
sql中的正則函式
SQL 中的正則函式
ORACLE中支援正則表示式的函式主要有下面四個:
1,REGEXP_LIKE :與LIKE的功能相似,比LIKE強大得多。
2,REGEXP_INSTR :與INSTR的功能相似。
3,REGEXP_SUBSTR :與SUBSTR的功能相似。
4,REGEXP_REPLACE :與REPLACE的功能相似。
REGEXP_REPLACE(source_string,pattern,replace_string,position,occurtence,match_parameter)函式(10g新函式)
描述:字串替換函式。相當於增強的replace函式。Source_string指定源字元表示式;pattern指定規則表示式;replace_string指定用於替換的字串;position指定起始搜尋位置;occurtence指定替換出現的第n個字串;match_parameter指定預設匹配操作的文字串。ITPUB個人空間.x mz\ n`rg9[1`
其中replace_string,position,occurtence,match_parameter引數都是可選的。
REGEXP_SUBSTR(source_string, pattern[,position [, occurrence[, match_parameter]]])函式(10g新函式)
描述:返回匹配模式的子字串。相當於增強的substr函式。Source_string指定源字元表示式;pattern指定規則表示式;position指定起始搜尋位置;occurtence指定替換出現的第n個字串;match_parameter指定預設匹配操作的文字串。
其中position,occurtence,match_parameter引數都是可選的。
match_option的取值如下:
'c' 說明在進行匹配時區分大小寫(預設值);
'i' 說明在進行匹配時不區分大小寫;
'n' 允許使用可以匹配任意字元的操作符;
'm' 將x作為一個包含多行的字串。
REGEXP_LIKE(source_string, pattern[, match_parameter])函式(10g新函式)
描述:返回滿足匹配模式的字串。相當於增強的like函式。Source_string指定源字元表示式;pattern指定規則表示式;match_parameter指定預設匹配操作的文字串。
其中position,occurtence,match_parameter引數都是可選的。
REGEXP_INSTR(source_string, pattern[, start_position[, occurrence[, return_option[, match_parameter]]]])
