
有史以來最精彩的自問自答:OpenAI 轉方塊的機械手
來源 | AI科技評論
原創 | 楊曉凡
AI 科技評論按:今年 2 月,OpenAI 發起了一組機械手挑戰,他們在基於 MuJoCo 物理模擬器的 Gym 環境中新設計了含有機械臂末端控制、機械手拿取物體的兩組八個有難度的、早期強化學習演算法已經不足以直接解決的問題。這些具有一定難度的任務 OpenAI 自己也在研究,他們認為這是深度強化學習發展到新時代之後可以作為新標杆的演算法測試任務,而且也歡迎其它機構與學校的研究人員一同研究這些任務,把深度強化學習的表現推上新的臺階。

機械手任務之三 - 轉雞蛋,示意圖
今天(美國時間 7 月 30 日),OpenAI 已經就機械手任務之二的「轉方塊」出了自己答案,展示了一個異常靈活的轉方塊的機械手。而且更精彩的是,這個完全在模擬器中強化學習學到的方案還可以不需任何微調就直接遷移到真實的機械手上。

機械手任務之二 - 轉方塊,真實機械手上執行
OpenAI 也製作了一個酷炫的介紹視訊,請看下方。
OpenAI 把這套系統稱作 Dactyl。OpenAI 過去一年中研究強化學習系統的偏好思路再次得到了體現:在完全模擬的環境中訓練,然後把訓練結果遷移到現實世界的機械結構中
得益於可以大規模高速並行訓練的模擬環境以及 OpenAI 在過去的研究中積累的系統設計與變數選擇經驗,這樣的做法已經可以得到很好的效果。強化學習演算法方面,OpenAI 再次選擇了之前在 DOTA2 5v5 AI 中使用的 PPO(近端策略優化),這當然也再次展示了 PPO 作為通用強化學習演算法的優越性。當然,系統最大的亮點還是可以完全在虛擬環境中訓練,不需要對真實世界有準確的物理模型也可以直接遷移到真實機械手、真實物體的控制上。

兩指夾住旋轉、滑動、手指同步旋轉,三種 Dactyl 完全自動學到的與人類類似的運動模式
任務介紹
任務中使用的機械手模型是參照 Shadow Dexterous Hand 設計的。這是一個完全仿照人手設計的具有 20 個驅動自由度、4 個半驅動自由度、共 24 個關節的機械手,它的大小也和人手大小相同。任務的要求是在機械手的掌心放置一個方塊或者六稜柱,然後要求機械手把它翻轉到一個指定的角度,比如把某個側面翻到上方。系統只能觀察到五指指尖的空間座標以及三個固定角度的彩色攝像機採集到的畫面。

