時,訓練演算法主要維持訓練SVM和在工作集上收斂的平衡迭代過程,同時在更新過程中去除一些工作集中樣本並新增其他特殊的標準。這裡的標準即去掉一些很容易區分的樣本類,並新增一些用現有的模型不能判斷的樣本類,進行新的訓練。工作集為整個訓練集中的一小部分資料。
非SVM中使用時,該Hard example mining演算法開始於正樣本資料集和隨機的負樣本資料集,機器學習模型在這些資料集中進行訓練使其達到該資料集上收斂,並將其應用到其他未訓練的負樣本集中,將判斷錯誤的負樣本資料(false positives)加入訓練集,重新對模型進行訓練。這種過程通常只迭代一次,並不獲得大量的再訓練收斂過程。
網路結構框架:
OHEM演算法基於Fast R-CNN演算法進行改進,作者認為Fast R-CNN演算法中創造mini-batch用來進行SGD演算法,並不具有高效和最優的狀態,而OHEM可以取得lower training loss,和higher mAP。對比下圖兩種演算法Fast R-CNN和OHEM結構: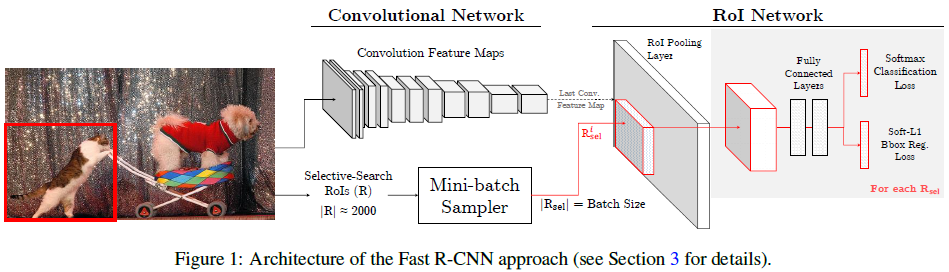
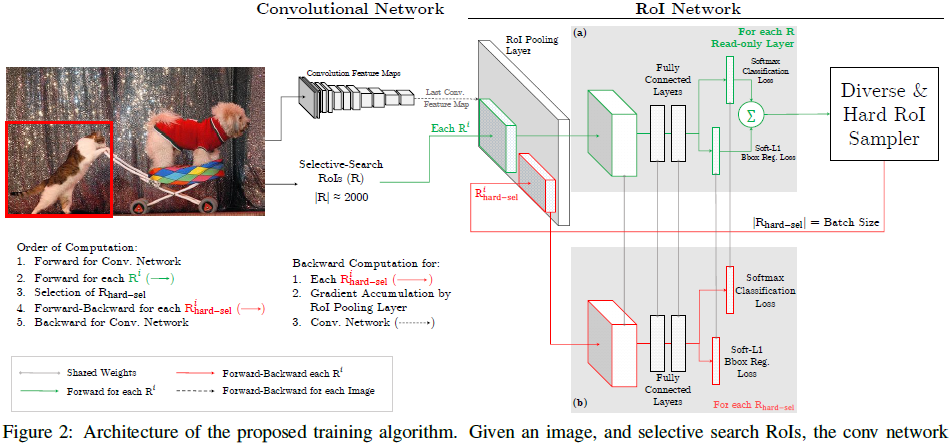
對比可以發現,文章提出的OHEM演算法裡,對於給定影象,經過selective search RoIs,同樣計算出卷積特徵圖。但是在綠色部分的(a)中,一個只讀的RoI網路對特徵圖和所有RoI進行前向傳播,然後Hard RoI module利用這些RoI的loss選擇B個樣本。在紅色部分(b)中,這些選擇出的樣本(hard examples)進入RoI網路,進一步進行前向和後向傳播。