Focal Loss for Dense Object Detection
Focal loss是Kaiming He和RBG發表在ICCV2017上的文章。
abstract:
one-stage網路和two-stage網路相比,one-stage會得到大量目標位置。one stage不好的原因在於:
- 極度不平衡的正負樣本比例:abchor近似於sliding window的方式會使正負樣本接近1000:1,而且絕大部分的負樣本都是easy example,這樣就導致了下面這個問題:
- gradient 被easy example dominant的問題:往往這些easy example 雖然loss很低,但是由於數量眾多,對於loss依然有很大的貢獻,從而導致了收斂到一個不夠好的結果。
所以,作者的解決思想很直接:直接按照loss decay掉那些easy example的權重,這樣使訓練更加bias到有意義的樣本中去。[摘自知乎]
在RCNN二階段系列,class imbalance is addressed by a two-stage cascade and simpling heuristics[二階段級聯和取樣啟發式]。可以使用selective search、EdgeBoxes、DeepMask、RPN來進行預取樣。這樣可以快速的減少候選目標位置樣本,過濾掉大部分的background samplings。在第二階段就可以可以採用一個固定的foreground-to-background ratio(1:3)或者是online hard example mining(OHEM),為了保證在頭部訓練的時候有一個正負樣本可控的平衡。
相反,在one-stage網路中,就要處理大量的候選目標定位。傳統的方法可以使用bootstrapping or hard example mining的方法去解決。
paper method:
paper提出了一個新的loss函式來代替以往的方法去解決class imbalance的問題。The loss function is a dynamically scaled cross entropy loss, where the scaling fator decays to zero as confidence in the correct class increases。[作者還強調,focal loss的形式並不重要,主要是這樣的思想。並且作者在論文的最後還嘗試了其他的一些form實現]
作者為了驗證Focal loss的作用,設計了RetinaNet網路[最好效果是Resnet-101-FPN backbone, achieves a COCO test-dev AP of 39.1 while running at 5 fps]。
Focal loss:
訓練的時候,不平衡的情況甚至可以達到foreground:background=1:1000,這樣的訓練樣本對loss的產生是有不平衡問題的。所以introduce the focal loss starting from the cross entropy(CE) loss for binary classification。

即當y為只有0和1值時(這裡是因為在cornerNet裡有y不全為0或1的情況所表述),。但是論文中是y
{-1, 1},
。
- Balanced Cross Entropy:now, a common methon for addressing class imbalance is to introduce a weighting factor
for class 1 and
for class -1. In practice
may be set by inverse class frequency or treated as a hyperparameter to set by cross validation.

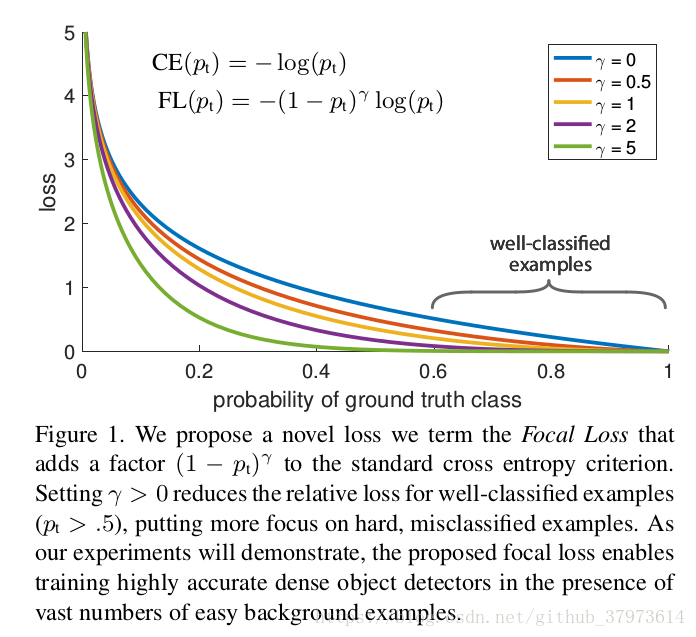
- Focal Loss Definition:給cross entropy loss新增一個因子
with tunable focusing parameter
,定義Focal loss函式如下,以及不同
值的對比圖[實驗發現當
時效果是最好的],實際上paper會再新增一個平衡超參
,這裡有一個細節,實驗採用sigmoid啟用函式來產生p值,會相對softmax產生一個更好的效果:
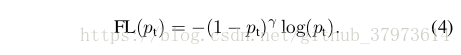

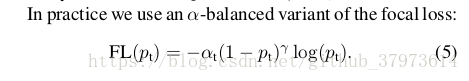
- Class Imbalance and Two-stage Detectors:二階段的檢測器經常會使用到cross entropy loss,但是不會使用
RetinaNet detector
由一個backbone和兩個task-specific子網路組成,backbone用來計算feature map。
- Feature Pyramid Network backbone:構建一個levels為
的金字塔,所有的level的channel為256。
- Anchor:use translation-invariant anchor boxes similar to those in the RPN variant in "Feature pyramid networks for object detection"。在金字塔的
到
,分別有
到
規格的anchors感受區域[The anchors have areas of
} of the original set of 3 aspect ratio anchors,那麼每一層就有9中anchors,結合所有的感受區域[相同的anchor在不同level有不同大小的感受區域],那麼this anchors can cover the scale range 32-813pixels with the respect to the network's input image。 每個anchor都會產生一個K one-hot vector of classification targets,其中K是目標的類別數量,a 4-vector of box regression targets。這些anchor與gt的IoU閾值大於0.5認為是對應類別正樣本即前景樣本,在0到0.4之間則認為是background樣本,0.4到0.5之間的ignored。每個anchor最多隻被安排對應於一個object box,Box regression targets are computed as the offset between each anchor and its assigned object box, or omitted if there is no assignment.