雖然這種機械手面世已經有幾十年了,但是如何讓它像人類一樣高效地控制物體一直都是機器人控制領域的老大難問題。與空間定位移動之類的問題不同,非常多自由度的機械手控制用傳統控制方法不僅執行緩慢,而且必須對自由度做出一些限制,這也就隨之限制了它們控制真實世界物體的能力。
想通過深度強化學習的方法讓機械手翻轉一個物體,需要考慮這幾個問題:
-
能在真實世界中工作。強化學習雖然已經在很多模擬器環境以及遊戲中展現出了優秀的表現,但是強化學習解決真實世界任務的研究仍然非常有限。OpenAI 的最終目標就是要讓 Dactyl 在真實的機器人上完成任務。
-
高自由度控制。一般的機械臂(比如末端為夾子的工業機械臂)只有 7 個自由度,而機械手有多達 24 個自由度,僅僅是不讓 5 個指頭打架都有相當的難度。
-
有噪聲的部分資訊觀察。Dactyl 在真實世界中工作的時候不可避免地會遇到感測器讀數的噪聲和延遲問題。當某一個手指的感測器受到其它手指或者物體的影響而無法返回讀數的時候,Dactyl 只能在部分資訊的狀況下工作。而且,真實物理系統許多細節(比如摩擦和滑動)是無法直接觀察到的,系統必須自己做出推斷。
-
能操作多個物體。Dactyl 的設計目標是要足夠靈活,能夠翻轉、定向多種不同種類的物體。這就意味著不能選用只對某一些特定的幾何形狀有效的策略。
OpenAI 的解決方法
總的來說,OpenAI 完全在模擬器環境中、不借助任何人類輸入進行,讓 Dactyl 通過強化學習訓練物體定向任務。在訓練結束後,學到的策略不需要任何微調環節就可以直接在真實機器人上工作。
不過其實,學習機器人控制方法面臨著兩難的困境。模擬環境中的機器人固然可以輕鬆地獲得大量資料、訓練出足夠複雜的策略,但是大多數控制問題本身的建模都不夠精確,導致學習到的策略難以遷移到真實世界的機器人上。即便只是對「兩個物體接觸」這樣的簡單現象建模,都還是一個開放性的科研問題,沒有什麼廣為接受的、足夠好的模型。直接在真實的機器人上進行訓練自然可以根據真實世界的物理規律學習到好的策略,不過真實世界中的訓練就只能按照真實世界的速度執行,目前的強化學習演算法受限於樣本效率問題,需要相當於好幾年的嘗試經驗才能夠解決物體轉向這樣的已經相對簡單的問題。(財大氣粗的谷歌還真的就這樣做了,具體請見今天推文的第二篇。可以說,谷歌利用自己的財力優勢替整個領域嘗試了很多僅僅理論上可行的研究方法)
OpenAI 的訓練技巧具體來說是「任務隨機化」(domain randomization),它並不追求建模的最佳擬真化,而是在充滿了豐富的變化的環境中學習到各種知識和經驗。這樣的做法兼備了模擬器和真實環境學習兩種做法的優點:在模擬器環境中學習,可以讓模擬器執行速度高於真實世界速度,快速積累經驗;同時用「多變」替代了「逼真」之後,它也可以在模擬器只能近似建模的任務中得到更好的表現。
包括 OpenAI 在內的許多研究者都已經通過實驗展示出了任務隨機化對於越來越複雜的任務的明顯的提升作用,近期的最有力的例子就是 OpenAI 訓練出的 DOTA2 5v5 AI。在這個機械手控制的任務中,OpenAI 也是在探索大規模執行的任務隨機化能否帶來超出現有機器人控制方法的表現。
MuJoCo 物理模擬器相比真實的物理系統有這些不足:
-
在真實機器人和方塊上測量摩擦、阻尼、翻轉阻力等物理屬性很麻煩、很困難。而且隨著機械手磨損、這些值也會逐漸發生變化;模擬器中只有帶有固定引數的近似模型;
-
MuJoCo 是一個剛體運動的模擬器,這意味著它無法模擬機械手指尖的橡膠發生的接觸形變,也無法模擬手指上肌腱的拉伸;
-
在這個任務中機械手只能夠靠多次接觸方塊來改變方塊的方向,但接觸力又眾所周知地難以準確在模擬器中復現。
如果仔細地調節模擬器中的引數,模擬的機械手的行為確實可以和真實機械手的行為做到比較好的匹配,但是上面的這些作用以目前的模擬器就很難準確建模了,調節引數也無濟於事。
所以 OpenAI 轉而使用的方法是使用大規模分散式的模擬訓練環境,而且這些環境中的物理屬性和視覺特徵都是隨機選擇的。隨機地選擇這些值是一種很自然的表徵各種真實物理系統的不確定性的做法,當然這樣也可以防止系統過擬合到一組特定的環境設定中。根據 OpenAI 研究人員們的想法,如果一種策略在所有這些不同的模擬環境中都可以完成任務,那麼它也就很有可能可以直接在真實環境中完成任務。
在開發和測試階段,OpenAI 通過內建的運動控制感測器對學習到的機械手控制策略進行驗證,這也是為了能夠隔絕 Dactyl 自身的控制網路與視覺網路,可以對系統表現做出「客觀」的評價。

系統設計示意圖 - 模擬環境中訓練
A. 分散式工作站從大量隨機環境中收集經驗
B. 通過強化學習訓練控制策略。這個策略根據物體的位姿和五個手指指尖的位置選擇接下來的行動
C. 訓練一個 CNN 根據三路模擬環境中的攝像頭畫面估計物體的位姿

系統設計示意圖 - 遷移到真實世界
D. 位姿估計網路和控制策略網路共同工作,把任務從虛擬環境遷移到真實環境
學習控制
通過構建可以支援遷移的模擬環境,OpenAI 把真實世界的機器人控制問題簡化為了模擬環境中完成任務的問題,現在它就很適合用強化學習解決。當然了,即便是在模擬器中,控制如此多自由度的機械手完成任務仍然是一個有挑戰性的目標,何況不同的模擬環境中還有不同的隨機物理屬性,這意味著物體的運動方式都會與真實世界有所不同。
為了能夠在不同的環境之間泛化,策略最好能夠在不同物理引數的環境中做出不同的行為。考慮到大多數的動態物理引數都無法從單次觀察中得出推斷結果,OpenAI 選用了帶有一定記憶能力的 LSTM 網路架構,實際上在模擬環境中基於 LSTM 得到的策略做出的旋轉動作也要比其它不具有記憶能力的策略多一倍。
Dactyl 使用的大規模分散式 PPO 實現「Rapid」是和 DOTA2 5v5 AI 一樣的。在這個任務中,模型架構、環境、超引數有所區別,但演算法和訓練程式碼是一致的。Rapid 訓練策略使用了 6144 個 CPU 和 8 個 GPU,訓練 50 小時就可以採集到相當於真實世界中 100 年長度的經驗。
學習觀察
OpenAI 的設計目標是讓 Dactyl 能夠控制任意的物體,不侷限於那些經過專門的改動以後更好追蹤的物體。所以 Dactyl 也就選用了一組正常的彩色攝像頭對物體的位置和姿態進行估計。
OpenAI 訓練了一個 CNN 用來估計位姿。這個網路把佈置在機械手周圍的三個攝像頭採集的視訊流作為輸入,然後輸出估計的物體位置和物體姿態。多個攝像頭的使用是為了避免判斷不清以及訊號延遲。訓練這個網路時 OpenAI 也使用了任務隨機化的做法,環境隨之暫時切換為了 Unity 遊戲開發平臺,它對各種視覺效果的支援豐富程度要比 MuJoCo 高得多。
「控制」與「觀察」兩個獨立的網路互相配合,控制網路可以根據給定的物體位姿重新調整它的位姿,視覺網路根據攝像頭採集的畫面確認物體當前的實際位姿。Dactyl 就這樣通過觀察控制了手裡的物體。

