
==6==基於tensorflow目標識別API進行mask_rcnn訓練
一 資料準備
在object_detection下建立資料夾my_mask_rcnn,把下載下來的資料放進去。
不想自己label的直接下載相關文件;連結主要包含原始圖片,標註後的json格式資料,Abyssinian_label_map.pbtxt(類別對映表)。



二 生成train.record val.record
create_tf_record.py用大佬修改的:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Created on Sun Aug 26 10:57:09 2018 @author: shirhe-lyh """ """Convert raw dataset to TFRecord for object_detection. Please note that this tool only applies to labelme's annotations(json file). Example usage: python3 create_tf_record.py \ --images_dir=your absolute path to read images. --annotations_json_dir=your path to annotaion json files. --label_map_path=your path to label_map.pbtxt --output_path=your path to write .record. """ import cv2 import glob import hashlib import io import json import numpy as np import os import PIL.Image import tensorflow as tf import read_pbtxt_file flags = tf.app.flags flags.DEFINE_string('images_dir', None, 'Path to images directory.') flags.DEFINE_string('annotations_json_dir', 'datasets/annotations/train', 'Path to annotations directory.') flags.DEFINE_string('label_map_path', None, 'Path to label map proto.') flags.DEFINE_string('output_path', None, 'Path to the output tfrecord.') FLAGS = flags.FLAGS def int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) def int64_list_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=value)) def bytes_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) def bytes_list_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=value)) def float_list_feature(value): return tf.train.Feature(float_list=tf.train.FloatList(value=value)) def create_tf_example(annotation_dict, label_map_dict=None): """Converts image and annotations to a tf.Example proto. Args: annotation_dict: A dictionary containing the following keys: ['height', 'width', 'filename', 'sha256_key', 'encoded_jpg', 'format', 'xmins', 'xmaxs', 'ymins', 'ymaxs', 'masks', 'class_names']. label_map_dict: A dictionary maping class_names to indices. Returns: example: The converted tf.Example. Raises: ValueError: If label_map_dict is None or is not containing a class_name. """ if annotation_dict is None: return None if label_map_dict is None: raise ValueError('`label_map_dict` is None') height = annotation_dict.get('height', None) width = annotation_dict.get('width', None) filename = annotation_dict.get('filename', None) sha256_key = annotation_dict.get('sha256_key', None) encoded_jpg = annotation_dict.get('encoded_jpg', None) image_format = annotation_dict.get('format', None) xmins = annotation_dict.get('xmins', None) xmaxs = annotation_dict.get('xmaxs', None) ymins = annotation_dict.get('ymins', None) ymaxs = annotation_dict.get('ymaxs', None) masks = annotation_dict.get('masks', None) class_names = annotation_dict.get('class_names', None) labels = [] for class_name in class_names: label = label_map_dict.get(class_name, 'None') if label is None: raise ValueError('`label_map_dict` is not containing {}.'