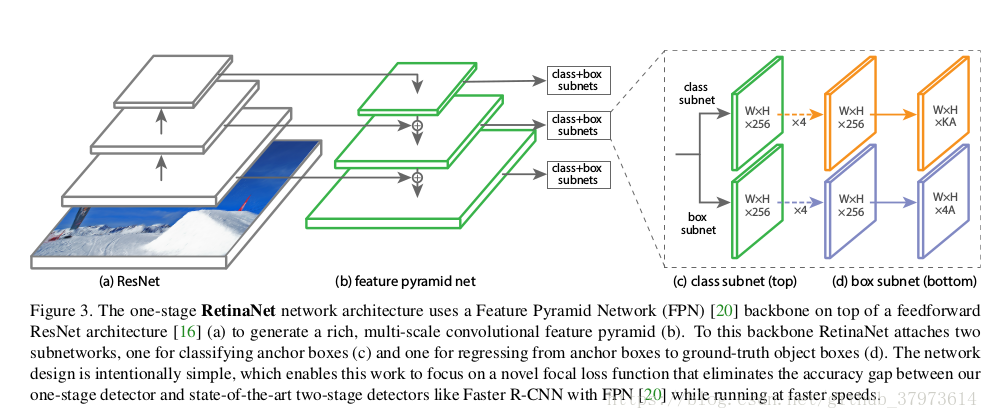
- Classification Subnet:This subnet is a small FCN attached to each FPN levels, parameters of this subnet are shared across all pyramid levels。設計是相當簡單的:從一個給定的pyramid level取出有c通道的feature map,分類子網路([c個3x3conv+relu]x4+K*A個3x3conv+sigmoid/softmax,這裡K是object classes, A anchors),paper中使用C=256,A=9。
- Box Regression Subnet:regression the offset from each achor box to a nearby ground-truth object。作者使用了class-agnostic bounding box regressor which uses fewer parameters and we found to be equally effective。
Inference and Training
- Inference:為了提升速度,先將confidence<0.05的box-predictions去掉,然後box predictions對每一個FPN level僅僅是取1k top-scoring predictions。The top predictions from all levels are merged and non-maximum suppression with a threshold of 0.5 is applied to yield the final detections。
- Focal loss:發現
魯棒性較高。When training RetinaNet, the focal loss is applied to all~100k anchors normalized by the number of anchors assigned to a ground-truth box(not total anchors, since the vast majority of anchors are easy negatives and receive negligible loss values under the focal loss) in each sampled image。