學習位姿估計的影象的一些示例
實驗結果
逐漸產生的行為
在部署系統的時候,OpenAI 的研究人員們注意到 Dactyl 會使用一系列豐富的靈活手掌內操縱技巧來解決在這個任務;人類其實也經常會使用這些技巧。而及這些技巧並不需要人類顯式地教會演算法,它們全都是演算法自己發掘、自己學到的。

兩指夾住旋轉、滑動、手指同步旋轉,三種 Dactyl 完全自動學到的與人類類似的運動模式

Dactyl 學到的六種不同的握持姿勢。根據握持分類學,從左上到右下依次為:指尖捏、掌心捏、三指握持、四指握持、強力握持以及 5 指精確握持。
OpenAI 通過觀察發現,對於幾種高精確度的握持方法,比如兩指指尖捏,Dactyl 傾向於使用大拇指和小拇指;人類比較習慣的自然是用大拇指+食指或者大拇指+中指。不過值得指出的是,機械手的小拇指比人類的多出一個自由度,更為靈活,這可以作為 Dactyl 學會了這樣行為的一個解釋。這也可以理解為,Dactyl 一面可以自己發現人類常用的手部姿態,同時也可以重新適應這些姿態,讓它們更符合自己的肢體的限制和能力。
( AI 科技評論注:多提供一個思考角度,從生物進化的角度來說,手指握持的方式是和手指的結構相互適應的。使用一個「類人」的機械手,學習到「類人」的握持姿勢並不奇怪。另一方面,握持姿勢的選擇除了自由度,也與生物結構有關,食指比小拇指更有力、也更靈活,這與人類更常用食指也是相輔相成)
系統表現的遷移
OpenAI 在真實環境的機械手與攝像頭配置上測試了 Dactyl 在物體脫手、或者時間用完之前能翻轉的次數,最高計數 50 次。在模擬器環境中訓練出的策略可以直接成功地操控真實世界中的物體。