.format( class_name)) labels.append(label) encoded_masks = [] for mask in masks: pil_image = PIL.Image.fromarray(mask.astype(np.uint8)) output_io = io.BytesIO() pil_image.save(output_io, format='PNG') encoded_masks.append(output_io.getvalue()) feature_dict = { 'image/height': int64_feature(height), 'image/width': int64_feature(width), 'image/filename': bytes_feature(filename.encode('utf8')), 'image/source_id': bytes_feature(filename.encode('utf8')), 'image/key/sha256': bytes_feature(sha256_key.encode('utf8')), 'image/encoded': bytes_feature(encoded_jpg), 'image/format': bytes_feature(image_format.encode('utf8')), 'image/object/bbox/xmin': float_list_feature(xmins), 'image/object/bbox/xmax': float_list_feature(xmaxs), 'image/object/bbox/ymin': float_list_feature(ymins), 'image/object/bbox/ymax': float_list_feature(ymaxs), 'image/object/mask': bytes_list_feature(encoded_masks), 'image/object/class/label': int64_list_feature(labels)} example = tf.train.Example(features=tf.train.Features( feature=feature_dict)) return example def _get_annotation_dict(images_dir, annotation_json_path): """Get boundingboxes and masks. Args: images_dir: Path to images directory. annotation_json_path: Path to annotated json file corresponding to the image. The json file annotated by labelme with keys: ['lineColor', 'imageData', 'fillColor', 'imagePath', 'shapes', 'flags']. Returns: annotation_dict: A dictionary containing the following keys: ['height', 'width', 'filename', 'sha256_key', 'encoded_jpg', 'format', 'xmins', 'xmaxs', 'ymins', 'ymaxs', 'masks', 'class_names']. # # Raises: # ValueError: If images_dir or annotation_json_path is not exist. """ # if not os.path.exists(images_dir): # raise ValueError('`images_dir` is not exist.') # # if not os.path.exists(annotation_json_path): # raise ValueError('`annotation_json_path` is not exist.') if (not os.path.exists(images_dir) or not os.path.exists(annotation_json_path)): return None with open(annotation_json_path, 'r') as f: json_text = json.load(f) shapes = json_text.get('shapes', None) if shapes is None: return None image_relative_path = json_text.get('imagePath', None) if image_relative_path is None: return None image_name = image_relative_path.split('/')[-1] image_path = os.path.join(images_dir, image_name) image_format = image_name.split('.')[-1].replace('jpg', 'jpeg') if not os.path.exists(image_path): return None with tf.gfile.GFile(image_path, 'rb') as fid: encoded_jpg = fid.read() image = cv2.imread(image_path) height = image.shape[0] width = image.shape[1] key = hashlib.sha256(encoded_jpg).hexdigest() xmins = [] xmaxs = [] ymins = [] ymaxs = [] masks = [] class_names = [] hole_polygons = [] for mark in shapes: class_name = mark.get('label') class_names.append(class_name) polygon = mark.get('points') polygon = np.array(polygon) if class_name == 'hole': hole_polygons.append(polygon) else: mask = np.zeros(image.shape[:2]) cv2.fillPoly(mask, [polygon], 1) masks.append(mask) # Boundingbox x = polygon[:, 0] y = polygon[:, 1] xmin = np.min(x) xmax = np.max(x) ymin = np.min(y) ymax = np.max(y) xmins.append(float(xmin) / width) xmaxs.append(float(xmax) / width) ymins.append(float(ymin) / height) ymaxs.append(float(ymax) / height) # Remove holes in mask for mask in masks: mask = cv2.fillPoly(mask, hole_polygons, 0) annotation_dict = {'height': height, 'width': width, 'filename': image_name, 'sha256_key': key, 'encoded_jpg': encoded_jpg, 'format': image_format, 'xmins': xmins, 'xmaxs': xmaxs, 'ymins': ymins, 'ymaxs': ymaxs, 'masks': masks, 'class_names': class_names} return annotation_dict def