
Apache Flume採集資料簡單案例
概述
Flume 是 Cloudera 提供的一個高可用的,高可靠的,分散式的海量日誌採
集、聚合和傳輸的系統。Flume 支援定製各類資料傳送方,用於收集各型別資料;同時,Flume 提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能
力。一般的採集需求,通過對 flume 的簡單配置即可實現。針對特殊場景也具備
良好的自定義擴充套件能力。因此,flume 可以適用於大部分的日常資料採集場景。
當前 Flume 有兩個版本。Flume 0.9X 版本的統稱 Flume OG(original
generation),Flume1.X 版本的統稱 Flume NG(next generation)。由於 Flume
NG 經過核心元件、核心配置以及程式碼架構重構,與 Flume OG 有很大不同,使用
時請注意區分。改動的另一原因是將 Flume 納入 apache 旗下,cloudera Flume
改名為 Apache Flume。
該部落格介紹Flume版本為:1.6.0
Centos 6.9
執行機制
Flume 的核心是把資料從資料來源(source)收集過來,在將收集到的資料送到
指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,
會先快取資料(channel),待資料真正到達目的地(sink)後,flume 在刪除自己緩
存的資料。
Flume 分散式系統中核心的角色是 agent,agent 本身是一個 Java 程序,一
般執行在日誌收集節點。flume 採集系統就是由一個個 agent 所連線起來形成。
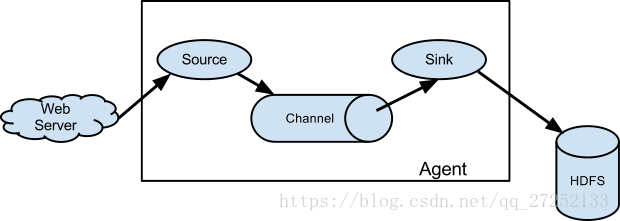
每一個 agent 相當於一個數據傳遞員,內部有三個元件:
- Source:採集源,用於跟資料來源對接,以獲取資料
- Sink:下沉地,採集資料的傳送目的,用於往下一級 agent 傳遞資料或者往
最終儲存系統傳遞資料 - Channel:agent 內部的資料傳輸通道,用於從 source 將資料傳遞到 sink
在整個資料的傳輸的過程中,流動的是 event,它是 Flume 內部資料傳輸的
最基本單元。一個完整的 event 包括:event headers、event body、event 資訊,其中event 資訊就是 flume 收集到的日記記錄。
安裝部署
- 下載地址:
https://www.apache.org/dist/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz - 減壓:
tar -zxvf apache-flume-1.6.0-bin.tar.gz - 進入flume的目錄修改conf下的
flume.env.sh,在裡面配置JAVA_HOME
測試Flume是否能正常執行
- 在conf目錄下新建一個檔案:vi netcat-logger.conf
# 定義這個 agent 中各元件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 元件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置 sink 元件:k1
a1.sinks.k1.type = logger
# 描述和配置 channel 元件,此處使用是記憶體快取的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source channel sink 之間的連線關係
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12.啟動agent去採集資料
在flume目錄下執行
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console-c conf 指定 flume 自身的配置檔案所在目錄
-f conf/netcat-logger.con 指定我們所描述的採集方案
-n a1 指定我們這個 agent 的名字