- Initialization:for the final conv layer of the classification subnet,we set the bias initialization to
,其中
闡述了:訓練每個anchor開始的時候,被標記為foreground with confidence of ~
,這樣的初始化可以在訓練迭代第一次的時候防止大量background anchors產生大的loss值。
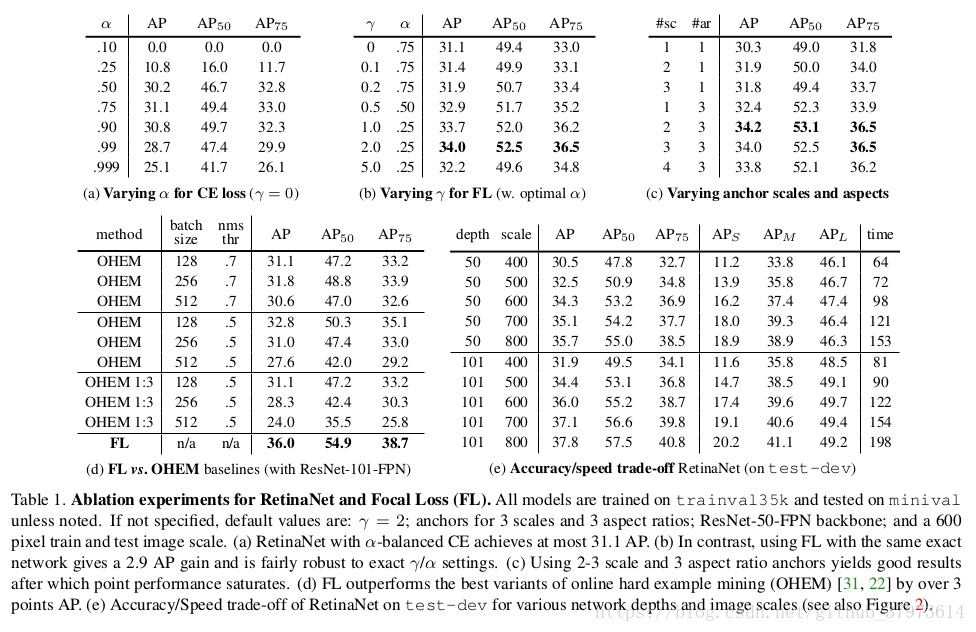
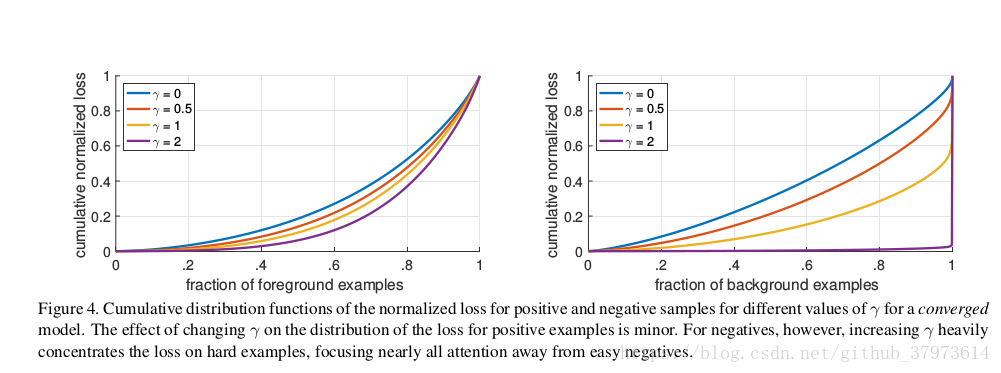
Experiments

- Focal loss VS. online hard example mining(OHEM):同focal loss一樣,ohem會重視被誤分類的例子,但是不像FL,OHEM會完全的放棄easy examples。[Specifically, in OHEM each example is scored by its loss, non-maximum suppression is then applied, and a minibatch is constructioned with the highest-loss examples.],最後minibatch取P:N=1:3。but FL is more effective than OHEM with a gap of 3.2AP。
- Focal loss VS.Hinge loss:略,作者沒有花功夫去優化比較。
Appedix:Focal Loss
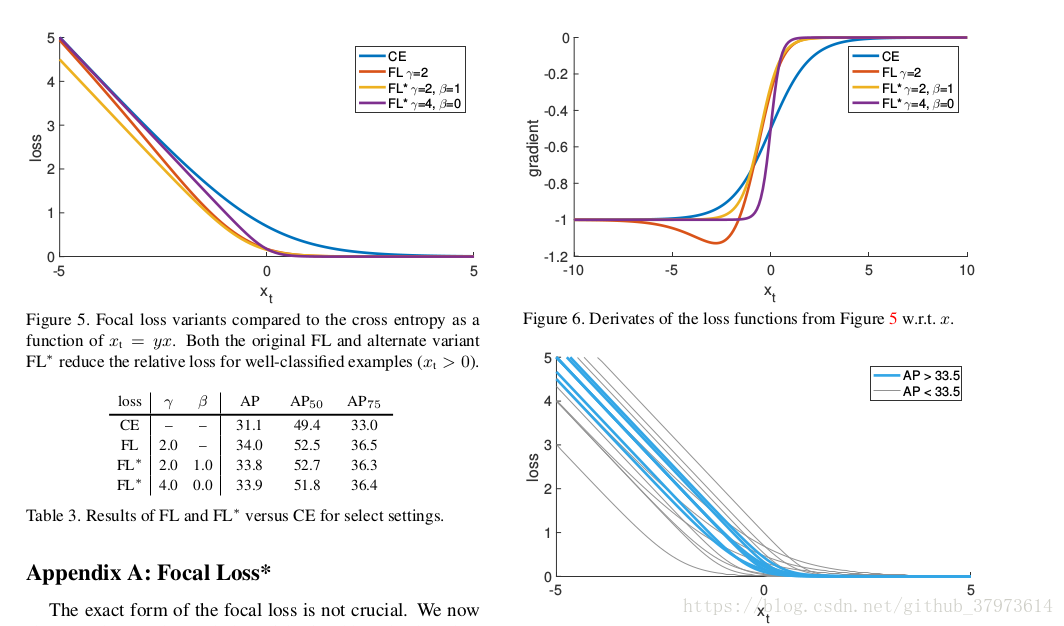
附錄部分是對Focal loss其他形式的一些闡述,因為作者說The exact form of the focal loss is not crucial。Focal loss的具體的形式不是最關鍵的,主要是這樣的一種樣本對loss貢獻的權重思想。
We now show an alternate instantiation of the focal loss that has similar properties and yields conparable results。