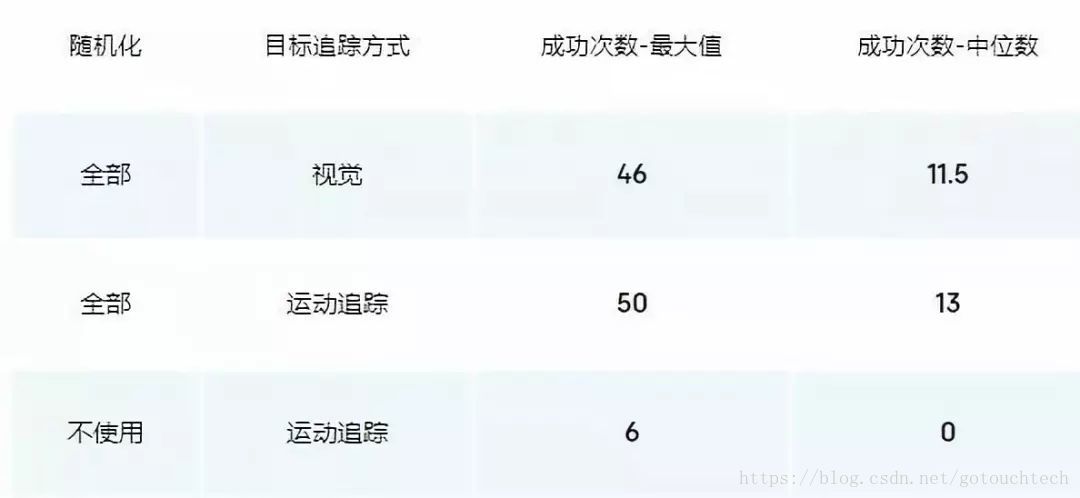
對於控制方塊的任務,使用了「任務隨機化」訓練得到的策略能成功完成翻轉的次數要多得多,如下表。並且,通過攝像頭訊號估計位姿進行控制得到的結果和使用運動追蹤感測器得到的結果差不多,這也體現出了視覺估計網路的高準確率。
學習過程
訓練過程中的大多數時間都花在了提升策略在不同物理屬性環境中的魯棒性上。在不使用隨機化時,在虛擬環境中學會翻轉物體需要的經驗大概相當於 3 年那麼長,而在全面使用了隨機化的設定下達到類似的表現需要大概相當於 100 年的經驗。(不過我們也別忘了,不使用隨機化時訓練出的策略是無法直接遷移到真實世界的機器人的,因為學到的策略只針對模擬器中那一組特定的物理引數有效)
實驗中的有趣發現
-
對於真實世界物體的控制來說,觸覺感知並不是必須的。Dactyl 接收到的訊號只包括 5 個手指指尖的位置以及方塊的位置和方向。機械手上確實帶有觸覺感測器,但是 OpenAI 並沒有使用它們就可以達到目標。總地來說,相比於有一大批感測器、一大批難以建模的數值,OpenAI 認為一組數目有限但可以在模擬環境中高效建模的感測器可以幫助帶來更好的表現。
-
為某一個物體做的隨機化設定可以泛化到其它屬性類似的物體上。在控制方塊的系統開發完成之後,OpenAI 製作了一個六稜柱,根據它的外型訓練了一個新的策略,然後嘗試讓機械手控制它。有點出乎他們意料的是,只依靠一開始為控制方塊設計的隨機化設定,機械手就能很好地控制六稜柱了。相比之下,重新訓練一個控制圓球的策略就不能連續成功很多次,可能是因為並沒有針對轉動行為設計適合的隨機化模擬引數。
-
對於真實機器人來說,好的系統工程和好的演算法一樣重要。在研究過程中,OpenAI 團隊發現幾個工程師都嘗試一樣的策略的時候,其中一位得到的表現總是要比其他幾位的好得多。後來他們發現是因為這位工程師的膝上型電腦比較快,一個會影響表現的計時器 bug 從而就不會出現。這個 bug 解決之後,整個團隊執行策略的表現都得到了提高。
沒有達到預期效果的專案
除了上面的驚喜之外,OpenAI 也驚訝地發現一些強化學習連續控制中的常用技巧並沒能幫助他們提高系統的表現。
-
減短反應時間並沒有提高系統表現。大家普遍認為減短做出動作的時間間隔能夠提高系統表現,因為這樣一來前後狀態之間的變化會比較小,也就更容易預測。目前 OpenAI 設定的動作時間間隔是 80ms,要比人類一般的反應時間 150~250ms 短一些,但是仍然比神經網路計算所需的大概 25ms 左右的時間長得多。令人驚訝的是,把動作時間間隔縮短到 40ms 需要花費更長的訓練時間,但同時並沒有給真實世界機械手的表現帶來可感的提升。有一種可能是,這種公認有效的做法用在神經網路模型上的效果確實要比用在目前廣泛使用的線性控制模型的效果差一些。
-
用真實資料訓練視覺策略並沒有帶來什麼提升。在早期的實驗中,OpenAI 綜合使用了模擬的以及真實的資料用來改進模型。真實資料的採集來自一個帶有追蹤標記的物體在測試策略的機械手上的實驗過程。然而,真實資料相比模擬的資料有著顯著的劣勢。從追蹤標記得到的位置資訊帶有延遲和測量誤差,而且更糟糕的是,隨便改變一點引數就會讓已經採集到的真實資料變得完全沒用。隨著 OpenAI 持續改進自己的方法,只使用模擬資料訓練的模型的表現也在不停提高,已經達到了模擬和真實資料混合訓練的模型的錯誤率水平。最終使用的模型也就完全沒有使用真實資料。
總結
對 OpenAI 來說,這個專案是他們過去兩年中追求的完整 AI 研發迴圈的最好體現:先開發新的強化學習演算法,再拓展它的執行規模、在模擬環境中訓練解決困難的問題,最後再把得到的系統應用在真實世界中。以越來越大的規模沿著這種途徑不停前進也是 OpenAI 為自己規劃的通往安全的通用人工智慧的主要路徑。
OpenAI 已經展示了聯通強化學習理論研究與現實世界問題探索的一座橋樑,我們也期待看到這個領域內更多的理論和現實世界問題聯動的案例。
論文地址:https://d4mucfpksywv.cloudfront.net/research-covers/learning-dexterity/learning-dexterity-paper.pdf