描述: 該函式查詢 pattern ,並返回該模式的第一個位置。您可以隨意指定您想要開始搜尋的 start_position。 occurrence 引數預設為 1,除非您指定您要查詢接下來出現的一個模式。return_option 的預設值為 0,它返回該模式的起始位置;值為 1 則返回符合匹配條件的下一個字元的起始位置。
一. 匹配字元
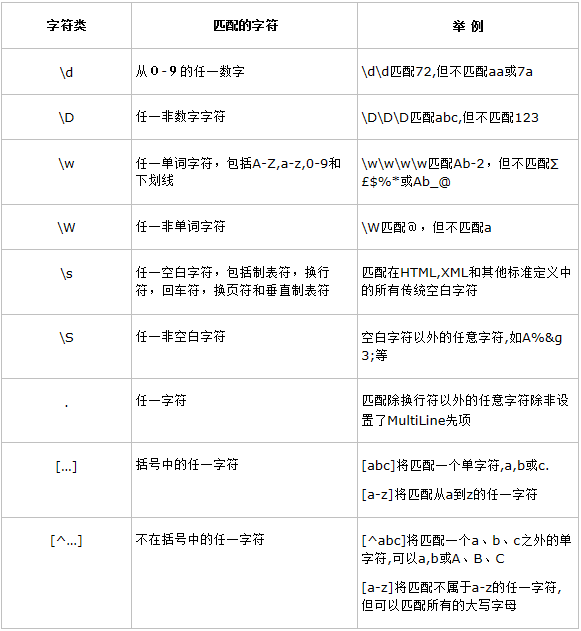
二. 重複字元
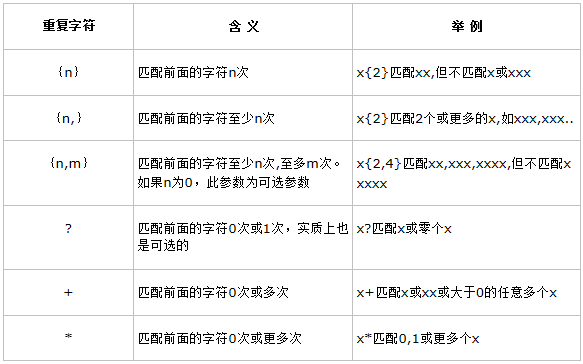
三. 定位字元
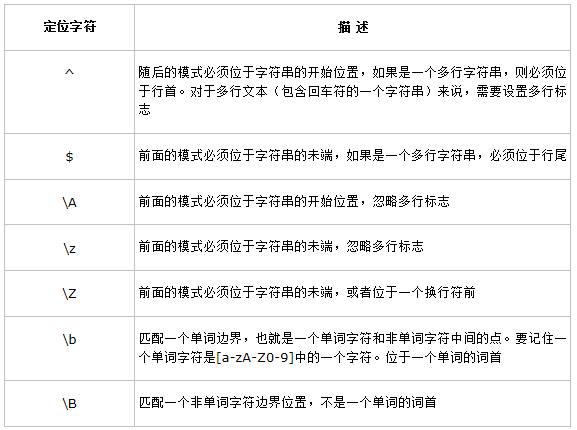
注:定位字元可以應用於字元或組合,放在字串的左端或右端
四. 分組字元
| 分組字元 |
定 義 |
舉 例 |
| () |
此字元可以組合括號內模式所匹配的字元,它是一個捕獲組,也就是說模式匹配的字元作為最終設定了ExplicitCapture選項――預設狀態下字元不是匹配的一部分 |
輸入字串為:ABC1DEF2XY 匹配3個從A到Z的字元和1個數字的正則表示式:([A-Z]{3}\d) 將產生兩次匹配:Match 1=ABC1;Match 2=DEF2 每次匹配對應一個組:Match1的第一個組=ABC;Match2的第1個組=DEF 有了反向引用,就可以通過它在正則表示式中的編號以及C#和類Group,GroupCollection來訪問組。如果設定了ExplicitCapture選項,就不能使用組所捕獲的內容 |
| (?:) |
此字元可以組合括號內模式所匹配的字元,它是一個非捕獲組,這意味著模式所的字元將不作為一個組來捕獲,但它構成了最終匹配結果的一部分。它基本上與上面的組型別相同,但設定了選項ExplicitCapture |
輸入字串為:1A BB SA1 C 匹配一個數字或一個A到Z的字母,接著是任意單詞字元的正則表示式為:(?:\d|[A-Z]\w) 它將產生3次匹配:每1次匹配=1A;每2次匹配=BB;每3次匹配=SA 但是沒有組被捕獲 |
| (?<name>) |
此選項組合括號內模式所匹配的字元,並用尖括號中指定的值為組命名。在正則表示式中,可以使用名稱進行反向引用,而不必使用編號。即使不設定ExplicitCapture選項,它也是一個捕獲組。這意味著反向引用可以利用組內匹配的字元,或者通過Group類訪問 |
輸入字串為:Characters in Sienfeld included Jerry Seinfeld,Elaine Benes,Cosno Kramer and George Costanza能夠匹配它們的姓名,並在一個組llastName中捕獲姓的正則表示式為:\b[A-Z][a-z]+(?<lastName>[A-Z][a-z]+)\b 它產生了4次匹配:First Match=Jerry Seinfeld; Second Match=Elaine Benes; Third Match=Cosmo Kramer; Fourth Match=George Costanza 每一次匹配都對應了一個lastName組: 第1次匹配:lastName group=Seinfeld 第2次匹配:lastName group=Benes 第3次匹配:lastName group=Kramer 第4次匹配:lastName group=Costanza 不管是否設定了選項ExplictCapture,組都將被捕獲 |