main(_): if not os.path.exists(FLAGS.images_dir): raise ValueError('`images_dir` is not exist.') if not os.path.exists(FLAGS.annotations_json_dir): raise ValueError('`annotations_json_dir` is not exist.') if not os.path.exists(FLAGS.label_map_path): raise ValueError('`label_map_path` is not exist.') label_map = read_pbtxt_file.get_label_map_dict(FLAGS.label_map_path) writer = tf.python_io.TFRecordWriter(FLAGS.output_path) num_annotations_skiped = 0 annotations_json_path = os.path.join(FLAGS.annotations_json_dir, '*.json') for i, annotation_file in enumerate(glob.glob(annotations_json_path)): if i % 100 == 0: print('On image %d', i) annotation_dict = _get_annotation_dict( FLAGS.images_dir, annotation_file) if annotation_dict is None: num_annotations_skiped += 1 continue tf_example = create_tf_example(annotation_dict, label_map) writer.write(tf_example.SerializeToString()) print('Successfully created TFRecord to {}.'.format(FLAGS.output_path)) if __name__ == '__main__': tf.app.run()
可以把下載下來的json檔案前8張作為train,後兩張作為val;
也就是將下載下來的資料中datasets/annotation 資料夾分為train和val
假設你的所有原始影象的路徑為 path_to_images_dir,使用 labelme 標註產生的所有用於 訓練 的 json 檔案的路徑為 path_to_train_annotations_json_dir(train),所有用於 驗證 的 json 檔案的路徑為 path_to_val_annotaions_json_dir(val),進入my_mask_rcnn在終端先後執行如下指令:
$ python3 create_tf_record.py \ --images_dir=datasets/images \ --annotations_json_dir=datasets/train\ --label_map_path=Abyssinian_label_map.pbtxt\ --output_path=my_train.record $ python3 create_tf_record.py \ --images_dir=datasets/images \ --annotations_json_dir=datasets/val\ --label_map_path=Abyssinian_label_map.pbtxt \ --output_path=my_val.record
報錯沒有cv2就裝一個 pip3 install opencv-python
三 模型下載
模型下載連結
我下載的模型是mask_rcnn_inception_v2_coco_2018_01_28.tar.gz
存放地址為my_mask_rcnn/
並且解壓到當前目錄
四 修改配置檔案
將其中的 num_classes : 90 改為你要檢測的目標總類目數,比如,因為這裡我們只檢測 阿比西尼亞貓 一個類,所以改為 1。另外,還需要將該檔案中 5 個 PATH_TO_BE_CONFIGURED 改為相應檔案的路徑;可從下載下來解壓後的配置檔案修改。‘
# Mask R-CNN with Inception V2 # Configured for MSCOCO Dataset. # Users should configure the fine_tune_checkpoint field in the train config as # well as the label_map_path and input_path fields in the train_input_reader and # eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that # should be configured. model { faster_rcnn { num_classes: 1 image_resizer { keep_aspect_ratio_resizer { min_dimension: 800 max_dimension: 1365 } } number_of_stages: 3 feature_extractor { type: 'faster_rcnn_inception_v2' first_stage_features_stride: 16 } first_stage_anchor_generator { grid_anchor_generator { scales: [0.25, 0.5, 1.0, 2.0] aspect_ratios: [0.5, 1.0, 2.0] height_stride: 16 width_stride: 16 } } first_stage_box_predictor_conv_hyperparams { op: CONV regularizer { l2_regularizer { weight: 0.0 } } initializer { truncated_normal_initializer { stddev: 0.01 } } } first_stage_nms_score_threshold: 0.0 first_stage_nms_iou_threshold: 0.7 first_stage_max_proposals: 300 first_stage_localization_loss_weight: 2.0 first_stage_objectness_loss_weight: 1.0 initial_crop_size: 14 maxpool_kernel_size: 2 maxpool_stride: 2 second_stage_box_predictor { mask_rcnn_box_predictor { use_dropout: false dropout_keep_probability: 1.0 predict_instance_masks: true mask_height: 15 mask_width: 15 mask_prediction_conv_depth: 0 mask_prediction_num_conv_layers: 2 fc_hyperparams { op: FC regularizer { l2_regularizer { weight: 0.0 } } initializer { variance_scaling_initializer { factor: 1.0 uniform: true mode: FAN_AVG } } } conv_hyperparams { op: CONV regularizer { l2_regularizer { weight: 0.0 } } initializer { truncated_normal_initializer { stddev: 0.01 } } } } } second_stage_post_processing { batch_non_max_suppression { score_threshold: 0.0 iou_threshold: 0.6 max_detections_per_class: 100 max_total_detections: 300 } score_converter: SOFTMAX } second_stage_localization_loss_weight: 2.0 second_stage_classification_loss_weight: 1.0 second_stage_mask_prediction_loss_weight: 4.0 } } train_config: { batch_size: 1 optimizer { momentum_optimizer: { learning_rate: { manual_step_learning_rate { initial_learning_rate: 0.0002 schedule { step: 900000 learning_rate: .00002 } schedule { step: 1200000 learning_rate: .000002 } } } momentum_optimizer_value: 0.9 } use_moving_average: false } gradient_clipping_by_norm: 10.0 fine_tune_checkpoint: "my_mask_rcnn/mask_rcnn_inception_v2_coco/model.ckpt" from_detection_checkpoint: true # Note: The below line limits the training process to 200K steps, which we # empirically found to be sufficient enough to train the pets dataset. This # effectively bypasses the learning rate schedule (the learning rate will # never decay). Remove the below line to train indefinitely. num_steps: 2000 data_augmentation_options { random_horizontal_flip { } } } train_input_reader: { tf_record_input_reader { input_path: "my_mask_rcnn/my_train.record" } label_map_path: "my_mask_rcnn/Abyssinian_label_map.pbtxt" load_instance_masks: true mask_type: PNG_MASKS } eval_config: { num_examples: 10 # Note: The below line limits the evaluation process to 10 evaluations. # Remove the below line to evaluate indefinitely. max_evals: 10 } eval_input_reader: { tf_record_input_reader { input_path: "my_mask_rcnn/my_val.record" } label_map_path: "my_mask_rcnn/Abyssinian_label_map.pbtxt" load_instance_masks: true mask_type: PNG_MASKS shuffle: false num_readers: 1 }
五訓練
model_dir 用來存放訓練過程中的資料 老版本是train_dir
$ python3 model_main.py \
--model_dir=my_mask_rcnn/ model_dir\
--pipeline_config_path=my_mask_rcnn/mask_rcnn_inception_v2_coco.config
執行到第70次~

還有訓練的時候老是報錯超記憶體

應該如何解決呢?
六 匯出結果並且測試
1匯出凍結檔案
雖然超出記憶體但是還是會儲存訓練到一定迭代步數的資料(200步)。
model_dir生成資料情況如下:

在object_detection下執行
在my_mask_rcnn下建立資料夾trained,儲放匯出檔案
python3 export_inference_graph.py
--input_tpye_image_tensor
--pipeline_config_path my_mask_rcnn/mask_rcnn_inception_v2_coco.config
--trained_checkpoint_prefix my_mask_rcnn/model_dir/model.ckpt200
--output_directory my_mask_rcnn/trained/
其中會有一個凍結檔案。
2測試
首先複製兩張貓的圖片到object_detection/test_images 修改名字為image+序號.jpg

其次再research/ 右擊開啟終端
jupyter-notebook
點選object_detection
開啟object_detection_tutorial.ipynb
修改文件
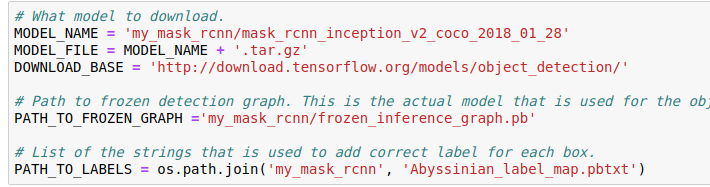
修改範圍;圖片序號為5則改為(1,6):1,2,3,4,5,
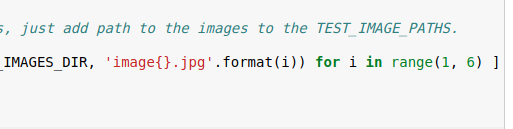
因為提前下好了模型,則不需要download,則把下載模型單元刪除了。
效果如下,因為只用了8張訓練,並且迭代次數為200次,效果很粗糙,只是熟悉過程。

總結 -溫習過程
1.訓練需要準備的資料有,原圖(3通道.jpg格式),label後的資料(.json),類別標籤對映表(Abyssinian_label_map.pbtxt)
2轉換為tfrecord格式。(需要create_tf_record.py,原圖,.json資料,類別標籤對映表)
python3 create_tf_record.py
–images_dir=datasets/images \
–annotations_json_dir=datasets/train\
–label_map_path=Abyssinian_label_map.pbtxt
–output_path=my_train.record
3.下載模型並修改其中自帶的配置表
4.匯出凍結檔案並且測試!