3.測試
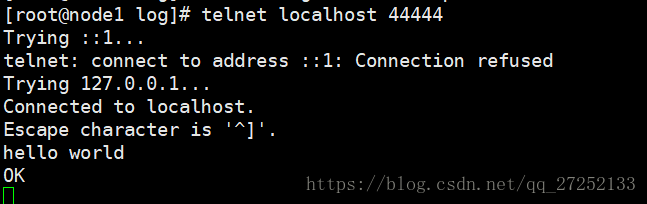
先要往 agent 採集監聽的埠上傳送資料,讓 agent 有資料可採。
隨便在一個能跟 agent 節點聯網的機器上:
telnet localhost 44444如果沒有安裝telnet先使用yum -y install telnet 安裝
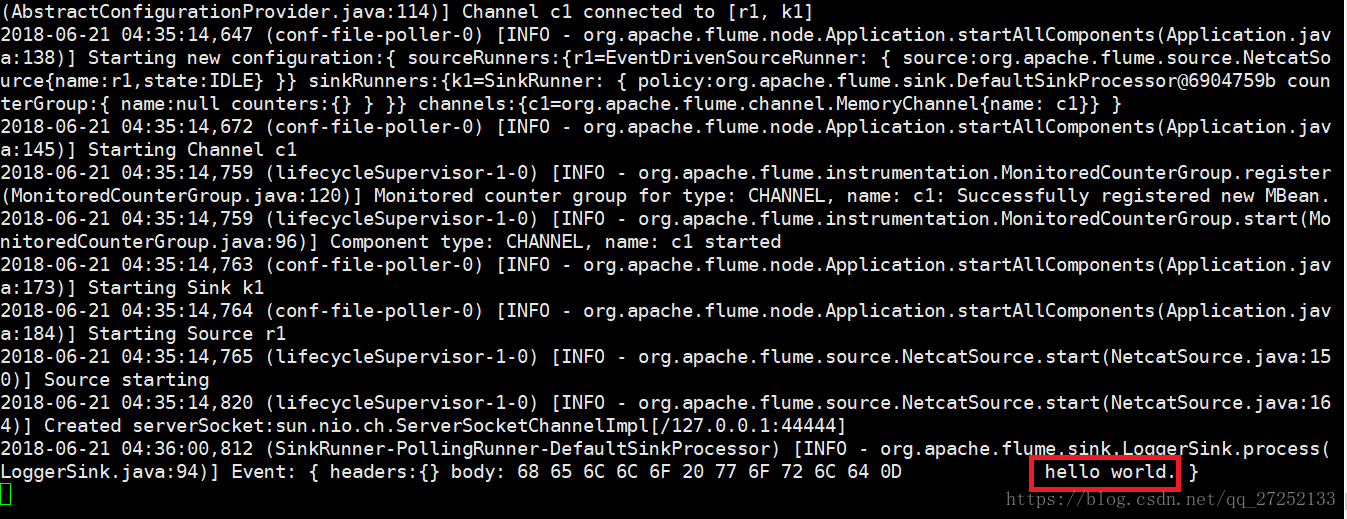
如果產生如下效果證明flume安裝並啟動成功
Flume簡單案例
採集目錄到HDFS
採集需求:伺服器的某特定目錄下,會不斷產生新的檔案,每當有新檔案出現,就需要把檔案採集到HDFS中去
根據需求,首先定義以下三大要素:
- 採集源,即source:spooldir
- 下沉目標,即sink:hdfs sink
- source和sink之間傳遞的通道-channel,可用file channel也可以用記憶體channel
配置檔案編寫:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##注意:不能往監控目中重複丟同名檔案
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的檔案型別,預設是Sequencefile,可用DataStream,則為普通文字
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1測試:
啟動該agent和HDFS,向/root/logs 目錄中建立一個檔案,觀察agent的輸出,最終結果在HDFS的/flume/events/ 下有檔案產生說明測試成功
採集檔案到HDFS
需求:業務系統使用 j log4j 生成的日誌,日誌內容不斷增加,需要把追加到日誌檔案中的資料實時採集到 HDFS
根據需求,首先定義一下3大要素:
- source :
exec tail -F file - sink :
hdfs - channel : 這裡我們使用
memory
編寫配置檔案:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的檔案型別,預設是Sequencefile,可用DataStream,則為普通文字
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
測試同採集目錄到hfs
日誌的採集和彙總
需求:把不同種類的日誌採集彙總到hdfs的不同種類目錄下。
access.log、nginx.log、web.log日誌採集到hdfs中目錄如下:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**配置檔案如下:
# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/log/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/log/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/log/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node2
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 2000000
a1.channels.c1.transactionCapacity = 100000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1測試:
while true ; do echo 'access access....' >>/root/log/access.log;done
while true ; do echo 'nginx nginx....' >>/root/log/nginx.log;done
while true ; do echo 'web web....' >>/root/log/web.log;done分別向三種類型的檔案寫入資料,觀察hdfs中是否有對應的目錄生成。