| (?=) |
正宣告。宣告的右側必須是括號中指定的模式。此模式不構成最終匹配的一部分 |
正則表示式\S+(?=.NET)要匹配的輸入字串為:The languages were Java,C#.NET,VB.NET,C,Jscript.NET,Pascal 將產生如下匹配:〕 C# VB JScript. |
| (?!) |
負宣告。它規定模式不能緊臨著宣告的右側。此模式不構成最終匹配的一部分 |
\d{3}(?![A-Z])要匹配的輸入字串為:123A 456 789111C 將產生如下匹配: 456 789 |
| (?<=) |
反向正宣告。宣告的左側必須為括號內的指定模式。此模式不構成最終匹配的一部分 |
正則表示式(?<=New)([A-Z][a-z]+)要匹配的輸入字串為:The following states,New Mexico,West Virginia,Washington, New England 它將產生如下匹配: Mexico England |
| (?<!) |
反向正宣告。宣告的左側必須不能是括號內的指定模式。此模式不構成最終匹配的一部分 |
正則表示式(?<!1)\d{2}([A-Z])要匹配的輸入字串如下:123A456F789C111A 它將實現如下匹配: 56F 89C |
| (?>) |
非回溯組。防止Regex引擎回溯並且防止實現一次匹配 |
假設要匹配所有以“ing”結尾的單詞。輸入字串如下:He was very trusing 正則表示式為:.*ing 它將實現一次匹配――單詞trusting。“.”匹配任意字元,當然也匹配“ing”。所以,Regex引擎回溯一位並在第2個“t”停止,然後匹配指定的模式“ing”。但是,如果禁用回溯操作:(?>.*)ing 它將實現0次匹配。“.”能匹配所有的字元,包括“ing”――不能匹配,從而匹配失敗 |
五. 決策字元
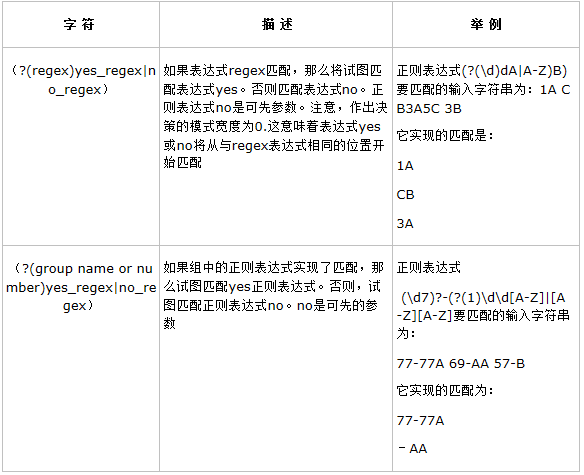
注:上面表中列出的字元強迫處理器執行一次if-else決策
六. 替換字元
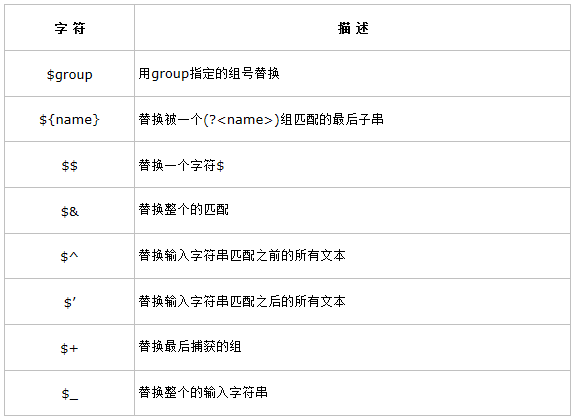
注:以上為常用替換字元,不全
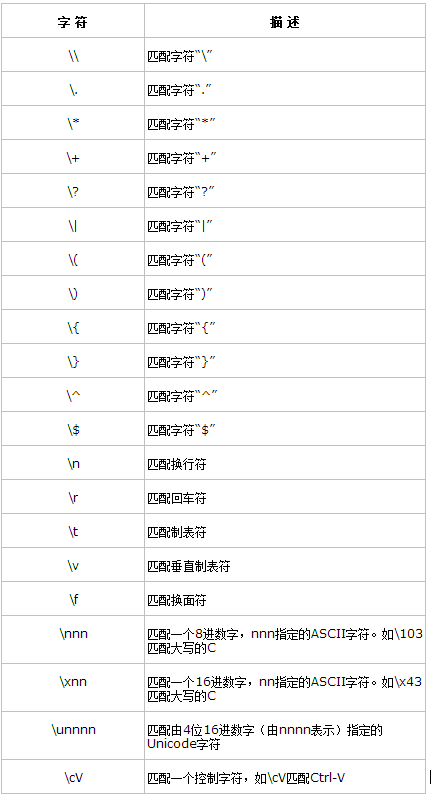
七. 轉義序列
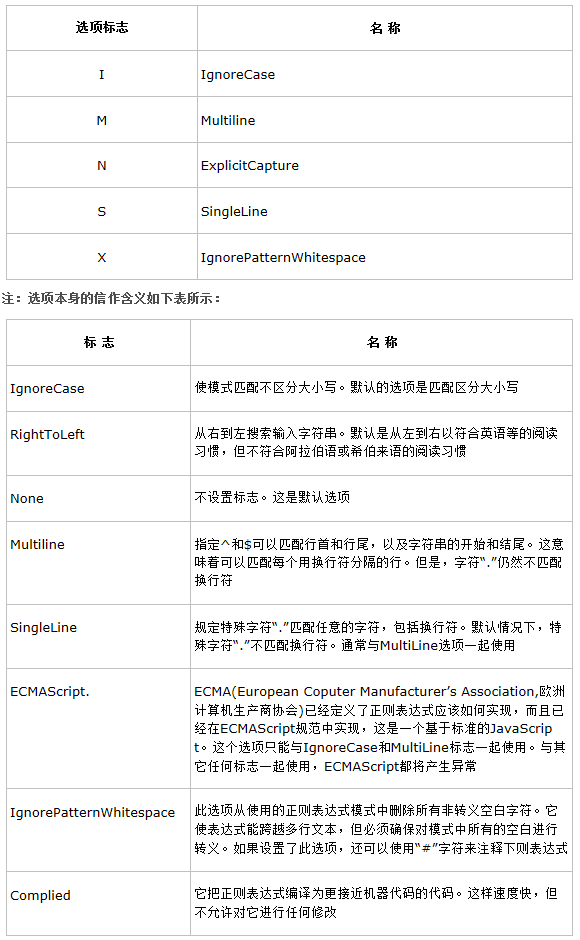
八. 選項標誌
參考:http://www.cnblogs.com/gkl0818/archive/2009/02/12/1389521.html